International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 2, Issue 12, December 2012)
167
Study and Analysis of Decision Tree Based Irrigation Methods
in Agriculture System
Ravindra M
1, V. Lokesha
2, Prasanna Kumara
3, Alok Ranjan
41
Research Scholar, Dept. of Computer Scince, Singhania University, Rajasthan – INDIA
2 Acharya Institute of Technology, Bangalore – INDIA
3 Asst. Professor, Dept. of MCA, Cambridge Institute of Technology, Bangalore – INDIA 4
Asst. Professor, Dept. of CSE, Canara Engg. College, Mangalore – INDIA Abstract - Most of the energy coupling materials currently
available have been around for decades, their use for the specific purpose of power harvesting has not been thoroughly examined until recently, when the power requirements of many electronic devices has reduced drastically. The objective of this research is to focus on the power source characteristics of various transducer devices in order to find some basic way to compare the relative energy densities of each type of device and, where possible, the comparative energy densities within subcategories of harvesting techniques. The successful implementation of decision tree helps to select the optimized utilization of the available methods in the irrigation to the fields to help farmer’s in making the decision in selecting the best suited pump set for irrigation. The various parameters such as irrigation types, the area coverage of the field in terms of acres, capacity of the motor being used for pumping the water, the height at which the water is being pumped etc., are considered while making the decision in the selection of best suited pump set for the irrigation.
Keywords- Classification, Decision Trees, Data Mining techniques, irrigation system, harvesting techniques.
I. INTRODUCTION
The development of Information Technology lead to a large amount of data generation, and are stored in the repositories, thus most of the organizations become „data rich and information poor‟.[1] The conversion of huge volume of data into highly valued information, which are used to aid in decision making in various business processes. The extraction of knowledge from large sets of data help the business organizations to focus on most important information‟s in their data warehouses.[2] Data mining is the science of extracting useful information from large data sets or databases. The different kinds of information which could be mined are: i) Business Transactions Data, ii) Scientific Data, iii) Media and Personal Data, iv) Surveillance video and images, v) Spatial data, vi) World Wide Web repositories etc.[3] The Data Mining techniques are the result of long process of research and product development.
Data Mining is also known as Knowledge Extraction, Data/Pattern Analysis, Data Archeology, Data Dredging, Information Harvesting, Business Intelligence etc. Data Mining is not specific to one kind of data or media; instead, it is applicable to any kind of information in the repository [4]. Its fundamental objective is to provide insight and understanding about the structure of the data and its important features, and to discover and extract patterns contained in the data set. Data mining brings together a multitude of disciplines, such as database systems, statistics, artificial intelligence, data visualization, and others. The discovered knowledge can be applied to Information Management, Query Processing, Decision-Making, Process Control and many other applications [5].
II. DATA MINING PROCESS
Data Mining is a convergence of three key technologies i.e. Increasing Computing Power, Statistical and Learning
Algorithms, and Improved Data Collection and
Management. The idea of Data Mining is drawn from
Artificial Intelligence, Machine Learning, Pattern
Recognition, Statistics and Database Systems [5]. The main techniques of data mining are Association Analysis, Clustering Analysis, Classification, Prediction, Time-Series Patterns and Bias Analysis.
The steps in the data mining process are: i. Problem
Definition: Defining the business problem is the first and the most important step in the Data Mining Process., ii. Data Collection and Enhancement: Involves the steps such as a. Define Data-Sources, b. Join and Deformalize-Data, c. Enrich Data, d. Transform-Data iii. Modeling Strategies: Fall into two categories: supervised learning and unsupervised learning, iv. Training, Validation, and Testing
of Models:Partitioning data sets into one set of data used to
train a model, another data set used to validate the model, and a third used to test the trained and validated model, v.
Analyzing Results: Diagnosing and evaluating the results obtained from a Data Mining Model, vi. Modeling
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 2, Issue 12, December 2012)
168
III. CLASSIFICATION
Classification is a data mining function that assigns items in a collection to target categories or classes. In data mining, classification is one of the most important tasks. It maps the data in to predefined targets. It is a supervised learning as targets are predefined. The aim of the classification is to build a classifier based on some cases with some attributes to describe the objects or one attribute to describe the group of the objects. Then, the classifier is used to predict the group attributes of new cases from the domain based on the values of other attributes [6]. The goal of classification is to accurately predict the target class for each case in the data. Classification technique is capable of processing a wider variety of data than regression and is growing in popularity.
The classification task begins with a data set in which the class assignments are known. In the model build (training) process, a classification algorithm finds relationships between the values of the predictors and the values of the target. Different classification algorithms use different techniques for finding relationships. These relationships are summarized in a model, which can then be applied to a different data set in which the class assignments are unknown. Classification models are tested by comparing the predicted values to known target values in a set of test data. The historical data for a classification project is typically divided into two data sets: one for building the model; the other for testing the model. Scoring a classification model results in class assignments and probabilities for each case.[7]
The basic classification techniques are: i. Decision Tree Based Methods, ii. Rule-Based Methods, iii. Neural Networks, iv. Naïve Bayes and Bayesian Belief Networks, v. Support Vector Machines etc. The Classification methods are used in many applications such as customer segmentation, business modeling, marketing, credit analysis, and biomedical and drug response modeling etc. A classification model is tested by applying it to test data with known target values and comparing the predicted values with the known values. The test data must be compatible with the data used to build the model and must be prepared in the same way that the build data was prepared. Typically the build data and test data come from the same historical data set. A percentage of the records are used to build the model; the remaining records are used to test the model.
Test metrics are used to assess how accurately the model predicts the known values. If the model performs well and meets the business requirements, it can then be applied to new data to predict the future. Since the classification model uses the Decision Tree algorithm, rules are generated with the predictions and probabilities.
IV. DECISION TREES
Most Data Mining techniques are based on inductive learning, where a model is constructed explicitly or implicitly by generalizing from a sufficient number of training examples. Traditionally, data collection was regarded as one of the most important stages in data analysis. The number of variables selected was usually small and the collection of their values could be done manually.
In the case of computer-aided analysis, the analyst had to enter the collected data into a statistical computer package or an electronic spreadsheet. Due to the high cost of data collection, people learned to make decisions based on limited information. Since the dawn of the Information Age, accumulating data has become easier and storing it is inexpensive [8]. It has been estimated that the amount of
stored information doubles every twenty months
unfortunately, as the amount of machine-readable information increases; the ability to understand and make use of it does not keep pace with its growth.
Training Set
Induction
Deduction
Test Set Decision Tree
Figure 1: Decision Tree Model Tree
Induction Algorithm
Apply Model Learn Model
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 2, Issue 12, December 2012)
169
There are two main types of data mining: Verification-Oriented (the system verifies the user‟s hypothesis) and Discovery-Oriented (the system finds new rules and
patterns autonomously). Each type has its own
methodology. In data mining, a Decision Tree is a predictive model which can be used to represent both Classifiers and Regression models. In Operations Research, on the other hand, decision trees refer to a hierarchical model of decisions and their consequences. The decision maker employs decision trees to identify the strategy most likely to reach her goal. When a decision tree is used for classification tasks, it is more appropriately referred to as a Classification Tree. When it is used for regression tasks, it is called Regression Tree.
Classification Trees are used to classify an object or an instance to a predefined set of classes (such as risky/non-risky) based on their attributes values. Classification Trees are frequently used in applied fields such as finance, marketing, engineering and medicine. Classification trees are usually represented graphically as hierarchical structures, making them easier to interpret than other techniques. The use of a decision tree is a very popular technique in data mining. In the opinion of many researchers, decision trees are popular due to their simplicity and transparency.
Decision trees (DTs) are either univariate or multivariate [9]. Univariate Decision Trees (UDTs) approximate the underlying distribution by partitioning the feature space recursively with axis parallel hyperplanes. The underlying function, or relationship between inputs and outputs, is approximated by a synthesis of the hyper-rectangles generated from the partitions. Multivariate Decision Trees (MDTs) have more complicated partitioning methodologies and are computationally more expensive than UDTs [10].
In the process of determining the right choice for the harvesting for the farmers, the various parameters such as irrigation types, the area coverage of the field in terms of acres, capacity of the motor being used for pumping the water, the height at which the water is being pumped etc., The following points are to be considered during are considered while making the decision in the selection of best suited pump set for the irrigation: a. Selection of Power Supply: i. Single Phase ii. Three Phase, b. Area available for irrigation, iii. Head to lift water supply, iv. Additional head for sprinkler irrigation. v. Type of cultivation, vi. Source of water (Plenty or Limited). vii. Economy of the power (to decide the cost method of irrigation), viii. Distance from the transformer, ix.
[image:3.612.327.550.171.380.2]Type of the Pump set: a). Mono block, b). Submersible, c) New Open Source, x. Required season for irrigation etc.
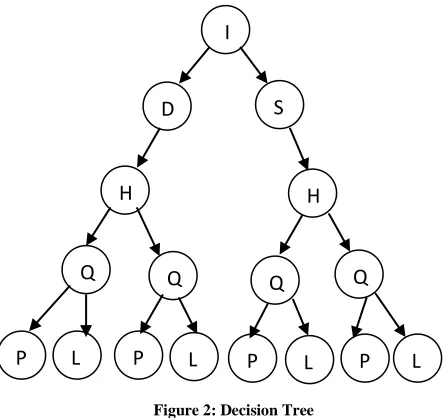
Figure 2: Decision Tree
I-Irrigation, S-Sprinkler, D-Drip, H-Height, Q-Quantity, P-Plenty, L-Limited
Tree Classification Rules are :
i. Type(Drip)^Distance(<100)^Height(<50)^Quantity
(Limited) ^ Acres(<5) => 2HP Good
ii. Type(Drip)^Distance(>100)^Height(<50)^Quantity
(Plenty)^Acres(<10) => 5HP Good
iii. Type(Sprinkler)^Distance(<100)^Height(<100)^Quant
ity(Limited)^Acres(<10) => 5HP Good
iv. Type(Sprinkler)^Distance(>100)^Height(<50)^Quantit
y(Plenty)^Acres(<5) => 2HP Good.
The Information Gain for the Decision Tree is calculated
using the formula I=(Log 2 N= log N/log 2). So the
information gain for the left and right hand side of the tree is:
P=35, N=29,
I(P,N) = -(35/(35+29))log2 (35/(35+29))
-(29/(35+29))log 2 (29/(35+29))
= -0.547 log2(0.547) - 0.453 log 2(0.453)
= -0.547 * -0.87 - 0.453 * -1.142 = 0.476+0.517 = 0.993.
(Left) P=18, N=14,
I(PSub1,NSub1) = (18/(18+14))log2 (18/(18+14)) = -(14/(18+14))log 2 (14/(18+14))
= -0.56 log2(0.56) - 0.44 log2(0.44)
= -0.56 * -0.837 - 0.44 * -1.18 = 0.469+0.5192 = 0.9882
I
D
S
H
H
Q
Q
Q
Q
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 2, Issue 12, December 2012)
170
(Right) : P=17, N=15,
I(PSub1,NSub1)= (17/(17+15))log2 (17/(17+15)) -(15/(17+15))log2 (15/(17+15))
= -0.53 log2(0.53) - 0.47 log2(0.47)
= -0.53 * -0.92 - 0.47 * -1.089 = 0.4876+0.512 = 0.9996
E(Type) = ((18+14)/64) * 0.9882 + ((17+15)/64) * 0.9996
= 0.5 * 0.9882 + 0.5 * 0.9996 = 0.4943 + 0.4998 = 0.9941
Therefore the Information Gain for the Irrigation Type is : I(Type of Irrigation) = 0.993 – 0.9941= -0.0011.
Drip->Distance->Left
P=9, N=7
= -(9/(16))log 2 (9/(16))-(7/(16))log 2 (7/(16)) = -0.562log2 (0.562))-0.437log2 (0.437) = (-0.562*-0.831)-(0.437*-1.194) = 0.9888
Drip->Distance-> Right
P=9, N=7
= (9/(16))log 2 (9/(16))-(7/(16))log 2 (7/(16)) = 0.562log2 (0.562))-0.437log2 (0.437) = (-0.562*-0.831)-(0.437*-1.194) = 0.9888
Sprinkler->Distance-> Left
P=9, N=7
= -(9/(16))log 2 (9/(16))-(7/(16))log 2 (7/(16)) = -0.562log2 (0.562))-0.437log2(0.437) = (-0.562*-0.831)-(0.437*-1.194) = 0.9888
Sprinkler->Distance-> Right
P=8, N=8
= -(8/(16))log 2 (8/(16))-(8/(16))log 2 (8/(16)) = -0.5log2(0.5))-0.5log2(0.5)
= -0.5*-1 - 0.5*-1 = 1.0
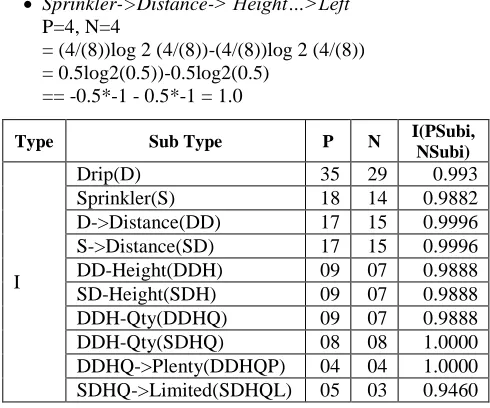
Drip->Distance-> Height…>Left
P=4, N=4
= -(4/(8))log 2 (4/(8))-(4/(8))log 2 (4/(8)) = -0.5log2(0.5))-0.5log2(0.5)
= -0.5*-1 - 0.5*-1 = 1.0
Drip->Distance-> Height…>Right
P=5, N=3
= -(5/(8))log 2 (5/(8))-(3/(8))log 2 (3/(8)) = -0.62log2(0.62))-0.375log2(0.375)) = -0.62*-0.670 - 0.375*-1.415 = 0.9460
Sprinkler->Distance-> Height…>Right
P=5, N=3
= (5/(8))log 2 (5/(8))-(3/(8))log 2 (3/(8)) 0.62log2 (0.62))-0.375log2 (0.375)) = -0.62*-0.670 - 0.375*-1.415 = 0.9460
Sprinkler->Distance-> Height…>Left
P=4, N=4
= (4/(8))log 2 (4/(8))-(4/(8))log 2 (4/(8)) = 0.5log2(0.5))-0.5log2(0.5)
== -0.5*-1 - 0.5*-1 = 1.0
Type Sub Type P N I(PSubi,
NSubi)
I
Drip(D) 35 29 0.993
Sprinkler(S) 18 14 0.9882
D->Distance(DD) 17 15 0.9996
S->Distance(SD) 17 15 0.9996
DD-Height(DDH) 09 07 0.9888
SD-Height(SDH) 09 07 0.9888
DDH-Qty(DDHQ) 09 07 0.9888
DDH-Qty(SDHQ) 08 08 1.0000
DDHQ->Plenty(DDHQP) 04 04 1.0000
[image:4.612.321.566.140.344.2]SDHQ->Limited(SDHQL) 05 03 0.9460
Table 1: Information Gain summary
V. CONCLUSION
Classification methods are typically strong in modeling interactions. The goal of classification result integration algorithms is to generate more certain, precise and accurate system results. Numerous methods have been suggested for the creation of ensemble of classifiers. The table lists the information gains with various types of parameters that could be used in the agriculture irrigation by a farmer in his/her fields. By comparing the various parameters considered, one could identify the best suitable method of irrigation for his/her fields, which could help them in the cultivation, and thus maximize the profit.
REFERENCES
[1 ] Shen-Ming Gu, Yun Zheng, Lin-Ting Guan, Yue-ting Zhuang: “The
Explore of Some Cases with Data Mining Techniques”, International Conference on Electronic Computer Technology, 2009, 978-0-7695-3559-3/09, DOI 10.1109/ICECT.2009.47.
[2 ] Mrs. Bharati M. Ramageri: “Data Mining Techniques and
Applications”, Indian Journal of Computer Science and Engineering, Vol. 1 No. 4 301-305, ISSN : 0976-5166.
[3 ] B.N Lakshmi, G.H. Raghunandan: “A Conceptual Overview of
Data Mining”, Proc. National Conference on Innovation in Emerging Technology, 2011, pp. 27-32.
[4 ] Prasanna Kumara, Alok Ranjan : “Data Mining And Its Significance
In Industrial Applications”, International Journal of Advanced Research in Computer Science, 2012, Vol 3, No. 2, ISSN No. 0976-5697.
[5 ] Jochen Hipp, Ulrich Günter, and Udo Grimmer: “Data Quality
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 2, Issue 12, December 2012)
171
[6 ] Shelly Gupta, Dharminder Kumar, and Anand Sharma: Data Mining
Classification Techniques Applied for Breast Cancer Diagnosis and Prognosis, Indian Journal of Computer Science and Engineering (IJCSE), Vol. 2 No. 2 Apr-May 2011, ISSN : 0976-516, Pg. No : 188-195.
[7 ] Tan, Steinbach, Kumar : Data Mining Classification - on: Basic Concepts, Decision Trees, and Model Evaluation
[8 ] Data Mining with Decision Trees - Theory and Applications: World
Scientific Publishing Co. Pte. Ltd.
[9 ] Abbass, H.A., Towsey M., &Finn G. (2001). C-Net: “A Method for
Generating Nondeterministic and Dynamic Multivariate Decision Trees.” Knowledge and Information Systems: An International Journal, Springer-Verlag, 5(2).
[10 ]D. Shanthi, Dr. G. Sahoo, Dr. N. Saravanan: Decision Tree