Finding Closed Correlated documents in
DDB using all-conf
K.REDDY MADHAVI 1 Assistant Professor, Dept.of CSE SSITS, Rayachoty, Kadapa. pin:516269
DR.T.V. RAJINI KANTH Professor and HOD of IT Dept,
GRIET, Hyderabad,
DR. A. VINAYA BABU Professor, Dept. of CSE,
Director, Admissions
JNTU College of Engineering, Hyderabad,
C.GEETHA
Assistant Professor, Dept.of ECE SSITS, Rayachoty, Kadapa. pin:516269
Abstract :
Correlation-Rule mining has been growing popularly as an augmentation of association rule mining. It uses correlation measure and pattern interestingness measures to generate correlation rules. Though Correlation-Rule mining generates significantly less number of rules compared to associative rule mining, it still generates quite large number of rules. In this paper, we propose closed correlated mining by using all-conf (all-confidence) to reduce the number of the correlated patterns produced without information loss. We first propose a new notion of the confidence-closed correlated patterns, and then an algorithm to generate closed correlated patterns. The results shown that closed correlated patterns are less when compared to correlated patterns.
Keywords: all-conf measure, closed-correlated patterns, DDB
1. Introduction
Information retrieval (IR) is the area of study concerned with searching for documents, for information within documents, and for metadata about documents, as well as that of searching relational databases and the WWW. There is overlap in the usage of the terms data retrieval, document retrieval, information retrieval, and text retrieval, but each also has its own body of literature, theory, praxis, and technologies. IR is interdisciplinary based on computer science, mathematics, library science, information science, information architecture, cognitive psychology, linguistics, and statistics. Many universities and public libraries use IR systems to provide access to books, journals and other documents. Web search engines are the most visible IR applications.
The rest of the paper is organized as follows. Section 2 provides basic concepts of interestingness measures and all-confidence. Section 3 provides properties of confidence-closed patterns. Section 4 . Section 5 concludes with its future work.
2. Basic Concepts and all-conf
Let D = {d1, d2, . . . , dm} be a set of documents, and DDB be a Document database that consists of a set of
documents. Each document is associated with an identifier, called DocID (DocumentID). Let A be a set of documents, referred to as an Docset (Document set) The Docset that contains k items is a k-Docset. The support (it is an interestingness measure) of Docset X in DDB, denoted as sup(X), is the number of documents in DDB containing X. The Docset X is frequent if it occurs no less frequent than a user-defined minimum support threshold and can be considered as significant.
To say that the document retrieved from DDB is relevant, it must not only satisfy the interestingness measures but also it is necessary to know the correlation among retrieved documents.
UV [support, confidence, correlation]
Among so many correlation measures all-confidence is emerging because of its null-invariance property. The all confidence of Docset X is the minimal confidence among the set of rules dj→X −dij, where dj € X. Its formal
definition is given as follows. Here, the max document sup of an Docset X means the maximum (single) document support in DDB of all the documents in X.
.
Definition 1. (all-confidence of Docset)
Given the Docset X = {d1, d2, . . . , dk},the all confidence of X is defined as,
max document sup(X) = max{sup(dj)|∀dj € X} (1)
all conf(X) = sup(X) / max document sup(X) (2)
Given a DDB, a minimum support threshold min sup and a minimum all confidence threshold min α, a frequent Docset X is all confident or correlated if all conf(X) ≥ min α and sup(X) ≥ min sup.
Although the all confidence measure reduces significantly the number of retrieved documents, it still generates quite a large number of patterns, some of which are redundant. This is because retrieving a long pattern may generate an exponential number of sub-patterns due to the downward closure property of the measure. For frequent docsets, there have been several studies proposed to reduce the number of documents retrieved, including closed [9], maximal [10], and compressed (approximate) [11] docsets. Among them, the closed docsets retrieval ,which retrieves only those frequent docsets having no proper superset with the same support, limits the number of patterns produced without information loss. It has been shown in [12] that the closed docsets generates orders of magnitude smaller result set than frequent docsets.
3. Confidence-Closed Correlated Documents
Finding closed Docsets serves as an effective method to reduce the number of documents produced without information loss in frequent Docsets. Motivated by this, the notion of closed pattern has been ectended so that it can be used in the domain of retrieving correlated docsets. The formal definitions of the original and extended ones was presented in Definitions 2 and 3, respectively.
Definition 2. (Support-Closed Docset)
The Docset Y is a support-closed (correlated)docset if it is frequent and correlated and there exists no proper superset Y1⊃ Y such that sup(Y1
Since the support-closed docset is based on support, it cannot retain the confidence information—notice that in this paper confidence means the value of all confidence. In other words, support-closed causes information loss. It is shown in an example1 as
Example 1. Let docset PQRST be a correlated pattern with support 30 and confidence 30% and docset RST be one with support 30 and confidence 80%. Support-closed pattern mining generates PQRST only eliminating RST since PQRST is superset of RST with the same support. We thus lose the pattern RST. However, RST might be more interesting than PQRST since the former has higher confidence that the latter. We thus extend the support-closed docset to encompass the confidence so that it can retain the confidence information as well as support information.
Definition 3. (Confidence-Closed docset)
The docset Y is a confidence-closed docset if it is correlated and there exists no proper superset Y1⊃ Y such
that sup(Y1
) = sup(Y ) and all conf(Y1
)= all conf(Y ).
By applying definition 3 to Example 1, it is obtained that not only docset PQRST but also RST as confidence-closed docsets since they have different confidence values and therefore no information loss occurs. In the rest of our paper, we call the support-closed pattern as SCP and the confidence closed pattern as CCP, respectively.
For generating confidence closed correlated documents, the following algorithm is used.
The algorithm adopts a pattern-growth methodology proposed in [14]. In the previous studies (e.g., CLOSET+ [13] and CHARM [15]) for mining SCPs, two search space pruning techniques, document merging and sub-docset pruning, have been used. However, if these techniques are applied directly into confidence-closed pattern then the complete set of CCPs cannot be obtained. This is because if there
exists a pattern, these techniques remove all of its sub-patterns with the same support without considering confidence. Hence these optimization techniques are modified so that they can be used in confidence-closed pattern generation
Lemma 1. (confidence-closed document merging)
Let X be a correlated docset. If every DocID containing docset X also contains docset Y but not any proper superset of Y , and all conf(XY) = all conf(X), then XY forms a confidence closed docset and there is no need to search any docset containing X but no Y .
Lemma 2. (confidence-closed sub-docset pruning)
Let X be a correlated docset currently under construction. If X is a proper subset of an already found confidence-closed docset Y and all conf(X) = all conf(Y ) then X and all of X’s descendants in the set enumeration tree cannot be confidence-closed docsets and thus can be pruned.
Algorithm which is based on the extension of CLOSET+ [13] and integrates the above discussions into the CLOSET+ is shown below. Among a lot of studies for support-closed pattern mining, CLOSET+ is the fastest algorithm for a wide range of applications. This algorithm uses another optimization technique to reduce the search space by taking advantage of the property of the all confidence measure. Lemma 3 describes the pruning rule.
Algorithm for confidence-closed correlated patterns(CCCP)
Input: A document database DDB; a support threshold min_ sup a minimum al-l confidence threshold min α Output: The complete set of confidence-closed correlated patterns.
Method:
1. Let CCP be the set of confidence-closed patterns. Initialize CCP ← 0
1: For each document Y in f_ list such that it appears in each DocID of DDB, delete Y from f list and set α← Y
∪ α if all conf(Y α) ≥all conf(α), otherwise insert Y into candidateList in the support increasing order; {confidence-closed document merging}
2: call GenerateCCP(α, candidateList, CCP);
3: build FP-tree for DDB using f_ list, which excludes all the documents Y s in the previous step; 4: for each ai in f _list (in reverse descending support order) do
5: set β = α∪ ai;
6: call GenerateCCP(β, candidateList, CCP);
7: get a set Dβ of documents to be included in β-projected database; {counting space pruning rule} 8: for each document in Dβ, compute its count in β-projected database;
9: for each bj in Dβ do
10: if sup(βbj)< min sup, delete bj from Dβ; {pruning based on min sup} 11: if all conf(βbj )< min α, delete bj from Dβ;{pruning based on min α} 12: end for
13: call FP-mine(β, DDB, f_ list, CCP, candidateList);
14: delete the documents that was inserted in step 1 from candidateList; 15: end for
Procedure GenerateCCP( α, candidateList, CCP) for k-docset Y = Y1 . . . Yk(Yi ∈ candidateList) do
add α∪ Y into CCP if all conf(α∪ Y ) ≥ min α if α∪ Y is not a subset of X (in CCP) with the same support and confidence; {confidence-closed sub-Docset pruning}
end for
Lemma 3. (counting space pruning rule) Let α = d1d2 . . . dk. In the α-conditional database, for document x to be included in an all confident pattern, the support of x should be less than sup(α)/min α.
Proof. In order for αx to be an all confident pattern, max document sup(αx) ≤ sup(αx)/min α. Moreover, |sup(α)|
≥ |sup(αx)|. Thus, max document sup(αx) ≤sup(α)/min α. Hence the lemma.
With this pruning rule, we can reduce the set of documents Dβ to be counted and thus, reduce the number of
nodes visited when we traverse the FP-tree to count each document in Dβ.
To work on this, let us consider the following database
Sample DDB : Table: 1
Refined DB
Let the min_ sup=3 and min α = 50%. Scan DB once and arrange the documents in descending order of their support (header table) and ignore the documents that do not satisfy min_sup and construct FP-tree.
DocID Documents
1 A B C D E F G H I
2 B C D E K J
3 C E F G H
4 B C D E M
5 F C B A H I
6 F C D I
7 B C D H
8 B M L
9 A M
10 C M B
11 A B C F H I
Fig: Header table and FP-tree
Then f_ list=<C:10,B:8, D:6, F:6, H:6, A:5, I:5, E:4, M:4>
Let us know the confidence-closed patterns with prefix M=4 , documents in M-projected database include C,B, D,A,E (it is from FP-tree)
The support of z(z ∈ { C,B, D,A,E }) should be less than or equal to sup(M)/min α = 4/0.5=8.With this pruning, Document C gets eliminated because it is greater than 8. . Now, compute counts of documents B, D, A, and E from M-projected database. They are 8,4,1 and 2 respectively. A and E are pruned since their support is less than min_sup. B cannot be pruned since their confidence = 4/8=0.5(it is not less than min α)hence CCP is BM=3
4. Results and Discussions
This algorithm was implemented using JAVA by considering no. of datasets. On working with no. of
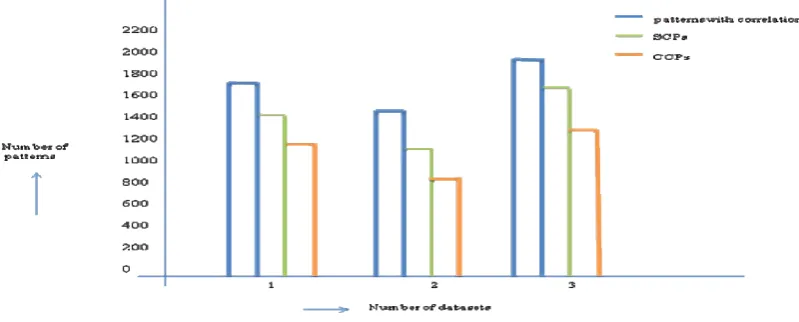
datasets it is observed that, by using correlation measure the number of patterns are less when compared to simple association rule patterns using support and confidence. But even correlation patterns are more, hence closed correlated patterns are generated with all-conf which are even less compared to correlated patterns. It is shown in fig1 below.
5. Conclusion and Future work
In this paper,we have presented an approach that can effectively reduce the number of correlated patterns to be retrieved without information loss. We proposed a new notion of confidence-closed correlated patterns that have no proper superset with the same support and the same confidence. For those patterns,we presented the CCCP algorithm. Several pruning methods have been developed that reduce the search space. Our performance study shows that confidence-closed,correlated patterns reduces the number of patterns by atleast an order of magnitude in comparison with correlated (non-closed)patterns
Acknowledgements
We would like to thank our colleagues in the Department of Computer Science Engineering for their advice and helpful discussions. We are grateful to Dr. C. Nageswara Raju, Associate Professor, SV Group of Institutions, kadapa, for his support in all aspects. We thank Dean of Academics Dr. P. Kannaiah and Dr.M.Murali Krishna, Principal, SSITS for his moral support and providing Laboratory. We are grateful to the British Library and JNTUniversity Library for their services.
References
[1] 1.C.C.AggarwalandP.S.Yu.Anewframeworkforitemsetgeneration.InProc.1998ACMSymp.PrinciplesofDatabase Systems(PODS’98),pages18–24,Seattle, WA,June1999
[2] S.Brin,R.Motwani,andC.Silverstein.Beyondmarketbasket:GeneralizingassociationrulestocorrelationsProc.1997ACM-SIGMODInt.Conf.Managementof Data(SIGMOD’97),pages265–276,Tucson,Arizona,May1997.
[3] S.MorishitaandJ.Sese.Traversingitemsetlatticewithstatisticalmetricpruning.InProc.2000ACMSIGMOD
SIGACT-SIGARTSymp.PrinciplesofDatabaseSystems(PODS’00),pages226–236,Dallas,TX,May2001.
[4] P.-N.Tan,V.Kumar,andJ.Srivastava.Selectingtherightinterestingnessmeasureforassociationpatterns.In
Proc.2002ACMSIGKDDInt.Conf.KnowledgeDiscoveryinDatabases(KDD’02),pages3241,Edmonton,Canada,July2002. [5] E.Omiecinski.Alternativeinterestmeasuresforminingassociations.IEEETrans.KnowledgeandDataEngineering,1 5:57–69,2003.
[6] Y.-K.Lee,W.-Y.Kim,D.Cai,andJ.Han.CoMine:EfficientMiningofCorrelatedPatterns.In Proc 2003 Int.Conf data
Mining(ICDM’03),pages581–584,Melbourne,FL,Nov.2003.
[7] S.MaandJ.L.Hellerstein.Miningmutuallydependentpatterns.InProc.2001Int.Conf.DataMining(ICDM’01),pages409– 416,SanJose,CA,Nov.2001.
[8] H.Xiong,P.-N.Tan,andV.Kumar.MiningStrongAffinityAssociationPatterns in data sets with skewed support Distribution.In Proc.2003Int.Conf.DataMining(ICDM’03),pages387–394,Melbourne,FL,Nov.2003.
[9] N.Pasquier,Y.Bastide,R.Taouil,andL.Lakhal.Discoveringfrequentcloseditemsetsforassociationrules.In Proc 7th
Int.Conf.DatabaseTheory(ICDT’99),pages398–416,Jerusalem,Israel,Jan.1999.
[10] R.J.Bayardo.Efficientlymininglongpatternsfromdatabases.InProc.1998ACM-SIGMODInt .Conf Management
ofData(SIGMOD’98),pages85–93,Seattle,WA,June1998.
[11] J.Pei,G.Dong,W.Zou,andJ.Han.Oncomputingcondensedfrequentpatternbases.InProc.2002Int.Conf.onDataMi ning(ICDM’02),pages378–385,Maebashi,Japan,Dec.2002.
[12] M.Zaki.GeneratingNon-redundantAssociationRules.In Proc.2000ACM SIGKDD Int.Conf Knowledge Disco-
eryinDatabases(KDD’00),Aug.2000.
[13] .J.Wang,J.Han,andJ.Pei.Closet+:Searchingforthebeststrategiesforminingfrequentcloseditemsets.In Proc .2003
[14] J.Han,J.Pei,andY.Yin.Miningfrequentpatternswithoutcandidategeneration.InProc.2000ACM-SIGMODInt. Conf.ManagementofData(SIGMOD’00),pages 1–12,Dallas,TX,May2000.
[15] M.ZakiandC.Hsiao.CHARM:AnEfficientAlgorithmforClosedItemsetMining,In Proc.SDM’02,Apr.2002.
Ms.K. Reddy Madhavi, obtained Bachelor of Technology in Mechanical Engineering from SVU,Tirupati and Master of Technology in Computer Science Engineering from JNTU. Working as Asst.Professor in CSE and member of R&D in an organization.
Dr.A.Vinay Babu obtained his Bachelors degree in Electronics & Communication Engineering from Osmania University. Has duel Masters Degree, one in Computer Science & Engg and the other one is in ECE from JNTU. He obtained his PhD from JNTU, Hyderabad. His research area is Data Mining and Image processing.