A CRITICAL EVALUATION OF
BAYESIAN CLASSIFIER
FOR LIVER DIAGNOSIS USING
BAGGING AND BOOSTING METHODS
Bendi. Venkata Ramana1
Associate Professor, Dept.of IT, Aditya Institute of Technology and Management, Tekkali, Andhra Pradesh, India.
Prof. M.Surendra Prasad Babu2
Department of Computer Science and Systems Engineering, Andhra University, Visakhapatnam-530 003, Andhra Pradesh, India.
Prof. N.B. Venkateswarlu3
Senior Professor, Dept.of CSE, Aditya Institute of Technology and Management, Tekkali, Andhra Pradesh, India.
Abstract:
Classification techniques are widely used in the application of medical-related fields. In this paper Bayesian classification technique with Bagging and Boosting is used for the diagnosis of Liver diseases enhance the performance of the classifier. Liver diseases are not easily identified in it’s early stage as it is functioning normally even it is partially damaged. Early diagnosis of the liver diseases may increase survival rate of patients.
Keywords: Liver Diagnosis, Bayesian Classification, Bagging, Boosting
1. Introduction
Bayesian classification technique is very popular in the field of medical diagnosis. Liver damages are categorized into 1) structural liver damage and 2) functional liver damage. This paper concentrates on fun ctional liver damages that analyzes levels of enzymes in the blood to determine the liver functionality[1].In this paper Bayesian classification is used with bagging and boosting for more accuracy in the diagnosis of liver diseases. Simple blood test is used for identifying the presence of certain liver enzymes in the blood [1]. The liver function tests are used to measure enzymes and proteins made by the Liver in the blood [2].
Liver diseases generally may be classified as i) Hepatocellular, ii) Cholestatic (obstructive) and iii) Isolated elevation of the bilirubin. Features of liver injury, inflammation, and necrosis predominate, which may cause viral hepatitis or alcoholic liver disease, may be classified as hepatocellular pattern. Features of Inhibition of bile flow predominate, which may cause gall stone or malignant obstruction, primary biliary cirrhosis, some drug-induced liver diseases, may be classified as cholestatic pattern. Diseases such as direct Hyper bilirubinemia and indirect Hyper bilirubinemia may be classified as Isolated elevation of the bilirubin pattern[6].
2. Naive Bayesian Classification
1. Let D be a training set of tuples and their associated class labels. Each tuple is represented by an n-dimensional attribute vector, X= (X1, X2,.. Xn), depicting n measurements made on the tuple from n attributes, respectively, A1, A2,…. , An.
2. Suppose that there are m classes, C1, C2,..., Cm. Given a tuple, X, the classifier will predict that X belongs to the class having the highest posterior probability, conditioned on X.
That is, the naïve Bayesian classifier predicts that tuple X belongs to the class Ci if and only if
P (Ci /X) > P(Cj/X) for 1≤ j≤ m; j ≠ i: (1)
Where P (Ci /X) is maximum posteriori hypothesis for the class Ci. P (Ci /X) can be calculated by using the formula.
XP C P C X P X C P i i i
3. As P(X) is constant for all classes, only P(X/ Ci)P(Ci) needed to be maximized.
If the class prior probabilities are not known, then it is commonly assumed that the classes are equally likely, that is,
P(C1) = P(C2) =….. = P(Cm). (3) P(Ci /X) = P(Xj/ Ci).
Otherwise
P(Ci /X) = P(X/Ci)P(Ci). (4)
Note that the class prior probabilities may be estimated by P (Ci) =|Ci, D|/|D|, where |Ci, D| is the number of training tuples of class Ci in D.
4. Given data sets with many attributes, it would be extremely computationally expensive to compute P(X/Ci). In order to reduce computation in evaluating P(X/Ci), the naive assumption of class conditional independence is made. This presumes that the values of the attributes are conditionally independent of one another, given the class label of the tuple i.e., that there are no dependence relationships among the attributes.
Thus,
)
/
(
)
/
(
1
n k i ki
x
c
c
p
X
P
(5)= P (X1|Ci) × P (X2|Ci) ×… P (Xn|Ci)
Probabilities P(X1/Ci), P(X2/Ci),…. are easily estimated from the training tuples. Recall that that here Xk refers to the value of attribute Ak for tuple X which may be categorical or continuous-valued. For instance, to compute P(X/Ci), the following are considered:
(a) If Ak is categorical, then P (Xk/Ci) is the number of tuples of class Ci in D having the value Xk for Ak, divided by |Ci, D|, the number of tuples of class Ci in D.
(b) If Ak is continuous-valued, then a continuous-valued attribute is typically assumed to have a Gaussian distribution with a mean μ and standard deviation s, defined by
g(X, μ, σ) =
2 2
2
2
1
xe
(6)and therefore
P(Xk|Ci) = g(Xk, μCi , Ci ).
5. In order to predict the class label of X, P (X|Ci) P (Ci) is evaluated for each class Ci. The classifier predicts that the class label of tuple X is the class Ci if and only if
3. Bagging
Bagging can improve the accuracy of a Classifier. The term bagging stands for Bootstrap aggregation. Given a set D, of d tuples, bagging works as follows. For iteration i=1,2,..k, a training set , Di , of d tuples is sampled with replacement form the original set of tuples , D. Each training set is a bootstrap sample is used with replacement. The accuracy can be increased because the composite model reduces the variance of the individual classifiers.
4. Boosting
Boosting is an ensemble method that is similar in concept to Bagging. Boosting trains the next weak learners based on the mistakes of previous learners. Normally , boosting results in better performance over bagging. However it has a risk of over fitting and thus the performance of combined hypothesis might be worse than the performance of a single hypothesis. Besides boosting requires a very large training set sample and is unsuitable for small data sets.
5. Results
In total, 751 patient details are used in this experimentation. Patients are chosen from Andhra Pradesh state of India. The features used are Gender, Age, Total bilirubin, Direct bilirubin, Indirect bilirubin, Total proteins, Albumin, Globulin, A/G ratio, SGOT, SGPT and ALP. Samples are labeled by a Gastroenterologist, who classified patients into five groups.
The notations employed in this study are
C1 is Direct Hyper Bilirubinemia
C2 is Indirect HyperBilirubinemia
C3 is Hepato Cellular Pattern
C4 is Cholestatic Pattern
C5 is No Liver Involvement
The dataset was divided into 10 parts of which 9 parts were used as training sets and the remaining part is used as testing set. Repeating these 10 folds ensures that each part is used for training and testing while minimizing the sampling bias.For the purpose of experimentation Weka 3-4-10jre, Data Mining open source machine learning software, was used on i7 processor with 4 GB RAM.
Table 1: Results of Liver diagnosis of Male
Table 2 :Results of Liver diagnosis of Female
Age(Years) 1 to 5 6 to 15 16 to 40 Above 40
# Samples 48 62 189 94
# Male with Disease 19 1 29 36
% Male with Disease 39.58 1.61 15.34 38.29
Classifier Accuracy 89.58 98.37 94.7 87.23
Bagging 97.91 98.38 97.88 91.48
Boosting 93.75 98.38 95.76 79.78
Age(Years) 1 to 5 6 to 15 16 to 40 Above 40
# Samples 48 79 169 62
# Female with Disease 31 28 32 4
% Female with Disease 64.58 35.44 18.93 6.45
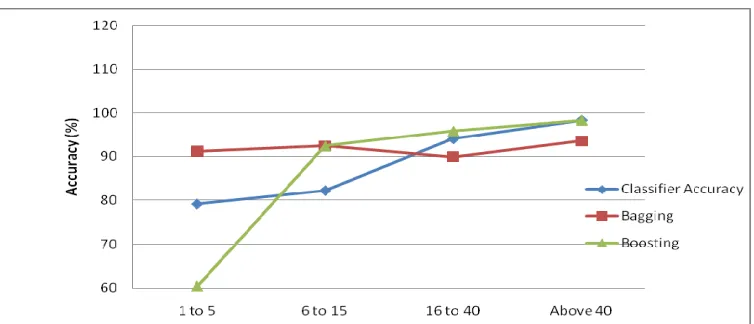
Classifier Accuracy 79.16 82.27 94.08 98.38
Bagging 91.16 92.40 89.94 93.54
Fig. 1. Chances of liver diseases for the men and women for different age groups
Fig. 2. Performance of Bayesian classifier with bagging and boosting for men
The results indicate that in the age group of one year to five years both men and women have more chances of liver disease. Female patients have more chances to liver damage. Bagging and Boosting increases the accuracy of the Bayesian Classifier for both men and women. The classification accuracy was taken as the average of the predictive accuracy values.
6. Conclutions
In the present work Bayesian Classification is proposed for diagnosis of liver diseases. The Bayesian Classification is combined with Bagging and Boosting for better accuracy. This accuracy can be further improved with huge amount of data.
7. Acknowledgements
We take this opportunity with much pleasure to thank Prof. N.B. Venkateswarlu for his helpful comments made during the collection and analysis of data required for this paper. Also we would like to thank Dr. Bevera. Lakshmana Rao in labeling samples.
8. References
[1] Rong-Ho Lin. An intelligent model for liver disease diagnosis. Artificial Intelligence in Medicine 2009;47:53—62.
[2] Schiff's Diseases of the Liver, 10th Edition Copyright ©2007 Lippincott Williams & Wilkins by Schiff, Eugene R.; Sorrell, Michael F.; Maddrey, Willis C.
[3] T. Menzies, J. Greenwald, A. Frank, Data mining static code attributes to learn defect predictors, IEEE Transactions on Software Engineering 33 (1) (2007) 2–13.
[4] P. Domingos, M. Pazzani, On the optimality of the simple bayesian classifier under zero-one loss, Machine Learning 29 (2–3) (1997) 103–130.