Based on Statistical D i s t r i b u t i o n s of
A r g u m e n t Structure
Paola
Merlo*
University of GenevaS u z a n n e S t e v e n s o n t University of Toronto
Automatic acquisition of lexical knowledge is critical to a wide range of natural language pro- cessing tasks. Especially important is knowledge about verbs, which are the primary source of relational information in a sentence--the predicate-argument structure that relates an action or state to its participants (i.e., who did what to whom). In this work, we report on super- vised learning experiments to automatically classify three major types of English verbs, based on their argument structure--specifically, the thematic roles they assign to participants. We use linguistically-motivated statistical indicators extracted from large annotated corpora to train the classifier, achieving 69.8% accuracy for a task whose baseline is 34%, and whose expert-based upper bound we calculate at 86.5%. A detailed analysis of the performance of the algorithm and of its errors con~'rms that the proposed features capture properties related to the argument struc- ture of the verbs. Our results validate our hypotheses that knowledge about thematic relations is crucial for verb classification, and that it can be gleaned from a corpus by automatic means. We thus demonstrate an effective combination of deeper linguistic knowledge with the robustness and scalability of statistical techniques.
1. Introduction
Automatic acquisition of lexical knowledge is critical to a wide range of natural lan- guage processing (NLP) tasks (Boguraev and Pustejovsky 1996). Especially important is knowledge about verbs, which are the primary source of relational information in a sentence--the predicate-argument structure that relates an action or state to its par- ticipants (i.e., who did what to whom). In facing the task of automatic acquisition of knowledge about verbs, two basic questions must be addressed:
What information about verbs and their relational properties needs to be learned?
What information can in practice be learned through automatic means?
In answering these questions, some approaches to lexical acquisition have focused on learning syntactic information about verbs, by automatically extracting subcategoriza- tion frames from a corpus or machine-readable dictionary (Brent 1993; Briscoe and Carroll 1997; Dorr 1997; Lapata 1999; Manning 1993; McCarthy and Korhonen 1998).
* Linguistics Department; University of Geneva; 2 rue de Candolle; 1211 Geneva 4, Switzerland; merlo@ lettres.unige.ch
Computational Linguistics Volume 27, Number 3
Table 1
Examples of verbs from the three optionally intransitive classes.
Unergative The horse raced past the barn.
The jockey raced the horse past the barn. Unaccusative The butter melted in the pan.
The cook melted the butter in the pan. Object-Drop The boy played.
The boy played soccer.
Other work has attempted to learn deeper semantic properties such as selectional re- strictions (Resnik 1996; Riloff and Schmelzenbach 1998), verbal aspect (Klavans and Chodorow 1992; Siegel 1999), or lexical-semantic verb classes such as those proposed b y Levin (1993) (Aone and McKee 1996; McCarthy 2000; Lapata and Brew 1999; Schulte im Walde 2000). In this paper, we focus on argument structure--the thematic roles as- signed by a verb to its arguments--as the w a y in which the relational semantics of the verb is represented at the syntactic level.
Specifically, our proposal is to automatically classify verbs based on argument structure properties, using statistical corpus-based methods. We address the prob- lem of classification because it provides a means for lexical organization which can effectively capture generalizations over verbs (Palmer 2000). Within the context of classification, the use of argument structure provides a finer discrimination among verbs than that induced b y subcategorization frames (as we see below in our example classes, which allow the same subcategorizations but differ in thematic assigmnent), but a coarser classification than that proposed b y Levin (in which classes such as ours are further subdivided according to more detailed semantic properties). This level of classification granularity appears to be appropriate for numerous language engineering tasks. Because knowledge of argument structure captures fundamental participant/event relations, it is crucial in parsing and generation (e.g., Srinivas and Joshi [1999]; Stede [1998]), in machine translation (Dorr 1997), and in information re- trieval (Klavans and Kan 1998) and extraction (Riloff and Schmelzenbach 1998). Our use of statistical corpus-based methods to achieve this level of classification is moti- vated b y our hypothesis that class-based differences in argument structure are reflected in statistics over the usages of the component verbs, and that those statistics can be automatically extracted from a large annotated corpus.
Table 2
Summary of thematic role assignments by class.
Transitive Intransitive
Classes Subject Object Subject
Unergative Agent (of Causation) Agent Agent Unaccusative Agent (of Causation) Theme Theme
Object-Drop Agent Theme Agent
The question then is what underlies these distinctions. We identify the property that precisely distinguishes among these three classes as that of argument structure-- i.e., the thematic roles assigned by the verbs. The thematic roles for each class, and their mapping to subject and object positions, are summarized in Table 2. Note that verbs across these three classes allow the same subcategorization frames (taking an NP object or occurring intransitively); thus, classification based on subcategorization alone would not distinguish them. On the other hand, each of the three classes is comprised of multiple Levin classes, because the latter reflect more detailed semantic distinctions among the verbs (Levin 1993); thus, classification based on Levin's labeling would miss generalizations across the three broader classes. By contrast, as shown in Table 2, each class has a unique pattern of thematic assignments, which categorize the verbs precisely into the three classes of interest.
Although the granularity of our classification differs from Levin's, we draw on her hypothesis that semantic properties of verbs are reflected in their syntactic behavior. The behavior that Levin focuses on is the notion of diathesis alternation--an alter- nation in the expression of the arguments of a verb, such as the different mappings between transitive and intransitive that our verbs undergo. Whether a verb partici- pates in a particular diathesis alternation or not is a key factor in Levin's approach to classification. We, like others in a computational framework, have extended this idea by showing that statistics over the alternants of a verb effectively capture information about its class (Lapata 1999; McCarthy 2000; Lapata and Brew 1999).
In our specific task, we analyze the pattern of thematic assignments given in Table 2 to develop statistical indicators that are able to determine the class of an op- tionally intransitive verb by capturing information across its transitive and intransitive alternants. These indicators serve as input to a machine learning algorithm, under a supervised training methodology, which produces an automatic classification system for our three verb classes. Since we rely on patterns of behavior across multiple occur- rences of a verb, we begin with the problem of assigning a single class to the entire set of usages of a verb within the corpus. For example, we measure properties across all occurrences of a word, such as raced, in order to assign a single classification to the lexical entry for the verb race. This contrasts with work classifying individual oc- currences of a verb in each local context, which have typically relied on training that includes instances of the verbs to be classified--essentially developing a bias that is used in conjunction with the local context to determine the best classification for new instances of previously seen verbs. By contrast, our method assigns a classification to verbs that have not previously been seen in the training data. Thus, while we do not as yet assign different classes to the instances of a verb, we can assign a single predominant class to new verbs that have never been encountered.
[image:3.468.34.419.93.167.2]Computational Linguistics Volume 27, Number 3
rate in this classification task by more than 50% over chance. Specifically, we achieve almost 70% accuracy in a task whose baseline (chance) performance is 34%, and whose expert-based u p p e r b o u n d is calculated at 86.5%.
Beyond the interest for the particular classification task at hand, this work ad- dresses more general issues concerning verb class distinctions based in argument structure. We evaluate our hypothesis that such distinctions are reflected in statis- tics over corpora through a computational experimental methodology in which we investigate as indicated each of the subhypotheses below, in the context of the three verb classes under study:
• Lexical features capture argument structure differences between verb classes. 1
• The linguistically distinctive features exhibit distributional differences across the verb classes that are apparent within linguistic experience (i.e., they can be collected from text).
• The statistical distributions of (some of) the features contribute to learning the classifications of the verbs.
In the following sections, we show that all three hypotheses above are borne out. In Section 2, we describe the argument structure distinctions of our three verb classes in more detail. In support of the first hypothesis above, we discuss lexical correlates of the underlying differences in thematic assignments that distinguish the three verb classes u n d e r investigation. In Section 3, we show how to approximate these features b y simple syntactic counts, and h o w to perform these counts on available corpora. We confirm the second hypothesis above, by showing that the differences in distribution predicted by the underlying argument structures are largely found in the data. In Section 4, in a series of machine learning experiments and a detailed analysis of errors, we confirm the third hypothesis b y showing that the differences in the distribution of the extracted features are successfully used for verb classification. Section 5 evaluates the significance of these results by comparing the program's accuracy to an expert- based u p p e r bound. We conclude the paper with a discussion of its contributions, comparison to related work, and suggestions for future extensions.
2. Deriving Classification Features from Argument Structure
Our task is to automatically build a classifier that can distinguish the three major classes of optionally intransitive verbs in English. As described above, these classes are differentiated by their argument structures. In the first subsection below, we elab- orate on our description of the thematic role assignments for each of the verb classes under investigation--unergative, unaccusative, and object-drop. This analysis yields a distinctive pattern of thematic assignment for each class. (For more detailed discussion concerning the linguistic properties of these classes, and the behavior of their compo- nent verbs, please see Stevenson and Merlo [1997b]; Merlo and Stevenson [2000b].)
Of course, the key to any automatic classification task is to determine a set of useful features for discriminating the items to be classified. In the second subsection below,
1 By lexical we mean features that we think are likely stored in the lexicon, because they are properties of words and not of phrases or sentences. Note, however, that some lexical features may not
we show how the analysis of thematic distinctions enables us to determine lexical properties that we hypothesize will exhibit useful, detectable frequency differences in our corpora, and thus serve as the machine learning features for our classification experiments.
2.1 The Argument Structure Distinctions
The verb classes are exemplified below, in sentences repeated from Table 1 for ease of exposition.
Unergative: (la) The horse raced past the barn.
(lb) The jockey raced the horse past the barn.
Unaccusative: (2a) The butter melted in the pan.
(2b) The cook melted the butter in the pan.
Object-Drop: (3a) The boy played.
(3b) The boy played soccer.
The example sentences illustrate that all three classes participate in a diathesis alter- nation that relates a transitive and intransitive form of the verb. However, according to Levin (1993), each class exhibits a different type of diathesis alternation, which is determined by the particular semantic relations of the arguments to the verb. We make these distinctions explicit by drawing on a standard notion of thematic role, as each class has a distinct pattern of thematic assignments (i.e., different argument structures). We assume here that a thematic role is a label taken from a fixed inventory of grammaticalized semantic relations; for example, an Agent is the doer of an action, and a Theme is the entity undergoing an event (Gruber 1965). While admitting that such notions as Agent and Theme lack formal definitions (in our work and in the literature more widely), the distinctions are clear enough to discriminate our three verb classes. For our purposes, these roles can simply be thought of as semantic labels which are non-decomposable, but there is nothing in our approach that rests on this assumption. Thus, our approach would also be compatible with a feature-based deft- nition of participant roles, as long as the features capture such general distinctions as, for example, the doer of an action and the entity acted upon (Dowty 1991).
Note that in our focus on verb class distinctions we have not considered finer- grained features that rely on more specific semantic features, such as, for example, that the subject of the intransitive m e l t must be something that can change from solid to liquid. While this type of feature m a y be important for semantic distinctions among individual verbs, it thus far seems irrelevant to the level of verb classification that we adopt, which groups verbs more broadly according to syntactic and (somewhat coarser-grained) semantic properties.
Computational Linguistics Volume 27, Number 3
Table 3
Summary of thematic assignments.
Transitive Intransitive
Classes Subject Object Subject
Unergative Agent (of Causation) Agent Agent Unaccusative Agent (of Causation) Theme Theme
Object-Drop Agent Theme Agent
introduced with the causing event. In a causative alternation, the semantic argument of the subject of the intransitive surfaces as the object of the transitive (Brousseau and Ritter 1991; Hale and Keyser 1993; Levin 1993; Levin and Rappaport H o v a v 1995). For unergatives, this argument is an Agent and thus the alternation yields an object in the transitive form that receives an Agent thematic role (Cruse 1972). These thematic assignments are shown in the first row of Table 3.
The sentences in (2) illustrate the corresponding forms of an unaccusative verb,
melt.
Unaccusatives are intransitive change-of-state verbs, as in (2a); the transitive counterpart for these verbs also exhibits a causative alternation, as in (2b). This is the "causative/inchoative alternation" (Levin, 1993). Like unergatives, the subject of a transitive unaccusative is marked as the Agent of Causation. Unlike unergatives, though, the alternating argument of an unaccusative (the subject of the intransitive form that becomes the object of the transitive) is an entity undergoing a change of state, without active participation, and is therefore a Theme. The resulting pattern of thematic assignments is indicated in the second row of Table 3.The sentences in (3) use an object-drop verb,
play.
These are activity verbs that exhibit a non-causative diathesis alternation, in which the object is simply optional. This is dubbed "the unexpressed object alternation" (Levin 1993), and has several subtypes that we do not distinguish here. The thematic assignment for these verbs is simply Agent for the subject (in both transitive and intransitive forms), and Theme for the optional object; see the last row of Table 3.For further details and support of this analysis, please see the discussion in Steven- son and Merlo (1997b) and Merlo and Stevenson (2000b). For our purposes here, the important fact to note is that each of the three classes can be uniquely identified by the pattern of thematic assignments across the two alternants of the verbs.
2.2 Features for A u t o m a t i c Classification
Our next task then is to derive, from these thematic patterns, useful features for au- tomatically classifying the verbs. In what follows, we refer to the columns of Table 3 to explain h o w we expect the thematic distinctions to give rise to distributional prop- erties, which, when appropriately approximated through corpus counts, will discrim- inate across the three classes.
Transitivity
Consider the first two columns of thematic roles in Table 3, which illus- trate the role assignment in the transitive construction. The Prague school's notion of linguistic markedness (Jakobson 1971; Trubetzkoy 1939) enables us to establish a scale of markedness of these thematic assignments and make a principled prediction about their frequency of occurrence. Typical tests to determine the unmarked element of a pair or scale are simplicity--the unmarked element is simpler, d i s t r i b u t i o n - - t h emarked member is more frequent (Greenberg 1966; Moravcsik and Wirth 1983). The claim of markedness theory is that, once an element has been identified by one test as the unmarked element of a scale, then all other tests will be correlated. The three thematic assignments appear to be ranked on a scale by the simplicity and distribu- tion tests, as we describe below. From this, we can conclude that frequency, as a third correlated test, should also be ranked by the same scale, and we can therefore make predictions about the expected frequencies of the three thematic assignments.
First, we note that the specification of an Agent of Causation for transitive unerga- tives (such as
race)
and unaccusatives (such asmelt)
indicates a causative construction. Causative constructions relate two events, the causing event and the core event de- scribed by the intransitive verb; the Agent of Causation is the Agent of the causing event. This double event structure can be considered as more complex than the sin- gle event that is found in a transitive object-drop verb (such asplay)
(Stevenson and Merlo 1997b). The simplicity test thus indicates that the causative unergatives and unaccusatives are marked in comparison to the transitive object-drop verbs.We further observe that the causative transitive of an unergative verb has an Agent thematic role in object position which is subordinated to the Agent of Causation in subject position, yielding an unusual "double agentive" thematic structure. This lex- ical causativization of unergatives (in contrast to analytic causativization) is a distri- butionally rarer p h e n o m e n o n - - f o u n d in fewer languages--than lexical causatives of unaccusatives. In asking native speakers about our verbs, we have found that lexical causatives of unergative verbs are not attested in Italian, French, German, Portuguese, Gungbe (Kwa family), and Czech. On the other hand, the lexical causatives are pos- sible for unaccusative verbs (i.e., where the object is a Theme) in all these languages. Vietnamese appears to allow a very restricted form of causativization of unergatives limited to only those cases that have a comitative reading. The typological distribu- tion test thus indicates that unergatives are more marked than unaccusatives in the transitive form.
From these observations, we can conclude that unergatives (such as
race)
have the most marked transitive argument structure, unaccusatives (such asmelt)
have an intermediately marked transitive argument structure, and object-drops (such asplay)
have the least marked transitive argument structure of the three. Under the assumptions of markedness theory outlined above, we then predict that unergatives are the least frequent in the transitive, that unaccusatives have intermediate frequency in the transitive, and that object-drop verbs are the most frequent in the transitive.Causativity
Due to the causative alternation of unergatives and unaccusatives, the thematic role of thesubject
of the intransitive is identical to that of theobject
of the transitive, as shown in the second and third columns of thematic roles in Table 3. Given the identity of thematic role mapped to subject and object positions across the two alternants, we expect to observe the same noun occurring at times as subject of the verb, and at other times as object of the verb. In contrast, for object-drop verbs, the thematic role of the subject of the intransitive is identical to that of the subject of the transitive, not the object of the transitive. We therefore expect that it will be less common for the same noun to occur in subject and object position across instances of the same object-drop verb.Computational Linguistics Volume 27, Number 3
our case, the object-drop verbs). H o w e v e r , since the causative is a transitive use, a n d the transitive use of unergatives is expected to be rare (see above), w e d o not expect unergatives to exhibit a high degree of detectable overlap in a corpus. Thus, this over- lap of subjects a n d objects s h o u l d p r i m a r i l y distinguish unaccusatives (predicted to h a v e high o v e r l a p of subjects a n d objects) from the other t w o classes (each of w h i c h is p r e d i c t e d to h a v e low [detectable] o v e r l a p of subjects a n d objects).
Animacy Finally, considering the roles in the first a n d last c o l u m n s of thematic assign- m e n t s in Table 3, w e observe that u n e r g a t i v e a n d object-drop v e r b s assign an agentive role to their subject in b o t h the transitive a n d intransitive, w h i l e unaccusatives assign an agentive role to their subject only in the transitive. U n d e r the a s s u m p t i o n that the intransitive use of unaccusatives is not rare, w e t h e n expect that unaccusatives will occur less often overall w i t h an agentive subject t h a n will the other t w o v e r b classes. (The a s s u m p t i o n that unaccusatives are n o t rare in the intransitive is b a s e d o n the linguistic c o m p l e x i t y of the causative transitive alternant, a n d is b o r n e out in o u r cor- p u s analysis.) O n the f u r t h e r a s s u m p t i o n that Agents t e n d to be animate entities m o r e so t h a n T h e m e s are, w e expect that unaccusatives will occur less f r e q u e n t l y w i t h an animate subject c o m p a r e d to u n e r g a t i v e a n d object-drop verbs. N o t e the i m p o r t a n c e of o u r use of f r e q u e n c y distributions: the claim is not that o n l y Agents can be animate, b u t rather that n o u n s that receive an A g e n t role will m o r e often be animate t h a n n o u n s that receive a T h e m e role.
Additional Features The a b o v e interactions b e t w e e n thematic roles a n d the syntactic expressions of a r g u m e n t s thus lead to three features w h o s e distributional p r o p e r t i e s a p p e a r p r o m i s i n g for distinguishing unergative, u n a c c u s a t i v e a n d object-drop verbs: transitivity, causativity, a n d a n i m a c y of subject. We also investigate t w o additional syn- tactic features: the use of the passive or active voice, a n d the use of the past participle or simple past part-of-speech (POS) tag (VBN or VBD, in the P e n n Treebank style). These features are related to the t r a n s i t i v e / i n t r a n s i t i v e alternation, since a passive use implies a transitive use of the verb, as well as to the use of a past participle f o r m of the v e r b . 2
Table 4 s u m m a r i z e s the features w e derive f r o m the thematic properties, a n d o u r expectations c o n c e r n i n g their f r e q u e n c y of use. We h y p o t h e s i z e that these five features will exhibit distributional differences in the o b s e r v e d usages of the verbs that can be u s e d for classification. In the next section, w e describe the actual c o r p u s counts that w e d e v e l o p to a p p r o x i m a t e the features w e h a v e identified. (Notice that the counts will be imperfect a p p r o x i m a t i o n s to the thematic k n o w l e d g e , b e y o n d the inevitable errors d u e to automatic extraction f r o m large automatically a n n o t a t e d corpora. E v e n w h e n the counts are precise, they o n l y constitute an a p p r o x i m a t i o n to the actual thematic notions, since the features w e are using are not logically i m p l i e d b y the k n o w l e d g e w e w a n t to capture, b u t only statistically correlated.)
3. Data Collection and Analysis
Clearly, some of the features w e ' v e p r o p o s e d are difficult (e.g., the passive use) or im- possible (e.g., a n i m a t e subject use) to automatically extract w i t h h i g h accuracy f r o m a
Table 4
The features and expected behavior.
Expected Frequency
Feature Pattern Explanation
Transitivity Unerg < Unacc < ObjDrop Unaccusatives and unergatives have a causative
transitive, hence lower transitive use. Further- more, unergatives have an agentive object, hence very low transitive use.
Causativity Unerg, ObjDrop < Unacc Object-drop verbs do not have a causal agent,
hence low "causative" use. Unergatives are rare in the transitive, hence low causative use.
Animacy Unacc < Unerg, ObjDrop Unaccusatives have a Theme subject in the in-
transitive, hence lower use of animate subjects.
Passive Voice Unerg K Unacc K ObjDrop Passive implies transitive use, hence correlated
with transitive feature.
VBN Tag Unerg < Unacc < ObjDrop Passive implies past participle use (VBN), hence
correlated with transitive (and passive).
large corpus, given the current state of annotation. H o w e v e r , w e do a s s u m e that cur- rently available corpora, such as the Wall Street Journal (WSJ), p r o v i d e a representative, a n d large e n o u g h , sample of l a n g u a g e from w h i c h to gather c o r p u s counts that can ap- proximate the distributional patterns of the verb class alternations. O u r w o r k d r a w s on t w o text c o r p o r a - - o n e an automatically t a g g e d c o m b i n e d c o r p u s of 65 million w o r d s (primarily WSJ), the second an automatically p a r s e d c o r p u s of 29 million w o r d s (a sub- set of the WSJ text from the first corpus). Using these corpora, w e d e v e l o p c o u n t i n g p r o c e d u r e s that yield relative f r e q u e n c y distributions for a p p r o x i m a t i o n s to the five linguistic features w e h a v e determined, over a sample of verbs f r o m o u r three classes.
3.1 Materials and M e t h o d
We chose a set of 20 verbs f r o m each class b a s e d p r i m a r i l y on the classification in Levin (1993). 3 The complete list of verbs a p p e a r s in Table 5; the g r o u p 1 / g r o u p 2 designation is explained b e l o w in the section on counting. As indicated in the table, unergatives are m a n n e r - o f - m o t i o n verbs (from the " r u n " class in Levin), unaccusatives are change- of-state verbs (from several of the classes in Levin's change-of-state super-class), while object-drop verbs were taken from a variety of classes in Levin's classification, all of w h i c h u n d e r g o the u n e x p r e s s e d object alternation. The m o s t frequently u s e d classes are verbs of change of possession, image-creation verbs, a n d verbs of creation a n d transformation. The selection of verbs w a s based partly on o u r intuitive j u d g m e n t that the verbs were likely to be used w i t h sufficient f r e q u e n c y in the WSJ. Also, each
3 We used an equal number of verbs from each class in order to have a balanced group of items. One potential disadvantage of this decision is that each verb class is represented equally, even though they may not be equally frequent in the corpora. Although we lose the relative frequency information among the classes that could provide a better bias for assigning a default classification (i.e., the most frequent one), we have the advantage that our classifier will be equally informed (in terms of number of exemplars) about each class.
Note that there are only 19 unaccusative verbs because ripped, which was initially counted in the
unaccusatives, was then excluded from the analysis as it occurred mostly in a very different usage in
Computational Linguistics Volume 27, Number 3
Table 5
Verbs used in the experiments.
Class Name Description Selected Verbs
Unergative manner of motion
jumped, rushed, marched, leaped, floated, raced, hurried, wan-
dered, vaulted, paraded
(group 1);galloped, glided, hiked,
hopped, jogged, scooted, scurried, skipped, tiptoed, trotted
(group 2).
Unaccusative change of state
opened, exploded, flooded, dissolved, cracked, hardened, boiled,
melted, fractured, solidified
(group 1);collapsed, cooled,
folded, widened, changed, cleared, divided, simmered, stabi-
lized
(group 2).Object-Drop unexpressed
object alternation
played, painted, kicked, carved, reaped, washed, danced,
yelled, typed, knitted
(group 1);borrowed, inherited, orga-
nized, rented, sketched, cleaned, packed, studied, swallowed,
called
(group 2).verb presents the same f o r m in the simple past a n d in the past participle (the reg- ular "-ed" form). In order to simplify the c o u n t i n g p r o c e d u r e , w e i n c l u d e d o n l y the "-ed" f o r m of the verb, o n the a s s u m p t i o n that counts o n this single verb f o r m w o u l d a p p r o x i m a t e the distribution of the features across all forms of the verb. Additionally, as far as w e were able g i v e n the p r e c e d i n g constraints, w e selected verbs that c o u l d occur in the transitive a n d in the passive. Finally, w e a i m e d for a f r e q u e n c y cut-off of 10 occurrences or m o r e for each verb, a l t h o u g h for unergatives w e h a d to use one
verb
(jogged)
that o n l y o c c u r r e d 8 times in order to h a v e 20 verbs that satisfied theother criteria above.
In p e r f o r m i n g this kind of c o r p u s analysis, one has to recognize the fact that current c o r p u s annotations d o not distinguish verb senses. In these counts, w e did n o t distinguish a core sense of the verb f r o m an e x t e n d e d use of the verb. So, for
instance, the sentence
Consumer spending jumped 1.7% in February after a sharp drop the
month before
(WSJ 1987) is c o u n t e d as an occurrence of the m a n n e r - o f - m o t i o n verbjump
in its intransitive form. This particular sense extension has a transitive alternant, b u t
n o t a causative transitive (i.e.,
Consumer spending jumped the barrier
. . . . b u t n o tLow taxes
jumped consumer spending... ).
Thus, while the possible subcategorizations r e m a i n the same, rates of transitivity a n d causativity m a y be different t h a n for the literal m a n n e r - o f - m o t i o n sense. This is an u n a v o i d a b l e result of u s i n g simple, a u t o m a t i c extraction m e t h o d s given the current state of a n n o t a t i o n of corpora.For each occurrence of each verb, w e c o u n t e d w h e t h e r it w a s in a transitive or intransitive use (TRANS), in a passive or active use (PASS), in a past participle or simple past use (VBN), in a causative or n o n - c a u s a t i v e use (CAUS), a n d w i t h an animate subject or n o t (ANIM). 4 N o t e that, except for the VBN feature, for w h i c h w e s i m p l y extract the POS tag f r o m the corpus, all other counts are a p p r o x i m a t i o n s to the actual linguistic b e h a v i o u r of the verb, as w e describe in detail below.
4 One additional feature was recorded--the log frequency of the verb in the 65 million word
[image:10.468.50.436.90.251.2]The first three c o u n t s (TRANS, PASS, VBN) were p e r f o r m e d on the t a g g e d A C L / D C I c o r p u s available f r o m the Linguistic Data C o n s o r t i u m , w h i c h includes the B r o w n Cor- p u s (of o n e million w o r d s ) a n d y e a r s 1987-1989 of the Wall Street Journal, a c o m b i n e d c o r p u s in excess of 65 million w o r d s . The counts for these features p r o c e e d e d as fol- lows:
• TRANS: A n u m b e r , a p r o n o u n , a determiner, an adjective, or a n o u n w e r e c o n s i d e r e d to be indication of a potential object of the verb. A v e r b occurrence p r e c e d e d b y f o r m s of the v e r b
be,
or i m m e d i a t e l y f o l l o w e d b y a p o t e n t i a l object w a s c o u n t e d as transitive; otherwise, the occurrence w a s c o u n t e d as intransitive (specifically, if the v e r b w a s f o l l o w e d b y a p u n c t u a t i o n s i g n - - c o m m a s , colons, full s t o p s - - o r b y a conjunction, a particle, a date, or a preposition.)* PASS: A m a i n v e r b (i.e., t a g g e d VBD) w a s c o u n t e d as active. A t o k e n w i t h tag VBN w a s also c o u n t e d as active if the closest p r e c e d i n g auxiliary w a s
have,
while it w a s c o u n t e d as p a s s i v e if the closest p r e c e d i n g auxiliary w a sbe.
• VBN: The counts for V B N / V B D w e r e s i m p l y d o n e b a s e d on the POS label w i t h i n the t a g g e d corpus.
Each of the a b o v e three counts w a s n o r m a l i z e d o v e r all occurrences of the " - e d " f o r m of the verb, yielding a single relative f r e q u e n c y m e a s u r e for each v e r b for that feature; i.e., p e r c e n t transitive (versus intransitive) use, p e r c e n t active (versus passive) use, a n d p e r c e n t VBN (versus VBD) use, respectively.
The last t w o c o u n t s (CAUS a n d ANIM) were p e r f o r m e d on a p a r s e d v e r s i o n of the 1988 y e a r of the Wall Street Journal, so that w e could extract subjects a n d objects of the v e r b s m o r e accurately. This c o r p u s of 29 million w o r d s w a s p r o v i d e d to us b y Michael Collins, a n d w a s a u t o m a t i c a l l y p a r s e d w i t h the p a r s e r d e s c r i b e d in Collins (1997). 5 The counts, a n d their justification, are described here:
CAUS: As d i s c u s s e d above, the object of a causative transitive is the s a m e s e m a n t i c a r g u m e n t of the v e r b as the subject of the intransitive. The c a u s a t i v e feature w a s a p p r o x i m a t e d b y the following steps, i n t e n d e d to c a p t u r e the d e g r e e to w h i c h the subject of a v e r b can also occur as its object. Specifically, for each v e r b occurrence, the subject a n d object (if there w a s one) w e r e extracted f r o m the p a r s e d corpus. The o b s e r v e d subjects across all occurrences of the v e r b w e r e p l a c e d into o n e m u l t i s e t of n o u n s , a n d the o b s e r v e d objects into a second m u l t i s e t of nouns. (A multiset, or bag, w a s u s e d so that o u r r e p r e s e n t a t i o n indicated the n u m b e r of times each n o u n w a s u s e d as either subject or object.) Then, the p r o p o r t i o n of o v e r l a p b e t w e e n the t w o multisets w a s calculated. We define o v e r l a p as the largest m u l t i s e t of e l e m e n t s b e l o n g i n g to b o t h the
Computational Linguistics Volume 27, Number 3
subject and the object multisets; e.g., the overlap between (a, a, a, b} and {a} is
{a,a,a}.
The proportion is the ratio between the cardinality of the overlap multiset, and the sum of the cardinality of the subject and object multisets. For example, for the simple sets of characters above, the ratio would be 3/5, yielding a value of .60 for the CAUS feature.ANIM: A problem with a feature like animacy is that it requires either manual determination of the animacy of extracted subjects, or reference to an on-line resource such as WordNet for determining animacy. To approximate animacy with a feature that can be extracted automatically, and without reference to a resource external to the corpus, we take advantage of the well-attested animacy hierarchy, according to which pronouns are the most animate (Silverstein 1976; Dixon 1994). The hypothesis is that the words
I, we, you, she, he,
andthey
most often refer to animate entities. This hypothesis was confirmed by extracting 100 occurrences of the pronounthey,
which can be either animate or inanimate, from our 65 million word corpus. The occurrences immediately preceded a verb. After eliminating repetitions,94 occurrences were left, which were classified by hand, yielding 71 animate pronouns, 11 inanimate pronouns and 12 unclassified
occurrences (for lack of sufficient context to recover the antecedent of the pronoun with certainty). Thus, at least 76% of usages of
they
were animate; we assume the percentage of animate usages of the other pronouns to be even higher. Since the hypothesis was confirmed, we count pronouns (other thanit) in
subject position (Kariaeva [1999]; cf. Aone and McKee [1996]). The values for the feature were determined by automatically extracting all subject/verb tuples including our 59 example verbs from the parsed corpus, and computing the ratio of occurrences of pronoun subjects to all subjects for each verb.Finally, as indicated in Table 5, the verbs are designated as belonging to "group 1" or "group 2". All the verbs are treated equally in our data analysis and in the machine learning experiments, but this designation does indicate a difference in details of the counting procedures described above. The verbs in group I had been used in an earlier study in which it was important to minimize noisy data (Stevenson and Merlo 1997a), so they generally underwent greater manual intervention in the counts. In adding group 2 for the classification experiment, we chose to minimize the intervention in order to demonstrate that the classification process is robust enough to withstand the resulting noise in the data.
Table 6
Aggregated relative frequency data for the five features. E = unergatives, A = unaccusatives, O = object-drops.
TRANS PASS VBN CAUS ANIM
Class N Mean SD Mean SD Mean SD Mean SD Mean SD
E 20 0.23 0.23 0.07 0.12 0.21 0.26 0.00 0.00 0.25 0.24 A 19 0.40 0.24 0.33 0.27 0.65 0.27 0.12 0.14 0.07 0.09 O 20 0.62 0.25 0.31 0.26 0.65 0.23 0.04 0.07 0.15 0.14
These w e r e collected a n d classified b y h a n d as p a s s i v e or active b a s e d on intuition. Similarly, partial a d j u s t m e n t s to the VBN counts w e r e m a d e b y h a n d .
For the c a u s a t i v i t y feature, subjects a n d objects w e r e d e t e r m i n e d b y m a n u a l in- spection of the c o r p u s for v e r b s b e l o n g i n g to g r o u p 1, while t h e y w e r e extracted a u t o m a t i c a l l y f r o m the p a r s e d c o r p u s for g r o u p 2. The g r o u p 1 v e r b s w e r e s a m p l e d in three w a y s , d e p e n d i n g on total frequency. For v e r b s w i t h less t h a n 150 occurrences, all instances of the v e r b s w e r e u s e d for s u b j e c t / o b j e c t extraction. For v e r b s w h o s e total f r e q u e n c y w a s greater t h a n 150, b u t w h o s e VBD f r e q u e n c y w a s in the r a n g e 100-200, w e extracted subjects a n d objects of the VBD occurrences only. For h i g h e r f r e q u e n c y verbs, w e u s e d o n l y the first 100 VBD occurrences. 6 The s a m e script for c o m p u t i n g the o v e r l a p of the extracted subjects a n d objects w a s t h e n u s e d on the resulting s u b j e c t / v e r b a n d v e r b / o b j e c t tuples for b o t h g r o u p 1 a n d g r o u p 2 verbs.
T h e a n i m a c y feature w a s calculated o v e r s u b j e c t / v e r b tuples extracted a u t o m a t i - cally for b o t h g r o u p s of v e r b s f r o m the p a r s e d corpus.
3.2 Data Analysis
The d a t a collection described a b o v e yields the following data points in total: TRANS:
27403; PASS: 20481; VBN: 36297; CAt;S: 11307; ANIM: 7542. (Different features yield differ- ent totals b e c a u s e t h e y w e r e s a m p l e d i n d e p e n d e n t l y , a n d the search p a t t e r n s to extract s o m e features are m o r e i m p r e c i s e t h a n others.) The a g g r e g a t e m e a n s b y class of the n o r m a l i z e d frequencies for all v e r b s are s h o w n in Table 6; i t e m b y i t e m distributions are p r o v i d e d in A p p e n d i x A, a n d r a w counts are available f r o m the authors. N o t e that a g g r e g a t e m e a n s are s h o w n for illustration p u r p o s e s o n l y - - a l l m a c h i n e l e a r n i n g e x p e r i m e n t s are p e r f o r m e d on the i n d i v i d u a l n o r m a l i z e d frequencies for each verb, as g i v e n in A p p e n d i x A.
The o b s e r v e d distributions of each feature are i n d e e d r o u g h l y as e x p e c t e d accord- ing to the d e s c r i p t i o n in Section 2. U n e r g a t i v e s s h o w a v e r y l o w relative f r e q u e n c y of the TRANS feature, f o l l o w e d b y unaccusatives, t h e n object-drop verbs. U n a c c u s a t i v e v e r b s s h o w a h i g h f r e q u e n c y of the CAUS feature a n d a l o w f r e q u e n c y of the ANIM fea- ture c o m p a r e d to the other classes. S o m e w h a t unexpectedly, object-drop v e r b s exhibit a n o n - z e r o m e a n CAUS v a l u e (almost half the v e r b s h a v e a CAUS v a l u e greater t h a n zero), l e a d i n g to a t h r e e - w a y c a u s a t i v e distinction a m o n g the v e r b classes. We s u s p e c t that the a p p r o x i m a t i o n that w e u s e d for causative u s e - - t h e o v e r l a p b e t w e e n subjects
Computational Linguistics Volume 27, Number 3
Table 7
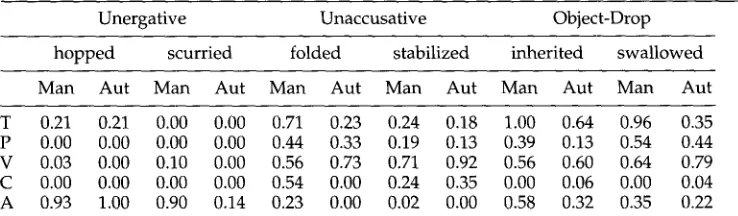
Manually (Man) and automatically (Aut) calculated features for a random sample of verbs.
T -~- T R A N S , P = P A S S , V ---- V B N , C -~ C A U S , A = A N I M .
Unergative Unaccusative Object-Drop
hopped scurried folded stabilized inherited swallowed
Man Aut Man Aut Man Aut Man Aut Man Aut Man Aut
T 0.21 0 . 2 1 0.00 0.00 0 . 7 1 0.23 0.24 0.18 1.00 0.64 0.96 0.35 P 0.00 0.00 0.00 0.00 0.44 0.33 0.19 0.13 0.39 0.13 0.54 0.44 V 0.03 0.00 0.10 0.00 0.56 0.73 0 . 7 1 0.92 0.56 0.60 0.64 0.79 C 0.00 0.00 0.00 0.00 0.54 0.00 0.24 0.35 0.00 0.06 0.00 0.04 A 0.93 1.00 0.90 0.14 0.23 0.00 0.02 0.00 0.58 0.32 0.35 0.22
and objects for a v e r b - - a l s o captures a "reciprocity" effect for some object-drop verbs (such as
call),
in w h i c h subjects a n d objects can be similar t y p e s of entities. Finally, a l t h o u g h e x p e c t e d to be a r e d u n d a n t indicator of transitivity, PASS a n d VBN, unlike TRANS, h a v e v e r y similar values for u n a c c u s a t i v e a n d object-drop verbs, indicating that their distributions are sensitive to factors w e h a v e not yet investigated.One issue w e m u s t address is h o w precisely the automatic counts reflect the actual linguistic b e h a v i o u r of the verbs. That is, w e m u s t b e assured that the patterns w e note in the data in Table 6 are accurate reflections of the differential b e h a v i o u r of the verb classes, a n d not an artifact of the w a y in w h i c h w e estimate the features, or a result of inaccuracies in the counts. In o r d e r to evaluate the accuracy of o u r feature counts, w e selected t w o verbs f r o m each class, a n d d e t e r m i n e d the " t r u e " v a l u e of each feature for each of those six v e r b s t h r o u g h m a n u a l counting. The six v e r b s w e r e r a n d o m l y selected f r o m the g r o u p 2 subset of the verbs, since counts for g r o u p 2 v e r b s (as explained above) h a d not u n d e r g o n e m a n u a l correction. This allows us to d e t e r m i n e the accuracy of the fully automatic c o u n t i n g procedures. The selected v e r b s (and their frequencies) are:
hopped
(29),scurried
(21),folded
(189),stabilized
(286),inherited
(357),swallowed
(152). For verbs that h a d a f r e q u e n c y of o v e r 100 in the " - e d " form, w e p e r f o r m e d the m a n u a l counts o n the first 100 occurrences.Table 7 s h o w s the results of the m a n u a l counts, r e p o r t e d as p r o p o r t i o n s to facil- itate c o m p a r i s o n to the n o r m a l i z e d automatic counts, s h o w n in adjoining columns. We observe first that, overall, most errors in the automatic counts occur in the unac- cusative a n d object-drop verbs. While tagging errors affect the VBN feature for all of the v e r b s s o m e w h a t , w e note that TP~ANS a n d PaSS are consistently u n d e r e s t i m a t e d for unaccusative a n d object-drop verbs. These errors m a k e the u n a c c u s a t i v e a n d object- d r o p feature values m o r e similar to each other, a n d therefore potentially h a r d e r to distinguish. F u r t h e r m o r e , because the TRANS a n d PASS v a l u e s are u n d e r e s t i m a t e d b y the automatic counts, a n d therefore l o w e r in value, t h e y are also closer to the values for the u n e r g a t i v e verbs. For the CAUS feature, w e predict the highest values for the unaccusative verbs, a n d while that p r e d i c t i o n is confirmed, the automatic counts for that class also s h o w the most errors. Finally, a l t h o u g h the general p a t t e r n of h i g h e r values for the ANIM feature of unergatives a n d object-drop verbs is p r e s e r v e d in the automatic counts, the feature is u n d e r e s t i m a t e d for almost all the verbs, again m a k i n g the values for that feature closer across the classes t h a n they are in reality.
[image:14.468.47.416.106.214.2]n o t likely to be r e s p o n s i b l e for the p a t t e r n of d a t a in Table 6 above, w h i c h g e n e r a l l y m a t c h e s o u r predictions. F u r t h e r m o r e , the errors, at least for this r a n d o m s a m p l e of verbs, occur in a direction that m a k e s o u r task of d i s t i n g u i s h i n g the classes m o r e difficult, a n d indicates that d e v e l o p i n g m o r e accurate search p a t t e r n s m a y p o s s i b l y s h a r p e n the class distinctions, a n d i m p r o v e the classification p e r f o r m a n c e .
4. Experiments in Classification
In this section, w e t u r n to o u r c o m p u t a t i o n a l e x p e r i m e n t s that investigate w h e t h e r the statistical indicators of thematic p r o p e r t i e s that w e h a v e d e v e l o p e d can in fact be u s e d to classify verbs. Recall that the task w e h a v e set o u r s e l v e s is that of a u t o m a t i c a l l y learning the best class for a set of u s a g e s of a verb, as o p p o s e d to classifying i n d i v i d u a l occurrences of the verb. The f r e q u e n c y distributions of o u r features yield a v e c t o r for each v e r b that r e p r e s e n t s the e s t i m a t e d v a l u e s for the v e r b on each d i m e n s i o n across the entire corpus:
Vector template: [ v e r b - n a m e , TRANS, PASS, VBN, CAUS, ANIM, class]
Example: [opened, .69, .09, .21, .16, .36, unacc]
The resulting set of 59 vectors constitutes the data for o u r m a c h i n e l e a r n i n g experi- ments. We u s e this data to train an a u t o m a t i c classifier to d e t e r m i n e , g i v e n the feature v a l u e s for a n e w v e r b (not f r o m the training set), w h i c h of the three m a j o r classes of English o p t i o n a l l y intransitive v e r b s it b e l o n g s to.
4.1 Experimental Methodology
In pilot e x p e r i m e n t s on a subset of the features, w e i n v e s t i g a t e d a n u m b e r of su- p e r v i s e d m a c h i n e learning m e t h o d s that p r o d u c e a u t o m a t i c classifiers (decision tree induction, rule learning, a n d t w o t y p e s of n e u r a l networks), as well as hierarchi- cal clustering; see S t e v e n s o n et al. (1999) for m o r e detail. Because w e a c h i e v e d a p - p r o x i m a t e l y the s a m e level of p e r f o r m a n c e in all cases, w e n a r r o w e d o u r f u r t h e r e x p e r i m e n t a t i o n to the p u b l i c l y available v e r s i o n of the C5.0 m a c h i n e l e a r n i n g s y s t e m ( h t t p : / / w w w . r u l e q u e s t . c o m ) , a n e w e r v e r s i o n of C4.5 (Quinlan 1992), d u e to its ease of use a n d w i d e availability. The C5.0 s y s t e m g e n e r a t e s b o t h decision trees a n d cor- r e s p o n d i n g rule sets f r o m a training set of k n o w n classifications. In o u r e x p e r i m e n t s , w e f o u n d little to n o difference in p e r f o r m a n c e b e t w e e n the trees a n d rule sets, a n d r e p o r t o n l y the rule set results.
In the e x p e r i m e n t s below, w e follow t w o m e t h o d o l o g i e s in training a n d testing, each of w h i c h tests a s u b s e t of cases h e l d o u t f r o m the training data. Thus, in all cases, the results w e r e p o r t are o n test d a t a that w a s n e v e r seen in training. 7
The first training a n d testing m e t h o d o l o g y w e follow is 10-fold cross-validation. In this a p p r o a c h , the s y s t e m r a n d o m l y d i v i d e s the data into ten parts, a n d r u n s ten times on a different 9 0 % - t r a i n i n g - d a t a / 1 0 % - t e s t - d a t a split, y i e l d i n g an a v e r a g e a c c u r a c y a n d s t a n d a r d error across the ten test sets. This training m e t h o d o l o g y is v e r y useful for
Computational Linguistics Volume 27, Number 3
our application, as it yields performance measures across a large number of training d a t a / t e s t data sets, avoiding the problems of outliers in a single random selection from a relatively small data set such as ours.
The second methodology is a single hold-out training and testing approach. Here, the system is run N times, where N is the size of the data set (i.e., the 59 verbs in our case), each time holding out a single data vector as the test case and using the remaining N-1 vectors as the training set. The single hold-out methodology yields an overall accuracy rate (when the results are averaged across all N trials), but also-- unlike cross-validation--gives us classification results on each individual data vector. This property enables us to analyze differential performance on the individual verbs and across the different verb classes.
Under both training and testing methodologies, the baseline (chance) performance in this task--a three-way classification--is 33.9%. In the single hold-out methodology, there are 59 test cases, with 20, 19, and 20 verbs each from the unergative, unaccusative, and object-drop classes, respectively. Chance performance of picking a single class label as a default and assigning it to all cases would yield at most 20 out of the 59 cases correct, or 33.9%. For the cross-validation methodology, the determination of a baseline is slightly more complex, as we are testing on a random selection of 10% of the full data set in each run. The 33.9% figure represents the expected relative proportion of a test set that would be labelled correctly by assignment of a default class label to the entire test set. Although the precise make-up of the test cases vary, on average the test set will represent the class membership proportions of the entire set of verbs. Thus, as with the single hold-out approach, chance accuracy corresponds to a maximum of 20/59, or 33.9%, of the test set being labelled correctly.
The theoretical maximum accuracy for the task is, of course, 100%, although in Section 5 we discuss some classification results from h u m a n experts that indicate that a more realistic expectation is much lower (around 87%).
4.2 Results Using 10-Fold Cross-Validation
We first report the results of experiments using a training methodology of 10-fold cross- validation repeated 50 times. This means that the 10-fold cross-validation procedure is repeated for 50 different random divisions of the data. The numbers reported are the averages of the results over all the trials. That is, the average accuracy and standard error from each random division of the data (a single cross-validation run including 10 training and test sets) are averaged across the 50 different random divisions. This large number of experimental trials gives us a very tight bound on the mean accuracy reported, enabling us to determine with high confidence the statistical significance of differences in results.
Table 8 shows that performance of classification using individual features varies greatly, from little above the baseline to almost 22% above the baseline, or a reduction of a third of the error rate, a very good result for a single feature. (All reported accuracies in Table 8 are statistically distinct, at the p < .01 level, using an ANOVA
[dr
= 249, F = 334.72], with a Tukey-Kramer post test.)The first line of Table 9 shows that the combination of all features achieves an accuracy of 69.8%, which is 35.9% over the baseline, for a reduction in the error rate of 54%. This is a rather considerable result, given the very low baseline (33.9%). Moreover, recall that our training and testing sets are always disjoint (cf., Lapata and Brew [1999]; Siegel [1999]); in other words, we are predicting the classification of verbs that were never seen in the training corpus, the hardest situation for a classification algorithm.
Table 8
Percent accuracy and standard error of the verb classification task using each feature individually, under a training methodology of 10-fold cross-validation repeated 50 times.
Feature %Accuracy %SE
CAUS 55.7 .1
VBN 52.5 .5
PASS 50.2 .5
TRANS 47.1 .4
ANIM 35.3 .5
Table 9
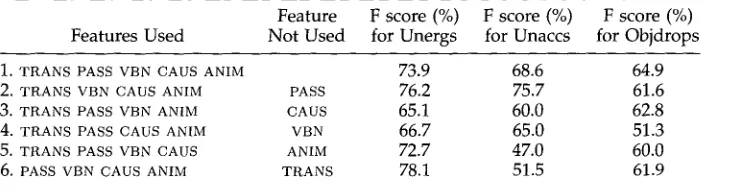
Percent accuracy and standard error of the verb classification task using features in combination, under a training methodology of 10-fold cross-validation repeated 50 times.
Feature
Features Used Not Used %Accuracy %SE
1. T R A N S PASS VBN CAUS ANIM 69.8 .5
2. T R A N S VBN CAUS ANIM PASS 69.8 .5
3. T R A N S PASS VBN ANIM CAUS 67.3 .6
4. T R A N S PASS CAUS ANIM VBN 66.5 .5
5. T R A N S PASS VBN CAUS ANIM 63.2 .6
6. PASS VBN CAUS ANIM T R A N S 6 1 . 6 .6
the contribution of each feature to the p e r f o r m a n c e of the classification process, b y c o m p a r i n g the p e r f o r m a n c e of the subset w i t h o u t it, to the p e r f o r m a n c e using the full set of features. We see that the r e m o v a l of PASS (second line) has n o effect on the results, while r e m o v a l of the r e m a i n i n g features yields a 2-8% decrease in p e r f o r m a n c e . (In Table 9, the differences b e t w e e n all r e p o r t e d accuracies are statistically significant, at the p < .05 level,
except
for b e t w e e n lines 1 a n d 2, lines 3 and 4, and lines 5 a n d 6, using an ANOVA[dr
= 299, F = 37.52], w i t h a T u k e y - K r a m e r post test.) We observe that the b e h a v i o r of the features in combination cannot be p r e d i c t e d b y the i n d i v i d u a l feature behavior. For example, CAUS, w h i c h is the best individually, does not greatly affect accuracy w h e n c o m b i n e d with the other features (compare line 3 to line 1). Conversely, ANIM and TRANS, w h i c h do not classify verbs accurately w h e n u s e d alone, are the m o s t relevant in a combination of features (compare lines 5 and 6 to line 1). We conclude that e x p e r i m e n t a t i o n with combinations of features is required to d e t e r m i n e the relevance of i n d i v i d u a l features to the classification task. [image:17.468.34.419.105.220.2] [image:17.468.37.393.265.362.2]Computational Linguistics Volume 27, Number 3
Table 10
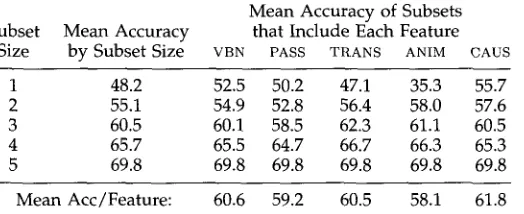
Average percent accuracy of feature subsets, by subset size and by sets of each size including each feature.
Mean Accuracy of Subsets Subset Mean Accuracy that Include Each Feature
Size by Subset Size VBN PASS TRANS ANIM CAUS
1 48.2 52.5 50.2 47.1 35.3 55.7 2 55.1 54.9 52.8 56.4 58.0 57.6 3 60.5 60.1 58.5 62.3 61.1 60.5 4 65.7 65.5 64.7 66.7 66.3 65.3 5 69.8 69.8 69.8 69.8 69.8 69.8
Mean Acc/Feature: 60.6 59.2 60.5 58.1 61.8
The first o b s e r v a t i o n - - t h a t m o r e features p e r f o r m b e t t e r - - i s c o n f i r m e d overall, in all subsets. Looking at the first data c o l u m n of Table 10, w e can o b s e r v e that, on average, larger sets of features p e r f o r m better t h a n smaller sets. F u r t h e r m o r e , as can be seen in the following i n d i v i d u a l feature columns, i n d i v i d u a l features p e r f o r m better in a bigger set t h a n in a smaller set, w i t h o u t exception. The second o b s e r v a t i o n - - t h a t the p e r f o r m a n c e of i n d i v i d u a l features is not always a predictor of their p e r f o r m a n c e in c o m b i n a t i o n - - i s c o n f i r m e d b y c o m p a r i n g the average p e r f o r m a n c e of each feature in subsets of different sizes to the average across all subsets of each size. We can observe, for instance, that the feature CAUS, w h i c h p e r f o r m s v e r y well alone, is a v e r a g e in feature combinations of size 3 or 4. By contrast, the feature ANIM, w h i c h is the w o r s t if u s e d alone, is v e r y effective in combination, w i t h a b o v e a v e r a g e p e r f o r m a n c e for all
subsets of size 2 or greater.
4.3 Results Using Single Hold-Out Methodology
One of the d i s a d v a n t a g e s of the cross-validation training m e t h o d o l o g y , w h i c h aver- ages p e r f o r m a n c e across a large n u m b e r of r a n d o m test sets, is that w e d o not h a v e p e r f o r m a n c e data for each verb, n o r for each class of verbs. In a n o t h e r set of experi- ments, w e u s e d the same C5.0 system, b u t e m p l o y e d a single h o l d - o u t training a n d testing methodology. In this approach, w e h o l d out a single verb vector as the test case, a n d train the system on the r e m a i n i n g 58 cases. We then test the resulting classifier o n the single h o l d - o u t case, a n d record the assigned class for that verb. This p r o c e d u r e is r e p e a t e d for each of the 59 verbs. As n o t e d above, the single h o l d - o u t m e t h o d o l o g y has the benefit of yielding b o t h classification results o n each i n d i v i d u a l verb, a n d an overall accuracy rate (the a v e r a g e results across all 59 trials). Moreover, the results on i n d i v i d u a l verbs p r o v i d e the data necessary for d e t e r m i n i n g accuracy for each verb class. This allows us to d e t e r m i n e the contribution of i n d i v i d u a l features as above, b u t with reference to their effect o n the p e r f o r m a n c e of i n d i v i d u a l classes. This is i m p o r - tant, as it enables us to evaluate o u r h y p o t h e s e s c o n c e r n i n g the relation b e t w e e n the thematic features a n d verb class distinctions, w h i c h w e t u r n to in Section 4.4.
Table 11
Percent accuracy of the verb classification task using features in combination, under a single hold-out training methodology.
Feature %Accuracy
Features Used Not Used on All Verbs
1. T R A N S PASS VBN CAUS ANIM 69.5 2. T R A N S VBN CAUS ANIM PASS 71.2 3. T R A N S PASS VBN ANIM CAUS 62.7 4. T R A N S PASS CAUS AN1M VBN 61.0 5. T R A N S PASS VBN CAUS ANIM 61.0 6. PASS VBN CAUS ANIM T R A N S 64.4
Table 12
F score of classification within each class, under a single hold-out training methodology.
Feature F score (%) F score (%) F score (%)
Features Used Not Used for Unergs for Unaccs for Objdrops
1. T R A N S PASS VBN CAUS ANIM 73.9 68.6
2. T R A N S VBN CAUS ANIM PASS 76.2 75.7
3. T R A N S PASS VBN ANIM CAUS 6 5 . 1 6 0 . 0
4. T R A N S PASS CAUS ANIM VBN 6 6 . 7 6 5 . 0
5. T R A N S PASS VBN CAUS AN1M 72.7 47.0
6. PASS VBN CAUS ANIM T R A N S 78.1 5 1 . 5
64.9 61.6 62.8 51.3 60.0 61.9
classified correctly. The r e m a i n i n g lines of Table 11 s h o w that the r e m o v a l of a n y other feature has a 5-8% negative effect on performance, again similar to the cross-validation results. ( A l t h o u g h note that the precise a c c u r a c y achieved is n o t the same in each case as w i t h 10-fold cross-validation, indicating that there is s o m e sensitivity to the precise m a k e - u p of the training set w h e n using a subset of the features.)
Table 12 presents the results of the single h o l d - o u t experiments in terms of per- f o r m a n c e within each class, u s i n g an F m e a s u r e w i t h b a l a n c e d precision a n d recall. 8 The first line of the table s h o w s clearly that, u s i n g all five features, the unergatives are classified with greater a c c u r a c y (F = 73.9%) than the unaccusative a n d object-drop verbs (F scores of 68.6% a n d 64.9%, respectively). The features a p p e a r to be better at distinguishing unergatives than the other t w o verb classes. The r e m a i n i n g lines of Table 12 s h o w that this p a t t e r n h o l d s for all of the subsets of features as well. Clearly, future w o r k on o u r verb classification task will need to focus on d e t e r m i n i n g features that better discriminate unaccusative a n d object-drop verbs.
O n e potential explanation that w e can exclude is that the p a t t e r n of results is d u e s i m p l y to the frequencies of the v e r b s - - t h a t is, that m o r e frequent verbs are m o r e ac- curately classified. We e x a m i n e d the relation b e t w e e n classification a c c u r a c y a n d log
8 For all previous results, we reported an accuracy measure (the percentage of correct classifications out of all classifications). Using the terminology of true or false positives/negatives, this is the same as truePositives/(truePositives + falseNegafives). In the earlier results, there are no falsePositives or trueNegatives, since we are only considering for each verb whether it is correctly classified
(truePositive) or not (falseNegative). However, when we turn to analyzing the data for each class, the
possibility arises of having falsePositives and trueNegatives for that class. Hence, here we use the
balanced F score, which calculates an overall measure of performance as 2PR/(P + R), in which P
[image:19.468.39.421.105.210.2] [image:19.468.37.412.247.342.2]