Contents lists available at ScienceDirect
Information
Sciences
journal homepage: www.elsevier.com/locate/ins
Link-aware
semi-supervised
hypergraph
Taisong
Jin
a,b,
Liujuan
Cao
a,∗,
Feiran
Jie
b,
Rongrong
Ji
caMedia Analytics and Computing Lab, Department of Computer Science, School of Informatics, Xiamen University, 361005, China bScience and Technology on Electro-optic Control Laboratory, Luoyang, 471023, China
cMedia Analytics and Computing Lab, Department of Artificial Intelligence, School of Informatics, Xiamen University, 361005, China
a
r
t
i
c
l
e
i
n
f
o
Article history: Received9March2019 Revised25July2019 Accepted29July2019 Availableonline22August2019 Keywords: Hypergraph Hyperedge Link Ridgeregression
a
b
s
t
r
a
c
t
Hypergraphlearninghasbeenwidelyappliedtovariouslearningtasks.Toensurelearning accuracy,itisessential toconstructaninformativehypergraphstructurethateffectively modulatesdatacorrelations. However,existing hypergraph constructionmethods essen-tiallyresorttoanunsupervisedlearningparadigm,whichignoressupervisoryinformation, suchaspairwiselinks/non-links.Inthisarticle,toexploitthesupervisoryinformation,we proposeanovellink-awarehypergraphlearningmodel,whichmodulateshigh-order cor-relationsofdatasamplesinasemi-supervisedmanner.Toconstructahypergraph,a coef-ficientsmatrixoftheentiredatasetisfirstcalculatedbysolvingalinearregression prob-lem. Then,pairwise linkconstraintsareexploited and propagated tothe unconstrained samples,uponwhichthecoefficientsmatrixisadjustedaccordingly.Finally,theadjusted coefficientsareused togenerateaset ofthehyperedges, aswellascalculatethe corre-spondingweights.Wehavevalidatedtheproposedlink-awaresemi-supervisedhypergraph modelontheproblemofimageclustering.Superiorperformanceoverthestate-of-the-art methodsdemonstratestheeffectivenessoftheproposedhypergraphmodel.
© 2019ElsevierInc.Allrightsreserved.
1. Introduction
Modelingof high-orderdata correlationsiscrucialin variouslearningtasks such ascontent-basedimage orvideo re-trieval[1,3,8,36,43],analysisofMagneticResonanceImaging[4],humanposerecoverfromanimage[10]andimage anno-tation[7,25].Comparedwithasimplegraph,ahypergraph,whichcapturesmorecomplexrelationsamongmultiplesamples byintroducinghyperedges,isthereforefarmorerobust,yetdiscriminative[2,48].
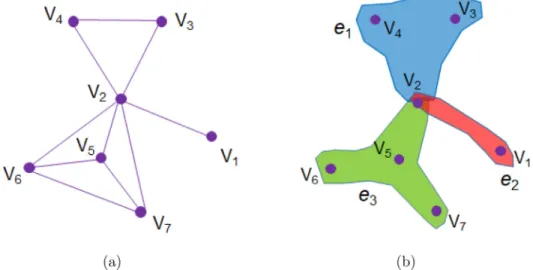
Differentfromasimplegraphthatuseseachedgetomodeltherelationshipbetweentwosamples,ahypergraphadopts ahyperedgetoconnect anynumberofsamples,whichenablesthemodelingofmore generaldata correlationswithhigh flexibility.Forexample,forasetofarticles,aundirectgraphcanbeconstructedbylinkinganytwoarticleswiththecommon author.However, wedon’tknowwhethersomeoneistheauthorofthreeormorearticlesornot.Suchinformationlossis unexpected,which isused formanylearningtasks. However, hypergraph caneffectively preserve thehigherrelationship amongmultiplearticles.Specifically,weobservethatthreearticleshaveancommonauthorbysharingonecommonvertex showninFig.1.
Forlearningdiscriminativehypergraphmodels,itisfundamentaltomodulatethetopologicalstructureamongsamples. Mostexisting hypergraphlearningmethodsuseaneighborhood-based approachtorepresenthigh-orderdatacorrelations.
∗ Correspondingauthor.
E-mail address: [email protected](L.Cao). https://doi.org/10.1016/j.ins.2019.07.095
Fig.1. Simplegraphversushypergraph.(a)Simplegraph.(b)Hypergraph.Givenasetofthearticles V ={v1,v2,v3,v4,v5,v6,v7},simplegraphand
hy-pergraphareusedtomodeltherelationshipamongthesamples,where E ={e 1,e 2,e 3}isasetoftheconstructedhyperedges.Asimplegraphlinkstwo
articlestogetherbyanedgeifthereisatleastoneauthorincommon.Thisgraphcannottelluswhetherthesamepersonistheauthorofthreeormore articlesornot.Ahypergraphcompletelymodelsthehigh-orderrelationshipsamongtheauthorsandarticles.[47].
Inparticular,to generatea hyperedge,each sampleismodeled asacentroidvertex,which islinkedtoits neighborswith a fixed number. However, performance of hypergraph learningis sensitive in two ways: (1) Neighborhood size. Asmall neighborhood size separates thesamples fromthe same cluster; whereas a large neighborhood size groupstogether the samples fromdifferent clusters; (2) Noise. Hypergraphlearning performance is usually sensitive to noise. Tothat effect, varioustypesofnoisessuchasGaussiannoise,sparsenoise,andsample-specificcorruptions,easilycontaminatereal-world data.
Alternatively, the representation-based approach has recently been proposed to modulatethe high-order relationship amongsamples[24,37,46]Suchanapproachgenerateseachhyperedgebysolvingalinearregressionproblem.Forinstance,
1-Hypergraph [37]leverages sparse regressionto generatea noise-resistanthyperedgeset. Thework by [46] further ex-tended the1-Hypergraphto removeredundanthyperedgesby jointlylearningfeatureselectionandhypergraph construc-tion.Elastic-netHypergraph[24]incorporatestheelastic-netregularizationintoalinearregressionframework,which effec-tivelyconnectscorrelatedsamplestogenerateasetofhyperedges.2-Hypergraph[12]leveragesridgeregressiontogenerate asetofthehyperedges.Sincethenoisecomponentsofthedataareseparatedfromtheoriginaldata,suchanapproachhas achievedconsiderableperformancegainswithnoisydata.
Beyondthetopicofhypergraphlearning,recentworkshavewelladvocatedexploitingsupervisoryinformationingraph construction. Forinstance,in[34],exploitation ofavailable labeled dataimproves performance ofgraph learning.In [18], GaussianProcess(GP)isusedtomodellabeldistribution,uponwhichgraphhyper-parameterswerelearnedthrough expec-tationmaximization.Toberobusttonoiseandofferdatum-adaptiveneighborhoods,thelabelswereexplicitlyincorporated intotherepresentation-basedgraph,suchaslow-rankrepresentation[49].Beyondclasslabels,pairwiselinksarealso mod-ulatedasconstraintstoconstructaneighborhood-basedgraph[28].
Notethatthereexisttwotypesofwidelyavailablesupervisoryinformation,whichcanbeusedtohelpenhancelearning performance:class labels andpairwiselink constraints[20].Comparedwithclass labels,pairwise link constraints,which canbeautomaticallyobtainedwithouthumanintervention,aremorecheaplyavailable.Inaddition,pairwiselinkinformation canbederivedfromlabeleddata,butnotviceversa.Thus,modelinggraphlearningwithpairwiselinkconstraintshasbeen recentlywellinvestigatedinmanyimageprocessingapplications[15,19,35,41].
Because of promising performance in applications,supervised graph modeling hasreceived more and moreattention from theresearchers. However, how to exploit supervisory information,especially widely used pairwise link constraints, tomodulatehigh-orderrelationshipsofdataisan unsolvedopenproblem.Specifically, existinghypergraphmodels essen-tiallybelong toanunsupervised learningparadigm. Itiscrucialto developanovel supervisedhypergraphmodeltomore effectivelyleveragethecheaplyavailablelinkconstraintstogeneratealink-awarehyperedgeset.
Wearguethatthepreviousmethodscannotexploitthesupervisedinformationofasmallnumberofsamplestomodel high-order data correlations. Specifically, the pairwise link constraints, which are cheaply available,cannot be effectively exploited. Thus, the previous methods cannot fully explore the noisydata, which only achieve limited performance im-provements on noisydata. To tacklethe above issues, in this paper, we propose a novel hypergraph learningapproach, Link-Aware Semi-Supervised Hypergraph, which effectivelyleverages widely-available pairwise link constraints to learn a robusthypergraphinasemi-supervisedmanner(SeeFig.2).Thecontributionsoftheproposedmodelareasfollows:
Fig.2. Theflowchartofourproposedhypergraph.Forthegivendataset(somesamplesareinitiallyimposedonpairwiselinkconstraints),eachsample isfirstlyrepresentedasthelinearcombinationoftherestofthesamples,resultinginacoefficientsmatrix;Furthermore,theinitiallinkconstraintsare propagatedtotheentiredatasetandthecoefficientsmatrixisadjustedaccordingly;Finally,theadjustedcoefficientsareusedtogeneratealink-aware hyperedgeset.
1.Weproposeahypergraphmodel,whichconstructsaninformativehypergraphinasemi-supervisedmanner.Specifically, cheaply availablepairwiselinkconstraintsinrealapplicationsareleveragedtogenerateasetoflink-awarehyperedges. Tothebestofourknowledge,thisisthefirstattempttoincorporatelinkconstraintsinhypergraphlearningtomodulate thehigh-orderdatacorrelations.
2.Theproposedhypergraphmodelbelongstotherepresentation-basedhypergraphconstructionscope,whereeach hyper-edgeisgeneratedbysolvingalinearregressionproblem.Initiallinkconstraintsarefurtherexploitedandpropagatedto the entiredataset,andtheresultingadjusted coefficientsare insensitivetonoise. Furthermore,the sampleswithlarge coefficientsareusedtogenerateasetofnoiseresistanthyperedges.
3.Based on the proposed hypergraph model, two novel hypergraph construction methods: Elastic-Net Semi-Supervised Hypergraph andNuclear-induced Semi-Supervised Hypergraph, are proposed, which are not only link-aware, but also robusttonoiseanddatacorruptions.Theexperimentalresultsonthenoisydatasetsdemonstratethattheproposedtwo methodsaresuperiortotheexistingmethods.
Therestofthispaperis organizedasfollows: Section 2introduces therelatedwork. Section3 presentsahypergraph learningmodel.Section3.1presentstwonovelhypergraphconstruction methods.Section3.2reportstheexperimental re-sults.Finally,weconcludethepaperanddiscussourfutureworkinSection3.3.
2. Relatedwork
AhypergraphisdefinedasG=
(
V,E,W)
,whichcontainsthevertexsetV,thehyperedgesetE,andthehyperedgeweight matrixW.A|V|×|E| incidencematrixHindicates whetheravertexbelongstoa hyperedge,whichhas thefollowing ele-ments:H(
v
,e)
={
0,1,otherwiseifv
∈e .Thedegree ofeachvertexvisdefinedas:d(
v
)
=e∈Ew(
e)
H(
v
,e)
,andthedegreeofhyperedgeeisdefinedas
δ
(
e)
=v∈VH(
v
,e)
.WeuseDv,De andWtodenotethediagonalmatricesofvertexdegrees,hy-peredgedegrees,andhyperedgeweights,respectively,basedon whichthenormalizedhypergraphLaplacianisformulated asL=I−
,where
=D−12
v HWeD−e1 HTD−
1 2
v .
Formuchdataanalysis,modelingofthedatarelationshipiscrucialtoobtainusefulinformation.Hypergraph,aneffective toolto modeldatarelationship,hasbeenusedtosolve variousproblemsinimage analysis.Formulti-modalfeature inte-gration,ahypergraphisusedtocapturethehigh-ordercorrelationamongmulti-modalfeatures[45].Hypergraphmatching modulatesthecomplexrelationsoffeaturesettorobustlymatchimage features[44].Hypergraph-basedrankingisusedto explorethephotos-relevancetoagivenevent[26],andsolvetheproblemsofimage retrieval[14]andobjecttracking[27]. Hypergraphrankingisusedtosolvetheproblemofmulti-objectivee-commercerecommendations[29].Hypergraph-based image classification [42] generates a setof hyperedges andautomatically learnsthe hyperedgeweights for classification. Hypergraph[40] isusedto multi-view basedimage classification.Context-Aware hypergraph constructionmethod [23] is designedforrobustspectral clustering. Hypergraphhierarchicalreduction [22] isconsidered a macro-vertexina reduced hypergraph corresponding to a hyperedge.Hypergraph-based tracking [5]exploits high-order geometric relations among multiple correspondences of object parts in different frames. Hypergraphs are incorporated into sparse coding [17] and low-rankmatrixfactorization[16],whichshowspromisingresultswithreal-worlddatasets.Recently,thefuzzyhypergraph modelisusedtorepresentgranularstructure[38].
Table1
Listofimportantnotations. Notationanddescription X Thesetofdatasamples ML Themust-linkset CL Thenot-linkset
xi Thefeaturevectorofthe i -thdatasample ei Thedataerrorsvectorofthei -thsample Xi Thepixelsmatrixofthe i -thimagesample Ei Thedataerrorsmatrixofthei -thimagesample C Thenormalizedcoefficientsmatrix
C Theadjustedcoefficientsmatrix Z Theinitiallinkconstraintsmatrix F Theexhaustiveconstraintsmatrix f ij theconfidencescoreof(xi,xj) H Theincidencematrix
L HypergraphLaplacian
N Thenumberofdatasamples
Alltheseapproachesdemonstratethatlearningperformancecanbesubstantiallyenhancedifthehigh-orderrelationship amongthe datasamples iseffectivelymodulated. However,existing hypergraph construction methods ignoresupervisory information.Theaimofthisworkistointegratecheaplyavailablelinksupervisoryinformationintohypergraphconstruction togenerateanoiseresistanthyperedges.
3. Link-awaresemi-supervisedhypergraph
Toconstruct an informative hypergraph,the key issueis to findmultiplecorrelated samples ofeach sampleto depict correcthigh-orderdatacorrelations.Here,wemakeanattempttoleveragethecommonly-usedpairwiselinkconstraintsto generatealink-awarehyperedgeset.
GivenasetofNdatasamplesX=
{
xi}
Ni=1,wherexiisthefeaturevectorofthei-thsample,two typesofpairwise linkconstraintsareusuallyimposedonasmallnumberofsamples,whichspecifywhetherapairofsamplesbelongtothesame class (must-link)ordifferentclasses (cannot-link).Forconvenience, the must-linksetis definedasML=
{
(
xi,xj)
|
i =j}
and the cannot-link set is definedasCL={
(
xi,xj)
|
i = j}
, where i is the class labelof xi. Table 1 lists the importantnotationsinthisarticle.
Toberobust todatanoiseandcorruption,deployedovertherepresentation-basedhypergraphconstructionisthe pro-posedmodel,whichexploits theself-expressivepropertyofdatatorepresenteach sampleasalinearcombinationofthe remaining samplesinthe entiredataset.Coefficientsofa linearregressionnaturallycharacterizehowother samples con-tributetorepresentthetargetsample,whichiscrucialtodiscoverthegroupinganddiscriminativestructures.
Theregressioncoefficientsaredirectlyusedtogeneratehyperedges[24].However,thecoefficientsmatrixdoesnot con-sidertheeffectsoflinkconstraints,whichprohibitsimprovingtheperformance.Thus,itisimportanttoleveragethecheaply availablelinkinformationtoadjusttheregressioncoefficients,whichareusedtogeneratealink-awarehyperedgeset. 3.1. Derivationofcoefficientsmatrixusinglinearregression
Basedonthe“dataself-expression” property,wereconstructdatabyitself,formulatedas min
C ,E Metric
(
E)
+μ
1Regularization(
C)
+μ
2Regularization(
E)
+μ
3Grouping−Regularization(
C)
s.t.E=X−XC, theother constraints, (1)
where C=[c1c2· · ·cN]∈RN×N isthe coefficients matrixof the data,andci isthe coefficientsvector of the i-th sample; E=[e1e2· · ·eN]∈RM×N isthedataerrorsmatrixandei∈RM isthedataerrorsvectorofthei-thsample;Metric(·) isthe
metrictomeasure thedataerrors;Regularization
(
·)
istheregularizationtermtoderive thedesiredstructuresofthedata andGroup-Regularization(
C)
isthegroupregularization,aimingtomakethecoefficientsreflectthegroupingstructuresof thedata.Constraint(C) aretheconstraintsimposedonthecoefficientsordataerrorstointroducepriorknowledge.μ
1>0,μ
2>0andμ
3>0aretheregularizationparameterstotradeoff theregularizationandrepresentationerrors.The coefficientsmatrix characterizes howdata samplescontribute to datareconstruction, where dateerrors are mea-suredbythemetricandthedesireddatastructures arereflectedbytheregularizationtermsandtheimposedconstraints. Thus, the coefficients matrixis used to generate a set ofhyperedges. In fact, the recentlyproposed 1-Hypergraph [37],
2-Hypergraph[12]andElastic-netHypergraph[24]areconsideredasthespecialcasesoftherepresentation-based hyper-graphs.
Worthemphasizingisthatthegroupregularization,whichhasthegroupselectioneffects,isusedinthelinearregression framework.Thisproperty,itissuitabletochooseagroupofcorrelatedsamplestogetherforhyperedgegeneration,iscrucial forhypergraphconstruction.
3.2.Exploitingpairwiselinkconstraints
Formanyrealworldproblems,thereexistsavailabledata,wheresomedatasamplesareimposedonpairlinkconstraints. Itis naturaltouselink informationasthe constraintsandincorporatethem intothehypergraph learningframework. To leveragetherepresentation-basedhypergraphlearningframework,theimportantissueistomaketherepresentation coeffi-cientsreflectthelinkinformation.
Astraightforwardapproachforusinglinkinformationistodirectlyincorporatelinkconstraintsintoalinearregression framework.Forexample,we forcethe coefficientofthenot-link samplestobe zero,i.e.,thenot-link samplesare not in-volvedin representingtheresponse sample.Bythisway,the regressioncoefficientsmatrixreflects theeffectsofthe link constraints.However,becauselink constraintsareimposed initiallyonlya smallnumberofsamplesintheentiredataset, theeffectsofthelinkinformationonthelinked samplesarelimited.Itisbettertopropagatetheinitiallinkconstraintsto theunconstrainedsamples,andcorrespondinglysignificantlyadjustthecoefficientsmatrix.
Toexploitthelinkinformationimposedonasmallnumberofsamples,weadopttheconstraintpropagationstrategy[28], whichdeterminestheconstraintrelationshipoftwounconstrainedsamplesbyclassifyingtherelationshiptoclasslabeled as+1orclasslabeledas-1.
Notethatthei-thcolumnofthenormalizedcoefficientsmatrixactuallyprovidestheinitialconfigurationofatwo-class semi-supervisedlearningproblemwithrespecttoxi,whereclass1containsthesamplesclosetoxiandclass-1containsthe samplesfarawayfromxi.Theothercolumnsofcoefficientsmatrixarehandledsimilarlytodecomposeconstraint
propaga-tioninverticaldirectionintoNindependentlabelpropagationsub-problems.Likewise,wecanperformhorizontalconstraint propagationbyconsideringcoefficientsmatrixrowbyrow.Thus,byverticalconstraintpropagationandthehorizontal con-straintpropagation, constraintpropagationis performedefficientlyusingthe labelpropagationtechnique[47],where the iterativeapproachisusedtosolvetheoptimizationproblem(SeeSteps3and4inAlgorithm1).
Algorithm1:Linkconstraintspropagation.
Input:TheinitialconstraintsmatrixZandthecoefficientsmatrixC.
Output:TheexhaustiveconstraintsmatrixF∗andtheadjustedcoefficientsmatrixC.
1 NormalizeCbyC∗
i j= |C i j|
max
i |C i j|
andsetC=(C ∗+(2C ∗)T) toensurethatthenormalizedcoefficientsmatrixCissymmetric.
2 ComputethematrixL=D−1/2CD−1/2,whereDisadiagonalmatrixwithitsi-thdiagonalelementbeingjCi j. 3 IterateFv
(
t+1)
=α
LFv(
t)
+(
1−α
)
Zfortheverticalconstraintpropagationuntilconvergence,whereα
isaparameterintherange(0,1).
4 IterateFh
(
t+1)
=α
Fh(
t)
L+(
1−α
)
F∗v forthehorizontalconstraintpropagationuntilconvergence,whereF∗visthelimitof
{
Fv(
t)
}
.5 F∗=F∗h istheexhaustiveconstraintmatrixbeingpropagated,whereF∗h isthelimitof
{
Fh(
t)
}
.6 DerivetheadjustedcoefficientmatrixC=
{
Ci j}
N×N byusingtheexhaustiveconstraintmatrix,F∗,definedasCi j=
1
−
1
−
f
∗ i j1
−
C
i j(
1
+
f
i j∗)
C
i jif
f
i j∗≥
0
otherwise
First,theinitialconstraintsmatrixZ=
{
Zi j}
N×N isdefinedasZi j=
1 if(
x i,xj)
∈ML −1 if(
xi,xj)
∈CL 0 otherwise . (2)Furthermore,thepropagatedexhaustiveconstraintsmatrixF=
{
fi j}
N×Nisdefined,where|fij|≤1indicatestheconfidencescoreof(xi,xj)beingamust-link(orcannot-link)constraint. Inother words,fij>0indicatesthattwosamplesxiandxjis imposedonamust-linkconstraint;fij<0indicatesthattwosamplesxiandxjisimposedonanot-linkconstraint.
Algorithm1presentsthepropagationprocedureofthelinkconstraints,whichproducesanadjustedcoefficientsmatrix
Cthathasthefollowingproperties:
1.Cisnonnegativeandsymmetric,Ci j∈[0,1].
2.Ci j≥Ci j (or<Ci j)if fi j∗≥0(or <0).
ThispropertymeanstheadjustedcoefficientsmatrixCisactuallyderivedfromthecoefficientsmatrixCi j by
increas-ingCi jforthemust-linkconstraintswith fi j∗≥0anddecreasingCi j forthecannot-linkconstraintswith fi j∗<0.
3.
∂
Ci j/∂
Ci j=1−fi j∗.Thispropertyshowsthatbothmust-linkandcannot-linkconstraintsplaytheimportantroles(withthesame deriva-tives)inadjustingcoefficientsiftheyhavethesamepairwiseconstraintvalues.
ThispropertyensuresCi j issettobelargewhen fi j∗takesalargepositivevalue,evenifCi j isinitiallyverysmall.On
theotherhand,Ci j issettobesmallwhen fi j∗ takesalargenegativevalue,evenifCi j isinitiallyverylarge.
Itisworthemphasizingthattheusedlinkpropagationschemeisdifferentfromtheconstraintpropagation[28]method. Theworkin[28] propagateslinkconstraintsbyusingtheneighborhood-basedgraph,wheretheedgeweightsareadjusted usingthe exhaustivelink constraints.Incontrast,our learningmodeldirectlyadjusts theregression coefficientmatrix by thepropagatedexhaustiveconstraints.
3.3. Hyperedgegeneration
Thecoefficientsmatrixobtainedbysolvingtheaforementionedlinerregressionproblemeffectivelyreflectsthegrouping anddiscriminantstructures ofthe data.After thelinkconstraintsimposed onasmallnumberofsamplesarepropagated, thecoefficientsmatrixischangedaccordingly.Thus,theobtainedcoefficientsarelink-aware.Basedonthepropertiesofthe adjustedregressioncoefficients,thesampleswiththesameclasshavemuchlargervalues,whilethesamplesfromdifferent classeshavemuchsmallervalues.
Sincethesampleswithlargenon-zerocoefficientsintheadjustedcoefficientsmatrixaremostcloselyrelatedtoxi,we
combinesuchsamplestogether togeneratealink-awarehyperedge.Furthermore,an incidencematrixH∈RN×N isdefined,
whoseincidencevectorindicates therelationshipbetweenthehyperedgeandits vertices.Theincidencevectorassociated withthecentroidvertexxiisformulatedas
H
(
v
i,ej)
=1, ifCi j>
θ
0, otherwise, (3)
where
θ
isathreshold.Ci j isthej-thadjustedregressioncoefficientofxi.Wetakeeachdatasampleascentroidvertexandlinkagroupofdatasampleslyingonorclosetothesamelinearsubspaceascentroidvertextogenerateahyperedgeand thecorrespondingnoiseanddatacorruptionaredetectedandremoved.Thus,thehigh-orderrelationshipbetweencentroid vertexanditsmostcorrelatedverticeschosenfromtheremainingdatasamplesaremodulated.
Wethenturntodecidethehyperedgeweights,whicharecrucialforthehypergraph-basedapplications.Sincethe real-world datasetisusually contaminatedby noise,itisnotsuitable todirectlymeasurethe similaritybetweentwo samples. Instead,wetaketheregressioncoefficientsvector[24]tomeasurethesimilaritybetweentwosamplesasfollows:
A
(
i,j)
=⎧
⎨
⎩
(C i) T C j C i C j , if(
i=j)
0, otherwise (4)Afterahypergraphisconstructedfromtheincidencematrix,H,thehyperedgeweightw(ei)iscalculatedby[10]
w
(
ei)
= vj∈eiH
(
v
i,ej)
A(
i,j)
, (5)4. Theproposedhypergraphconstruction
Inthissection, wepresenttwohypergraph construction methods,whichserveastheimplementationofthe proposed hypergraph model.Exceptforthecomputationofthecoefficientsmatrix,thetwo hypergraphconstruction methodsshare thesamemechanism.
4.1. Elastic-netsemi-supervisedhypergraph
Real-world data may contain sample-specificcorruptions. For instance,the faces in images maybe occludedby sun-glassesorascarf[31].Toberobusttosuchsample-specificcorruptions,therecentElastic-netHypergraphmodel[24] gen-erateseachhyperedgebysolvingthefollowinglinearregressionproblem:
min
C ,E
λ
1C1+λ
2CF+E21s.t.X=XC+E,diag
(
C)
=0, (6)whereEdenotestheerrormatrixandthe21-normbasedmatrixisusedtomeasure thedataerrors; Cisthecoefficients matrix;
λ
1>0andλ
2>0aretheregularizationparameters.ThediagonalelementsofCaresetaszeros,ensuringthateach imageisrepresentedbytheremainingimages,excludingitself.Eq.(6)adoptsanElastic-netregularizedlinearrepresentationtocomputetherepresentationcoefficientsofeachsample, whichfavorstheselectionofmultiplecorrelatedsamplestogethertorepresenttheresponsesample.Weremovethesample xifromthesamplematrixtodecomposethexiastheelastic-netregularizedbasedlinearregression,formulatedas
min C
i
wherethedictionaryDi=[x1,x1,· · ·,xn−1]isdesignedforremovingtheconstraintCii=0.
Tocompute the entireelastic-netregularization path ofEq.(7),the LARS-ENalgorithm [50] can be usedto solve the optimizationproblem,wheretheElastic-netlinearregressionproblemistransformedintoanequivalentproblemofalasso regressionontheaugmenteddatasetforemployingtheLARSalgorithm[6].
AfterobtainingthecoefficientsmatrixC∈RN×N,thecoefficientsofElastic-netregularizedlinearregressionareadjusted
bypropagatingtheinitiallinkconstraintstotheunconstrainedsamples(SeeAlgorithm1).Finally,theadjustedcoefficients areusedtogeneratelink-awarehyperedges.Forclarification,werefertothehypergraphsconstructedinourwayasEN-sHG intherestofthearticle.
4.2.Nuclear-inducedsemi-Supervisedhypergraph
In various image analysis andclassification tasks,often used to measure the representation errors is the pixel-based errorsmodelwhichassumesthat thepixel-wisederrorsare independentandidenticallydistributed(i.i.d).However,such i.i.dassumptiondoesnotholdinregions withocclusions orlargeilluminationchanges, whichinsteadhaveapproximated low-rankstructures[33,39].
Insuchacase,thelinearmatrixregression,whichdoesn’trequireconvertingeachimagetoalongvector,ismoresuitable torepresenteachimage. Toachieve thateffect,thepixelsmatrixXiofthei-thimage (i=1,· · ·,N) isdirectlyrepresented
as
Xi =ci1 X1+· · · +cii −1 Xi −1 +cii +1 Xi +1 +· · · +ciN XN+Ei , (8) whereci=[ci1ci2,cii−1,cii+1· · ·ciN]T∈RN−1isthecoefficientsvectorandEiistherepresentationerror,correspondingtoan
errorimage.
DefiningA
(
ci)
=ci1X1+· · · +cii−1Xi−1+cii+1Xi+1+· · · +ciNXN,Eq.(8)isre-writtenasXi=A
(
ci)
+Ei. (9)Furthermore,by adoptingnuclear-norm basedmetrictomeasure thedataerrorsandaddingthe2-normbasedgroup selectionregularization,thelinearmatrixregressionisrewrittenas
min c i,E i
Ei
∗+λ
3ci22 s.t. xi=A(
ci)
+Ei,(10) where the second term is the 2-norm regularization fordiscovering the grouping structures of the data,
λ
3>0 is the parametertotradeoff theregularizationandrepresentationerrors.Tomeasuretheerrorimage,Eq.(10)adoptsanuclear-normbasedmetrictodiscovertheunderlyinglow-rankstructures of the data [6,39]. The objective function in Eq. (10) is non-convex, which is solved by using the Alternating Direction MethodofMultipliers(ADMM)approach[9,39].
By incorporating the penalty termof the constraintinto the objective function of Eq. (10), the augmented Lagrange functionis
L
(
Z,ci,Ei)
=Ei2∗+λ2ci22+tr(
ZT(
Xi−Ai(
c)
−Ei)
+ρ2Xi−Ai(
c)
−Ei2
F (11)
where
ρ
istheaugmentedLagrangeparameter.Z∈RN×NarethematrixoftheLagrangemultipliersfortheconstraints.tr(·)denotesthe traceof thematrix.ADMMeffectivelysolves an optimizationproblemintwo separate steps:primal variable updatinganddualascending;i.e.,ADMMiterativelyupdatestheprimal variables(ci,Ei),andtheLagrangemultipliers(Z)to obtainthelocaloptimalsolution.
Foreach sample, the coefficientsvector isderived by solving Eq. (10).After all the sampleshave beenselected once, acoefficientsmatrixC=[c1,c2,· · ·,cN]T∈R(N−1)×N canbe derived. Then,the coefficientsmatrixC∈RN×N isobtainedby
addingzerostothediagonalelements.Furthermore,theregressioncoefficientsofnuclearinduced linearmatrixregression areadjustedbypropagatingtheinitiallinkconstraintstotheunconstrainedsamples(SeeAlgorithm1).Finally,theadjusted coefficientsareusedtogenerateasetoflink-awarehyperedges.
Forclarification,werefertothehypergraphsconstructedinourwayasNuclear-sHGintherestofthearticle.
Algorithm2 overviewstheproposed semi-supervisedhypergraph constructionto capturethe high-orderdata correla-tions.
4.3.Computationalcomplexity
The computational cost of our proposed hypergraph model consistsof three components: representation coefficients computation,coefficientspropagationandhyperedgegeneration.Notethattwoproposedsemi-supervisedhypergraph con-structionmethodsarethesameexceptforthederivationofcoefficientsmatrix.WeassumethatthereexistNsamplesinthe dataset.Forcoefficientspropagation(SeeAlgorithm1),thecomputationcostisO(pN2),wherepisthenumberofnon-zero coefficientsofcentroidvertex.ThecomputationalcostofhyperedgegenerationisO(N2).
Algorithm2:Link-awaresemi-supervisedhypergraph.
Input:AfeaturesetofthedatasamplesXandasetoflinkconstraints Output:Alink-awareSemi-SupervisedHypergraph
1 ComputethecoefficientsmatrixaccordingtoEq.(6)or(10).
2 AdjustcoefficientsmatrixbyemployingAlgorithm1.
3 fori=1,· · ·,N do
(a)Linkcentroidvertex,xitotheverticeswithnon−zerocoefficientstogenerateahyperedge,ei,accordingto
Eq.(3);
(b)Definetheweightofthehyperedge,ei.accordingtoEq.(5); end
FortheEN-sHGmethod,thecomputationcostofcoefficientsderivationofusingtheLeastangleregressionapproach[6]is O(N3).
Forthe Nuclear-sHG method,the computationcost of thecoefficients derivationusing ADMMapproach [9]is mainly determined by the nuclear-norm based minimization operator, where singular value decomposition of image matrix is involved. Forconvenience, we assume the image matrix is p×q sizes, the computation cost of coefficientsderivation is O(N×min(pq2,qp2).
5. Experimentalresultsanddiscussions
Inthissection,weevaluatetheproposedtwohypergraphconstructionmethodsinthetaskofimageclustering. 5.1. Experimentalsettingandcomparedmethods
Clusteringviahypergraph istypicallyperformedfromaspectralperspective.First,theK-largesteigenvectorsof hyper-graphLaplacianarecomputed. Then,theK-meansclusteringisemployedontherowsoftheeigenvectormatrixtoobtain thefinalclusteringresult,wheretheclusternumberKissetasthenumberofdataclasses.Inourexperiments,weadopted two commonlyused metrics tomeasure the performance, i.e., theaccuracy (AC)andthe normalizedmutualinformation (NMI) [16]. Accuracy is the percentage of correctclustering labels, while normalized mutual information measures how similardifferentclustersetsare.
Wecomparedtheperformanceoftheproposedmethods(EN-SHGandNuclear-SHG)withthefollowingbaselines: KNN−HG [13]. KNN-HG is a hypergraph construction method, where each hyperedge is generated by using the neighborhood-basedapproachandaGaussiankernelisusedtocomputetheedgeweight.
2−HG[12].2-HGadoptsridgeregressiontoconstructahypergraph,wherethe2-normbasedmetricisusedto mea-suretherepresentationerrors.
EN−HG[24].EN-HGisahypergraphconstructionmethod,whereeachhyperedgeisgeneratedbysolvingtheproblem ofelastic-netregularizedlinearregression.The21-normbasedmetricisusedtomeasuretherepresentationerrors.
KNN−sGr[28].KNN-cGris asemi-supervised graphconstruction method,wherethepairwise constraintsare propa-gatedontheneighborhood-basedgraph,andtheedgeweightsofaGaussiankernelisadjustedaccordingly.
Nuclear−Gr[39].Nuclear-Grisagraphconstructionmethod,wherethenuclear-normbasedmetricisusedtomeasure therepresentationerrorsandthe2-normisusedastheregularization.
Tofurtherknowhowlinkconstraintscanhelpenhancethehypergraphlearningperformance.Basedonthelinear regres-sionbasedlearningframework,we developnovelmultipleconstraintsbasedgraphconstructionmethods.Fromtheabove, fourgraphorhypergraphconstructionmethodsaredevelopedasfollows:
Nuclear−cHG. Nuclear-cHGisa semi-supervisedhypergraph construction method,wherethe linkconstraints are di-rectlyimposedonthenuclear-inducedhypergraphlearningframework.
Nuclear−sGr. Nuclear-sGr is a semi-supervised graphconstruction method, which isthe same asNuclear-Gr except thatthecoefficientsobtainedbylinkpropagationaredirectlyusedtoconstructagraphinsteadofahypergraph.
EN−cHG.EN-cHGis a semi-supervised hypergraph construction method,where the linkconstraints are directly im-posedontheelastic-net-basedhypergraphlearningframework.
EN−sGr.EN-sGrisasemi-supervisedgraphconstructionmethod,whichisthesameastheproposedEN-sHGmethod exceptthatthecoefficientsobtainedbylinkpropagationaredirectlyusedtoconstructagraphinsteadofahypergraph.
Among thesemethods, Nuclear-cHG, EN-cHGdirectlyimpose the linkconstraints onthe coefficientsforreflecting the linkeffects.Inpractice,wedefinetheconstraintci j=Qi j,whereQijreflects thenot-linkandmust-linkconstraintshaving thefollowingformulation:
Qi j=
α
if(
xi ,xj)
∈MLandcij <θ
Table2
Thecomparedmethods.
Method Graphtype Linkconstraint Metric
KNN-sGr[28] Graph Constraint Null
KNN-HG[13] Hypergraph Null Null
2-HG[12] Hypergraph Null 2-norm
Nuclear-Gr[39] Graph Null Nuclear-norm
Nuclear-sGr Graph ConstraintPropagation Nuclear-norm
Nuclear-cHG Hypergraph Constraint Nuclear-norm
Nuclear-sHG Hypergraph ConstraintPropagation Nuclear-norm
EN-HG[24] Hypergraph Constraint 21-norm
EN-cHG Hypergraph Constraint 21-norm
EN-sGr Graph ConstraintPropagation 21-norm
EN-sHG Hypergraph ConstraintPropagation 21-norm
Fig.3. TheimageexamplesfromExtendedYaleBdataset.(a)Session1.(b)Session2.
where
θ
isthethresholdparameterofchoosingthe vertexofhyperedge,ensuring themust-linksampletobechosen for hyperedgegeneration,whileatthesametime,ensuringthenot-linksampleisn’tchosenforhyperedgegeneration.Forour experiments,α
issetequalto1.2|cij|.FortheKNN-sGr, Nuclear-sGr,EN-sGrandtheproposed methods(EN-sHGandNuclear-sHG),theyadopttheconstraint propagationapproachtogeneratethelink-awareedgesorhyperedges.Thus,fortheconstraintsinvolvedmethods,regardless ofexploitingthelinkconstraintsortheconstraintspropagation,theyconstructagraphorhypergraphinasemi-supervised manner.Forconvenience,welistthecomparedmethodsinTable2.
Fortheparametersinthesemethods,weconductedcross-validationexperimentstosettheoptimalparametervaluesfor dataclustering.Forthehypergraph-basedmethods,the
θ
issetequalto0.8|cij|.FortheNuclearinducedmethods(Nuclear-Gr,Nuclear-HG,Nuclear-cHG,Nuclear-sGrandourproposedNuclear-sHG),we usethepixels matrixofan image astheimage feature.Forall othermethods, we convertthe pixelsmatrix ofanimage intoalongvector,whichisusedastheimagefeature.
Forsemi-supervisedgraphorhypergraphconstructionmethods,werandomlylabel1%ofthelinkpairsfromtheentire datasettosimulateboth must-linkandcannot-link constraints,whichareimposed ona smallnumberofimage samples. Since thelink information doesn’t necessarilycontain the class labelof the samples,the classification taskis unsuitable forconstraintsinvolvedmethods.Weconductedtheclusteringexperimentsonthereal-worlddatasetstodemonstrateour proposedtwomethods.
5.2.Faceclusteringwithdifferentilluminations
Tohandlethedatawithilluminationchanges,weconductedthefaceclusteringexperimentsontheExtendedYaleBface dataset[21].Thedatabasecontains5760singlelightsourceimagesof10subjectseachseenunder576viewingconditions (9poses × 64 illuminationconditions).Forevery subjectina particularpose,an image withambient(background) illu-minationwasalsocaptured.Hence,thetotalnumberofimagesis5760+90=5850.Forthisdatabase,wesimplyusethe croppedimagesandresizethemto32×32pixels.Thisdatasethas38individualsandaround64nearfrontalimagesunder differentilluminationsperindividual.
Weadoptedtwo separatedsessions: Session1 (containingtheimagesfromSubset 1,2and3 withslightillumination changes)andSession2(containing theimagesfromSubset 1,4,5 withextremeillumination conditions).Fig.3 showsthe imageexamplesonExtendedYaleB.Table3liststhefaceclusteringresults.
As showninTable 3, whenthe lighting changeis large (Session 2), theclustering performance ofall the methods is degraded;Comparedwiththeneighborhood-basedmethods(KNN-sGrandKNN-HG),therepresentation-basedmethodsare relativelyrobusttolightingchanges.
Table3
ClusteringresultsontheYaleBdataset.
Different AC(%) NMI(%)
illuminations Session1 Session2 Session1 Session2
KNN-sGr[28] 29.9 20.2 43.0 35.3 KNN-HG[[13] 27.6 21.6 40.1 33.1 2-HG[12] 39.6 34.5 48.8 44.3 Nuclear-Gr[39] 48.6 47.2 60.1 58.3 Nuclear-sGr 50.7 49.1 62.4 61.5 Nuclear-cHG 49.7 48.1 60.4 60.5 Nuclear-sHG 53.3 49.8 66.7 62.1 EN-HG[24] 44.3 41.2 57.6 53.1 EN-cHG 44.9 42.3 58.4 54.5 EN-sGr 45.8 44.1 65.6 57.4 EN-sHG 47.3 43.2 58.1 59.6
Fig.4. TheimageexamplesfromCoil20Dataset.(a)Theimagesoccludedbythecups.(b)Theimagesoccludedbythebooks.(c)Theimagesoccludedby theflowers.(d)Theimagesoccludedbythedollars.
The constraint involved methods consistently outperform corresponding unconstraint involved methods.(Nuclear-sGr, Nuclear-cHG and the proposed Nuclear-sHG > Nuclear-Gr; EN-cHG, En-sGr andthe proposed EN-sHG > EN-HG, KNN-sGris > KNN-HG).Theexperimentalresultsdemonstratethatlinkconstraintseffectivelyenhancethehypergraph learning performance. For both two sessions,our proposed Nuclear-sHG consistently andsignificantly outperforms other compared methodsandourproposedEN-sHGisalsosuperiortoEN-HGbyalargemargin.
Theseexperimentalresultsdemonstratethatourproposedtwomethodseffectivelyleveragethelinkinformationto gen-erate a link-aware hyperedge set. Specifically, the linear matrix regression-based hypergraph construction (Nuclear-sHG) capturestheunderlyinglow-rankstructuresoftheimage,whichisrobusttothecaseofextremelightingconditions. 5.3. Objectclusteringwithcontiguousocclusions
To handle the data with the contiguous occlusions, we conducted the image clustering experiments on the Coil20 dataset[32].Tosimulatethecontiguousocclusions,wereplaced30% ofrandomlychosenpixels fromeach selectedimage withdifferentkindsofocclusions: cup,book,flower andmonkey.Fig. 4showstheimage examplesoccludedbydifferent objects.Table4liststheexperimentalresultsonCoil20dataset.
As shown in Table 4, the link constraints involved methods outperform the corresponding unconstrained methods (Nuclear-sGr,Nuclear-cHGandtheproposedNuclear-sHG > Nuclear-Gr;EN-cHG,En-sGrandtheproposed EN-sHG > EN-HG).Specifically, the constraintpropagation-based methods outperform the methods usingthe link constraints(the pro-posedNuclear-sHG > Nuclear-cHG;theproposedEN-sHG > En-cHG).TheproposedNuclear-sHGmethodachievesthebest clusteringresultsunderallcircumstancesofdifferentoccludedobjects.TheproposedEN-sHGsignificantlyoutperformsthe unsupervisedEN-HG.Theseexperimentalresultsdemonstratesthattheproposedmethodscanleveragethelinkinformation tobemorerobusttothecontiguousocclusions.
5.4. Faceclusteringwithreal-worldocclusions
Tohandlethe datawith real-worldocclusions, we conductedfaceclusteringexperiments onthe AR dataset[30].The AR dataset contains over 4000 face images of126 people, which vary in expression, illumination anddisguise (wearing sunglassesorscarves).Eachsubjecthas26images:fourteenclean,sixwithsunglasses,andsixwithscarves.First,weused asubsetcontaining1400cleanfacesrandomlyselectedfromfiftymaleandfiftyfemalesubjects.Limitedbycomputational capabilities(aswasthecasein[17]),were-sizedalltheimagesfromtheoriginal165×120to60×43andconvertedthem tograyscale,weselected,fromtheARdataset,selected700faceswearingsunglasses(occludedratioisabout20%)and700 faceswearingscarves(occludedratioisabout40%).
Table4
ClusteringresultsontheCoil20dataset. Contiguousocclusion AC(%)
byoccludedobject Cup Book Flower Monkey
KNN-sGr[28] 36.0 32.9 37.0 33.9 KNN-HG[13] 39.5 33.2 39.1 34.3 2-HG[12] 49.2 45.7 48.5 47.3 Nuclear-Gr[39] 60.8 55.4 59.7 57.2 Nuclear-sGr 62.3 57.9 61.6 59.8 Nuclear-cHG 61.7 56.4 60.4 58.5 Nuclear-sHG 67.8 61.3 66.9 68.2 EN-HG[24] 57.8 54.3 59.6 60.3 EN-cHG 58.3 55.1 60.4 60.9 EN-sGr 60.4 56.9 62.1 61.3 EN-sHG 61.4 57.6 63.1 62.8
Contiguousocclusion NMI(%)
byOccludedobject Cup Book Flower Monkey
KNN-sGr[28] 43.5 39.4 44.5 46.4 KNN-HG[13] 45.1 37.0 46.5 40.8 2-HG[12] 57.8 54.3 55.4 56.2 Nuclear-Gr[39] 69.7 68.3 72.1 76.2 Nuclear-sGr 71.4 70.6 73.1 75.8 Nuclear-cHG 70.3.7 69.1 72.7 77.1 Nuclear-sHG 75.1 72.3 76.9 79.2 EN-HG[24] 68.8 66.6 70.3 73.3 EN-cHG 69.2 67.1 70.4 73.9 EN-sGr 70.7 68.3 73.4 74.5 EN-sHG 70.3 67.2 72.1 75.6
Fig.5. TheimageexamplesfromtheARDataset.(a)Theimagesoccludedbytheglasses.(b)Theimagesoccludedbyascarf.
Forcomputation efficiency, a subset containing2600 faces wasused, which were randomly selected from fifty male andfiftyfemale subjects.Each subjectcontains26 images,i.e.,fourteen clean,sixwith sunglasses,andsix withscarves. AstheAR datasetcontainstwo typesofocclusions(the occlusionby theglassesandscarf),we conductedtwoclustering experiments corresponding to the sunglasses andscarf occlusions. Forthe sunglasses occlusion,we select14 clean face imagesand6faceimageswithsunglassesfromeachsubject.Forthescarfocclusion,weselected14cleanfaceimagesand 6face imageswithscarf fromeachsubject. Fig. 5showstheimage examples occludedby theglassesora scarf. Table5 presentstheexperimentalresultsontheARdatasets.
AsshowninTable5,theconstraintpropagation-basedmethodsoutperformthemethodsusingthelinkconstraints(the proposed Nuclear-sHG > Nuclear-cHG; the proposed EN-sHG > EN-cHG). The proposed nuclear-sHG achieves the best clusteringresultsandtheproposed EN-sHGissuperior tothe unsupervisedEN-HG.Specifically, whentheocclusion level islarge (the occlusionis caused by a scarf), the proposed two methods achieve much better clusteringresults than the corresponding unsupervisedmethods (the proposed Nuclear-sHG significantly outperformsNuclear-HG; theproposed EN-sHGoutperformsEN-HGbyalargemargin).Theexperimentalresultsdemonstratethattheexploitationoflinkinformation makestheproposedmethodsrobusttoreal-worldocclusions.
5.5.Faceclusteringwithuncontrolledsetting
Tohandlethedatawithuncontrolledsetting,weusetheLFWfacedataset[11]toconduct faceclusteringexperiments. LFWis a large-scale unconstrained face dataset underthe uncontrolled setting. Images in LFWwere collectedfrom the
Table5
ClusteringresultsontheARdataset.
Realocclusion AC(%) NMI(%)
byoccludedobject Glasses Scarf Glasses Scarf
KNN-sGr[28] 37.1 35.5 51.8 53.3 KNN-HG[13] 33.7 33.4 59.2 59.4 2-HG[12] 47.2 46.8 62.3 61.7 Nuclear-Gr[39] 55.4 52.5 67.6 64.3 Nuclear-sGr 57.3 54.7 69.2 65.4 Nuclear-cHG 55.9 53.1 68.2 65.0 Nuclear-sHG 59.3 57.7 70.2 66.5 EN-HG[24] 49.8 47.1 63.2 62.4 EN-cHG 50.2 47.8 63.9 63.0 EN-sGr 52.8 49.4 64.9 64.4 EN-sHG 53.6 50.3 65.6 65.3 Table6
ClusteringresultsontheLFWdataset.
Clustering AC(%) NMI(%)
number 12 22 32 42 52 12 22 32 42 52 KNN-sGr[28] 20.4 11.4 12.2 12.5 10.6 21.9 14.5 16.8 17.8 15.4 KNN-HG[13] 21.6 15.6 14.6 13.3 13.2 23.6 19.2 18.5 18.4 17.8 2-HG[12] 27.3 20.2 18.6 18.2 17.4 25.4 20.1 19.8 20.1 18.1 Nuclear-Gr[39] 30.4 25.5 20.0 18.5 16.4 34.7 31.3 24.7 21.6 19.6 Nuclear-sGr 32.1 27.6 22.5 21.3 19.6 37.2 33.9 28.3 24.9 21.9 Nuclear-cHG 30.8. 26.1 20.5 19.0 16.9 35.3 31.8 25.2 22.1 20.3 Nuclear-sHG 33.4 30.8 25.4 24.6 21.3 35.6 30.2 28.6 25.6 23.2 EN-HG[24] 28.7 18.3 19.6 17.2 17.7 24.7 20.7 20.6 19.6 16.9 EN-cHG 29.5 19.1 20.4 17.9 17.8 25.3 21.3 21.0 20.2 17.2 EN-sGr 30.2 20.1 21.5 19.2 18.9 26.7 22.5 21.9 21.6 19.2 EN-sHG 30.1 24.9 22.1 19.0 18.9 30.3 28.4 26.8 20.3 21.6
YahooNews,whichcontains13,233 faceimagesof5749subjectsinuncontrolledenvironments.Theseimagescontainlarge variationsinpose,illumination,expression,occlusion,andresolution.
Forcomputational convenience, we onlyselected a subset of 2213 images,which only contains52 subjectsand each subject hasmore than 20 imagesand simply crop the face image to remove the background,the images are resized to 64×64pixels.Forcomputationconvenience,weonlyselectasubset of2213 images,whichcontains52subjects,eachof whichhasmorethan20images.Wecropthefaceimagetoremovethebackgroundandresizetheimagetobe64×64 pix-els.Fig.6showstheimageexamplesofLFWdataset.Table6presentstheclusteringresults.
AsshowninTable6,theuncontrolledsettingmakesfaceclusteringbecomeachallengingtask.Allthemethodsperform lesspromising,whereastheproposedNuclear-sHGmethodstillobtainsthebestclusteringresults,andtheproposedEN-sHG issuperiortoEN-HG,EN-cGrandEN-CHG.Theseexperimentalresultsdemonstratethattheproposedmethodscangenerate link-awarehyperedges,whicharerelativelyrobusttohandlesuchauncontrolledsetting.
5.6. Thequalitativeexperimentsonrobustness
To illustrate the superiority of our proposed link-aware hypergraph model, specifically to handle the noisy data, we selected20imagesfromeachindividualoftheExtendedYaleBdatasetandtheentire200imagesareselectedtoconduct
Fig.7. Theplotoftheregressioncoefficientsoftheresponseimageviadifferentmethods,wheretheresponseimageisrepresentedasthelinear com-binationoftherestoftheimagesandtheredlinesarethecoefficientsofmust-linkedsamplesandthegreenlinesarethecoefficientsofnot-linked samples.(a)EN-HG[24].(c)EN-cHG.(e)OurproposedEN-sHG.(b)Nuclear-Gr[39].(d)Nuclear-cHG.(f)OurproposedNuclear-sHG.(Forinterpretationof thereferencestocolourinthisfigurelegend,thereaderisreferredtothewebversionofthisarticle.)
Fig.8. Theresponseimageandtheimagesimposedonthelinkconstraints.Fortheselected199imagesusingthedictionary,the18-thand19-thimages arethemust-linkedsamplesandthe98-thand99-thimagesarethenot-linkedsamples.
theexperiments. Inthis case, an image isused asthe response image, whilethe remaining 199 imagesare used asthe dictionarytorepresentthisresponseimage, wherethemust-linkconstraintsare imposedonthe18-thand19-thsamples andnotlinkconstraintsareimposedonthe98-thand99-thsamples(SeeFig.7forthegreaterdetails).Quantitatively,only the19largestcoefficientsareretained.Fig.7showstheabsolutevaluesoftheregressioncoefficientsofresponseimage.
As shown inFig. 7, for the constraint involved methods (EN-cHG, Ourproposed EN-sHG, Nuclear-cHG, our proposed Nuclear-sHG),themust-linked samplesare usedtorepresenttheresponse imageandnot-linkedsamplesarenot involved inrepresentingtheresponseimage.Comparedwiththemethodsusingthelinkconstraints(EN-cHGandNuclear-cHG),our proposedtwo methods (EN-sHGandNuclear-sHG) adoptthe constraintspropagationstrategy, whichcan moreeffectively choosethesampleshavingthesameclass torepresenttheresponseimage. Forthemethodswithoutusingthelink infor-mation(EN-HGandNuclear-Gr),moresamplesoftheotherclassareinvolvedinrepresentingtheresponseimage.Notethat theregressioncoefficientsofseveralnonemask-linkedsamplesornot-linkimage arebig.Thepossiblereasonisthatthese samplesarecontaminated by noiseorthe dataiscorrupted. Thus,thesecorrupted ornoisysamplesmaybecloseto the responseimage,whosecoefficientsarebig(Fig.8).
Fig.9. Theclusteringresultswithvariedpercentagesoflinkedsamples.(a)TheACresultsvsthepercentageoflinksamples.(b)TheNMIresultsvsthe percentageofthelinkedsamples.
Fig.10. ParametertunningexperimentalresultsofEN-sHG.(a)TheACresultsvsthedifferentvaluesofλ1andλ2.(b)TheNMIresultsvsthedifferent
valuesofλ1andλ2.
Theexperimentalresultsdemonstratethatthelinkconstraintscanenhancetherepresentationability,whichisrobustto noise anddatacorruption. Fortheexploitation oflinkinformation,directlyadoptingthelinkconstraintshavethelimited learningeffects,whereas,ourproposed twomethodsadoptthepropagated constraintsscheme,whichachievesthebetter learningperformance.
5.7. Onthelinkeffectsandparametertuning
Toevaluatehowlinkinformationofthedataaffectstheclusteringresults,wefurtherconductedtheclustering experi-mentsusingtheARdataset(containing2600images)withvaryingpercentagesoflinkedsamples.Fig.9showsthe experi-mentalresults.
As showninFig. 9,asthepercentages ofthelinked samplesincreases,performance ofthesemethodsfirstly increases accordinglyandthen becomesfairly stable. Forthedifferentpercentages oflinked samples,our proposedNuclear-sHG is superiortoNuclear-cHGandNuclear-HG;ourproposedEN-sHGissuperiortoEN-cHGandEN-HG.Theexperimentalresults demonstratethatourmethodsleveragethelinkinformationtoenhanceperformance.
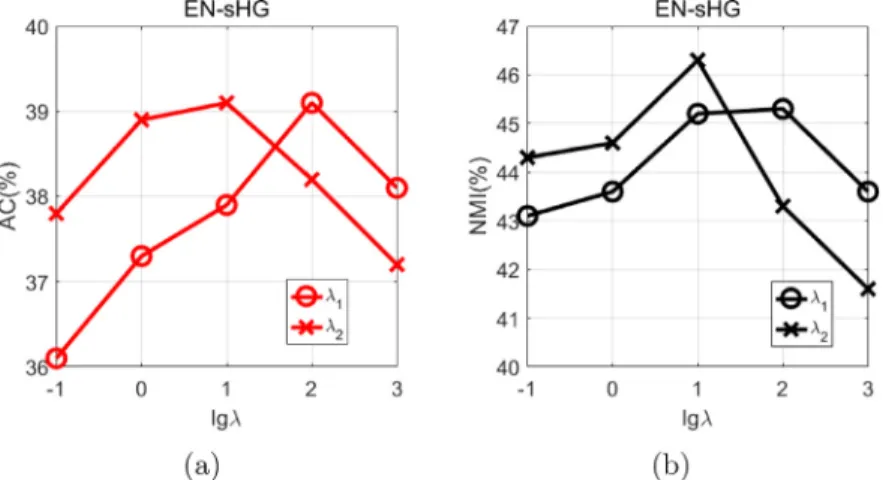
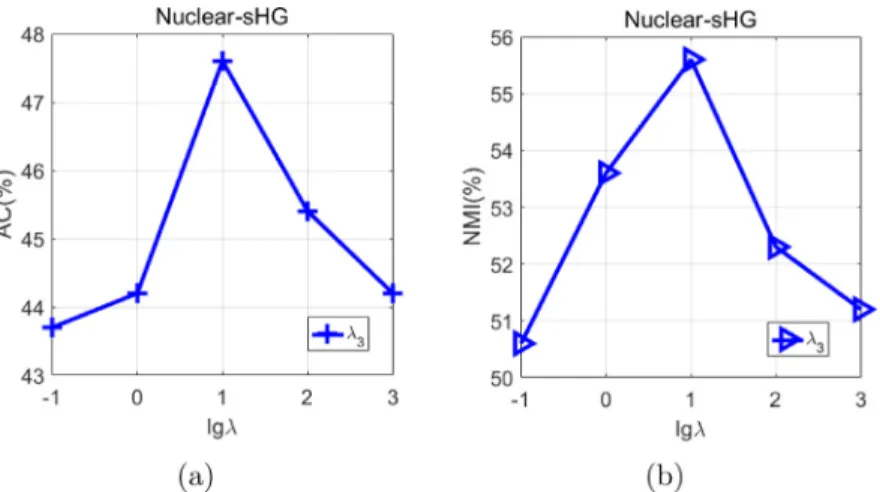
Furthermore,we present theparameter tuning results tocheck howdifferent parameter settingsaffect the clustering results.(1)ForourproposedEN-sHGmethod,ithastwokeyparameters
λ
1andλ
2,whereλ
1isthe1-normregularization parameter, andλ
2 is theFrobinous-norm regularizationparameter. (2)Forourproposed Nuclear-sHG,we tuneparameterλ
3,which isthe 2-normregularization parameter. Figs.10 and11shows theclusteringresults withdifferentparameter settingsontheARdataset,where1%samplesareimposedonthelinkconstraints.Fig.11. TheparametertuningexperimentalresultsofNuclear-sHG.(a)TheACresultsvsthedifferentvaluesofλ3.(b)TheNMIresultsvsthedifferent
valuesofλ3.
AsshowninFigs. 10and11,ourproposed EN-sHGmethodachievesgoodclusteringperformance withdifferentvalues ofparameter
λ
1. When the parameter value is larger than 100, clusteringperformance begins to degenerate.The above experimentalresultsdemonstratethatthe1-normregularizationiscrucialtodiscoverthediscriminativestructuresofthe data.Asthevaluesofparameters
λ
2 andλ
3 increase, ourproposedEN-sHGandNuclear-sHGmethods obtainsgood cluster-ingperformance.When theparametervaluesarelarge(λ
2>10andλ
3>10),thecorresponding performancesbegintobe degradedalittle.Theexperimentalresultsdemonstratethatthe2-normregularizationiscrucialtodiscoverthegrouping structuresofthedataforgeneratingtheinformativehyperedges.5.8.Furtherdiscussions
Ourproposedlink-aware hypergraphmodel andits twovariants outperformthe comparedmethods onthenoisydata withdifferentilluminations,contiguousocclusions,real-worldocclusionsandtheuncontrolledsetting.Weconsider superi-orityofperformanceisattributedtothefollowingtworeasons:
Ontheonehand,thesuperiorityofourmodelliesinthatourproposedtwomethodsbelongtotherepresentation-based hypergraphmodel,whichgeneratesasetofhyperedgesbysolvingalinearregressionproblem.Sincethesampleswiththe largeregressioncoefficientsaremorelikelytoreflecttheaffinityrelationsofthedata,thegeneratedhyperedgesarerobust tonoisebylinkingeachvertextothesampleswiththelargecoefficients.
Onthe other hand,our model further enhancesthe robustness to noise by exploiting thelink information, which is cheaplyavailable. Itis worthemphasizing thatourmodeldoesn’t directlyexploitthe linkinformation,whichhaslimited effects on the linked samples. Instead,our model propagatesthe link information of a small numberof samples to the entiredataset,wherethelearnedregressioncoefficientsareaffectedbyboththedatareconstructionandthelinkconstraints imposedonasmallnumberofsamples.Thus,thelink-awareandnoiseresistanthyperedgesaregenerated,whichresultsin thebetterperformanceonnoisydatasets.
6. Conclusion
Inthisarticle,weproposedanovelhypergraphmodel,whichbelongstotherepresentation-basedhypergraph construc-tionscope.Comparedwiththeexistingmethods,ourproposedhypergraphmodelhasthefollowingadvantages:our meth-odsconstructahypergraphinasemi-supervisedmanner,wherethelinkinformationofthedataareleveragedtogenerate alink-awarehyperedgeset.Specifically,theadjustedcoefficientsmatrixobtainedbylinkconstraintpropagationisusedfor hyperedgegeneration.Currently,thereal-worlddataisusuallycontaminatedbydifferenttypesofnoiseandoutliers,which are one key issue forimage processing. Thus, it iscrucial to develop the novel hypergraph models to be robust against variousdatanoise.Inthefuture,weplantoextendourmethodtohandlemorecomplexnoise.
DeclarationofCompetingInterest
TheauthorswhosenamesarelistedimmediatelybelowcertifythattheyhaveNOaffiliationswithorinvolvementinany organizationorentitywithanyfinancialinterest(suchashonoraria;educationalgrants;participationinspeakers’bureaus; membership,employment,consultancies,stockownership,orotherequityinterest;andexperttestimonyorpatent-licensing arrangements),ornon-financialinterest(suchaspersonalorprofessionalrelationships,affi liations,knowledgeorbeliefs)in thesubjectmatterormaterialsdiscussedinthismanuscript.
Acknowledgments
Thiswork wassupported by theNational KeyResearch andDevelopmentProgramof China (no.2017YFC0113000,no. 2016YFB1001503, no. 2018YFC0830105), by the Natural Science Foundation of China (no. U1705262, no. 61802324, no. 61732005,no.61772443,no.61672361,no. 61702136,no.61572410) andby theBeijingMunicipal EducationCommission -BeijingNaturalFundJointFundingProject(KZ201910028039).
References
[1] L.Cao,X.Liu,W.Liu,R.Ji,T.S.Huang,Localizingwebvideosusingsocialimages,Inf.Sci.302(2015)122–131.
[2] G.Chen,J. Zhang,F.Wang,C.Zhang, Y.Gao, Efficientmulti-labelclassificationwith hypergraphregularization,in: ComputerVisionandPattern Recognition,2009.CVPR2009.IEEEConferenceon,IEEE,2009,pp.1658–1665.
[3] R.Datta,D.Joshi,J.Li,J.Z.Wang,Imageretrieval:ideas,influences,andtrendsofthenewage,ACMComput.Surv.(Csur)40(2)(2008)1–66. [4] W.Ding,C.Lin,M.Prasad,Hierarchicalco-evolutionaryclusteringtree-basedroughfeaturegameequilibriumselectionanditsapplicationinneonatal
cerebralcortexMRI,ExpertSyst.Appl.101(2018)243–257,doi:10.1016/j.eswa.2018.01.053.
[5] D.Du,H.Qi,L.Wen,Q.Tian,Q.Huang,S.Lyu,Geometrichypergraphlearningforvisualtracking,IEEETrans.Cybern.47(12)(2017)4182–4195. [6] B.Efron,T.Hastie,I.Johnstone,R.Tibshirani,etal.,Leastangleregression,Ann.Stat.32(2)(2004)407–499.
[7] L.Gao,J.Song,F.Nie,Y.Yan,N.Sebe,H.T.Shen,Optimalgraphlearningwithpartialtagsandmultiplefeaturesforimageandvideoannotation,IEEE Trans.Cybern.44(7)(2014)1225–1236.
[8] Y.Gao,M.Wang,R.Ji, Z.Zha,J.Shen,K-partitegraphreinforcementanditsapplicationinmultimediainformationretrieval,Inf.Sci.194(2012) 224–239.
[9] T.Goldstein,B.O’Donoghue,S.Setzer,R.Baraniuk,Fastalternatingdirectionoptimizationmethods,SIAMJ.ImagingSci.7(3)(2014)1588–1623. [10] C.Hong,J.Yu,J.Wan,D.Tao,M.Wang,Multimodaldeepautoencoderforhumanposerecovery,IEEETrans.ImageProcess.24(12)(2015)5659–5670. [11] G.B.Huang,M.Ramesh,T.Berg,E.Learned-Miller,Labeledfacesinthewild:adatabaseforstudyingfacerecognitioninunconstrainedenvironments,
TechnicalReport,TechnicalReport07–49,UniversityofMassachusetts,Amherst,2007.
[12] S.Huang,D.Yang,B.Liu,X.Zhang,Regression-basedhypergraphlearningforimageclusteringandclassification,arXiv:Comput.Vis.PatternRecognit. (2016).
[13] Y.Huang,Q.Liu,F.Lv,Y.Gong,D.N.Metaxas,Unsupervisedimagecategorizationbyhypergraphpartition,IEEETrans.PatternAnal.Mach.Intell.33 (6)(2011)1266–1273.
[14] Y.Huang,Q.Liu,S.Zhang,D.N.Metaxas,Imageretrievalviaprobabilistichypergraphranking,in:ComputerVisionandPatternRecognition,2010IEEE Conferenceon,IEEE,2010,pp.3376–3383.
[15] M.Jian,C.Jung,Interactiveimagesegmentationusingadaptiveconstraintpropagation,IEEETrans.ImageProcess.25(3)(2016)1301–1311. [16] T.Jin,J.Yu,J.You,K.Zeng,C.Li,Z.Yu,Low-rankmatrixfactorizationwithmultiplehypergraphregularizer,PatternRecognit.48(3)(2015)1011–1022. [17] T.Jin,Z.Yu,L.Li,C.Li,Multiplegraphregularizedsparsecodingandmultiplehypergraphregularizedsparsecodingforimagerepresentation,
Neuro-computing154(2015)245–256.
[18] A.Kapoor,H.Ahn,Y.Qi,R.W.Picard,Hyperparameterand kernellearningfor graphbasedsemi-supervisedclassification,in:Advances inNeural InformationProcessingSystems,2006,pp.627–634.
[19] D.Klein,S.D.Kamvar,C.D.Manning,Frominstance-levelconstraintstospace-levelconstraints:makingthemostofpriorknowledgeindataclustering, TechnicalReport,Stanford,2002.
[20] B.Kulis,S.Basu,I.Dhillon,R.Mooney,Semi-supervisedgraphclustering:akernelapproach,Mach.Learn.74(1)(2009)1–22.
[21]K.-C.Lee,J.Ho,D.J.Kriegman,Acquiringlinearsubspacesforfacerecognitionundervariablelighting,IEEETrans.PatternAnal.Mach.Intell.27(5) (2005)684–698.
[22] H.Lee-Kwang,C.H.Cho,Hierarchicalreductionandpartitionofhypergraph,IEEETrans.Syst.ManCybern.PartB26(2)(1996)340–344. [23] X.Li,W.Hu,C.Shen,A.R.Dick,Z.M.Zhang,Context-awarehypergraphconstructionforrobustspectralclustering.
[24] Q.Liu,Y.Sun,C.Wang,T.Liu,D.Tao,Elasticnethypergraphlearningforimageclusteringandsemi-supervisedclassification,IEEETrans.ImageProcess. 26(1)(2017)452–463.
[25] W.Liu,D.Tao,Multiviewhessianregularizationforimageannotation,IEEETrans.ImageProcess.22(7)(2013)2676–2687.
[26] X.Liu,M.Wang,B.-C.Yin,B.Huet,X.Li,Event-basedmediaenrichmentusinganadaptiveprobabilistichypergraphmodel,IEEETrans.Cybern.45(11) (2015)2461–2471.
[27]R.Lu,W.Xu,Y.Zheng,X.Huang,Visualtrackingviaprobabilistichypergraphranking,IEEETrans.CircuitsSyst.VideoTechnol.27(4)(2017)866–879. [28] Z.Lu,Y.Peng,Exhaustiveandefficientconstraintpropagation:agraph-basedlearningapproachanditsapplications,Int.J.Comput.Vis.103(3)(2013)
306–325.
[29] M.Mao,J.Lu,J.Han,G.Zhang,MultiobjectiveE-commercerecommendationsbasedonhypergraphranking,Inf.Sci.471(2019)269–287. [30] A.Martínez,R.Benavente,Thearfacedatabase,1998,ComputerVisionCenter,TechnicalReport3(2007)5.
[31] A.M.Martinez,Thearfacedatabase,CVCTechnicalReport24(1998). [32] S.A.Nene,S.K.Nayar,H.Murase,etal.,Columbiaobjectimagelibrary(1996).
[33] J.Qian,L.Luo,J.Yang,F.Zhang,Z.Lin,Robustnuclearnormregularizedregressionforfacerecognitionwithocclusion,PatternRecognit.48(10)(2015) 3145–3159.
[34] M.H.Rohban,H.R.Rabiee,Supervisedneighborhoodgraphconstructionforsemi-supervisedclassification,PatternRecognit.45(4)(2012)1363–1372. [35] D.Wang,X.Gao,X.Wang,Semi-supervisednonnegativematrixfactorizationviaconstraintpropagation,IEEETrans.Cybern.46(1)(2016)233–244. [36] M.Wang,H.Li,D.Tao,K.Lu,X.Wu,Multimodalgraph-basedrerankingforwebimagesearch,IEEETrans.ImageProcess.21(11)(2012)4649–4661. [37]M.Wang,X.Liu,X.Wu,Visualclassificationby 1-hypergraphmodeling,IEEETrans.Knowl.DataEng.27(9)(2015)2564–2574.
[38] Q.Wang,Z.Gong,Anapplicationoffuzzyhypergraphsandhypergraphsingranularcomputing,Inf.Sci.429(2018)296–314.
[39] J.Yang,L.Luo,J.Qian,Y.Tai,F.Zhang,Y.Xu,Nuclearnormbasedmatrixregressionwithapplicationstofacerecognitionwithocclusionand illumi-nationchanges,IEEETrans.PatternAnal.Mach.Intell.39(1)(2017)156–171.
[40] J.Yu,Y.Rui,Y.Y.Tang,D.Tao,High-orderdistance-basedmultiviewstochasticlearninginimageclassification,IEEETrans.Cybern.44(12)(2014) 2431–2442.
[41] J.Yu,D.Tao,J.Li,J.Cheng,Semanticpreservingdistancemetriclearningandapplications,Inf.Sci.281(2014)674–686.
[42] J.Yu,D.Tao,M.Wang,Adaptivehypergraphlearninganditsapplicationinimageclassification,IEEETrans.ImageProcess.21(7)(2012)3262–3272. [43] J.Yu,X.Yang,F.Gao,D.Tao,Deepmultimodaldistancemetriclearningusingclickconstraintsforimageranking,IEEETrans.Cybern.47(12)(2017)
4014–4024.
[44] R.Zass,A.Shashua, Probabilisticgraphandhypergraphmatching,in:ComputerVisionandPatternRecognition,2008.CVPR2008.IEEEConferenceon, IEEE,2008,pp.1–8.
[45] L.Zhang,Y.Gao,C.Hong,Y.Feng,J.Zhu,D.Cai,Featurecorrelationhypergraph:exploitinghigh-orderpotentialsformultimodalrecognition,IEEE TransCybern44(8)(2014)1408–1419.
[47]D.Zhou,O.Bousquet,T.N.Lal,J.Weston,B.Schölkopf,Learningwithlocalandglobalconsistency,in:AdvancesinNeuralInformationProcessing Systems16[NeuralInformationProcessingSystems,NIPS2003,December8–13,2003,Vancouverand Whistler,BritishColumbia,Canada],2003, pp.321–328.
[48]D.Zhou,J.Huang,B.Schölkopf,Learningwithhypergraphs:clustering,classification,andembedding,in:Advancesinneuralinformationprocessing systems,2007,pp.1601–1608.
[49]L.Zhuang,Z.Zhou,S.Gao,J.Yin,Z.Lin,Y.Ma,Labelinformationguidedgraphconstructionforsemi-supervisedlearning,IEEETrans.ImageProcess. 26(9)(2017)4182–4192.