Shared Disk Big Data Analytics with Apache
Hadoop
Anirban Mukherjee, Joydip Datta, Raghavendra Jorapur, Ravi Singhvi, Saurav Haloi, Wasim Akram
{Anirban_Mukherjee, Joydip_Datta, Raghavendra_Jorapur,
Ravi_Singhvi, Saurav_Haloi, Wasim_Akram}@symantec.com
Symantec Corporation
ICON, Baner Road, Pune – 411021, India
Abstract—Big Data is a term applied to data sets whose size is beyond the ability of traditional software technologies to capture, store, manage and process within a tolerable elapsed time. The popular assumption around Big Data analytics is that it requires internet scale scalability: over hundreds of compute nodes with attached storage. In this paper, we debate on the need of a massively scalable distributed computing platform for Big Data analytics in traditional businesses. For organizations which don’t need a horizontal, internet order scalability in their analytics platform, Big Data analytics can be built on top of a traditional POSIX Cluster File Systems employing a shared storage model. In this study, we compared a widely used clustered file system: VERITAS Cluster File System (SF-CFS) with Hadoop Distributed File System (HDFS) using popular Map-reduce benchmarks like Terasort, DFS-IO and Gridmix on top of Apache Hadoop. In our experiments VxCFS could not only match the performance of HDFS, but also outperformed in many cases. This way, enterprises can fulfill their Big Data analytics need with a traditional and existing shared storage model without migrating to a different storage model in their data centers. This also includes other benefits like stability & robustness, a rich set of features and compatibility with traditional analytics applications.
Keywords--BigData; Hadoop; Clustered File Systems; Analytics; Cloud
I.INTRODUCTION
The exponential growth of data over the last decade has introduced a new domain in the field of information technology called Big Data. Datasets that stretches the limits of traditional data processing and storage systems is often referred to as Big Data. The need to process and analyze such massive datasets has introduced a new form of data analytics called Big Data Analytics.
Big Data analytics involves analyzing large amounts of data of a variety of types to uncover hidden patterns, unknown correlations and other useful information. Many organizations are increasingly using Big Data analytics to get better insights into their businesses,
increase their revenue and profitability and gain competitive advantages over rival organizations.
The characteristics of Big Data can be broadly divided into four Vs i.e. Volume, Velocity, Varity and Variability. Volume refers to the size of the data. While Velocity tells about the pace at which data is generated; Varity and Variability tells us about the complexity and structure of data and different ways of interpreting it.
A common notion about the applications which consume or analyze Big Data is that they require a massively scalable and parallel infrastructure. This notion is correct and makes sense for internet scale organizations like Facebook or Google. However, for traditional enterprise businesses this is typically not the case. As per Apache Hadoop wiki [3], significant number of deployments of Hadoop in enterprises typically doesn’t exceed 16 nodes. In such scenarios, the role of traditional storage model with shared storage and a clustered file system on top of it, to serve the need to traditional as well as Big Data analytics cannot be totally ruled out.
Big Data analytics platform in today’s world often refers to the Map-Reduce framework, developed by Google [4], and the tools and ecosystem built around it. Map-Reduce framework provides a programming model using “map” and “reduce” functions over key-value pairs that can be executed in parallel on a large cluster of compute nodes. Apache Hadoop [1] is an open source implementation of Google’s Map-Reduce model, and has become extremely popular over the years for building Big Data analytics platform. The other key aspect of Big Data analytics is to push the computation near the data. Generally, in a Map-Reduce environment, the compute and storage nodes are the same, i.e. the computational tasks run on the same set of nodes that hold the data required for the computations. By default, Apache Hadoop uses Hadoop Distributed File System (HDFS) [2] as the underlying storage backend, but it is designed to work with other file systems as well. HDFS is not a POSIX-compliant file system, and once data is written it is not modifiable (a write-once, read-many access model). HDFS protects
data by replicating data blocks across multiple nodes, with a default replication factor of 3.
In this paper, we try to gather a credible reasoning behind the need of a new non-POSIX storage stack for Big Data analytics and advocate, based on evaluation and analysis that such a platform can be built on traditional POSIX based cluster file systems. Traditional cluster file systems are often looked at with a whim that it requires expensive high end servers with state of the art SAN. But contrary to such impressons, these file systems can be configured using commodity or mid-range servers for lower costs. More importantly, these file systems can support traditional applications that rely on POSIX API’s. The extensive availability of tools, software applications and human expertise are other add-ons to these file systems. Similar efforts are undertaken by IBM Research [5], where they have introduced a concept of metablock in GPFS to enable the choice of a larger block granularity for Map/Reduce applications to coexist with a smaller block granularity required for traditional applications, and have compared the performance of GPFS with HDFS for Map/Reduce workloads
The rest of the paper is organized as follows. Section 2 describes the concept of shared Big Data analytics. Section 3 describes the architecture of the Hadoop connector for VERITAS Cluster File System. Section 4 describes our experimental setup followed by our experiments and results in section 5. Section 6 tells us about additional use cases and benefits of our solution. The future work as a continuation to our current proposal has been described in section 7 followed by conclusion and citations.
II.SHARED DISK BIG DATA ANALYTICS In our study we compare the performance of Hadoop Distributed File System (HDFS), the de-facto file system in Apache Hadoop with a commercial cluster file system called VERITAS Storage Foundation Cluster File System (SF-CFS) by Symantec, with a variety of workloads and map reduce applications. We show that a clustered file system can actually match the performance of HDFS for map/reduce workloads and can even outperform it for some cases. We have used VMware virtual machines as compute nodes in our cluster and have used a mid-level storage array (Hitachi HUS130) for our study. While we understand that comparing a clustered file system running on top of a SAN to that of a distributed file system running on local disks is not an apple to apple comparison, but the study is mostly directed towards getting a proper and correct reasoning (if any) behind the notion of introducing a new storage model for Big Data analytics in datacenters of enterprises and organizations which are not operating at an internet scale. To have an estimate, we have run the same workload with HDFS in a SAN environment. Both SF-CFS and HDFS has been configured with their default settings/tunable in our experiments.
We have developed a file system connector module for SF-CFS to make it work inside Apache Hadoop platform as the backend file system replacing HDFS altogether and also have taken advantage of SF-CFS’s potential by implementing the native interfaces from this module. Our shared disk Big Data analytics solution doesn’t need any change in the Map Reduce applications. Just by setting a few parameters in the configuration of Apache Hadoop, the whole Big Data analytics platform can be made up and running very quickly.
III.ARCHITECTURE
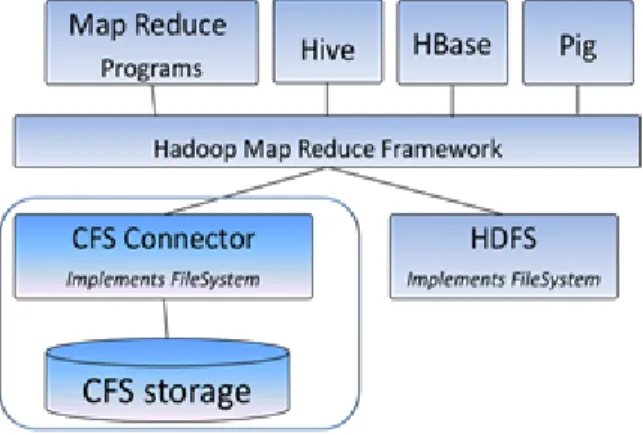
The clustered file system connector module we developed for Apache Hadoop platform has a very simple architecture. It removes the HDFS functionality from the Hadoop stack and replaces it with VERITAS Clustered File System. It introduces SF-CFS to the Hadoop class by implementing the APIs which are used for communication between Map/Reduce Framework and the File System. This could be achieved because the Map-Reduce framework always talks in terms of a well-defined FileSystem [6] API for each data access. The FileSystem API is an abstract class which the file serving technology underneath Hadoop must implement. Both HDFS and our clustered file system connector module implement this FileSystem class, as shown in Figure 1.
Figure 1. Architecture of SF-CFS Hadoop Connector
VERITAS Clustered File System being a parallel shared data file system, the file system namespace and the data is available to all the nodes in the cluster at any given point of time. Unlike HDFS, where a Name Node maintains the metadata information of the whole file system namespace, with SF-CFS all the nodes in the cluster can serve the metadata. Hence a query from Map Reduce framework pertaining to data locality can always be resolved by the compute node itself. The benefit of such a resolution is the elimination of extra hops traversed with HDFS in scenarios when data is not locally available. Also, the data need not be replicated across data nodes in case of a clustered file system.
Since, all the nodes have access to the data; we can say that the replication factor in SF-CFS is equivalent to the HDFS with replication factor equal to the no. of nodes in the cluster. This architecture does away with the risk of losing data when a data node dies and minimum replication was not achieved for that chunk of data. The usage of RAID technologies and vendor SLAs in storage arrays used in SAN environment can account to overall reliability of the data.
IV.EXPERIMENTAL SETUP
In this study on shared disk Big Data analytics, we have compared HDFS (Apache Hadoop 1.0.2) which is the default file system of Apache Hadoop and Symantec Corporation’s VERITAS Cluster File System (SFCFSHA 6.0) which is widely deployed by enterprises and organizations in banking, financial, telecom, aviation and various other sectors.
The hardware configuration for our evaluation comprises of an 8 node cluster with VMware virtual machines on ESX4.1. Each VM has been hosted on individual ESX hosts and has 8 vCPUs of 2.67GHz and 16GB physical memory. The cluster nodes are interconnected with a 1Gbps network link dedicated to Map Reduce traffic through a DLink switch. Shared storage for clustered file system is carved with SAS disks from a mid-range Hitachi HUS130 array and direct attached storage for HDFS is made available from local SAS disks of the ESX hosts. Each of the compute node virtual machine is running on Linux 2.6.32 (RHEL6.2).
Performance of HDFS has been measured both with SAN as well as DAS. The setup for HDFS-SAN consists of the same storage LUNs used for SF-CFS, but configuring in such a way that no two nodes see the same storage, so as to emulate a local disk kind of scenario. HDFS-Local setup uses the DAS of each of the compute nodes. In both cases, we used ext4 as the primary file system.
The following table summarizes the various scenarios we compared:
Scenario Description
SF-CFS Our solution
HDFS-SAN (1) HDFS in SAN with replication factor 1
HDFS-SAN (3) HDFS in SAN with replication factor 3
HDFS-Local (1) HDFS in Local Disks (DAS) with replication factor 1
HDFS-Local (3) HDFS in Local Disks (DAS) with replication factor 3
V.EXPERIMENTS
We have used TeraSort, TestDFSIO, MRbench and GridMix3 [7] for comparing the performance of
SF-CFS and HDFS. These are widely used map/reduce benchmarks and are available pre-packaged inside Apache Hadoop distribution.
In our performance evaluation, for TestDFSIO and TeraSort, we have done the comparison for HDFS replication factor of 1 as well as 3. We have used block size of 64MB for both HDFS (dfs.blocksize) and SF-CFS (fs.local.block.size) in our experiments.
TeraSort:
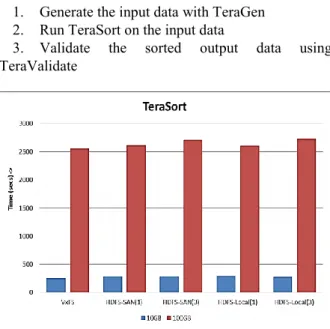
TeraSort is a Map Reduce application to do parallel merge sort on the keys in the data set generated by TeraGen. It is a benchmark that combines testing the HDFS and Map Reduce layers of a Hadoop cluster. A full TeraSort benchmark run consists of the following three steps:
1. Generate the input data with TeraGen 2. Run TeraSort on the input data
3. Validate the sorted output data using TeraValidate
Figure 2: TeraSort
Hadoop TeraSort is a Map Reduce job with a custom partitioner that uses a sorted list of n-1 sampled keys that define the key range for each reduce. Figure: 2 above illustrate the behavior of TeraSort benchmark for a dataset size of 10GB and 100GB. As observed, SF-CFS performs better than HDFS in all the different scenarios.
TABLE 1.TIME TAKEN FOR TERASORT (LOWER IS BETTER)
In map/reduce framework, the no. of map tasks for a job is proportional to the input dataset size for constant file system block size. Hence, the increase of dataset
Dataset GB SF-CFS HDFS SAN(1) HDFS SAN(3) HDFS Local(1) HDFS Local(3) 10 247 286 289 295 277 100 2555 2610 2707 2606 2725
size leads to higher concurrency and load at the file system as well as storage layer in case of a shared file system. Due to this, the performance gap between SF-CFS and HDFS is observed to have decreased with increase in dataset size.
TestDFSIO:
TestDFSIO is a distributed I/O benchmark which tests the I/O performance of the file system in a Hadoop cluster. It does this by using a Map Reduce job as a convenient way to read or write files in parallel. Each file is read or written in a separate map task [8].
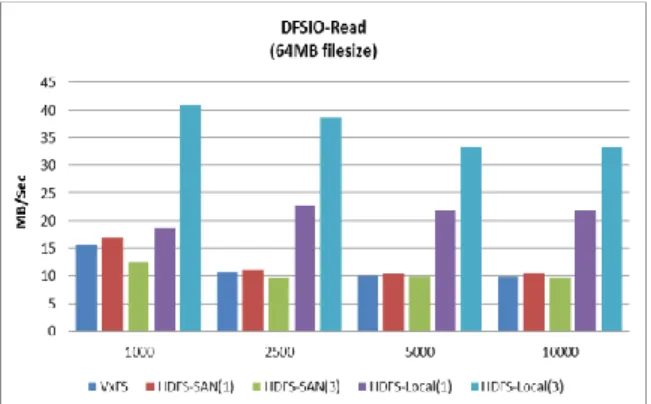
Figure 3: TestDFSIO Read (higher is better)
Figure 4: TestDFSIO Write (higher is better)
In our study, the performance tests are done on 64MB files and varying the number of files for different test scenarios as illustrated in figure 3 and 4 above.
It has been observed that HDFS significantly outperforms SF-CFS in read for both replication factor of 1 and 3. This is due to the fact that HDFS pre-fetches an entire chunk of data equal to the block size and HDFS don’t suffer from any cache coherence issues with its write-once semantics. HDFS-Local(3) gives an added advantage of read parallelism equal to the number of compute nodes, assuming the blocks are
evenly distributed/replicated across all nodes, which a shared file system lacks.
In TestDFSIO write, it is observed that HDFS with DAS with a replication factor of 1 outperforms SF-CFS. This performance improvement however comes at the cost of data loss in the event of node failures. In all other cases, SF-CFS performs similar or better than HDFS for TestDFSIO write workload.
MRBench:
MRbench benchmarks a Hadoop cluster by running small jobs repeated over a number of times. It tries to check the responsiveness of the Map Reduce framework running in a cluster for small jobs. It puts its focus on the Map Reduce layer and as its impact on the file system layer of Hadoop is minimal. In our evaluation we ran MRbench jobs repeated 50 times for SF-CFS, HDFS in SAN and HDFS in local disks for replication factor of 3. The average response time reported by MRBench in milliseconds was found to be best for SF-CFS:
TABLE 2.RESPONSE TIME OF MRBENCH (LOWER IS BETTER)
Use Case AvgTime (msec)
SF-CFS 54084
HDFS-SAN(3) 56090
HDFS-Local(3) 57234 GridMix3:
GridMix3 is used to simulate Map Reduce load on a Hadoop cluster by emulating real time load mined from production Hadoop clusters. The goal of GridMix3 is to generate a realistic workload on a cluster to validate cluster utilization and measure Map Reduce as well as file system performance by replaying job traces from Hadoop clusters that automatically capture essential ingredients of job executions. In our experiments, we used the job trace available from Apache Subversion, for dataset size of 64GB, 128GB and 256GB. We observed that SF-CFS performed better than HDFS in SAN as well as HDFS in local disks with replication factor of 3.
Figure 5: Time (s) Taken by GridMix3 (lower is better)
In the course of our study, we also compared the performance of SF-CFS with HDFS using the SWIM [9] benchmark by running Facebook job traces and have observed SF-CFS to perform better or at par with HDFS. SWIM contains suites of workloads of thousands of jobs, with complex data, arrival, and computation patterns which enables rigorous performance measurement of Map/Reduce systems.
VI.ADDITIONAL CONSIDERATIONS
In addition to comparable performance exhibited by SF-CFS for various Map/Reduce workloads and applications, SF-CFS provides the benefits of being a robust, stable and highly reliable file system. It gives the ability run analytics on top of existing data using existing analytics tools and applications, which eliminates the need for copy-in and copy-out of data from a Hadoop cluster, saving significant amount of time. SF-CFS also supports data ingestion over NFS. Along with all these, it brings in other standard features like snapshot, compression, file level replication and de-duplication etc. For example, gzip compression for the input splits with HDFS is not possible as it is impossible to start reading at an arbitrary point in a gzip stream, and a map task can’t read its split independently of the others [8]. However, if compression is enabled in SF-CFS, the file system will perform the decompression and return the data to applications in a transparent way. Data backups, disaster recovery are other built in benefits of using SF-CFS for big data analytics. SF-CFS solution for Hadoop, also known as Symantec Enterprise Solution for Hadoop™ is available as a free download for SF-CFS customers of Symantec Corporation [10].
VII.FUTURE WORK
During our study of the performance exhibited by a commercial cluster file system in Map/Reduce workloads and its comparison with a distributed file system, we observed that a significant amount of time is spent during the copy phase of the Map/Reduce model after map task finishes. In Hadoop platform, the input and output data of Map/Reduce jobs are stored in
HDFS, with intermediate data generated by Map tasks are stored in the local file system of the Mapper nodes and are copied (shuffled) via HTTP to Reducer nodes. The time taken to copy this intermediate map outputs increase proportionately to the size of the data. However, since in case of a clustered file system, all the nodes see all the data, this copy phase can be avoided by keeping the intermediate data in the clustered file system as well and directly reading it from there by the reducer nodes. This endeavor will completely eliminate the copy phase after map is over and bound to give a significant boost to overall performance of Map/Reduce jobs. This will require changes in the logic and code of Map/Reduce framework implemented inside Apache Hadoop and we keep it as a future work for us.
VIII.CONCLUSIONS
From all the performance benchmark numbers and their analysis, it can be confidently reasoned that for Big Data analytics need, traditional shared storage model cannot be totally ruled out. While due to architectural and design issues, a cluster file system may not scale at the same rate as a shared nothing model does, but for use cases where internet order scalability is not required, a clustered file system can do a decent job even in the Big Data analytics domain. A clustered file system like SF-CFS can provide numerous other benefits with its plethora of features. This decade has seen the success of virtualization which introduced the recent trends of server consolidation, green computing initiatives in enterprises. Big data analytics with a clustered file system from the existing infrastructure aligns into this model and direction. A careful study of the need and use cases is required before building a Big Data analytics platform, rather than going with the notion that shared nothing model is the only answer to Big Data needs.
ACKNOWLEDGEMENTS
We would like to thank the anonymous reviewers at Symantec for their feedback on this work; Niranjan Pendharkar, Mayuresh Kulkarni and Yatish Jain contributed to the early design of the clustered file system connector module for Apache Hadoop platform.
REFERENCES [1] Apache Hadoop. hadoop.apache.org
[2] K. Shvachko, Hairong Kuang, S. Radia and R Chansler – The Hadoop Distributed File System. Mass Storage Systems and Technologies (MSST), 2010 IEEE 26th Symposium 3-7 May 2010
[3] Powered by Hadoop.
http://wiki.apache.org/hadoop/PoweredBy
[4] J. Dean and S. Ghemawat. Mapreduce: Simplified data processing on large clusters. In Sixth Symposium on Operating System Design and Implementation, pages 137–150, December 2004
[5] Rajagopal Ananthanarayanan, Karan Gupta, Prashant Pandey, Himabindu Pucha,Prasenjit Sarkar, Mansi Shah, Renu Tewari, IBM Research
Cloud Analytics: Do We Really Need to Reinvent the Storage Stack? USENIX: HotCloud '09
[6] Apache Hadoop File System APIs.
hadoop.apache.org/common/docs/current/api/org/apache/hadoo p/fs/FileSystem.html
[7] GridMix3.
developer.yahoo.com/blogs/hadoop/posts/2010/04/gridmix3_e mulating_production/
[8] Hadoop: The Definitive Guide, Third Edition by Tom White (O’Reilly - 2012)
[9] SWIMProjectUCB.
github.com/SWIMProjectUCB/SWIM/wiki [10] Symantec Enterprise Solution for Hadoop™
![Figure 5: Time (s) Taken by GridMix3 (lower is better) In the course of our study, we also compared the performance of SF-CFS with HDFS using the SWIM [9] benchmark by running Facebook job traces and have observed SF-CFS to perform b](https://thumb-us.123doks.com/thumbv2/123dok_us/1291336.2673165/5.918.109.434.107.318/figure-gridmix-compared-performance-benchmark-running-facebook-observed.webp)
