Volume-5 Issue-1
International Journal of Intellectual Advancements
and Research in Engineering Computations
Multi-objective scheduling workflow applications in cloud
computing
A.Sujitha1, Dr.N.Shanthi2. PG Student1, Professor2
Department of Computer Science and Engineering
Nandha Engineering College,Perundurai, Erode-638052.
[email protected] ,[email protected]
Abstract - Cloud computing has emerged as a computing paradigm that supports computing services to remote clients with heterogeneous request. It is widely known that the scheduling
in an exceedingly distributed computing
platform may be a NP-hard problem. The matter turns out to be significantly more difficult once an outsized assortment of tasks on virtual machines under a cloud setting. This work aims for creating an efficient multi-objective optimization technique for dealing with a workflow scheduling drawback on an Infrastructure as a Service (IaaS) environment. Most importantly, it includes exploiting the domain information for the event of novel answer encoding scheme, population formatting methods, fitness assignment ways and genetic offspring generation operators. Besides, it includes the event of powerful strategies for taking care of issues with an outsized variety of goals.
Keywords: Cloud computing, evolutionary algorithm, Infrastructure as a Service, multi-objective optimization, workflow scheduling.
I. INTRODUCTION
Distributed computing gives a propelling innovation which encourages the execution of logical and modern applications. This gives an on request, flexible and ascendable administrations to clients through a compensation for every utilization premise. This offers three sorts of administrations:
IaaS(Infrastructure as a
Service),PaaS(Platform as a
Service),SaaS(Software as a Service). These administrations are offered absolutely with various administration levels to meet the prerequisites of different customer groups. (e.g., computing services, storage services, network services, etc) They take issue from each other by non-practical qualities named as QoS (Quality of Service) parameters, similar to service time, service price, service availability, service energy consumption, service utilization.
These QoS parameters is planned and arranged by very surprising SLAs (Service Level Agreements). A SLA determines the QoS of negotiated resources, the base desires and constrains that exist amongst clients and providers. Applying such a SLA represents a coupling contract. Absence of such assertions will lead applications to move a long way from the cloud and can bargain the long run development of distributed computing.
Because of the significance of work process applications, numerous examination are directed to create workflow administration frameworks with scheduling algorithms. Those frameworks are regularly seen as a kind of administration encouraging the logical and modern applications on the matrix and cloud by covering their organizations and executions. In order to successfully plan the
errands and information applications on these cloud environments, workflow administration frameworks require extra point by point planning strategies to satisfy QoS imperatives and the priority connections between work process assignments. The investigation of work process scheduling is changing into a significant test inside the space of distributed computing.
The work process scheduling inside the cloud might be a difficult task. This disadvantage is significantly harder once there are many components to be contemplated especially, the arranged QoS needs of customers like administration time interim, benefit value, the nonuniformity, dynamicity and physical property of cloud administrations; the various courses in which of blending these administrations to execute workflow assignments; the exchange of enormous volumes of information. However the workflow process scheduling drawback is viewed as a combinatorial disadvantage, wherever it's not possible to look out for the best answer by victimisation straightforward algorithms or rules.
The majority of the work planning have focused exclusively on 2 QoS parameters especially, the point and spending plan. While proposing this concept we have an idea of extending these attempts to deal with numerous QoS needs. We tend to address the QoS-based workflow planning that expects to decrease the cost and total time execution of client applications according to the SLA. We have a tendency to achieve this by the exploitation process of multi-objective optimization techniques. The artificial and real world applications are used to run the simulation to achieve the planned process. This new multi-objective formula considerably improves the performance of interrelated approaches.
The rest of this paper is sorted out as follows. Segment 2 surveys many associated works. Segment 3 exhibits the matter
demonstrating the QoS fundamentally based on progressing the schedule. Segment 4 portrays altogether that our planning heuristic known as evolutionary multi-objective optimization strategy. Segment 5 demonstrates a experimental analysis of our heuristic. Area 6 closes the paper and examines some future works.
II. RELATED WORK
Work process is one among the pre-eminent regular applications in distributed computing, and workflow process planning has drawn high degree of interests within the current years. Until now, an variety of workflow scheduling algorithm are produced. Among the present workflow scheduling approaches, they'll be separated into 3 classes: list-based, cluster based, meta-heuristic-based. for instance, Durillo et al. arranged a list-based work flow scheduling heuristic (indicated as MOHEFT) to frame trade-off amongst makespan and energy utilization [1]. Lee et al. arranged 2 programming arrangements that first extend the schedule to makespan, then minimize the output to diminish resource usage [2]. There's an outsized assemblage of work with workflow scheduling approaches for upheld assignment. for example, Abrishami et al. arranged a scheduling algorithm, named PCP, for utility networks to understand each limiting a work process execution cost and ensuring the work process point in time [3].
cloud platform [6]. Being that, the igher existing methodologies are intended for one work process, and ignored the instabilities of assignment execution times, by this way the dynamic way of work process applications works in cloud environment.
Calheiros et al. planned an algorithm to duplicate workflow assignments, that mitigates the outcomes of resources differed performance on work processes target dates [7]. Tang et al. built up an random heuristic to decrease the makespan for work flow [8]. Zheng et al. arranged an approach, supported a town technique, to address the instabilities in task execution times [9]. Rodriguez et al. fixated on the execution variety of VMs, the presented algorithmic program, upheld Particle Swarm streamlining (PSO), to decrease the workflow execution cost while meeting its point in time limitation [10]. However these methodologies are intended for one work process, and aren't adequate for dynamic cloud environment, wherever various workflow will be submitted every once in a while. one among the first wide utilized heuristics for programming workflow application is that the Heterogeneous Earliest Finish Time (HEFT) calculation created by Topcuoglu et al. [11]. HEFT might be a static scheduling algorithm that makes an endeavor to decrease execution time (makespan). It saves the workflow priority constraints and produces a better average schedule length.
The majority of those past works have focused on limiting the workflow execution time while not considering the clients budget limitation. In any case, with the market-oriented business plan of action in distributed computing environment, wherever clients are curved for their utilization of resources, many works that consider clients financial plan and point in time are planned [12,13]. In [14], a review demonstrating the best approach to schedule logical workflow applications with budget plan and point in time limitations onto
frameworks exploitation genetic algorithm is offered.
III. PRELIMINARY A.Workflow Definition
The general model for representing workflow process is to utilize Direct Acyclic Graph (DAG). A workflow process is a DAG W = (T, D), where T = {T0, T1, . . . , Tn} is the group of tasks and D = {(Ti , Tj )|Ti , Tj ∈ T} is the set of information or control conditions. The weights relates to the errands represents their reference execution time, which is the time of running the undertaking task on a processor of a particular type, and the weights joined to the edges represents the size of the information exchanged between tasks. The reference execution time of Ti is meant as refertime(Ti) and the information exchange size from Ti to Tj is signified as data(Ti, Tj ).With this we characterize all ancestors of tasks Ti as pred(Ti) = {Tj | (Tj , Ti) ∈ D}. (1) For a given W, Tentry indicates a entry errand fulfilling pred(Tentry) =, and Texit means a leave errand fulfilling Ti∈ T : Texit ∈ pred(Ti). (3) Most scheduling algorithms need a DAG with a solitary Tentry and a solitary Texit, which can be effectively guaranteed by including a pseudo Tentry or potentially a pseudo Texit with zero weight to the DAG. In the proposed system, we additionally expect that the given work process has single Tentry and Texit.
B.Cloud Resource Management
In Infrastructure as a Service (IaaS) environment, the virtual machines are utilized to give computational resources, where a running virtual machine is called an instance. Despite the fact that its original size is normally obscure to people in general, a business IaaS environment is usually considered having countless instances. In 2013, Cycle Computing could construct a cluster with 156,314 centers on Amazon EC2.
examples accessible in Amazon EC2. In light of these perceptions, we expect that the most extreme number of the occurrences that a client can provision is boundless. We hence characterize an infinite set I = {I0, I1, . . .} to portray every accessible instances in an IaaS environment, and a set P = {P0, P1, . . . , Pm} to represent all instance types where m is the quantity of the instances. Since an assignment can just keep running on one case, I can essentially be viewed as a set with a similar size of T. Compute Unit (CU) or similar ideas are as of now utilized by IaaS providers to portray the CPU capacities of various occurrence types. We utilize CU(Pi) to represent the Compute Unit of instance type Pi. In the proposed system, all tasks are thought to be parallelizable so that the multicore CPUs can be completely utilized. It is normal that, if CU of an instance is multiplied, the execution time of the errands running on it would be divided. We likewise expect that the reference execution time of an errand is the time of executing this assignment on a instance whose CU equals 1. With these suspicions, the real running time of task Ti, running on an instance of type Pj.
The communication data transfer capacities are typically unique for various instance types, and the way that sorts with higher CU have higher transmission capacities is natural. Here we utilize bw(Pi) to represent to the data transmission of instance type Pi . The communication time between errand Ti and Tj , while overlooking setup delays, can be figured by where Pp and Pq are the types of the instances to which Ti and Tj are scheduled, individually. For every single existing IaaS environment, the fundamental estimating rule is of same charging as per-instance use. Being that, the itemized estimating methodologies are distinct. Due to the assortment of valuing models, a generic scheduling algorithm intended for IaaS environment should not be founded on any current estimating model. Here we utilize M = {M0, M1, . . . , Mk} to represent the group of estimating alternatives
that an IaaS environment gives, and we characterize a function charge (Mh, Pj, Ii) to figure the running cost of instance Ii with type Pj utilizing evaluating model Mh. Beside this, we don't accept any more detail of evaluating alternatives, so that the model could be non-exclusive for most IaaS environment. With the meanings of the instance pool, instance type and purchase options, we can now represent an IaaS environment as a services S = (I, P, M).
IV. EVOLUTIONARY MULTIOBJECTIVE OPTIMIZATION
A Multi-objective Optimization Problem is an issue that has a few clashing goals which should be optimized simultaneously: minimize , where x ∈ X and X is the decision space. The workflow process scheduling issue can be viewed as a MOP, the objectives of the scheduling issue (W, S) are given as follows. FT(Ti) is the finish time of errand Ti. Since the targets in a MOP normally differ with each other, Pareto predominance is generally used to compare the solutions. For u, v ∈ X, u is said to dominate v if and only if. An solution x∗ is Pareto optimal if it is not dominated by any other solution. The arrangement of all Pareto optimal solution in the target space is called Pareto front. For the Cloud workflow process scheduling issue, schedule I∗ dominates schedule I if neither the cost nor the makespan of I∗ which is bigger than that of I, and at least one of them is less. In recent years, evolutionary Algorithms (EAs) that reproduce regular evolution procedures are discovered expanding fortunate for addressing MOPs with differed qualities.
the client will choose from it in accordance with his/her inclination.On account to the properties of the Cloud workflow scheduling drawback is it's depleting to adopt the present genetic operations within the EMO areas, similar to binary encoding, real-valued encoding, and furthermore the relating variety of operations supports them. By taking full preference to the issue's properties we tend to present a full set of the exploration operations, and additionally encoding, population format, crossover, and mutation [15].
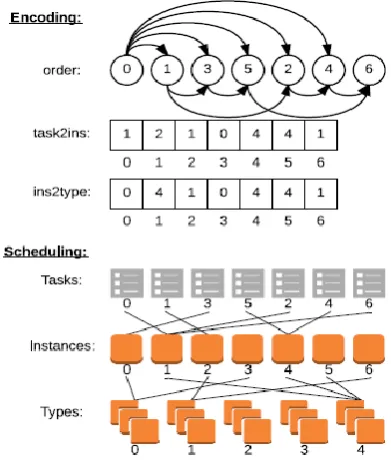
Fig. 1 demonstrates an illustration of DAG, inside which the tasks are ordered,mistreat the consequences of a topological kind. Fig. 2 offers the encoding of a possible schedule for this workflow. In this schedule, the fitness function, discussed in [15], follows the arrangement [T0, T1, T3, T5, T2, T4, T6] to process the finish time of T6, which is utilized as the makespan of the workflow. Fig. 2 likewise gives the mappings from the tasks to the instances and from the instance to their types; for example, assignment T0 will be scheduled to instance I1 whose type is P4.
Fig.1. An workflow DAG’s example
Fig. 2. DAG’s Example for Encoding And Scheduling Scheme Of A Valid Schedule In Fig. 1.
V. RESULTS AND DISCUSSION
create satisfactory solutions that are truly close to the ideal ones. Furthermore, it's cost is nothing, however MOHEFT will see a few arrangements Pareto-dominating obtained schedules, EMS-C may turn out quicker schedules that MOHEFT can't take note.
VI. CONCLUSION
In this proposed work a unique encoding theme that represents all the scheduling orders, errand-instance assignments and instance specification decisions. On supporting this concept, we tend to present a group of most recent genetic operators, the analysis work and furthermore the population design theme for this drawback. we have a tendency to apply our styles to numerous standard EMO systems, and investigate the anticipated algorithm on each with this present reality workflow processes and two arrangements of unpredictably produced workflow processes. The inside and out tests are upheld the specific assessment and resource parameters of Amazon EC2, and results have incontestible that this algorithm is extremely encouraging with surely wide acceptability. As a future work, we will consider utilizing more than one rating plans, example sort groups or maybe multi-Clouds in an exceedingly single schedule.
VII. REFERENCES
[1].J. J. Durillo, V. Nae, and R. Prodan, “Multi-objective energy-efficient workflow scheduling using list-based heuristics,” Future Generation Computer Systems, vol. [36], pp. [221]–[236], [2014].
[2].Y. C. Lee and A. Y. Zomaya, “Stretch out and compact: Workflow scheduling with resource abundance,” in Proceedings of the [2013] International Symposium on Cluster Cloud and the Grid (CCGRID). IEEE, [2013], Conference Proceedings, pp. [367]– [381].
[3].S. Abrishami, M. Naghibzadeh, and D. Epema, “Cost-driven scheduling of grid workflows using partial critical paths,” IEEE Transactions on Parallel and Distributed
Systems, vol. [23], no. [8], pp. [1400]– [1414],[ 2012].
[4].S. Abrishami, M. Naghibzadeh, and D. H. Epema, “Deadline-constrained workflow scheduling algorithms for infrastructure as a service clouds,” Future Generation Computer Systems, vol. [29], no. [1], pp. [158]–[169],[ 2013].
[5].Y. Xu, K. Li, J. Hu, and K. Li, “A genetic algorithm for task scheduling on heterogeneous computing systems using multiple priority queues,” Information Sciences, vol. [270], pp. [255]–[287], [2014]. [6].Z. Zhu, G. Zhang, M. Li, and X. Liu, “Evolutionary multi-objective workflow
scheduling in cloud,”
DOI:10.1109/TPDS.[2015].2446459, [2015]. [7].R. N. Calheiros and R. Buyya, “Meeting deadlines of scientific work- flows in public clouds with tasks replication,” IEEE Transactions on Parallel and Distributed Systems, vol. [25], no. [7], pp.[ 1787]– [1796],[ 2014].
[8]X. Tang, K. Li, G. Liao, K. Fang, and F. Wu, “A stochastic scheduling algorithm for precedence constrained tasks on grid,” Future Generation Computer Systems, vol. 27, no. [8], pp. [1083]–[1091], [2011].
[9].W. Zheng and R. Sakellariou, “Stochastic dag scheduling using a monte carlo approach,” Journal of Parallel and Distributed Computing, vol. [73], no. [12], pp. [1673]– [1689], [2013].
[10].M. Rodriguez Sossa and R. Buyya, “Deadline based resource provisioning and scheduling algorithm for scientific workflows on clouds,” IEEE Transactions on Cloud Computing, vol. [2], no. [2], pp. [222]–[235], [2014].
[11].AmazonWeb Service,
http://aws.amazon.com/autoscaling
[13].X. Liu, Y. Yang, Y. Jiang, and J. Chen, “Preventing temporal violations in scientific workflows: where and how,” IEEE Transactions on Software Engineering, vol. [37], no. [6], pp. [805]–[825], [2011].