Tagging accurately Don’t guess if you know
Full text
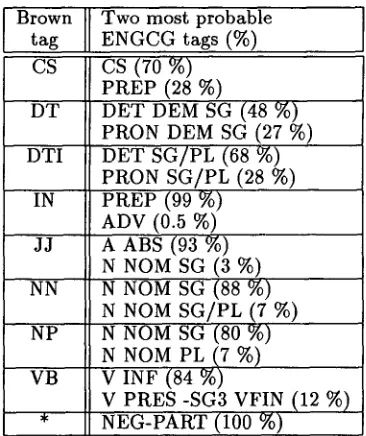
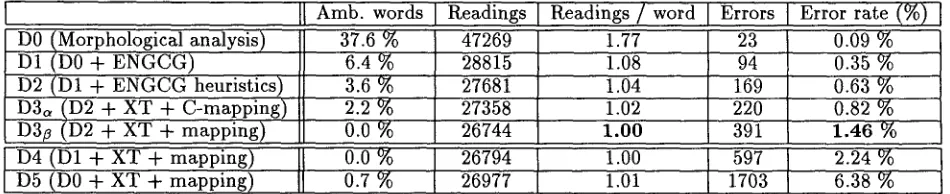
Figure
Related documents
Major computer hardware companies such as IBM, Intel, and EMC have been making great strides in patent filing in recent years.. Though as patent data is publicly available,
Founder and Director, CERT Insider Threat Center - Carnegie Mellon University Software Engineering Institute 2001-2013.. Vice President, Information Risk Management,
Based on an initial scoping of knowledge development needs, an initial list of possible functions for a PLE have been suggested, including: access/search for information and
knowledge from perception and testimony 10 already there in Sosa’s’s intention-based view. The main difference would be that the need-based stories would treat the most central
based systems give " credit for learning no matter where it happens [or how long it takes ]...students would be able to build on their own skills, abilities and knowledge, the
• Knowledge and research based development project: PhD students’ information searching behaviour and information needs. – as documented in
Proprietary Information – Copyright © 2013 by Waterfall Security Solutions
Hence, if every justification, and the knowledge based on it, is fallible then necessary propositions cannot be known; because for the belief to count as knowledge it must be
