Spatial Data and Hadoop Utilization
G
eorgios
E
conomides
| G
eorgios
P
iskas
| S
okratis
S
iozos
-D
rosos
∗Department of Informatics, Aristotle University of Thessaloniki, 54006 Thessaloniki, Greece
Keywords: Data Parallelism, Hadoop, MapReduce, Spatial Data
1.
I
ntroduction
S
patial data are mainly used for scientificresearch purposes in order to model real world problems. They are capable of accu-mulating highly detailed information, includ-ing multi-variable data sets, resultinclud-ing in enor-mous storage and processing demands.
Google’s MapReduce [1] and its implemen-tation Hadoop [2] provide us with the ability to efficiently process large scale data sets by exploiting parallelization.
Prior to current and future research presen-tation, the fundamentals of MapReduce frame-work and Hadoop are briefly introduced in section 2. We describe the step-by-step execu-tion process of this programming model, as well as its core modules. Additionally, we an-alyze the distributed file system of Hadoop (HDFS) [4] and its specialised nodes. Section 2 also explains spatial data types – vector and raster [3] – and their common usage.
In section 3 we explain how we can take advantage of Hadoop’s parallelism, aiming to achieve efficient processing of spatial data. In addition, we present many research fields where Hadoop has been proven to be a bene-fitial solution, able to manage large scale data, also known as Big Data.
Finally, in section 4 we point out the cur-rent scientific trends that will possibly be the center of attention of future research projects, regarding Hadoop and spatial data.
2.
S
cientific
B
ackground
In subsection 2.1 we introduce MapReduce framework. In subsection 2.2 we introduce Hadoop, an open source implementation of MapReduce. In subsection 2.3 we introduce spatial data and their usage.
2.1
MapReduce
MapReduce [1] is a distributed data-centric processing framework developed by Google, capable of managing large scale data efficiently, through a large number of machines (Nodes), collectively referred to as a cluster. It is used for both scientific research as well as commer-cial purposes. Typical examples of usage are webpage crawling, document processing and other computation-intensive tasks.
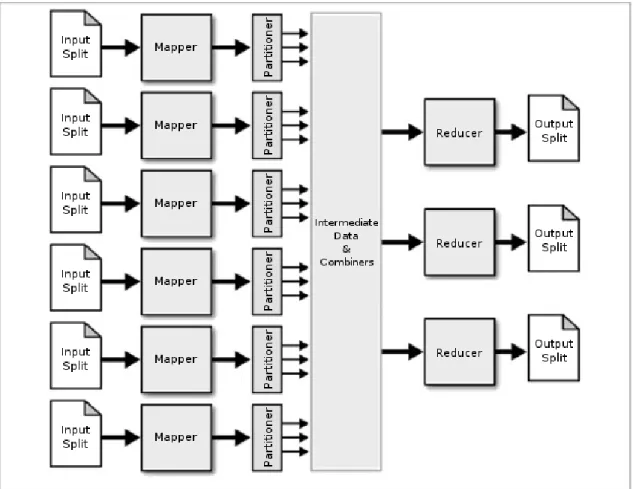
MapReduce conceals its implementation from the programmer, by requiring the cod-ing of only two functions, Map and Reduce. Secondary functions, such as the input reader, partitioner and the combiner, do not require im-plementation, but are vital to the framework’s functionality. The components of MapReduce (Figure 1) are described below.
The concept of the framework is based on divide and conquer philosophy and consists of five tasks:
• Iteration over the input.
• Computation of key/value pairs from each piece of input.
• Grouping of all intermediate values by key.
• Iteration over the resulting groups.
• Reduction of each group. ∗[email protected], [email protected], [email protected]
Figure 1:The MapReduce framework. Input Reader
Prior to Map function, the Input Reader di-vides the input data – which is also referred to as the problem – into sub-problems of appro-priate size. The partitioning outputs key/value pairs that are passed to the mappers for pro-cessing.
Mapper & Partitioner
A Mapper receives the previous pairs, processes each and outputs intermediate key/value pairs. Note that the input and out-put pairs may differ. These pairs are then grouped by their intermediate key and passed to the reducers.
The allocation of an output pair to a specific reducer is determined by the partitioner, based
on the output key and the number of reducers.
Reducer
A Reducer collects the results of sub-problems, grouped by their intermediate key. These results are then combined in a manner predefined by the programmer, forming the output which is the answer to the original prob-lem.
Combiner
In between mapping and reducing there exists an optional task, the Combiner. This function provides a partial aggregation of the key/value pairs produced by the mappers. This partial combination of intermediate pairs
aims to reduce the network overhead by trans-mitting a smaller amount of pairs. The com-biner’s implementation is very similar to the reducer’s.
2.2
Hadoop
Apache Hadoop [2] is an open source imple-mentation of Google’s MapReduce framework which was described in the previous section. Hadoop supports the execution of applications on large clusters consisting of commodity ma-chines, where an application is divided into many fragments of work that are executed par-allelly. In addition, it provides its own dis-tributed file system (HDFS) [4], which was de-rived from Google File System (GFS).
HDFS can achieve very high aggregate throughput and computational power across the cluster by replicating data on Datanodes, coordinated by the Namenode. Hadoop is writ-ten in Java programming language and is a large scale project maintained by Yahoo! and Apache.
HDFS
HDFS is a common example of master/slave architecture. The Namenode [4] is considered to be the master and Datanodes [4] the slaves. Datanodes consist of data blocks, while the Datanodes themselves are grouped into Racks. The architecture of HDFS is shown inFigure 2.
It should be pointed out that the default replication factor of HDFS is 3. This means that a data block that is initially saved in a single Datanode on a random Rack, is then replicated on two other Datanodes. One of them, by default, is on the same Rack with the initial Datanode, while the second one is on a different Rack.
The default HDFS replication policy defines that no Datanode is allowed to contain more than one replica of any block and no rack con-tains more than two replicas of the same block, provided there are sufficient racks on the clus-ter.
Figure 2:HDFS architecture. [3] The greatest benefits of HDFS are [3][4]:
• Low cost per byte.
• Data redundancy and replication.
• Large storage capacity.
• Balanced storage utilization.
• High fault-tolerance.
• High throughput rate.
• Scalability.
Namenode
The role of the Namenode [4] is the coordi-nation of the whole cluster. There exists only one Namenode per cluster, which is responsi-ble for the storage and update operations of the namespace as well as job tracking. The namespace is a tree-like hierarchic structure of the filesystem, – files and directories – which maintains a physical address mapping of data block to the equivalent Datanode.
Since every action on the cluster uses this tree, it is stored in the Namenode’s main mem-ory for faster queries. Due to the fact that there is a single Namenode per cluster, tech-niques such as metadata images, checkpoints and backup nodes exist to guarantee fault-tolerance and recovery.
To sum up, the Namenode is responsible for load balancing, job tracking and namespace handling. The latter consists of operations such as physical address and block mapping, write, read, open, close and rename.
Datanode
Datanodes [4] are the cluster’s storage space and processing units. Every Datanode in HDFS has a unique and permanent storage identifier, that is assigned to it by the Namenode, the moment it joins the cluster. The Namenode uses this ID to recognize the Datanodes and be able to communicate and exchange informa-tion with them.
Once a new Datanode is connected to the cluster, the Namenode registers a unique stor-age ID to it and the newly added node is ready for use, as soon as the handshake between the two nodes is complete. The handshake is noth-ing more than an ID verification process.
A Datanode regularly sends heartbeats to the Namenode in order to confirm that it is operational. sThe interval between heartbeat is 3 seconds by default. If no heartbeat has been received by the Namenode for 10 minutes, the Datanode is deemed out of service. In the above scenario, data stored in the unavailable Datanode are replicated to other Datanodes in order to sustain data redundancy and fault-tolerance properties.
Heartbeats, apart from notifying the Na-menode about the availability of a Datanode, are used for carrying additional information concerning work load, storage capacity and uti-lization as well as current data traffic. Such in-formation – combined with all the other heart-beats received – allow the Namenode to make load balancing decisions and efficient schedul-ing.
2.3
Spatial Data
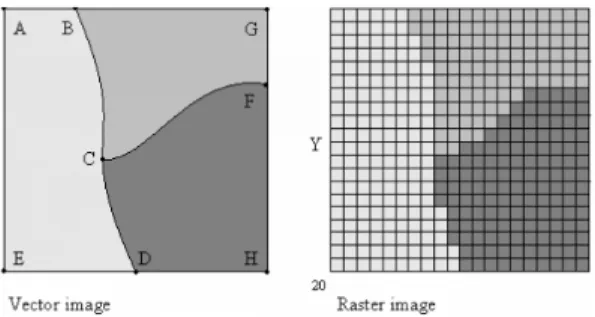
Spatial data [3][6] are multidimensional data sets of information through which we can rep-resent real world features. Using predefined spatial models, we can represent natural or constructed entities or even phenomena in a manner that computer systems can interpret. Data is saved in either Vector or Raster form. The difference between the two is visualised in Figure 3.
For instance, spatial data can be used to store coordinates by the Geographic Informa-tion System (GIS), sensor data or even repre-sent biomedical, satellite, aerial and any other type of images [5].
As far as storage is concerned, customised spatial databases [6][7] have been designed for cost-effective, scalable and efficient spatial real-time query processing. These databases, by ex-ploiting the benefits of MapReduce, provide ad-vanced multidimentional indexing techniques and effectively deal with high modification-frequency data.
Figure 3:Difference between Vector and Raster data. Common real world examples of spatial data usage:
• Proximity assessment.
• Entity identification and estimation of likeness.
• Geometric computation.
• Digital representation of elevation data.
• Topological matching and pattern analy-sis.
• Multidimensional data representation. Raster Data
Raster data [3] type is used to represent both discrete and continuous entities. This is achieved with the use of a regular grid, where the value in each grid cell corresponds to the characteristics of a spatial property at that spe-cific location. Continuous representation can be achieved using multiple grids groupped in a stack topology.
Difference between Raster and Vector data can be clearly noticed in Figure 3.
Vector Data
Vector data [3] is another spatial data type represented by vectors. Vectors consist of points, lines, polygons and regions, through which we have unlimited level of detail com-pared to Raster data. For example, we can endlessly enlarge an image without any pixela-tion effect.
Polygons are one of the most widely used spatial data type. They are capable of effec-tively representing two dimensional spatial fea-tures such as geological, medical and other scientific data.
3.
C
urrent
R
esearch
Spatial Database Design
Despite the fact that current database tech-nology is able to handle the massive storage requirements of spatial data, the efficiency of queries related to them is considered to be a very challenging research problem.
A typical database needs an index in or-der to achieve fast query processing. An index for single-dimensional data can be easily con-structed using one of the several variations of B-Trees [7].
As far as multidimensional – such as spatial – data are concerned, advanced techniques for projecting higher order dimensions to lower ones are needed. There exist mathematical models, such as Hilbert and Z-order space-filling curves [6][7] that can map multidimen-sional data to a single dimension, while pre-serving locality properties. This projection makes the data compatible with the previously mentioned B-Trees.
Another approximal solution to spatial in-dexing is the R-Tree data structure [3][6][7]. R-Tree indices group nearby entities and rep-resent them using their minimum bounding rectangle.
R-trees can be efficiently constructed us-ing a three-phase approximal algorithm that
harnesses Hadoop’s parallelization feature. A brief description (Figure 4) of each phase fol-lows.
Phase 1: Input is partitioned according to data proximity and size properties.
Phase 2: Hadoop processes the newly formed partitions, producing lower level R-Trees. Phase 3: Previous trees are combined and
form the complete R-tree index of the data.
Figure 4:R-tree construction phases. [6] Apart from database indexing, numer-ous Spatial DataBase Management Systems (SDBMS) are being developed, such as MIGIS [5].
MIGIS is a Hadoop based framework, able to handle complicated spatial queries effec-tively and with high performance. Hadoop framework is extended by two components, YSmart [5] and RESQUE [5]. Architecture of MIGIS is shown inFigure 5.
The user provides a typical SQL query, which is interpreted by YSmart. The role of YSmart is to convert the latter into MapReduce compatible query through the replacement of default operators with spatial ones, as well as optimize the execution tree ordering.
RESQUE is an execution engine which parses Spatial execution trees, extracts the
equivalent data from HDFS and finally ex-ecutes the query by taking advantage of Hadoop’s parallelization.
Figure 5:MIGIS architecture. [5] Geospatial & Spatiotemporal Analysis
A substantial amount of research effort is focused on the analysis of physical entities or phenomena that are sampled via sensors, GPS satellites and other geospatial information sys-tems [3].
The previously mentioned sampling tools produce a massive amount of data sets, – also known as Big Data – the processing of which is deemed a challenging task. By exploiting the parallelization advantage of Hadoop over outdated sequential processing tools such as PASSaGE [8], we can overcome this difficulty and efficiently handle them.
MapReduce framework is also used to solve another spatial data problem related to map-ping and topology, where the purpose of the study is to achieve improved accuracy on au-tomatic road-to-map alignment, by combining satellite and vector data.
Roads usually consist of continuous pat-terns along with other related parameters, such as ground and road color differences. Smart parallelizable algorithms utilize the above in-formation aiming to confine human interaction and consequently reduce the error rates.
In addition, since a variety of physical phe-nomena, such as motion, are not static, we need an extra variable in order to accurately represent them. This variable is time in the
sense of sampling frequency. This type of aug-mented spatial data, also known as Spatiotem-poral data, presumes massive available storage space – corresponding to sampling frequency – and processing efficiency.
At this point, we should recall the scala-bility feature of Hadoop [2]. By adding an additional dimension, the problem is automati-cally scaled up, but HDFS combined with paral-lelization is once more proven to be an effective workaround.
Biomedical Analysis
Hadoop framework is also used in other im-portant research fields, such as medicine and biomedical science, along with their applica-tions.
The most frequently produced spatial data are in the form of images, the resolution of which can exceed 100K x 100K pixels [5]. How-ever, medical datasets consist of numerous im-ages, causing storage requirements, during a study, to scale up to tens of Terabytes or even Petabytes. Moreover, the previous datasets in-clude additional variables in order to express scientific information.
Common query types that are submitted to the above datasets include the following [5]:
a.
Multiway spatial join query.b.
Nearest neighbour query.c.
Global density pattern query.Query
a
in (Figure 6) includes cross-matching, comparison and consolidation of algorithm results. For example a spatial join query is used for pattern matching and entity identification in a medical image.Query
b
in (Figure 6) includes the compu-tation of nearest blood vessel for each cell and distance between them.Query
c
in (Figure 6) illustrates identifica-tion of tumor subtypes using density values and their characteristics through regional co-location patterns.Figure 6:Medical queries. [5] In order to be able to process these complex
and expensive queries, MIGIS [5] framework – which was previously described – has been developed especially for this purpose, since tra-ditional database systems are impractical for such workload.
Apart from static sample analysis, Hadoop can be used for simulation purposes, such as molecular dynamics simulation, [9] which is considered to be a computationally intensive application, due to atom spatial decomposi-tion.
4.
F
uture
R
esearch
Due to the enormous need for efficient pro-cessing, query optimization [5] research is a prioritised task. Spatial databases are an indis-pensable part of every data intensive research project, thus we need a more intelligent opti-mizer which can pick the best plan according to query type and data topology.
Current technology has reached a point where storage space is not an issue. However, there is still room for improvement regarding inter-cluster connectivity. It is crucial to re-duce network overhead between nodes, racks and generally within the cluster while boosting the internal network bandwidth for faster data transmission.
Apart from a CPU, nowadays most comput-ing units include a Graphics Processcomput-ing Unit
(GPU) [10]. The most modern – high end – GPUs consist of multiple processors and re-dundant built-in memory, so that they can cope with demanding computation tasks.
Due to their high performance, it would be wise to integrate them to a parallel process-ing framework such as Hadoop. An important drawback of a GPU is that it does not feature a programmer-friendly Application Program-ming Interface (API), resulting in difficult ex-ploitation.
A great deal of research activity is focused on the development of a hybrid MapReduce framework, harnessing both CPU and GPU resources. Mars [10] is an experimental frame-work that implements scheduling, load balanc-ing and synchronization between the CPU and GPU. It can achieve up to 16 times greater per-formance than typical setups.
Another field of interest is the evaluation of statistics and parameters by a Decision Sup-port System (DSS) [11]. A decision made by this kind of systems is an aggregate assessment of the problem’s variables.
The point is that we need to extract a deci-sion as fast as possible, thus a parallelization framework, such as Hadoop, – combined with machine learning – can greatly speed up the process. In addition, recommendation systems can also benefit, as they are closely related to decision support systems.
5.
C
onclusion
In this paper, we outlined the importance of spatial data, since they are used in almost every research field that needs to depict multi-dimensional data. We illustrated how they can be efficiently processed in a parallel manner. Furthermore, due to ever-growing data sets, the need arises for technological advancements towards information management.
It is clearly understandable that parallel computing is more beneficial over sequential methods. As a result, the way towards paral-lelization – MapReduce and its implementa-tion, Hadoop – will be the solution to a variety of difficult computational problems.
R
eferences
[1] Ralf Lammel, 2008, Google’s MapReduce programming model – Revisited,Science of Computer Programming 2008, 70, pp. 1-30. [2] Apache Hadoop.
http://hadoop.apache.org/
[3] Abhishek Sagar, Umesh Bellur, 2011, Dis-tributed Computation on Spatial Data on Hadoop Cluster,Department of Computer Science and Engineering Indian Institute of Technology, Bombay Mumbai-400076. [4] Konstantin Shvachko, Hairong Kuang,
Sanjay Radia, Robert Chansler, 2010, The Hadoop Distributed File System, IEEE 2010, 978-1-4244-7153-9/10.
[5] Ablimit Aji, Fusheng Wang, 2012, High Performance Spatial Query Processing for Large Scale Scientific Data, SIGMOD’12 PhD Symposium, pp. 9-14.
[6] Ariel Cary, Zhengguo Sun, Vagelis Hris-tidis, Naphtali Rishe, 2009, Experiences on Processing Spatial Data with MapReduce, SSDBM 2009, pp. 302-319.
[7] Liu Yi, Jing Ning, Chen Luo, Chen Huizhong, 2011, Parallel Bulk-Loading of Spatial Data with MapReduce: An R-tree Case,Wuhan University – Journal of Natural Sciences, pp. 513-519.
[8] Michael S. Rosenberg, Corey Devin An-derson, 2011, PASSaGE: Pattern Analysis, Spatial Statistics and Geographic Exegesis. Version 2,Methods in Ecology and Evolution 2011, 2, pp. 229-232.
[9] Chen He, 2011, Molecular Dynamics Sim-ulation Based on Hadoop MapReduce, DigitalCommons@University of Nebraska -Lincoln.
[10] Bingsheng He, Naga K. Govindaraju, Wen-bin Fang, Tuyong Wang, Qiong Luo, 2011, Mars: A MapReduce Framework on Graphics Processors,PACT 2008, ACM 978-1-60558-282-5/08/10.
[11] Samadi Alinia, M. R. Delavar, 2008, Ap-plications of Spatial Data Infrastructure in Disaster Management,Management, Dept. of Surveying and Geomatics Eng., Collage of Eng., University of Tehran, Tehran, Iran.
![Figure 2: HDFS architecture. [3]](https://thumb-us.123doks.com/thumbv2/123dok_us/1581622.2712651/3.918.478.784.136.302/figure-hdfs-architecture.webp)
![Figure 4: R-tree construction phases. [6]](https://thumb-us.123doks.com/thumbv2/123dok_us/1581622.2712651/5.918.473.784.361.631/figure-r-tree-construction-phases.webp)
![Figure 5: MIGIS architecture. [5]](https://thumb-us.123doks.com/thumbv2/123dok_us/1581622.2712651/6.918.147.443.233.350/figure-migis-architecture.webp)
![Figure 6: Medical queries. [5]](https://thumb-us.123doks.com/thumbv2/123dok_us/1581622.2712651/7.918.145.778.136.329/figure-medical-queries.webp)
