How To
Software engineering and QA
This document describes general rules, practices and recommendations for software
engineering in scope of ITER CODAC activities.
Approval Process
Name Action Affiliation
Author Stepanov D. 11-Feb-2011:signed IO/DG/DIP/CHD/CIT/CODAC
CoAuthor
Reviewers Klotz W.- D.
Wallander A. 21-Feb-2011:recommended14-Feb-2011:recommended IO/DG/DIP/CHD/CITIO/DG/DIP/CHD/CIT/CODAC
Approver Bora D. 23-Feb-2011:approved IO/DG/DIP/CHD
Document Security: level 1 (IO unclassified) RO: Di Maio Franck
Read Access AD: ITER, AD: External Collaborators, AD: Section - CODAC, project administrator, RO
IDM UID
2NRS2K
VERSION CREATED ON / VERSION / STATUS
11 Feb 2011 / 2.1 / APPROVED
Change Log
Version Latest Status Date Description of Change
v2.1 Approved 11 Feb 2011 Minor corrections after the internal and external reviews. v2.0 Signed 10 Jan 2011 Updated for the inclusion into the PCDH v6.
Table of Contents
1
Introduction
...3
1.1
Purpose
...3
1.2
PCDH Context
...3
1.3
Scope
...3
1.4
Definitions and Abbreviations
...4
1.5
References
...5
2
Software Engineering
...6
2.1
Recommended Software
...6
2.2
Integrated Development Environment (IDE)
...6
2.3
Software Support Infrastructure
...6
2.3.1
Software repository
...7
2.3.2
Issue tracking system
...7
2.3.3
Reference development server
...7
2.3.4
Dedicated development machines...7
2.3.5
Nightly-build server...7
2.3.6
File server
...8
2.3.7
Software distribution server
...8
2.3.8
Infrastructure support servers...8
2.3.9
Developers’ website area
...9
2.3.10
User accounts
...9
2.4
Naming and Coding Conventions
...9
2.4.1
File naming and contents
...9
2.4.2
Standard headers
...9
2.4.3
Java coding conventions
...10
2.4.4
C coding conventions...10
2.4.5
Python coding conventions
...10
2.4.6
SQL coding conventions...10
2.4.7
XML coding conventions
...10
2.5
Software Licensing Policy
...11
2.6
Packaging Guidelines
...11
2.6.1
Packages classification...11
2.6.2
Packages naming convention (regular case)
...12
2.6.3
Packages naming convention (advanced case)
...12
2.6.4
Packages breakdown guidelines
...12
2.6.5
Packaging other than RPM
...13
2.7
Distribution Guidelines
...13
2.7.1
Using an RPM / YUM repository
...13
2.7.2
Using Red Hat Network Satellite...13
2.7.3
Using RPMs and self-extracting archives
...14
2.7.4
Using plain tarballs
...14
2.7.5
Using OS-bundled distribution...14
3.1
Roles and Responsibilities
...15
3.1.1
Roles...15
3.1.2
Responsibility chart
...15
3.1.3
Configuration control board...17
3.2
Quality Control
...17
3.2.1
Issue tracking
...17
3.2.2
QA records...17
3.3
Version Control
...17
3.3.1
Storage principles
...18
3.3.2
Top level breakdown
...18
3.3.3
Software units...19
3.3.4
Principal operations on a repository
...22
3.3.5
Version control systems other than Subversion
...24
3.4
Software Life Cycle
...24
3.4.1
Parallel product versions
...24
3.4.2
Environment setup...25
3.4.3
Development
...25
3.4.4
Testing...26
3.4.5
Documenting
...26
3.4.6
Release cutting
...26
3.4.7
Porting and packaging
...27
3.4.8
Release
...27
3.4.9
User support
...28
3.5
Documentation Guidelines
...28
3.5.1
Documents prepared by developers
...28
3.5.2
Generated documentation...28
1
Introduction
1.1 Purpose
This document describes general rules, practices and recommendations for software engineering in scope of ITER CODAC activities.
1.2 PCDH Context
The Plant Control Design Handbook (PCDH) [RD1] defines methodology, standards, specifications and interfaces applicable to ITER Plant Systems instrumentation and control (I&C) system life cycle. I&C standards are essential for ITER to:
Integrate all plant systems into one integrated control system;
Maintain all plant systems after delivery acceptance;
Contain cost by economy of scale.
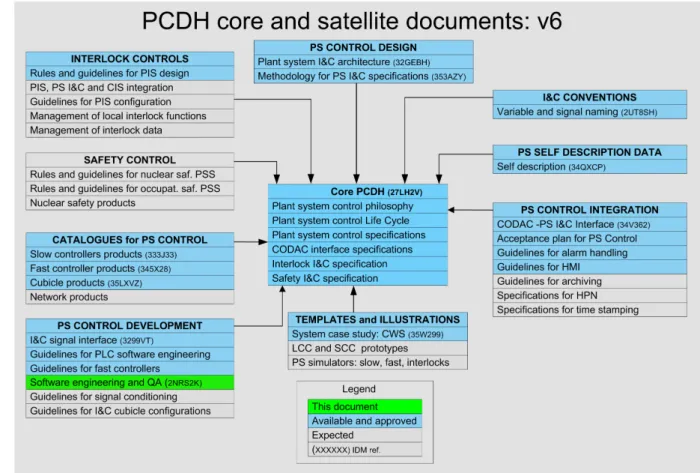
PCDH comprises a core document which presents the plant system I&C life cycle and recaps the main rules to be applied to the plant system I&Cs for conventional controls, interlocks and safety controls. Some I&C topics will be explained in greater detail in dedicated documents associated with PCDH as presented on Figure 1-1. This document is one of them. Its objective is to describe the software engineering and quality assurance (QA) in more detail.
Figure 1-1: PCDH documentation structure
1.3 Scope
This document defines only general topics. Particular projects within CODAC (such as CODAC Core System) may go into further details on their particular subjects.
PLC-specific development is described in a separate handbook ([RD2]).
The content of this document applies both to the plant system specific development (PBS XX) and to the CODAC internal development (PBS 45). This document is equally applicable to development of interlock
systems (PBS 46) and plasma control algorithms (PBS 47). The safety part (PBS 48) is not addressed yet. Software for control system elements qualified as COTS devices does not have to follow these rules and should follow engineering and QA guidelines of their respective manufacturers and / or maintainers instead.
1.4 Definitions and Abbreviations
24/7 24 hours a day, 7 days a week CIS Central Interlock System
CODAC COntrol, Data Access and Communication COTS Commercial Off-The-Shelf
CR Carriage Return
CSS Central Safety System
DHCP Dynamic Host Configuration Protocol
DNS Domain Name System
DVD Digital Video Disc
EOL End-Of-Line
EPICS Experimental Physics and Industrial Control System
GNU GNU's Not UNIX
GPG GNU Privacy Guard
I&C Instrumentation and Control
IDE Integrated Development Environment IDM ITER Document Management
LDAP Lightweight Directory Access Protocol
LF Line Feed
NFS Network File System NTP Network Time Protocol
OS Operating System
PBS Plant Breakdown Structure PCDH Plant Control Design Handbook PDF Portable Document Format PLC Programmable Logic Controller
PS Plant System
PSH Plant System Host
QA Quality Assurance
QC Quality Control
R&D Research and Development
RD Reference Document
RHEL Red Hat Enterprise Linux RO Responsible Officer RPM Red Hat Package Manager
S-DDD Software Design Description Document SCCB Software Configuration Control Board SQL Structured Query Language
SRS Software Requirements Specification STP Software Test Plan
STR Software Test Report
tar tape archive
UNIX UNiplexed Information and Computing System URI Uniform Resource Identifier
URL Uniform Resource Locator
UTF-8 Unicode Transformation Format – 8-bit W3C World Wide Web Consortium
XML eXtensible Mark-up Language YUM Yellowdog Updater, Modified
Table 1-1: Abbreviations used
1.5 References
[RD2] PLC Software Engineering Handbook (3QPL4H v1.3), 09 Feb 2011
[RD3] Version Control with Subversion (http://svnbook.red-bean.com/nightly/en/index.html) [RD4] Code Conventions for the Java Programming Language
(http://www.oracle.com/technetwork/java/codeconvtoc-136057.html), 20 Apr 1999
[RD5] Linux Kernel Coding Style (http://www.kernel.org/doc/Documentation/CodingStyle), 13 Jul 2007 [RD6] Style Guide for Python Code (http://www.python.org/dev/peps/pep-0008/), 28 Nov 2010
[RD7] XML Schema Part 2: Datatypes Second Edition ( http://www.w3.org/TR/2004/REC-xmlschema-2-20041028/), 28 Oct 2004
[RD8] CODAC Software Licensing (332QB4 v1.0), 14 Jan 2010 [RD9] Maximum RPM (http://www.rpm.org/max-rpm/), 2000
[RD10] How to setup your own package repository (http://yum.baseurl.org/wiki/RepoCreate) [RD11] Apache Maven Project / Introduction to the Standard Directory Layout
(http://maven.apache.org/guides/introduction/introduction-to-the-standard-directory-layout.html), 2010
[RD12] ITER Plugin for Maven (32Z6UL v1.0), 09 Feb 2010 [RD13] Bugzilla-tutorial (33KAC4 v1.0), 09 Feb 2010
[RD14] CODAC Core System Support Procedures (34EHTM v1.3), 05 May 2010 [RD15] CODAC Core System Documentation template (33ZDG3)
2
Software Engineering
2.1 Recommended Software
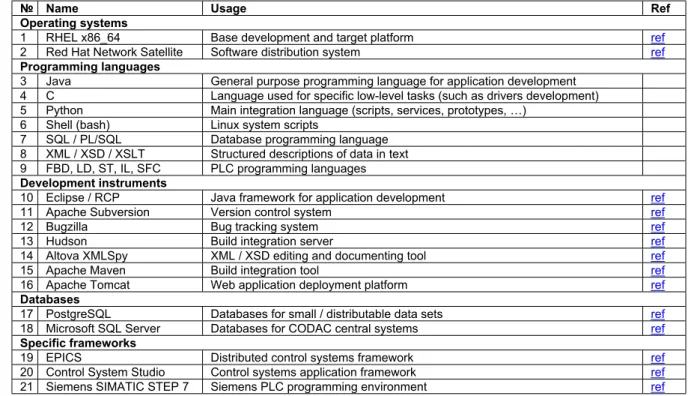
The software listed below should be considered as preferred when choosing the environment for a new project within the CODAC framework. Deviations from this list shall be discussed with the ITER Organization.
№ Name Usage Ref
Operating systems
1 RHEL x86_64 Base development and target platform ref 2 Red Hat Network Satellite Software distribution system ref Programming languages
3 Java General purpose programming language for application development 4 C Language used for specific low-level tasks (such as drivers development) 5 Python Main integration language (scripts, services, prototypes, …)
6 Shell (bash) Linux system scripts
7 SQL / PL/SQL Database programming language 8 XML / XSD / XSLT Structured descriptions of data in text 9 FBD, LD, ST, IL, SFC PLC programming languages Development instruments
10 Eclipse / RCP Java framework for application development ref
11 Apache Subversion Version control system ref
12 Bugzilla Bug tracking system ref
13 Hudson Build integration server ref
14 Altova XMLSpy XML / XSD editing and documenting tool ref
15 Apache Maven Build integration tool ref
16 Apache Tomcat Web application deployment platform ref Databases
17 PostgreSQL Databases for small / distributable data sets ref 18 Microsoft SQL Server Databases for CODAC central systems ref Specific frameworks
19 EPICS Distributed control systems framework ref
20 Control System Studio Control systems application framework ref 21 Siemens SIMATIC STEP 7 Siemens PLC programming environment ref
Table 2-1: Recommended software
Versions of these programs are the subject of controlled evolution along with the development of CODAC and are not communicated here.
2.2 Integrated Development Environment (IDE)
The principal IDE solution for software development is Eclipse IDE. There is an ongoing activity to provide a special Eclipse IDE setup tailored for CODAC-oriented software development.
2.3 Software Support Infrastructure
In order to support the development process it is recommended that a number of machines (physical or virtual) serving different functions are installed. They are listed below.
1. Software repository; 2. Issue tracking system;
3. Reference development server; 4. Dedicated development machines; 5. Nightly-build server;
6. File server;
7. Software distribution server; 8. Infrastructure support servers; 9. Developers’ website area.
Depending on nature of work, some of these machines may be missing or, on the contrary, replicated in multiple copies.
The setup of the environment shall be complementary, not exclusive, so that the whole setup can be replicated on a reduced set of servers in order to enable completely autonomous development. The setup technique is optionally a kick-start installation of the CODAC default Linux image plus a script-driven installation of the particular environment on top of the OS.
ITER Organization has this setup fully implemented and available 24/7. I&C designers and software programmers are invited to use this central infrastructure with their projects.
2.3.1 Software repository
The software repository is a key instrument for software development. It keeps track of all the versions of the software produced and allows a consistent snapshot from any given time in the past to be restored.
In the CODAC environment the repository is organized with a help of Subversion software. For more details on repository organization see section 3.3.
2.3.2 Issue tracking system
An issue tracking system serves as a peer management tool for software development. It allows tracking of bugs and features, assigning priorities and responsible persons, discussion and following up on implementation progress.
In the CODAC environment, Bugzilla software is used as an issue tracking system. Several software products (such as the CODAC Core System) together with their associated release planning may be introduced in it.
Normally, some sort of cross-references exists between a software repository and an issue tracking system. For instance, when something is committed in the repository it often carries the corresponding issue’s identifiers, whereas comments in the issue tracking system record the history of commits made in relation to the issue in the repository. Software exists which allows the automation of these cross-references to a certain extent.
2.3.3 Reference development server
The reference development server provides a 24/7 environment for general development and testing. It comprises two principal parts:
1) Current OS installation with rich development-specific profile (compilers, debuggers, profilers, …); 2) The latest nightly build of the CODAC software installed.
The software shall be used for reference purposes and will not be available for direct modification by developers. The primary use of this machine is to serve as a reference development environment, to allow rapid consultation of the latest state of CODAC software without any installation work, to be able to write and / or run some simple occasional tests against this software and to consult the latest source codes and test results. This machine is supposed to be used by developers on a daily basis; no resource-intensive tasks should be run on it.
2.3.4 Dedicated development machines
Certain development tasks and activities may require full control over the machine or its development environment. Typically these include:
The need to have administrator privileges on the machine;
Installation and development against the new, experimental software;
Particular resource-intensive activities, such as regression tests execution;
Feature-oriented development, such as integration with databases;
Connectivity with specific peripheral devices, such as fast controller boards;
Driver development;
Development and testing of installation procedures (e.g., RPM packaging);
Release preparation activities (freezing, packaging, installing, verifying, …).
For such tasks, dedicated development machines can be allocated (either virtual or physical). The name of the machine may reflect its purpose.
2.3.5 Nightly-build server
The nightly-build server is used to compile the latest snapshots of the software and to perform regression testing on them. The set of packages installed on the nightly-build machine is identical to the one of the development server.
1) Complete source tree of the units being developed; 2) Set of tests to be run against, including control scripts; 3) Current canonical outputs.
Canonical outputs of the unit are those which have been approved after thorough verification steps and then saved in the software repository.
The machine is set up in the way that, first, once per night the latest source code (*/trunk/) is checked out from the Subversion, then the incremental build is done (only compiling changed files) and then the entire set of existing regression tests is executed. The output of the tests is stored separately for each day and kept in such a way that they are easily accessible until the next major release is issued. Once a week the compilation environment is cleaned of binaries and the fresh build is made, followed by the same regression testing. This allows errors introduced in the build procedure itself to be caught.
The entire compilation and testing process is executed under a dedicated account (e.g., builder), so that ordinary developers have no possibility to intervene in, or impede the testing process. They should still have the possibility to compile and test in their own home folders.
2.3.6 File server
Because the development cluster has multiple machines installed, it needs a simple and practical file exchange facility and a place dedicated for storing common files. The file server fulfills this role. Typically, the following are stored there:
Snapshot of the latest source code from the software repository (used for quick browsing / reference);
Packaged and unpackaged products of previous public releases, allowing execution or to be compiled against (used for user support and bug hunting);
Binary files used for compilation but which are not part of the software repository;
Any sort of documentation or support files deemed necessary for developers but which are not a part of released products;
Area for rapid file exchange between machines in the same network;
Users home folders.
The shared area shall be mounted via NFS at the same mount points for all computers concerned.
Selected subfolders of the shared space may be mounted read-write or read-only on different NFS client machines, depending on their needs. As a general rule, to prevent accidental data damage, no write access should be provided unless required for work procedures.
2.3.7 Software distribution server
The software distribution server contains packaged software for all supported releases and allows downloading and installing this software. It can be used both for CODAC clients and for internal installations. In the CODAC environment the Red Hat Network Satellite software is used to organize software distribution. Every user performing installation from this server has to be registered with the server.
Apart from the public releases, the distribution server facilitates distribution of the software built everyday by publishing its packages on a daily basis and allowing daily updates from local machines.
2.3.8 Infrastructure support servers
Infrastructure support servers are not directly visible to software developers and are used to support various system administration tasks on the development cluster. Typically these tasks include:
User and group management (e.g., LDAP);
Remote access support (firewalls and remote connection services, such as NoMachine NX);
Name resolution services (DNS, DHCP, …);
Time synchronization service (NTP);
Backup and mirroring systems;
Servers and networks monitoring systems;
2.3.9 Developers’ website area
The developers’ website serves as an area to centralize all development activities. This website usually hosts or provides references to the following information:
List of projects being worked on, with the associated tasks and progress tracking;
Entry point to the software repository;
Entry point to the issue tracking system;
Entry point to the distribution server;
Developers’ discussion boards;
Description of the development environment (servers, access, how-to’s, …);
Documentation for various software packages.
2.3.10
User accounts
As a general rule, every user in the development environment obtains and uses his or her own user account. Use of shared accounts should be kept to the absolute minimum. By its nature, the development and testing process implies some risk of improper software behavior or data loss. A proper access policy shall be put in place in order to minimize the risk of data corruption across the user accounts. If there is a need to do development or testing under the super-user account, it is recommended to set up a dedicated machine for that purpose.
All the software delivered to end user shall run under non-privileged user accounts unless it requires super-user rights for some specific, well defined purpose.
2.4 Naming and Coding Conventions
2.4.1 File naming and contents
File naming conventions are largely driven by particular domains of use and follow their established practices. In the case that there is no particular rule, two different schemes are proposed:
1) All words are capitalized, underscore “_” is used as a word separator (example: “CODAC_Core_System_User_Manual.pdf”);
2) All words are lowercase, hyphen “-” is used as a word separator (example: “privilege-separation.sh”).
Special characters and whitespaces are generally not recommended, as they cause various problems in processing. Capital letters are allowed; however, software shall not be case sensitive to file names (this will cause collisions on Windows).
File extensions shall be provided in order for the file to be properly associated with application software. In the case that several extensions exist for the same file type (e.g., “html” and “htm”), the most common one should be used. File extensions should be lowercase.
Encoding of files shall be UTF-8 unless needed otherwise for a particular purpose.
Line endings (EOL characters) are not standardized and can be either UNIX style (LF) or Windows style (CR+LF), with preference given to UNIX style. All other styles (e.g., CR of Mac OS) shall be avoided; mixture of different EOL styles in the same file shall be avoided as well. Preference shall be given to software capable of transparent processing of all kinds of line endings.
Folder (file directories) names shall follow the same rules as for files. In the UNIX tradition, folders often have short simplistic lowercase name (e.g., “src” or “doc”).
2.4.2 Standard headers
As far as practicable, every file created by the ITER Organization or for the ITER Organization shall carry identification information. For text files (source codes, text documentation, etc) the following standard header shall be used:
$HeadURL$ $Id$
Description : <Short file description> Author : <Author name>
Copyright (c) : 2010-2011 ITER Organization, CS 90 046
13067 St. Paul-lez-Durance Cedex France
This file is a part of the ITER CODAC software.
For the terms and conditions of redistribution or use of this software refer to the file ITER-LICENSE.TXT located in the top level directory of the distribution package.
The tags $HeadURL$ and $Id$ are Subversion keywords which are filled by the version control system. It is not a Subversion default behavior to fill keywords and it has to be configured on the client side (per file or as a global setting). More information on keyword substitution is available in [RD3].
If the file includes third party intellectual property, the corresponding copyright statement shall be retained or included.
The header shall be placed close to the top of the file and enclosed in a comment block appropriate in a given context (e.g., /* */ for Java).
2.4.3 Java coding conventions
Sun’s Java original guidelines shall be followed (see [RD4]).
Java packages developed by CODAC shall use the org.iter.codac.<packagename> name prefix. Javadoc annotations shall be used where appropriate to allow automatic generation of source code documentation.
2.4.4 C coding conventions
In the current CODAC context the C language is used mostly to write Linux drivers. The Linux kernel coding guidelines shall be followed for this purpose (see [RD5]).
2.4.5 Python coding conventions
Python original guidelines shall be followed (see [RD6]).
2.4.6 SQL coding conventions
SQL is essentially a case-insensitive language, so the following recommendations are mostly to improve readability.
SQL keywords shall be written in capital letters (e.g., UPDATE tableName SET …). Table names shall use a so-called “CamelCase” notation (i.e., no spaces, all words are capitalized; e.g., “PlantSystems”). Table fields shall use a “lowerCamelCase” capitalization style (all words but first are capitalized; e.g., “attributeName”). If a field is designed to be a primary or a foreign key, it shall have a suffix “_pk” or “_fk” to emphasize its meaning.
It is recommended that table constraints are defined separately from the table definition itself in order to facilitate their removal for debugging purposes.
In the case that there is a choice of SQL constructs or data types, it is recommended to use the more portable one.
2.4.7 XML coding conventions
XML documents shall follow the methodology used for the W3C XML Schema definition (see [RD7]). In particular, names of tags and attributes shall follow a so-called “lowerCamelCase” capitalization style (i.e., no spaces, all words but first are capitalized). If the first word starts from a capital letter by its nature (e.g., it is an acronym), the capitalization is retained.
XML namespaces shall be used for reasonably isolated schemas. The format of the CODAC namespace URI is:
http://www.iter.org/CODAC/SSSSSSSS/YYYY
where SSSSSSSS indicates domain (variable length), and YYYY indicates edition year (e.g., 2010). The domain shall be a word (or a word combination) briefly and clearly identifying a data domain. Mixing of uppercase and lowercase characters is allowed, with words joined by a capital letter without underscores. Examples of the domains are: "PBS", "EPICS", "TTT", "PlantSystem", etc.
2.5 Software Licensing Policy
For the sake of the involvement of a wider range of experts, the scientific community and industry in testing and enhancement, the CODAC software may be distributed to organizations or bodies not bound by contractual obligations with the ITER Organization. For this purpose, the distributed software is protected by a special ITER license. The full text of the license is reproduced below:
Copyright (c) 2010-2011, ITER Organization
Route de Vinon, CS 90 046, 13067 Saint Paul Lez Durance Cedex, France All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met: * Redistribution and use are granted solely to the members of the ITER Agreement (the People's Republic of China, the European Atomic Energy Community, the Republic of India, Japan, the Republic of Korea, the Russian Federation, and the United States of America).
Organizations, bodies or individuals belonging to the parties other than that in the list above shall seek specific written permission
from the ITER Organization before redistribution or use of this software. * Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer. * Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. * Neither the name of the ITER Organization nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE ITER ORGANIZATION BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
This text is usually placed in the top level directory of the distribution package under the name of ITER-LICENSE.TXT. Equally, it can be present in the accompanying documentation or in the program’s online help. More details on the CODAC licensing policy are available in [RD8].
2.6 Packaging Guidelines
All the software produced by CODAC has to be properly packaged. A formalized packaging step facilitates porting and installation procedures as well as clearly separating the development environment from the production (target) environment.
CODAC software uses a native Red Hat Linux packaging mechanism called RPM ([RD9]).
2.6.1 Packages classification
All packages on a particular Linux system can be classified in the following categories:
1) Packages which are part of a standard Linux distribution (either installed by default or not);
2) Packages which are required by CODAC software but are not a part of a standard Linux distribution (or the existing ones do not have the required functionality);
3) Packages which are created and maintained by the CODAC team.
It is expected that the target system shall have or be able to install packages from the first category. Packages from the categories 2 and 3 will be provided as a part of CODAC distribution. All these packages will have properly identified dependencies, so that installation of the required package automatically brings in all the required support packages.
2.6.2 Packages naming convention (regular case)
Following the established Linux tradition (see [RD9]), the full name of a package shall look like this:
<name>-<version>-<release>.<arch>.rpm
where:
1) <name> indicates a name of the program (can have hyphens within);
2) <version> is a program version (see section 3.3.3.3 for more information on versions);
3) <release> is a number indicating a version of the package of the same software release. That means that the source code of the software remains the same, but the way it is packaged might be slightly changed. The number starts from 1;
4) <arch> is a target system architecture (x86_64 in our case), or noarch for platform-independent packages.
An example of the name would be eclipse-pde-3.6.1-3.x86_64.rpm.
This approach implies that only one version of the program can be installed at any given time. Should multiple versions be required or should there be a need to give a common group name and version to a set of packages, the advanced technique may be used, as described in the next section.
2.6.3 Packages naming convention (advanced case)
In the case that a program makes part of a well defined product, its package name may be formed as follows:
<prodname>-<prodversion>-<progname>-<prodversion>.v<progversion>-<release>.<arch>.rpm
where the <prodname> and <prodversion> are product’s name and version in the same format as for the regular program. The rest of the tags are the same as for the regular case.
This kind of naming allows several product versions to coexist on the same machine. Of course, apart from naming, packages shall be carefully designed in order to arrive at different places on the disk and to be able to operate independently. The first product version number could be reduced only to major or major.minor number, depending on what level of product maturity is required to be installed.
The reason the product version appears twice in the formula above is that RPM is unaware of this user-added complexity and counts everything found between the last two hyphens as a package version. In order for it to be properly compared by RPM taking into account the product’s version, both product and program versions have to be present in the notation. The “.v” serves as a separator for a person to distinguish the two versions.
The version numbers for the product and its components are not supposed to coincide and may be different, depending on the development activity of these components.
For example, if the product is a CODAC Core System, and the program is EPICS, and minor versions of the CODAC Core System are allowed to coexist on the same system, the package name will look like
codac-core-2.0-epics-2.0.1.v3.14.12-1.x86_64.rpm.
2.6.4 Packages breakdown guidelines
Every distributed program has to be mapped to RPM packages during the packaging procedure. Usually it is not a one-to-one mapping. The following recommendations should help to choose the breakdown wisely:
If software is packaged by a third party, the package should be retained;
Software having a different life cycle (e.g., provided by different vendors) should be packaged in separate packages;
Software which is supposed to work on separate machines should be packaged in separate packages;
Additional functionality of the software, considered as optional in some cases, should be packaged as a separate package;
Extensive documentation of a particular product normally comes as a separate package (*-doc.*.rpm);
Programs not supposed to be used separately could be joined in a single package.
The packages should have proper RPM dependencies where they exist between each other or with system packages. For each product a meta-package may be provided which depends on every package included in the product. Different installation profiles (e.g., PSH or mini-CODAC) can be handled in the same way. This way, it will be possible to install a whole set of required packages by installing just a meta-package.
2.6.5 Packaging other than RPM
Sometimes there is a need to distribute CODAC software in a non-conventional way. Typical cases include contributions back to the open source community or publishing selected pieces of software for use in projects other than ITER. In this case, there is little sense to distribute binaries, since the target environment might differ substantially from ITER’s. Also, there is no need to distribute components which have not been developed by ITER (such as RHEL OS or EPICS); these could be downloaded from their original internet locations .
In such a case, a source code has to be provided, accompanied with the relevant documentation; porting has to be done at the software reception side. The packaging would be just a simple source file archive (.tar.bz2 is recommended). As with regular packaging, care should be taken to properly identify versions of the software which goes to such a public release.
2.7 Distribution Guidelines
This section describes recommended ways of distribution of the CODAC software. The distribution method depends on the way software is packaged.
2.7.1 Using an RPM / YUM repository
The preferred way of distributing software is to establish and maintain one or several YUM repositories (see [RD10] for more information). This will allow smooth installation and update of the software concerned. Normally, the repository is organized as an add-on to some existing installation (e.g., on top of the regular RHEL YUM repositories), so only CODAC-specific software is placed there.
Each repository is described with a small web-downloadable RPM file. Client machines with a clean Linux installation can configure the link to the repository by installing this package:
rpm –i http://<distribution-website>/<reponame>-<repoversion>.noarch.rpm
Note that RPM / YUM repositories contain binaries and rely on specific packaging scheme and dependencies in the original Linux distribution. Consequently, they can only be used with the same distribution for which the software was built and tested.
An alternative way of configuring the repository would be manually adding its description into the
/etc/yum.conf configuration file or in the /etc/yum.repos.d/ folder (see [RD10]). Once the link has been established, the software can be installed as simple as:
yum install <packagename>
On the first use you will be asked to import the repository’s GPG key (answer “yes”).
Equally, the same could be done using the graphical wizard which comes with a Linux distribution (pirut in RHEL).
Updates are intended to be distributed in the same way. Once they are available, they are published in the YUM repository. On the client side the update of the package to the latest version would simply be:
yum update <packagename>
2.7.2 Using Red Hat Network Satellite
If there is a need to have more control of the software distribution over a multitude of local or remote systems, tools like Red Hat Network Satellite can be used. The Red Hat Network Satellite is based on the
same concept of YUM repositories, but provides a management layer for them, allowing the management of users and distribution channels, updates to be pushed or for software integrated with the OS itself to be distributed.
Target systems installed with the help of Red Hat Network Satellite are preconfigured to use the correct repositories. The client RPM / YUM interface stays the same.
2.7.3 Using RPMs and self-extracting archives
For users who do not have an internet connection, or are not familiar with RPM and want click-and-run installation, an alternative way can be provided, where a product (a set of packages) is bundled to a self-extracting archive which runs a simple script which launches RPM installation. The script could be made graphical if needed (a fancy window with an OK button). This method of installation is commonly used by many commercial vendors of Linux software.
The benefit of this approach is that the end result is the same as with installation from the RPM repository, so all the files installed stay under control of system’s packet manager and can be tracked, repaired and updated if necessary.
2.7.4 Using plain tarballs
If the software is packaged as a source code (see section 2.6.5), tar archives (tarballs) can be distributed using any file transfer method (such as putting them on a web page or sending by email). There is no control over the software installation or its use in this case.
2.7.5 Using OS-bundled distribution
A less error-prone distribution method (which is quite popular nowadays) is the following. CODAC specific software together with all necessary third party software can be combined with the original OS distribution forming an image of a complete pre-installed OS. The image is written on DVDs (or made available for download) and is then distributed (as an image file download or written on physical disks). The DVD prepared with the help of this image is a “live” DVD, which allows booting from it on any reasonable hardware and to start immediate use. The data which needs to be persistent (like settings configured by user) can be saved on external media, such as a flash drive. The live DVD can also have an option of transferring the same installation to a computer’s hard drive, thus forming an ordinary installation in place. This sort of distribution can be used for quick demonstration, promo actions and as a fast track to actual use of the software.
3
Software Quality Assurance
3.1 Roles and Responsibilities
This section presents the actors and their roles and responsibilities.
3.1.1 Roles
The actors in the development process are:
1. Product manager – a supervisor of all activities, responsible for overall product releases; 2. Development manager – a person defining development policy and supervising developers;
3. Test & QA manager – a person supervising the testing process, especially for nightly-builds. Also responsible for overall QA definition and enforcement;
4. Documentation manager – a person defining the documentation strategy and enforcing its QA; 5. System administrator – a person installing and maintaining machines in the development
environment;
6. Developer – a person actively contributing to the source code;
7. Tester (Reviewer) – a person reviewing the code and running various tests, either existing or specially prepared ones;
8. Documenter – a person writing end user documentation;
9. Packager – a person performing packaging of the releases, but not contributing the code except for packaging specific changes;
10. Supporter – a person delivering support to end users. The subordinates hierarchy is show below:
Product manager
├ Development manager │ ├ Developer
│ └ Packager ├ Test & QA manager │ └ Tester ├ Documentation manager │ └ Documenter ├ System administrator └ Supporter
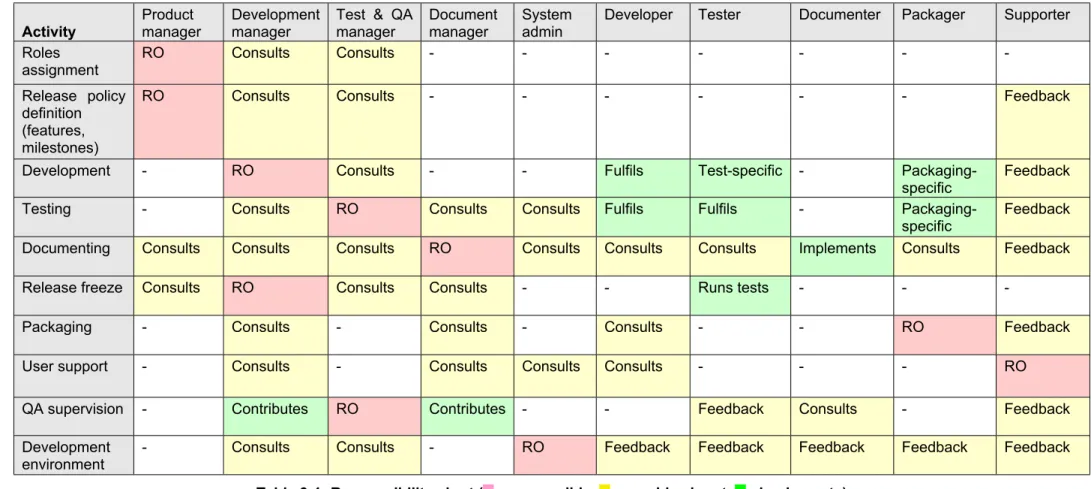
3.1.2 Responsibility chart
Some of the roles may be attributed to the same people. The product manager assigns roles in such a way that the role substitution does not defeat the QA process (e.g., a person must not be assigned to review his or her own code).
The procedure of delegation of authority has to be put in place, so that a particular person missing at a given moment does not restrain the whole process.
Activity Product manager Development manager Test & QA manager Document manager System admin
Developer Tester Documenter Packager Supporter Roles
assignment RO Consults Consults - - -
-Release policy definition (features, milestones)
RO Consults Consults - - - Feedback
Development - RO Consults - - Fulfils Test-specific -
Packaging-specific Feedback
Testing - Consults RO Consults Consults Fulfils Fulfils -
Packaging-specific
Feedback Documenting Consults Consults Consults RO Consults Consults Consults Implements Consults Feedback
Release freeze Consults RO Consults Consults - - Runs tests - -
-Packaging - Consults - Consults - Consults - - RO Feedback
User support - Consults - Consults Consults Consults - - - RO
QA supervision - Contributes RO Contributes - - Feedback Consults - Feedback
Development environment
- Consults Consults - RO Feedback Feedback Feedback Feedback Feedback
3.1.3 Configuration control board
A software configuration control board (SCCB) is a panel of people involved in the development process. It is a working instrument to follow up current activities. The issue tracking system is a key tool for SCCB work. Main SCCB activities are:
1. Review current progress with respect to the release schedule; 2. Decide on features and bug fixes to go into particular release; 3. Assign responsible persons and milestones to new issues; 4. Review and decide on overdue items;
5. Decide on new software units and their owners;
6. Discuss any particular difficulties and problems which occurred during development or testing. The SCCB shall be chaired by the product manager. It convenes regularly (usually weekly, depending on development intensity) and also for particular topics, as needed.
3.2 Quality Control
Quality control (QC) is an essential part of the software development process. Depending on the nature of the software, the control can be strict or relaxed. Relaxed QC is applied during the early software development phase (“alpha” versions), or for various types of experimental development (e.g., prototypes). Production software shall be the subject of strict QC.
3.2.1 Issue tracking
Each bug report or feature request which might lead to a change in the product, however minor, is filed as a separate entity in the issue tracking system. Dependencies between items, if they exist, must be clearly indicated.
For each issue at least the following items shall be recorded:
1. Clear description of the problem or feature together with supporting materials (test cases, screen shots, etc);
2. Short description of implementation (if not trivial), or reference to design document(s); 3. Indication of repository branch and all commits (Subversion revision numbers); 4. Names of tests added or modified in the regression test bed;
5. Characteristic differences in outputs of the regression tests;
6. Indication and justification of change which might affect end users (e.g., compatibility break); 7. Justification if the issue is closed without making changes.
It is good practice to introduce a “release issue” for a particular release and make it dependent on all key features or bug fixes in the release. This will ensure that nothing is forgotten and will facilitate preparation of release notes.
More information on issue processing in the Bugzilla environment is available in [RD13] and [RD14].
3.2.2 QA records
A QA plan shall be written and followed by all stakeholders.
The QA process will be supported by a number of mandatory documents. They include: 1. Software requirements specification (SRS);
2. Software design description document (S-DDD); 3. Software test plan (STP);
4. Software test report (STR).
The documents should be reviewed and updated at each life cycle phase, as appropriate. During testing, the correspondence of the actual software to the declared requirements has to be verified; any discrepancies found must be properly recorded and followed up.
3.3 Version Control
Software version control is a cornerstone of the software development and QA process. The CODAC team uses Subversion software to manage different versions of the software it produces. This section summarizes
the methodology for organizing a repository for CODAC-related development.
It is assumed that the reader knows the basics of Subversion and its terminology. Extensive user documentation is available in [RD3].
3.3.1 Storage principles
The following are some guidelines on what has to be stored in the repository:
Source code with associated building environment (scripts);
Canonical test outputs;
Design support information (models, diagrams, etc);
Associated documentation.
The list above applies not only to the information being worked on, but also to the deliverables from various contracts and procurements (e.g., selected parts of the PCDH deliverables or R&D contract deliverables). The following things should not normally be stored in the repository:
Derived data (that which can be obtained from automated processing, such as compilation, stylesheet transformation, javadoc generation, etc) unless the process of its creation is non-trivial and is difficult to be fully automated;
Binary files (especially executable binaries) unless they are an integral part of the software (e.g., picture files, project files, etc);
Any sort of run-time, dynamic, operational data;
Information which is a routine product of some programs rather than a human creative work (e.g., daily reports, logs, etc). Databases are normally better suited for this;
Huge files (usually need special handling);
User manuals for CODAC software (these require review process, which shall be done via IDM); These guidelines are neither exhaustive nor imperative. The decision to put a particular file into repository should be based on common sense, experience and best practice.
The repository must be operated in a way that traceability of information is maintained. This is supported by several measures:
Well chosen top level breakdown, so that changes at that level are rare;
Well defined procedures for product life cycle, including obsolescence management;
The information shall never be physically deleted from the repository (unless extreme cases, such as a legal claim);
Move or rename operations shall be properly logged;
The information shall not be excessively redundant or blindly replicated.
3.3.2 Top level breakdown
The URL of the CODAC repository is:
https://svn.iter.org/codac/
Here codac/ refers to organizational breakdown, i.e. to the area managed by the CODAC team. Within it the following top level breakdown is implemented:
/iter/ ├ codac/
│ ├ contracts/ (deliverables of various contracts)
│ │ ├ <YYYY>/ (yearly breakdown seems to be most convenient for browsing) │ │ └ ...
│ ├ design/ (various design works not directly related to the software) │ │ └ ...
│ ├ dev/ (software development area for central CODAC) │ │ ├ units/ (software units, see below)
│ │ │ └ ...
│ │ └ obsolete/ (obsolete units are moved here) │ │ └ ...
│ ├ i&cdev/
│ │ ├ pbs<NN>/ (folder for PS specific developments) │ │ │ ├ dev/ (PS software)
│ │ │ └ ... │ │ └ ...
│ └ plcdev/ (PLC-related development (Windows / STEP 7)) │ └ ... (same organization as for /iter/codac/dev/) └ css/
└ ... (same organization as for /iter/codac/)
For the i&c/ and contracts/ folders the folder hierarchy will be complemented by a similar one in IDM. The general idea is that document-oriented deliverables (like Microsoft Word or Excel) will be kept in IDM, whilst software-oriented deliverables will be placed in Subversion. In the case that contractors require instant access to Subversion for their own development (e.g., prototyping) they should allocate a subfolder in the
contracts/<YYYY> tree. The <YYYY> is a current year.
It is suggested that CIS-related software is managed in the same hierarchy /iter/codac/ whilst CSS related software resides in a separate folder /iter/css/. The reason for that is that interlock implementation is likely to share a significant part of code base with CODAC, whereas safety is likely to be implemented completely differently. Clear separation of safety also helps to cope with regulatory safety requirements.
The folders in the repository hierarchy shall have short names, all lowercase (unless imposed by some product) and use hyphens as word separators. The length of the folder name shall not exceed 32 characters.
3.3.3 Software units
A suggested development approach is to follow unit testing pattern, where the whole set of software is broken down into rather small pieces and then an aggregation (integration) logic is defined on top of them.
3.3.3.1 Definitions
In order to define software structure in the repository, common names for software “pieces” are proposed as follows:
Software Module – a piece of software possessing a well defined function (functions).
Software Subsystem – an autonomous program (programs) providing a high-level function or functions.
Software System – an integrated complex of subsystems delivering complete solution for a given problem.
Software Unit – a collective name for module, subsystem or system.
Modules may exhibit strong dependencies between each other. Typical examples of modules are libraries or drivers.
Subsystems normally should have loose coupling between them and communicate through well defined interfaces. Subsystems should be able to continue working if other subsystems manifest malfunctions. Examples of subsystems are the central alarm handler or the central data archiver.
Systems shall be able to act completely independently from other systems. Examples of systems are CODAC, CIS, CSS, CODAC Core System.
The higher level units (systems or subsystems) normally act as aggregators for lower level units (subsystems or modules). A system may include an arbitrary number of subsystems or modules. A subsystem may include an arbitrary number of modules. This is illustrated in Figure 3-1:
System Module Module Module Subsystem Subsystem Subsystem Module Module Module
Figure 3-1: Functional aggregation of software units
Note that this aggregation is purely functional; it does not mean that in the repository a folder of one unit is a subfolder of another unit. In fact, in the repository all units are stored in a flat structure:
dev/ ├ units/ │ ├ <unit1> │ ├ <unit2> │ └ ... └ obsolete/ ├ <unit1> ├ <unit2> └ ...
The aggregation knowledge is kept in the build logic of units. Equally this means that the pattern of software storage in most cases does not match the product installation pattern. This feature actually gives flexibility, especially when one unit is reused by several others (then there is no question in which hierarchy it should be placed). The drawback is that a flat folder with all units might become difficult to navigate.
The basic guidelines of breaking down software into modules are the following:
Software having different a life cycle (e.g., coming from different vendors or released at different milestones) has to go into different modules;
A module normally should be written using a single programming language;
A module should be autonomous enough to allow standalone testing of its functionality;
A module should be small enough to be manageable by one active developer;
A module’s documentation and tests should be part of the same module.
Higher level units (systems and subsystems) shall not contain anything other than what is needed for integration (e.g., an integrated build script or common documentation). The rest of the code goes in the corresponding modules and is just referenced in the building environment of the aggregate unit.
3.3.3.2 Unit naming convention
Each unit shall have a unique name following the convention:
t-cc..c[-cc..c]*
where t designates the type of the unit (s – system, b – subsystem, m – module). The rest of the string is a short recognizable name of the unit of a variable length of alphanumeric characters cc..c, not less than two characters (not counting the first hyphen). Words in the name shall be separated with hyphens. All letters in the name shall be lowercase. The total length of the name string shall not exceed 32 characters.
Examples of names: m-ni-pxi-6259-driver, b-alarm-handler, s-codac-core.
The words in the name must not be used to build a hierarchy with the help of word separators. The name is assumed to reflect a function, not a hierarchical breakdown.
3.3.3.3 Unit version numbering
Each unit shall maintain its own versions independently of any higher level products it might be part of. The version numbering for CODAC-developed units shall be a classical one, X.Y.Z, with a major number X
meaning major upgrade (possibly incompatible), minor number Y meaning enhancement (normally staying compatible) and bug fix number Z meaning bug fixes and small improvements. All numbers start from 0 and may exceed 9. The major number for newly developed software is 0; it stays zero until the first stable release.
This way, versions serve as a means to track software features and stability. If possible, no special meaning should be associated with versions numbers. Developers should not be bound to maintain specific version numbers because of external conditions (such as public announcement), as it may cause serious inconvenience in the development process.
For software being actively developed the “alpha” (a) and “beta” (b) qualifiers shall be used (see section 3.4.1 for more information what “alpha” and “beta” mean). They are inserted between minor and bug fix number (example: 2.0b3). In this case the bug fix number changes its meaning to the number of the corresponding “alpha” or “beta” release; these numbers start from 1. Stable versions (marked with X.Y.Z) shall not have “alpha” or “beta” qualifiers.
The version tags for imported products (not developed by CODAC) shall be those assigned by their vendors. They may differ from the traditional X.Y.Z scheme given that they allow proper lexicographical comparison between releases. In the case that the imported product does not have a clear notion of versions the version shall be assigned by the person doing import.
3.3.3.4 Unit internal structure
Each module, subsystem or system is assigned a folder in the repository. The organization of main folders is the same for all types of units:
<unit-name>/
├ branches/ (forks for features)
│ ├ <feature1 tag> (same organization as for trunk/ within) │ └ ... (more features)
├ tags/ (release/milestone tags)
│ ├ <release1 tag> (same organization as for trunk/ within) │ └ ... (more releases)
├ vendor/ (optional, used for third party software) │ ├ <release1 tag> (same organization as for trunk/ within) │ └ ... (more releases)
└ trunk/ (main tree)
├ pom.xml (unit control script) ├ doc/ (unit documentation) │ └ ...
└ src/ (source code)
├ main/ (main build artifact)
│ ├ <lang> (product language, such as java, c or python) │ │ └ ... (source code of any complexity)
│ ├ resources/ (application resources) │ │ └ ...
│ ├ config/ (application config files) │ │ └ ...
│ └ ... (other folders, if needed) └ tests/ (unit tests)
├ <lang> (tests’ language, such as java, c or python) │ └ ...
├ resources/ (test resources) │ └ ...
├ config/ (test config files) │ └ ...
└ ... (other folders, if needed)
The “branches / tags / trunk” breakdown is a typical arrangement of a product, recommended in the Subversion documentation ([RD3]). The “vendor” part is optional and used to keep original copies of third party software (other than that, its use is identical to the “tags” folder).
Since the control software for unit builds is Maven, the organization of trunk/ and all similar folders follows Maven conventions ([RD11]). Not all the folders suggested by Maven have to be present.
The file structure under main/<lang> or test/<lang> is not defined in this document. Depending on the product nature (EPICS application, Linux driver, etc) it is up to more specific manuals to define the internal layout.
The tests/ folder records not only test program codes, but also canonical outputs.
Work is ongoing to automate unit creation and for making basic unit consistency checks in the repository.
3.3.3.5 Unit control script
The top level file pom.xml located in the unit folder is a unit control script. It shall be always present in every unit and serve as an entry point for Maven-driven builds. Typically, at least the following actions (“goals” in Maven terminology) have to be defined: compile and test. They launch appropriate tasks for the unit as a whole. Apart from goals, Maven also allows the definition of build the configuration, such as environment variables or project dependencies.
It is recommended to use Maven for underlying software build operations as well. However, if this is not practicable (e.g., if the building infrastructure already exists), Maven can delegate underlying builds to some other tools, like make or ant.
For the purpose of software QA some general information shall also be defined and stored in the control script. This information includes:
1. unit name;
2. unit summary (one line); 3. unit description (text);
4. unit version;
5. unit owner and contributors (persons); 6. unit vendor (organization);
7. unit license(s).
Some other information could also be defined; Maven provides built-in infrastructure to store this kind of data. This information is then used for administrative and statistical purposes.
Use of the unit version may be more advanced than just for developers’ interest. If there is a need to use a version tag somewhere inside the product (e.g., show it to the end user in the “About” dialogue), a good practice would be to store the version number in a single place across the unit. A unit control script is an ideal place for that; the building environment can be set up to pass this information into underlying builds. This way, there will be only one place with a version tag to maintain.
More information on Maven and its particular use at ITER is available in [RD12].
3.3.4 Principal operations on a repository
The operations described below are largely compliant with the general Subversion methodology described in [RD3]. This section focuses on points which present further customization or are of particular importance for the CODAC development process.
3.3.4.1 Check out and check in
Usually there is little sense to check out the entire unit folder, since it contains many branches and / or releases and thus consumes space and brings much duplication. Normally, only the trunk or one of the branches should be checked out. It is recommended that the name of the extracted portion is indicated in the target folder name with some sort of suffix. This suffix stays local and will not affect names in the repository, but will help in local navigation. Example:
svn checkout https://svn.iter.org/.../units/m-plc-sample/trunk m-plc-sample-TRUNK
When doing commits, it is important to remember that Subversion is a collaborative environment, and someone else might be changing the same code as you, even if you do not expect this. The safe commit procedure consists of three steps:
1. run svn status (and svn diff, if necessary) in order to check that your set of changes is concise and clean, and no accidental or temporary changes have crept in;
2. run svn update to synchronize your copy with the one in the repository. In many cases it will result in no changes, meaning you can safely proceed. If there are changes, you should review them and decide whether the combined change set (yours + repository’s) is coherent. If there are conflicts, they must be resolved before doing the commit. By default the repository’s copy always takes precedence (unless something was committed by mistake) and so the person trying to do the next commit is in charge of conflict resolution;
3. run svn commit to submit your changes.
It is important to keep changes to a practicable minimum and to avoid changes in places which are irrelevant to the current change (such as massive formatting changes).
3.3.4.2 Working with a trunk
Trunk is an area for the mainstream development. Most development activities occur in this area. The decision when exactly the activities should be moved from experimental branches to the trunk, or vice versa, is taken by the unit owner; it does not depend on the life cycle of products using this unit.
The code checked in the trunk must be stable enough to be compiled and submitted to regular testing (the tests themselves can fail). This is needed to support the overall nightly build procedure occurring on units trunks. If there is a need to commit a really unstable code, a separate branch must be allocated to it (see section 3.3.4.4).
The unit version string stored in the unit control script of the trunk shall always be a fixed sting TRUNK. This way there will be a clear indication in the built software that this is a running development version. Also, it will eliminate differences in test outputs related to regular changes of unit versions.
3.3.4.3 Working with tags
Tags are used to indicate milestones in development or to name a particular snapshot of code. Tags can be classified in several groups:
1. unit’s own version tags;
2. version tags of the product embracing this unit; 3. temporary tags.
Unit version tags are used to track a units own evolution. In order to distinguish this group, it is proposed that the tag format is v<unitversion>. For example, for the unit that has reached version 2.0.0 the tag will be
v2.0.0.
Version tags of products including this unit are formed as <productprefix><productversion>, where the product prefix is a well defined name for the product. An example would be CODAC-CORE-1.1.0.
Tags from the first two groups listed above shall stay forever and never be removed from the repository. They serve as reference information and may be used at any given time later on.
Temporary tags are created for convenience of development (for instance, to pass a ready piece of code from one development group to another). They can be created at any given time and should be sufficiently descriptive; however, no particular naming convention is imposed on them. As the name implies, these tags will be purged from the repository when they are obsolete or no longer needed.
The information about which version of unit goes into this particular product is kept in the unit control script, as explained in section 3.3.3.5. That is, if one wants to know what version of the unit was present in the particular product, he or she should look into
.../units/<unitname>/tags/<productname><productversion>/pom.xml
for the unit version string stored there. The unit version string shall correctly reflect the unit version for all but temporary tags.
The tagging operation creates an identical copy of the source. Normally during a version stamping operation at least the version number has to be updated in the code. This is why it is recommended to do version stamping in two steps:
1. Tag a new version in Subversion (svn copy);
2. In the tagged snapshot, modify the version string in the unit control script to the one required (svn checkout + svn commit).
Apart from this version update case, it is generally not recommended to do any development activity on the
tags/ or vendor/ folders or even check out these folders. Though Subversion gives no particular meaning to these folders, logically they are very different. Tags, once done, are not supposed to change; thus neither renaming of tags nor change of tagged folders contents is allowed. If there is a need to get contents of a tagged folder on the local disk, the svn export command shall be used rather than the svn checkout.
3.3.4.4 Working with branches
Branches are used for feature specific development or parallel support of several versions of code. Two main categories of branches are used:
1. Feature branches; 2. Release branches.
A feature branch is opened whenever is a need to implement a rather complex feature which will render the source code unusable or unstable for some time. Small fixes can be done directly on trunk or release branches (see below) without forking a separate branch.
A release branch is a branch used for release preparation. It accumulates all changes which go into the specific release. It is a responsibility of unit developers to propagate changes from the trunk or feature branches into release branches. In order to decrease double commit effort, this propagation (“merging” in terms of Subversion) could be done close to the release preparation stage rather than on each distinct commit. Section 3.4.6 describes procedures to handle release branches.
Feature branches shall have descriptive names; however, no specific naming convention is defined for them. Release branches shall have names with the format <productprefix><productversion>, where the version is a product version reduced to a major.minor number (maintenance releases do not require parallel support and thus there is no need for a separate branch).
Branches are considered as temporary items and will be closed (deleted from a repository) at due time. A feature branch is closed whenever the feature is merged back to the source it was designated for (a trunk or a release branch). A release branch is closed when the support for this release ceases. In this way, only active branches will be listed in the branches/ area. There is no real danger of deleting a branch from the