International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)532
Multi-criteria sequence-dependent single machine
scheduling using genetic and simulated annealing
algorithms
M. Rahimian
1, R. Soltani
2, A. Tahmasbi-birgani
3, A. Mahmoodi-Rad
1, S. Molla-Alizadeh-Zavardehi
2 1Department of Mathematics, Islamic Azad University, Masjed Soleyman Branch, Masjed Soleyman, Iran2Department of Mathematics, Shoushtar Branch, Islamic Azad University, Shoushtar, Iran
3Department of Industrial Engineering, Islamic Azad University, Masjed Soleyman Branch, Masjed Soleyman, Iran
Abstract— In this paper, we consider the single machine scheduling problem with jobs due on different days, multiple criteria and sequence-dependent setup times. The problem is even more complex because businesses often judge solution goodness according to multiple competing criteria. Producing an optimal solution would be time consuming to the point of rendering the result meaningless. To tackle such an NP-hard problem, we propose a genetic algorithm (GA) and a simulated annealing algorithm (SA) based on the string representation. Besides, some crossover and mutation operators are used in this work. Due to the significant role of crossover and mutation operators on the algorithm’s quality, the operators and parameters required to be accurately calibrated to ensure the best performance. Furthermore, we apply the experimental design method to set the proper values of GA and SA parameters in order to improve their performances. Finally, we investigate the impact of increasing the problem size on the performance of our proposed algorithms.
Keywords—Multi-criteria single machine scheduling, Genetic Algorithm, simulated annealing algorithm, Sequence-dependent setup times.
I. INTRODUCTION
The single machine scheduling problem (SMSP) has been extensively investigated during the last decades [1]. Most of the contributions consider a single optimization criterion, although in practice the Decision Maker often faces several (usually conflicting) criteria. The scheduling of machines is crucial to the enterprise because it is responsible for makespan and earliness and tardiness in customers order delivery. Job scheduling on this machine is a way of approaching the problem that treats the whole production system. The single machine model provides a basis for more complicated environments such as those seen in many real cases [1].
Production of good schedules often relies on management of these setup times, and decision makers must therefore organize the job scheduling on this single machine by trying to minimize downtime while respecting the different deadlines [1]. Sequence-dependent setup times in single machine scheduling are very common. This type of problem is mathematically complex to solve optimally. Additional complexity arises because management routinely wants to consider multiple criteria when evaluating schedule goodness. In many manufacturing environments, the sequence of jobs run on a particular machine affects the setup times. The setup times for each order are different due to different previous job order. There is little work in the literature handling single machine scheduling problems with different criteria. Agnetis et al. [2] studied a multi-criteria scheduling model. They considered three classes of objective functions that are minimizing the maximum of a regular function, minimizing weighted completion time, and minimizing the number of tardy jobs. They constructed different combinations of these criteria in order to optimize it, minimized the objective function. Baker and Smith [3] introduced a multiple-criterion model for a single machine and regarded the objectives of minimizing total weighted completion time, minimizing maximum lateness and minimizing maximum completion time. They offered two polynomial time dynamic programming models for the problem of minimizing a positive combination of total completion time or maximum lateness criterion.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)533 therefore NP-hard. In addition, this problem is even more difficult when total tardiness is the performance measure and there has been relatively little research reported on it [4]. Furthermore, in the presence of sequence dependent setup times, most of the research has focused on either minimizing the sum of setup times or minimizing the sum of job completion times [4].
Different approaches have been proposed by a number of researchers to solve the single machine scheduling problem with setup times. Rubin and Ragatz [5] proposed a Branch and Bound approach, which quickly showed its limitations. Bigras et al. [6] have optimally solved all instances proposed by Rubin and Ragatz [5] using a Branch and Bound approach with linear programming relaxation bounds. They also demonstrated and used the problem's similarity with the time-dependent TSP. Because this problem is NP-hard, many researchers used a wide variety of metaheuristics to solve this problem, such as a genetic algorithm [7] and [8], a memetic algorithm [5], [7] and [9], a simulated annealing [10], a GRASP [11], an ant colonies optimization [12] and [13] and a Tabu/VNS [14]. Heuristics such as Random Start Pairwise Interchange (RSPI) [10] and Apparent Tardiness Cost with Setups (ATCS) [15] have also been proposed for solving this problem. For their part, Sioud et al. [16] introduce a hybrid approach using constraint programming and a genetic algorithm. This paper considers the single machine scheduling problem with sequence-dependent setup times, with the objective to minimize makespan, total tardiness and total earliness of the jobs.
To the best of our knowledge so far no solution procedure has been proposed to this problem. The complexity of the problem necessitates meta-heuristic methods for solving large scale problems. Our contribution is the first attempt in applying two meta-heuristics named genetic algorithm (GA) and simulated annealing (SA) to optimize this problem. In this paper we compare the performance of these metaheuristics to show the effect of the population-based and local search methods on optimization of the problem under consideration. To achieve the better robustness of each algorithm and analyze the parameters of the problem simultaneously, Taguchi experimental design is employed to choose the best level for each parameter with the least number of experiments.
The rest of this paper is organized as follows: In Section 2 we define the problem. In Sections 3 and 4 we present the solution procedure which includes an overview on the used genetic algorithm and simulated annealing. In Section 5 computational testing and discussion are presented.
In the final section of the paper conclusions are provided and some areas of further research are then presented.
II. PROBLEM DESCRIPTION
The problem may be defined as a set of n jobs available for processing at time zero on a continuously available machine. Each job j has a processing time pj, a due date dj,
and a setup time sij which is incurred when
job j immediately follows job i. It is assumed that all the processing times, due dates and setup times are
non-negative integers. A sequence of the
jobs Q=[q0,q1,…,qn−1,qn] is considered where qj and q0 are the subscripts of the jth job in the sequence and a dummy job representing the initial setup times, respectively. The due date and the processing time of the jth job in sequence
are denoted as and , respectively. Thus, the
completion time of the jth job in sequence will be
expressed as ∑ while the
earliness and tardiness of the jth job in sequence will be
expressed as and
respectivly. Also the makespan or the completion time of the last job can be expressed as
. We will use multiple weighted criteria in our
objective functions to reflect the tradeoffs that production planners deal with when scheduling. The objective of the scheduling problem studied is to minimize the makespan, total earliness tardiness of all the jobs which will be
expressed as ∑ ( ) .
III. THE PROPOSED GENETIC ALGORITHM
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)534 Representation and Initialization:
Most of the evolutionary algorithms use a random procedure to generate an initial set of solutions. The chromosome is coded as a permutation of the considered jobs is performed from randomly generated n digits. A GA must be initialized with a starting population. According to the most of the evolutionary algorithms, we use a random procedure to generate an initial set of solutions. We use randomized sequences to seed the initial solution. These sequences are then turned into schedules by computing the required processing times and setup times.
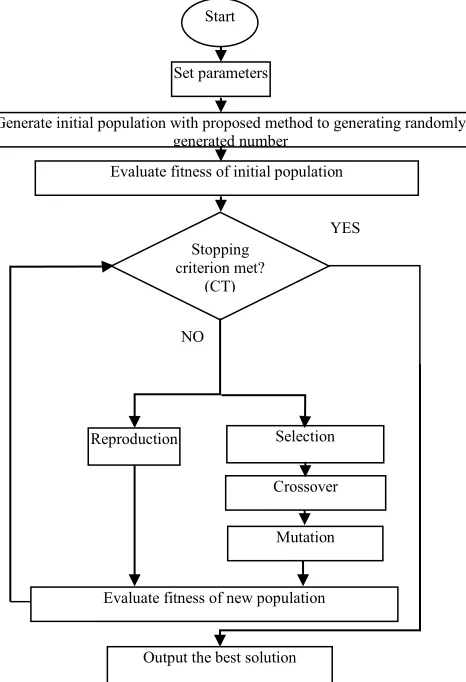
Fig. 1The proposed GA flowchart. CT: CPU Time
Selection mechanism:
Analogous to natural selection, the more fit the parent is the more likely they are to have offspring. A simple way of carrying out this selection is via roulette wheel selection. The wheel has different width spaces so that the worst solution has the minimum wedge increasing up to the best solution with the maximum wedge.
Since the objective function is the minimization of the total cost, better chromosomes are those results in a lower objective function. The higher fitness value means the better solution, so we define the following function to evaluate each fitness value:
Function Objective
1 Value
Fitness
Using the roulette-wheel selection mechanism, the higher fitness value a solution has, the more chance it has to be selected.
Reproduction:
The best solution or Chromosomes with higher fitness values are more desirable than the other and should be considered in next generations. At a minimum, the best solution from the current population needs to be copied to the next generation thus ensuring the best score of the next generation is at least as good as the previous generation. Here elite is expressed as a percent, so the top pr% of the chromosomes is kept with the better fitness values. Hence they are copied to the next generation.
Crossover:
Crossover is the breeding of two parents to produce offsprings. The main purpose of this operator is to generate ‘better’ offspring, i.e. to create better sequences after combining the parents. The generated offsprings have features from both parents and thus may be better or worse than either parent according to the objective function. As we assigned pr% of the chromosomes of generation to reproduction, the (1–pr)% remaining chromosomes are generated through crossover operator. In this paper, we employ the One-point, Two-point and Uniform crossovers.
Mutation:
Mutation is expressed as a probability. For each solution in the parent population a random number is generated from uniform distribution between 0 and 1 giving this solution a percent chance of being mutated. If this solution is chosen for mutation then a copy of the solution is made and job sequences mutated. In this paper, we employ the Swap, Big Swap, Inversion and Displacement Mutations.
IV. THE PROPOSED SIMULATED ANNEALING ALGORITHM
The use of conventional tools for solving the mathematical programming models problem is limited due to the complexity of the problem and the large number of variables and constraints, particularly for realistically sized problems.
Start
Set parameters
Generate initial population with proposed method to generating randomly generated number
Evaluate fitness of initial population
Output the best solution
Reproduction Selection
Crossover
Mutation
Evaluate fitness of new population NO
Stopping criterion met?
(CT)
[image:3.612.42.275.275.616.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)535 Regarded as the time complexity function and also a class of combinational optimization problems known as
nondeterministic polynomial-time hard (NP-hard),
evolutionary algorithms are applied to solve the problem. SA is a popular local search algorithm (meta-heuristic) for solving combinatorial optimization problems [18]. SA searches the set of all possible solutions, reducing the chance of getting stuck in local optima by allowing moves to inferior solutions under the control of a randomized scheme. The name of the approach points to a direct analogy with the way that liquids freeze and crystallize or that metals cool and anneal.
The SA algorithm starts with an initial solution and iteratively moves towards other existing solutions. The algorithm generates a neighboring solution
s
in the neighborhood of the candidate solution s. Then, the change of objective function value, s s, f s( ) f s( ), is calculated. In case s,s value is smaller than zero, to move to the neighboring solution is acceptable; otherwise, if s,svalue is greater than zero, to reduce the probability to get trapped in local optima, the SA may accept to move to an inferior neighboring solution depending on a randomized scheme. More precisely, the move is still accepted if
exp( s,s / )
R T , where T is a control parameter, called
temperature, and
R
is a uniform random number betweeninterval (0,1). SA algorithm generally starts from a high temperature and then the temperature is gradually lowered. At each temperature, a search is carried out for a certain number of iterations. When the termination condition is satisfied, the algorithm will stop. The general SA algorithm is shown in Fig. 2.
Initialization: Select an initial solution (s0), an initial temperature (T0), Number of neighborhood search in each temperature nmax, and termination and Set T ← T0 and s ← s0;
Repeat Repeat
Randomly select sN(s); Calculate s,s f(s)f(s)
if s,s 0 then ss;
else generate random R uniformly in the range (0, 1); if exp( / )
,s n
s T
R then ss;
Until iteration_countre = nt Decrease of the temperature T; until the stopping criterion is met
Fig.2. Steps of the general simulated annealing algorithm
Encoding scheme and initialization:
Similar to GA, a random procedure is utilized for generating an initial solution. Also, the solution is coded as a permutation of the considered jobs is performed from randomly generated n digits.
Neighborhood structure:
The main purpose of applying a neighborhood operator is to rearrange the structure of a solution and to slightly change the allocations, i.e. generating a new but similar allocation. The neighborhood structure must work in a way that prevents any infeasible solution. The four mutation operators used in the GA are selected for each solution.
Cooling Schedule:
The basic aim of utilizing cooling schedule is to control the behavior of SAs. In general, the cooling schedule is specified by several parameters and methods, namely the initial temperature (T0), Number of neighborhood search in each temperature (nmax), the law of decrease of the temperature and the termination condition of algorithm. As the procedure of SA proceeds, the temperature is gradually lowered under the law of decrease of temperature. In general, there are three laws for lowering the temperature in the literature of SA: linear, exponential and hyperbolic. In this study, we use an exponential function to reduce the temperature; the function is as follows:
i i T
T1
where, i represents a stage in the algorithm and Ti represents the temperature of stage i of algorithm.
V. EXPERIMENTAL DESIGN
Data generation:
The performance of the algorithms is compared on 360 problems instances. The sizes of these instances are n =10, 20, 30, 40, 50, 75, 100, 150 and 200. The problems were generated randomly. For each job j, the processing time
and the tardiness penalty were uniformly generated in [1, 100] and [20, 100], respectively. The earliness penalty generated k times of the tardiness penalty of the same job, k being a random real number in the interval [0.1, 0.9].
The due date dj was uniformly generated in , where
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)536 Parameter Tuning:
Three hundred twenty test problems, with different sizes and specifications, are generated and solved to evaluate the performance of the presented algorithms. To
yield more reliable information and Due to having
stochastic nature of the algorithms, we tackle each test problem three times. In order to conduct the experiment,
we implement the proposed algorithm in C++ language, and run on a PC with dual core Duo 2 2.8 GHz and 4 GB of
RAM memory. Because the scale of objective functions in
each instance is different, they could not be used directly. To solve this problem, the relative percentage deviation (RPD) is used for each instance. The RPD is obtained by the following formula:
RPD = Algsol − Minsol Minsol × 100
where Algsol and Minsol are the obtained objective value and minimum objective value found from both proposed algorithms for each instance, respectively. After obtaining the results of the test problems in different trial, results of each trial are transformed into RPD measure.
The RPD measures of trials are averaged and the
parameters and operators that have minimum RPD average are set as the best ones. The parameters and operators of GA were set as follows: Population size=50, Crossover percentage=0.75, Mutation probability=0.1, Crossover
operator=Uniform crossover, Mutation operator=Inversion
Mutation. Also, for SA, we set the parameters and
operators as follows: Initial temperature (T0)=5500,
nmax=250, α =0.93, Neighborhood structure=Displacement
neighborhood.
Parameter Tuning:
We set searching time to be identical for both algorithms which is equal to 4.5×n milliseconds. Hence, this criterion is affected by n. The more the number of jobs,
the more the rise of searching time increases. We generated
10 instances for each combination of n and for each of
the nine problem sizes, summing to
instances which are different from the ones used for
calibration to avoid bias in the results. Considering forty
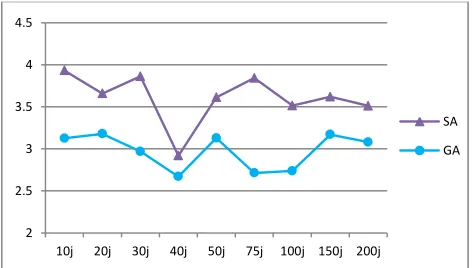
instances for each of the nine problem sizes, for both algorithms, the instances have been run three times and hence, by using the RPD we deal with 120 data for each algorithm. The averages of these data for each algorithm and each instance are shown in Fig. 3.
In order to verify the statistical validity of the results, we have performed an analysis of variance (ANOVA) to accurately analyze the results. The point that can be concluded from the results is that there is a clear statistically meaningful difference between performances of the algorithms.
The means plot and LSD intervals (at the 95% confidence level) for two algorithms are shown in Fig. 4. Since, we are to appraise the robustness of the algorithms in different circumstances, the effects of the problem sizes on the performance of both algorithms are analyzed. The reciprocal between the capability of the algorithms and the size of problems is illustrated in Fig. 3. As it is shown, GA exhibits robust performance, meanwhile the problems size increases. It also shows remarkable performance improvements of GA in large size problems versus SA.
Fig. 3. Means plot for the interaction between each algorithm and problem size
GA SA
3.8
3.6
3.4
3.2
3.0
2.8
R
P
[image:5.612.326.562.261.395.2]D
Fig . 4. Means plot and LSD intervals for the algorithms.
VI. CONCLUSION AND FUTURE WORKS
We considered a single machine scheduling problem involving sequence-dependent setup times which have three different criteria that are minimization of makespan, total earliness tardiness. Since optimizing a weighted average of these criteria is in the NP-hard class of problems, we implemented meta-heuristic methods such as genetic algo. & simulated annealing to solve this problem.
2 2.5 3 3.5 4 4.5
10j 20j 30j 40j 50j 75j 100j 150j 200j
SA
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)537
Because of the dependency of the proposed algorithms on the correct choice of parameters, various operators were employed. In order to adjust the parameters and operators of the proposed algorithms, the experimental design method was used. The computational results show the effectiveness and efficiency of GA to solve the problem and superior performance in comparison with SA in all problem size. As a suggestion for future research, other meta-heuristic methods such as Tabu Search, Simulated Annealing, Variable Neighborhood Search, Scatter Search, and Ant Colonies can be applied to this problem. Furthermore, we can consider other criteria or objectives and solve the problem with multi-criteria decision making or multi-objective methods.
Acknowledgment:
This study was partially supported by Islamic Azad University, Masjed Soleyman Branch. The authors are grateful for their financial support.
References
[1] Pinedo M. (2002). Scheduling theory: algorithm and systems.Prentice-Hall.
[2] Agnetis, A., Mirchandani, P. B., Pacciarelli, D., & Pacifici, A. (2004). Scheduling problems with two competing agents. Operations Research, 52, 229–242.
[3] Baker, K. R., & Smith, C. J. (2003). A multiple criterion model for machine scheduling. Journal of Scheduling, 6, 7–16.
[4] Allahverdi A, Ng C, Cheng T, Kovalyov MY. (2008). A survey of scheduling problems with setup times or costs. European Journal of Operational Research, 187, 985–1032.
[5] Rubin P, Ragatz G. (1995). Scheduling in a sequence-dependent setup environment with genetic search. Computers and Operations Research, 22, 85–99.
[6] Bigras L, Gamache M, Savard G. (2008). The time-dependent traveling salesman problem and single machine scheduling problems with sequence dependent setup times. Discrete Optimization, 5, 663– 762.
[7] Franca PM, Mendes A, Moscato P. (2001). A memetic algorithm for the total tardiness single machine scheduling problem. European Journal of Operational Research,132, 224–42.
[8] Sioud A, Gravel M, Gagne C. (2009). New crossover operator for the single machine scheduling problem with sequence-dependent setup times. In: GEM’09 the 2009 international conference on genetic and evolutionary methods. p. 79–84.
[9] Armentano V, Mazzini R. (2000). A genetic algorithm for scheduling on a single machine with setup times and due dates. Production Planning and Control,11, 713–20.
[10]Tan K, Narasimhan R. (1997). Minimizing tardiness on a single processor with setup- dependent setup times: a simulated annealing approach. Omega, 25, 619–34.
[11]Gupta S. R, Smith J. S. (2006). Algorithms for single machine total tardiness scheduling with sequence dependent setups. European Journal of Operational Research, 175, 722–39.
[12]Gagné, C., Price, W. and Gravel, M. (2002). Comparing an aco algorithm with other heuristics for the single machine scheduling problem with sequence-dependent setup times, Journal of the Operational Research Society, 53, 895–906.
[13] Liao, C. and Juan, H. (2007). An ant colony optimization for single-machine tardiness scheduling with sequence-dependent setups, Computers and Operations Research, 34, 1899–1909.
[14] Gagné, C., Gravel, M. and Price, W.L. (2005). Using metaheuristic compromise programming for the solution of multiple objective scheduling problems, The Journal of the Operational Research Society, 56, 687–698.
[15]Lee, Y., Bhaskaram, K. and Pinedo, M. (1997). A heuristic to minimize the total weighted tardiness with sequence-dependent setups, IIE Transactions, 29, 45–52
[16]Sioud A, Gravel M, Gagné C. (2010). Constraint based scheduling in a genetic algorithm for the single machine scheduling problem with sequence dependent setup times. In: ICEC'2010: proceedings of the international conference on evolutionary computation, 137-45.
[17]Holland, J. (1975). Adaptation in natural and artificial systems. Ann Arbor: University of Michigan Press.