A Novel Frequent Subgraph Mining Based
Intelligent MapReducing Technique
Mayuri V. Hipalgaonkar 1, A.V. Mophare 2, H. S. Chabukswar3
M.E Student, Department of Computer Science and Engineering, N B Navale Sinhgad College of Engineering, Kegaon,
Solapur, India
Assistant Professor, Department of Computer Science and Engineering, N B Navale Sinhgad College of Engineering,
Kegaon, Solapur, India
Assistant Professor, Department of Computer Science and Engineering, N B Navale Sinhgad College of Engineering,
Kegaon, Solapur, India
ABSTRACT: MapReducing is one of the most important task in Data Mining industry. It is essential to analyze the graph oriened data to manipulate the resulting sequences at every iteration over large data processing. Frequent Subgraph Mining (FSM) is implemented in this system to efficiently analyze the subgraph patterns with MapReducing concept clearly. This algorithm/methodology is more suitable for processing large data structure and mines the data with small amount of memory requirement to avoid cost consumptions. Be that as it may, as this present reality chart information develops, both in size and processing, such a suspicion does not hold any more. To defeat this, some diagram database-driven strategies have been proposed lately to solve FSM; notwithstanding, a disseminated arrangement utilizing MapReduce worldview has not been investigated broadly. Since MapReduce is getting to be the true worldview for calculation on monstrous information, an effective FSM calculation on this worldview is of immense request. In this system, an incessant subgraph mining calculation called FSM-H is proposed, which utilizes an iterative MapReduce based system. FSM-H is finish as it returns all the continuous subgraphs for a given client characterized support, and it is effective as it applies every one of the advancements that the most recent FSM calculations receive. For all our empirical results demonstrate our approach is more suitable to process large dataset in efficient manner without any cost and time wastage.
KEYWORDS: MapReduce, Graph Mining Approach, Iterative Principles, Mining with FSM.
I. INTRODUCTION
As of late, the ‘BigData’ wonder has overwhelmed countless and application areas including information mining, computational science, ecological sciences and web based business, web mining, and interpersonal organization examination. In these areas, breaking down and digging of BigData for extricating novel experiences has turned into a standard errand.
Another primary explanation behind this structure to pick up consideration of numerous admirers is the larger amount of reflection that it gives, which keeps numerous framework level subtle elements avoided the software engineers and permit them to focus more on the issue particular computational rationale. MapReduce has turned into a well known stage for examining huge systems as of late. Be that as it may, the dominant part of such examinations are constrained to evaluating worldwide measurements, (for example, distance across), ghostly investigation, or vertex-centrality examination.
There additionally exist a few works that mine (and check) sub-structures from a vast system. For example, Suri and Vassilvitskii and Pagh and Tsourakakis utilize MapReduce for tallying triangles, Afrati et al. utilize MapReduce for identifying the occurrences of a question chart in an expansive system, and Bahmani et al. mine densest subgraphs in a vast diagram. Be that as it may, mining incessant subgraphs from a chart database has gotten the slightest consideration. Given the development of uses of continuous subgraph mining (FSM) in different controls including informal communities, bioinformatics, cheminformatics, and semantic web, a versatile strategy for successive subgraph mining on MapReduce is of appeal. Settling the assignment of successive subgraph mining on a dispersed stage like MapReduce is trying for different reasons.
Initial, a FSM technique processes the support of a competitor subgraph design over the whole arrangement of info diagrams in a chart dataset. In a circulated stage, if the info diagrams are divided over different specialist hubs, the nearby support of a subgraph in the particular parcel at a laborer hub is very little valuable for choosing whether the given subgraph is visit or not. Additionally, nearby support of a subgraph in different hubs can't be collected in a worldwide information structure, on the grounds that, MapReduce programming model does not give any implicit system to speaking with a worldwide state. Additionally, the bolster calculation can't be deferred subjectively, as taking after Apriori standard, future competitor visit patterns1 can be created just from an incessant example.
II. LITERATURE SURVEY
In the year of 2012, the authors "S. Hill, B. Srichandan, and R. Sunderraman" proposed a paper titled "An iterative Mapreduce approach to frequent subgraph mining in biological datasets", in that they clearly described such as Mining incessant subgraphs has pulled in a lot of consideration in numerous zones, for example, bioinformatics, web information mining and interpersonal organizations. There are many promising principle memory-based procedures accessible here, however they need versatility as the fundamental memory is a bottleneck. Mulling over the gigantic information, conventional database frameworks like social databases and protest databases flop wretchedly concerning effectiveness as incessant subgraph mining is computationally concentrated.
With the coming of the MapReduce system by Google, a couple of analysts have connected the MapReduce display on a solitary diagram for mining successive substructures. In this paper, we propose to make utilization of the MapReduce programming model which accomplishes multifold adaptability on an arrangement of named charts. We tried our strategy on both genuine and engineered datasets. To the best of our insight, this is the principal endeavor to execute exchange diagrams utilizing the MapReduce display.
In the year of 2014, the authors "X. Xiao, W. Lin, and G. Ghinita" proposed a paper titled "Large-scale frequent subgraph mining in Mapreduce", in that they clearly described such as Mining continuous subgraphs from a substantial gathering of chart articles is a vital issue in a few application spaces, for example, bio-informatics, interpersonal organizations, PC vision, and so forth. The fundamental test in subgraph mining is effectiveness, as (i) testing for diagram isomorphisms is computationally serious, and (ii) the cardinality of the chart gathering to be mined might be huge. We propose a two-stage channel and-refinement approach that is reasonable to monstrous parallelization inside the versatile MapReduce figuring model.
We additionally propose viable methodologies to dodge excess calculation in each round when looking for competitor charts, and additionally a lightweight diagram pressure component to lessen the correspondence cost between machines. Broad exploratory assessment comes about on a few certifiable expansive diagram datasets demonstrate that the proposed approach unmistakably outflanks the current best in class and gives a pragmatic answer for the issue of successive subgraph digging for enormous accumulations of charts.
In the year of 2005, the authors "M. Kuramochi and G. Karypis" proposed a paper titled "Finding frequent patterns in a large sparse graph", in that they clearly described such as Chart based demonstrating has developed as a capable reflection fit for catching in a solitary and bound together structure a considerable lot of the social, spatial, topological, and different attributes that are available in an assortment of datasets and application regions.
Computationally productive calculations that discover designs comparing to much of the time happening subgraphs assume a vital part in creating information digging driven systems for investigating the diagrams coming about because of such datasets.
This paper presents two calculations, in view of the level and vertical example revelation standards, that locate the associated subgraphs that have an adequate number of edge-disjoint embeddings in a solitary vast undirected marked inadequate chart. These calculations utilize three unique techniques for deciding the quantity of edge-disjoint embeddings of a subgraph and utilize novel calculations for hopeful era and recurrence checking, which permit them to work on datasets with various qualities and to rapidly prune unpromising subgraphs.
Exploratory assessment on genuine datasets from different spaces demonstrate that both calculations accomplish great execution, scale well to inadequate info diagrams with more than 120,000 vertices or 110,000 edges, and fundamentally beat already created calculations.
III. PROPOSED APPROACH
In this framework, FSM-H2 is proposed, which process a dispersed continuous subgraph mining strategy over MapReduce. Given a chart database, and a base bolster limit, FSM-H produces an entire arrangement of successive subgraphs. To guarantee fulfillment, it develops and holds all examples in a segment that has a non-zero support in the guide period of the mining, and afterward in the decrease stage, it chooses whether an example is visit by accumulating its support registered in all segments from various figuring hubs.
To defeat the reliance among the conditions of a mining procedure, FSMH keeps running in an iterative mold,
where the yield from the reducers of emphasis i 1 is utilized as a contribution for the mappers in the cycle i. The mappers of emphasis i produce applicant subgraphs of size i (number of edge), furthermore register the nearby support of the hopeful example. The reducers of cycle i then locate the genuine regular subgraphs (of size i) by collecting their neighborhood bolsters. They likewise compose the information in circle that is handled in consequent cycles.
Algorithm: Novel_MapReducing
1. Start While Loop to Check the Novel Procedures 2. Processing the MapReducing Task
3. Mark the Processing result in DFS 4. Updating the Current Status 5. Mention G as the Current Database 6. And Intialize the variable k to 1
7. Mining the Frequent SubGraph with parameters G and k 8. populating F1
9. Start While Loop to Check whether the F is not equal to 0 10. Then Ck is increamented by 1
11. Generate for loop until Ck is not equal to c
12. Count the Supporting Loop with respect to two parameters such as G and Ck 13. Increament Ck with respect to C
14. Increament K by 1
15. Return the function variable F.
IV. EXPERIMENTAL RESULTS
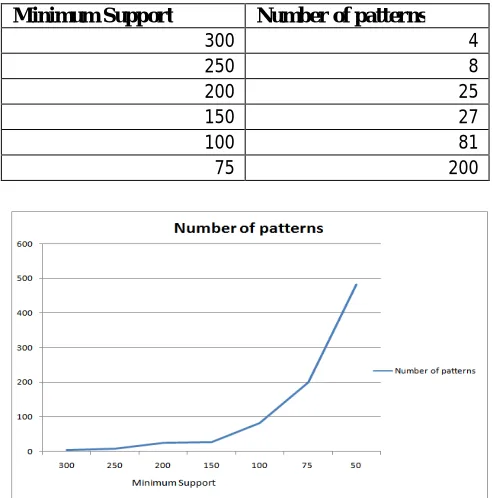
Minimum Support Number of patterns
300 4
250 8
200 25
150 27
100 81
75 200
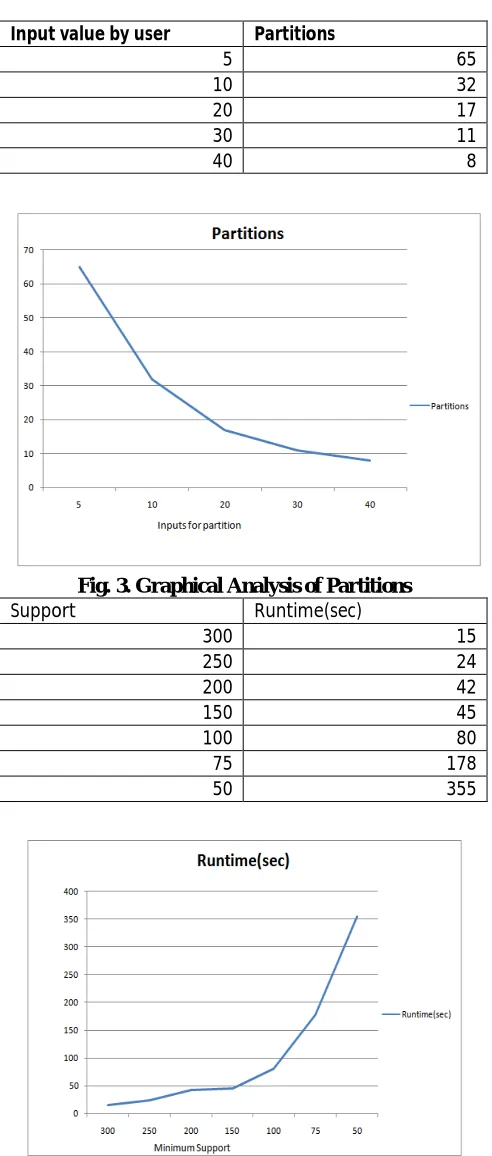
Input value by user Partitions
5 65
10 32
20 17
30 11
40 8
Fig. 3. Graphical Analysis of Partitions
Support Runtime(sec)
300 15
250 24
200 42
150 45
100 80
75 178
50 355
V. CONCLUSION
In this framework we introduce a novel iterative MapReduce based regular subgraph mining calculation, called FSMH. We demonstrate the execution of FSM-H over genuine and vast manufactured datasets for different framework and info designs. We likewise think about the execution time of FSM-H with a current technique, which demonstrates that FSMH is fundamentally superior to the current strategy.
REFERENCES
[1] S.-Q. Wang, Y.-B. Yang, Y. Gao, G.-P. Chen, and Y. Zhang, “Mapreduce-based closed frequent itemset mining with efficient redundancy filtering,” in Proc. IEEE 12th Int. Conf. Data Mining Workshops, 2012, pp. 49–453.
[2] L. Zhou, Z. Zhong, J. Chang, J. Li, J. Huang, and S. Feng, “Balanced parallel FP-growth with Mapreduce,” in Proc. IEEE Youth Conf. Inf. Comput. Telecommun, 2010, pp. 243–246.
[3] H. Li, Y. Wang, D. Zhang, M. Zhang, and E. Y. Chang, “Pfp: parallel FP-growth for query recommendation,” in Proc. ACM Conf. Recommender Syst., 2008, pp. 107–114.
[4] B.-S. Jeong, H.-J. Choi, M. A. Hossain, M. M. Rashid, and M. R. Karim, “A MapReduce framework for mining maximal contiguous frequent patterns in large DNA sequence datasets,” IETE Tech. Rev., vol. 29, pp. 162–168, 2012.
[5] S. Hill, B. Srichandan, and R. Sunderraman, “An iterative Mapreduce approach to frequent subgraph mining in biological datasets,” in Proc. ACM Conf. Bioinformat., Comput. Biol. Biomed., 2012, pp. 661–666.
[6] X. Xiao, W. Lin, and G. Ghinita, “Large-scale frequent subgraph mining in Mapreduce,” in Proc. Int. Conf. Data Eng., 2014, pp. 844–855. [7] M. Kuramochi and G. Karypis, “Finding frequent patterns in a large sparse graph*,” Data Mining Knowl. Discov., vol. 11, pp. 243–271, 2005. [8] S. Skiadopoulos, M. Elseidy, E. Abdelhamid, and P. Kalnis, “Grami: Frequent subgraph and pattern mining in a single large graph,” Proc. Very Large Database Endow., vol. 7, pp. 517–528, 2014.
[9] J. Lin and C. Dyer, Data-Intensive Text Processing with MapReduce. San Rafael, CA, USA: Morgan and Claypool.
[10] J. Cheng, Y. Ke, W. Ng, and A. Lu, “Fg-index: Towards verification-free query processing on graph databases,” in Proc. ACM SIGMOD Int. Conf. Manage. Data, 2007, pp. 857–872.
[11] J. Huan, W. Wang, D. Bandyopadhyay, J. Snoeyink, and J. Prins, “Mining protein family specific residue packing patterns from protein structure graphs,” in Proc. Int. Conf. Res. Comput. Mol. Biol., 2004, pp. 308–315.
[12] S. Kramer, L. Raedt, and C. Helma, “Molecular feature mining in HIV data,” in Proc. Int. Conf. Knowl. Discov. Data Mining, 2004, pp. 136– 143.
[13] B. Berendt, “Using and learning semantics in frequent subgraph mining,” in Proc. Adv. Web Min. Web Usage Anal., 2006, pp. 18–38.
[14] R. Agrawal and R. Srikant, “Fast algorithms for mining association rules in large databases,” in Proc. 20th Int. Conf. Very Large Data Bases, 1994, pp. 487–499.
[15] A. Inokuchi, T. Washio, and H. Motoda, “An apriori-based algorithm for mining frequent substructures from graph data,” in Proc. 4th Eur. Conf. Principles Data Mining Knowl. Discov., 2000, pp. 13–23.
[16] M. Kuramochi and G. Karypis, “Frequent subgraph discovery,” in Proc. Int. Conf. Data Mining, 2001, pp. 313–320. [17] X. Yan and J. Han, “gSpan: Graph-based substructure pattern mining,” in Proc. Int. Conf. Data Min., 2002, pp. 721–724.
[18] S. Nijssen, and J. Kok, “A quickstart in frequent structure mining can make a difference,” in Proc. 10th ACM SIGKDD Int. Conf. Knowl. Discov. Data Mining, 2004, pp. 647–652.
[19] V. Chaoji, M. Hasan, S. Salem, and M. Zaki, “An integrated, generic approach to pattern mining: Data mining template library,” Data Min. Knowl. Discov. J., vol. 17, no. 3, pp. 457–495, 2008.
[20] S. Chakravarthy, R. Beera, and R. Balachandran, “Db-subdue: Database approach to graph mining,” in Proc. Adv. Knowl. Discov. Data Mining, 2004, pp. 341–350.
[21] S. Chakravarthy and S. Pradhan, “Db-FSG: An SQL-based approach for frequent subgraph mining,” in Proc. 19th Int. Conf. Database Expert Syst. Appl., 2008, pp. 684–692.
[22] B. Srichandan and R. Sunderraman, “Oo-FSG: An object-oriented approach to mine frequent subgraphs,” in Proc. Australasian Data Mining Conf., 2011, pp. 221–228.
[23] D. J. Cook, L. B. Holder, G. Galal, and R. Maglothin, “Approaches to parallel graph-based knowledge discovery,” J. Parallel Distrib. Comput., vol. 61, pp. 427–446, 2001.
[24] C. Wang and S. Parthasarathy, “Parallel algorithms for mining frequent structural motifs in scientific data,” in Proc. 18th Annu. Int. Conf. Supercomput., 2004, pp. 31–40.