PATTERN BASED EVALUATION FOR EXTRACTING
PERSONALIZED PROFILES
1
P. SATHVIK NAGA SAI, 2DR .P. SIVA KUMAR
1
Student., Department of Computer Science and Engineering, Kl University, INDIA 2
Assoc. Prof., Department of Computer Science and Engineering, Kl University, INDIA
E-mail: 1 [email protected],2 [email protected]
ABSTRACT
The customer server model, we display a point by point structural planning and outline execution of PMSE. In this configuration, customer accumulates and stores locally the explore data to secure protection, while substantial undertakings, for instance, thought extraction, get ready, and re situating are performed near PMSE server. PMSE altogether enhances the exactness contrasting with the benchmark. In the event that any system presents for enhancing the productivity of their relative system is being referred to examples also, travel examples getting to. In this paper, we propose CPHC (Classification by Pattern based Hierarchical Clustering), a semi-controlled grouping calculation that uses an example based bunch chain of command as an immediate implies for order. All preparation what's more, test occasions are initially bunched together utilizing an occurrence driven example based progressive grouping calculation that permits every case to "vote" for its agent size-2 designs in a way that adjusts neighborhood design centrality and worldwide example interestingness. These examples structure beginning groups and whatever is left of the bunch chain of command is acquired by taking after a remarkable iterative group refinement prepare that endeavors neighborhood data. The subsequent group progressive system is then utilized straightforwardly to characterize test cases, taking out the need to prepare a classifier on an upgraded preparing set. Our exploratory results appear productive preparing of each inquiry improvement in preparing data set.
Keywords: PMSE, CPHC, Cluster Chain Of Command, Group Refinement, Semi-Directed
Characterization
1. INTRODUCTION
Information mining is the principle application with incorporating required hunt information in
sensible information occasion administration
operations. Information extraction is the procedure of removing pertinent data from different information present in the information stockroom. Item investigation of the every client inclinations is the fundamental idea in present application improvement elements taking into account the client inclinations. The procedure of removing data from client arranged information sets with including the operations on the information accomplishments present arranged information sets. A percentage of the examination application advancement individuals may sort out the procedure of the location based search results of the client These results are with references to the technique of the of the area of every client. These
results are gotten business information
administration internet searcher application
advances with information levels of all the related information present in the built information base.
In this paper we propose to make proficient technique for extraction client points of interest in view of the hunt procedure of the every client secured information base. Consider the case of the taking care of units may accomplish information presentation in late application advancement we add to an application, it will consequently identify each preparing occasion in removed information set representation. For instance we hunt term i.e., Hotel at that point it will show area of lodging and after that likewise discover all the relative presents
present in the application procedure may
accomplish every one of the subtle elements of inn including inn booking and different operations present element server operations. For building up this application adequately we propose to add to a
customer server structural planning with
profitability of the preparing occasions
progressively application forms. These outcomes
are gotten extremely related information
Figure 1: Context Awareness In Application Development.
Personalized Mobile Search Engine explains the process of client server architecture which includes every one of the operations in late application improvement. In this application server keep up all the client/customer points of interest with reference operations present during the time spent application advancement. Customer sends solicitation to the server then server confirm customer solicitation
There is no unbiased "right" grouping calculation, yet as it was noted, "bunching is in the eye of the beholder."[2] The most proper grouping calculation for a specific issue regularly should be picked tentatively, unless there is a scientific motivation to favor one gathering model over another. It ought to be noticed that a calculation that is intended for one sort of model has no possibility on an data set that contains a profoundly diverse sort of model.[2] For instance, k-means can't discover non-arched bunches.
In the above diagram show efficient
communication of the each learning phase assessment process which includes efficient communication in each query representation which includes data process with required data. Our experimental results show efficient processing in query processing in relevant data search application development.
2. BACKGROUND APPROACH
Hassan H. Malik, and John R. Kender stated that The worldwide example mining venture in existing example based hierarchical clustering calculations may bring about an eccentric number of examples. In this paper, we propose IDHC, an example based various leveled grouping calculation that builds a group progressive system without digging for internationally huge patterns.IDHC permits every occasion to "vote" for its delegate size-2 designs in away that guarantees a compelling harmony in the middle of neighborhood and worldwide pattern significance. The quantity of examples chose for every
occurrence is dynamically determined utilizing a nearby standard deviation based plan rest of the, and the rest of progressive system is gotten by taking after an one of a kind iterative group refinement process.
Figure 2: Pattern Evaluation Of The Working Process.
By successfully using occurrence to-group
connections, this process directly recognizes groups for every level in the chain of command, and productively prunes duplicate groups. Besides, IDHC produces bunch marks that are more descriptive (examples are not falsely confined), and adjusts a delicate clustering scheme that permits examples to exist in suitable hubs at different levels in the cluster pecking order. We present aftereffects of trials performed on 16 standard text datasets, and demonstrate that IDHC quite often outflanks condition of-the -art various leveled grouping calculations as far as entropy, and accomplishes better F Scores much of the time, without requiring tuning of parameter
qualities. Jianyong Wang and George
Karypis stated that many studies have shown that rule-based classifiersperform well in classifying categorical and sparse high dimensional databases. However, a fundamental limitation with numerous principle based classifiers is that they discover the guidelines by employing various heuristic systems to prune the pursuit space, and select the rules based on the sequential database covering paradigm. Therefore, the last arrangement of standards that they utilize may not be the universally best guidelines for a few cases in the training database. To aggravate matters, these algorithms fail to fully exploit some more effective search space pruning methods inorder to scale to large databases.
high efficiency and great adaptability. Our careful execution study with some vast content and absolute databases has indicated that HARMONY beats some surely understood classifiers in terms of both accuracy and computational effectiveness, furthermore, scales well with the database size. Wenmin Li Jiawei Han Jian Pei expressed that past studies suggest that affiliated classification has high grouping precision and solid adaptability at handling unstructured information. On the other hand, despite everything it endures from the immense arrangement of mined guidelines and now and then one-sided classification or over fitting subsequent to the order depends on just single high-certainty principle. In this study, we propose another cooperative characterization technique, CMAR, i.e., Classification taking into account Multiple Association Rules. The technique expands an effective incessant example mining strategy, development, builds class dissemination related FP-tree, and mines vast database effectively. Besides, it applies a CR-tree structure to store and recover mined affiliation principles effectively, and prunes govern successfully taking into account certainty,
connection and database scope. The
characterization is performed in view of a weighted investigation utilizing numerous solid affiliation rules. Our broad tests on databases from UCI machine learning database vault demonstrate that CMAR is steady, profoundly compelling at classification of different sorts of databases and has better average order precision in correlation with CBA andC4.5. Besides, our execution study demonstrates that the technique is exceptionally productive and versatile in examination with other reported acquainted grouping techniques
Martin Ester expressed that Text grouping routines can be utilized to structure substantial arrangements of text or hypertext archives. The understood systems for text clustering, on the other hand, don't generally address the unique issues of text grouping: high dimensionality of the information, extremely huge size of the databases and understandability of the bunch
Portrayal. In this paper, we present a novel methodology which uses visit thing (term) sets for content grouping. Such incessant sets can be productively found utilizing calculations for association rule mining. To bunch in light of continuous term sets, we measure the common cover of frequent sets with respect to the sets
ofsupporting documents. We exhibit two
calculations for regular term-based substance clustering, FTC which makes level gathering's and HFTC for dynamic gathering. A test assessment on
traditional content reports on web records demonstrate that the proposed calculations get grouping's of similar quality essentially more productively than cutting edge content bunching calculations. Also, our strategies give a reasonable depiction of the found groups by their frequent term sets.
Bing Liu Wynne Hsu Yiming Ma stated that Classification principle mining expects to find a little set of rules careful classifier structures an exact classifier. Association guideline mining finds every one of the principles existing in the database that fulfill some base backing and minimum confidence guideline mining there is one and one and just foreordained target. In this paper, we
propose to coordinate these two mining
methodologies. The focusing so as to join is finished on mining an exceptional subset of affiliation rules, called class connection rules (CARs). (CARs). An efficient algorithm is additionally given for building a classifier in view of these of found CARs. Trial results demonstrate that the classifier constructed along these lines is, as a rule, more accurate than that produced by the best in class order systemC4.5. Moreover, this reconciliation tackles number of issues that exist in the present order frameworks.
3. PROBLEM STATEMENT
Plan for PMSE by embracing the meta inquiry approach which relies on upon one of the business web crawlers, for example, Google, Yahoo, or Bing, to perform a genuine pursuit..
A personalization structure that uses a client's substance inclinations and area inclinations and in addition the GPS areas in personalizing search results. The user profiles for specific users are stored on the PMSE customers, along these lines safeguarding security to the clients. PMSE has been prototyped with PMSE clients on the. The client profiles for specific clients are put away on the PMSE clients, in this way saving protection to the clients. PMSE has been prototyped with PMSE clients on the GOOGLE Server. PMSE joins a client's physical areas in the personalization process. We direct examinations to concentrate on
the impact of a client's GPS areas in
Figure 3: Procedure For Client Server Architecture
[image:4.612.314.526.340.549.2]PMSE profiles both of the client's substance and area inclinations in the philosophy based user profiles, which are consequently gained from the navigate and GPS data without requiring extra endeavors from the client .PMSE addresses this issue by controlling the measure of data in the customer's client profile being presented to the PMSE server utilizing two security parameters, which can control privacy smoothly, while keeping up great positioning quality..
Figure 4: Query Processing For The Keyword Hotel
PMSE fuses a client's physical areas in the personalization process. We lead investigations to think about the effect of a client's GPS areas in personalization.
4. SYSTEM IMPLEMENTATION
In this segment we depict the relations of the data request outline with reproduction of each development of the inquiry preparing late application improvement. For doing this work effectively we handle the area based pursuit process
by ascertaining the longitude and degree
representation process. The method actualize in
proposed methodology may accomplish
information handling operations with pertinent
information and doled out association
applications.
Figure 5: Relational Data Assets For Query Evaluation
This component may constitute the outcome
process in helpful also other semantic
representation.
This blend may perform successful representation of the inquiry design by gathering coordinated bunch with pertinent element taking
care of operations
Figure 6: Procedure For Query Evaluation By joining the operations of the information examination we handle seeking method by default extracting data values with sufficient and interactive data representation. By applying some inquiry bunching here we propose to create
productive handling in later application
development.
5. PERFOMANCE EVALUATION
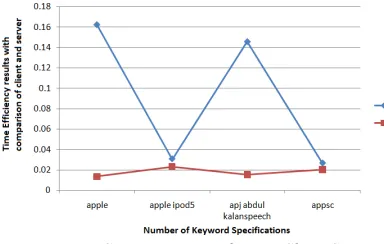
[image:4.612.93.305.346.451.2]of existing together preparing occasions, measuring them by hub design lengths (i.e., by duplicating the hub design interestingness esteem with the example length) to acquire class label(s) for the test occurrence. By Using CPHC we can order test examples and we can discard the enhanced get ready set.
Figure 7: Comparison Results For Client Server Architecture
By that outcomes can indicate productive preparing of every question streamlining in preparing data set.
For instance we submit to extricate diverse data sets present in the preparing application improvement. In this paper we make area hunt preparing with equivalent need sharing utilizing longitude and scope estimations of each query relevance pattern evaluation. As appeared in the above we access to create distinctive watchword search applications with relative data events and other progressive measurement operations. The resultant analysis of the query processing will take additional time many-sided quality when contrast with substance based inquiry process. This application procedure may close adequate and other element advancement of the each question accommodation.
In this circumstance of the advancement technique may close powerful and separating data from data base information base. We as of now store data as addition question representation of the every inquiry preparing.
6. CONCLUSION
The semi-regulated approach first groups both the preparation and test sets together into a solitary bunch pecking order, and after that uses this chain of importance as an immediate means for classification; this disposes of the need to prepare a classifier on an improved preparing set. What's more, this methodology utilizes a novel element determination system that guarantees that all training and test cases are secured by the chose
elements, utilizes parameters that are vigorous crosswise over datasets with shifting qualities, furthermore has the positive reaction of enhancing the possibilities of inducing so as to characterize disengaged test occasions on sparse training information a type of highlight transitivity. Ultimately, this methodology is exceptionally
powerful on extremely scanty preparing
information.
REFERENCES
[1]. Gathering counts from Wikipedia
[2]. Estivill-Castro, Vladimir (20 June 200202). " Why such an assortment of collection counts — A Position Paper". ACM SIGKDD
Explorations Newsletter 4 (1): 65–75.
doi:10.1145/568574.568575
[3].Malik, H. H., Kender, J. R.: Instance Driven
Hierarchical Clustering of Document
Collections. In: From Local Patterns to Global Models Workshop, European Conference on Machine Learning and Practice of Knowledge Discovery in Databases (2008).
[4].Wang, J., Karypis, G.: On Mining
Instance-Centric Classification Rules. IEEE
Transactions Knowledge and Data
Engineering, Volume 18, No. 11 (2006). [5].Li, W., Han, J., Pei, J.: CMAR: Accurate and
Efficient Classification taking into account multiple class-affiliation rules. In: First IEEE International Conference on Data Mining. [6].Beil, F., Ester, M., Xu, X.: Frequent term-based
content bunching. In: International Conference on Knowledge Discovery and Data Mining, pp. 436-442.
[7].Liu, B., Hsu, W., Ma, Y.: Integrating Classification and Association Rule Mining. In: Fourth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
[8]. Kyriakopoulou, A., Kalamboukis, T.: Using grouping to upgrade content order. In: 30th yearly worldwide ACM SIGIR gathering on Research and advancement in information recovery (2007).
[9]. Raskutti, B., Ferr, H., Kowalczyk, A.: Using unlabeled information for content order through addition of bunch parameters. In: ninth International Conference on Machine Learning. [10]. Zeng, H. J., Wang, X.H., Chen, Z., Lu, H., Ma,
W. Y.: CBC: Clustering based text