Multiframe Error Concealment for MPEG-Coded
Video Delivery Over Error-Prone Networks
Yen-Chi Lee, Student Member, IEEE, Yucel Altunbasak, Senior Member, IEEE, and
Russell M. Mersereau, Fellow, IEEE
Abstract—Compressed video sequences are very vulnerable to channel disturbances when they are transmitted through an unre-liable medium such as a wireless channel. Transmission errors not only corrupt the current decoded frame, but they may also prop-agate to succeeding frames. A number of post-processing error concealment (ECN) methods that exploit the spatial and/or tem-poral redundancy in the video signal have been proposed to combat channel disturbances. Although these approaches can effectively conceal lost or erroneous macroblocks (MBs), all of them only con-sider spatial and/or temporal correlation in a single frame (the corrupted one), which limits their ability to obtain an optimal re-covery. Since the error propagates to the next few motion-compen-sated frames in the presence of lost MBs in an or frame, error concealment should simultaneously minimize the errors not only in the current decoded frame but also in the succeeding and frames that depend on the corrupted frame. In this paper, we pro-pose a novel multiframe recovery principle which analyzes the prop-agation of a lost MB into succeeding frames. Then, MPEG-compat-ible spatial and temporal error concealment approaches using this multiframe recovery principle are proposed, where the lost MBs are recovered in such a way that the error propagation is mini-mized.
Index Terms—Error concealment, error propagation, error-re-silient video communications, MPEG, multiframe processing.
I. INTRODUCTION
T
HE DEMAND for real-time video transmission over the Internet has increased rapidly in recent years. This is not only because of the success of the Internet and the availability of broadband access technologies to residential users, but also because of the efficacy of image and video compression tech-niques.Most video compression methods, such as those in the MPEG-2 and H.263 standards, use a block-based discrete cosine transform (DCT) with motion-compensation to remove spatial and temporal redundancy. In an MPEG-coded video bitstream, each frame is divided into slices, and each slice is divided into macroblocks (MBs), which, in turn, are split into blocks. The contents of each block are quantized and encoded using variable length entropy coding. Although these hybrid
Manuscript received July 2, 2001; revised June 24, 2002. This work was sup-ported in part by the National Science Foundation (NSF) under Grants CCR-0105654 and CAREER-0133221. The associate editor coordinating the review of this manuscript and approving it for publication was Dr. Thiow Keng Tan.
The authors are with the Center for Signal and Image Processing, School of Electrical and Computer Engineering, Georgia Institute of Technology, At-lanta, GA 30332-0250 (e-mail: [email protected]; [email protected]; [email protected]).
Digital Object Identifier 10.1109/TIP.2002.804275
motion compensation-DCT based compression methods suc-cessfully reduce the bit rate, they are very sensitive to channel disturbances because of the variable length entropy encoding that they employ, especially in an error-prone environment, such as a wireless channel. A single bit error may corrupt all the MBs within a slice and significantly degrade the video quality. In addition, because of motion compensation, this error may propagate to succeeding frames.
Postprocessing error concealment (ECN) is an effective way to combat channel disturbances and has been widely investigated [1]. This approach exploits the spatial and/or temporal redundancy in the video sequence to estimate lost or erroneous MBs. For spatial ECN, intraframe interpolation, which uses the available neighbors of the lost MB, is probably the most common form. One simple spatial ECN approach uses bilinear interpolation from the neighboring available pixels [2]. Wang et al. proposed a method that operates in the frequency domain by minimizing a measure of spatial variation between adjacent pixels in the MB to be reconstructed and spatially neighboring pixels using the principle of “maximally smooth recovery” [3]. It reduces to bilinear interpolation when all DCT coefficients are lost. This method was later extended to include temporal smoothness [4]. Edge-adaptive and second-order extensions have also been proposed in [5], [6]. Hemani and Meng proposed an algorithm that reconstructs the corrupted block from a linear combination of adjacent blocks [7]. Park et al. presented an approach that is a special case of Wang’s method and applied it to MPEG-2 video [8]. Sun et al. adopted projection onto convex sets (POCS) to conceal the errors [9]. Lee et al. proposed a fuzzy logic approach to recover both low-and high-frequency coefficients [10].
Another group of post-processing error concealment methods exploits temporal redundancy. Motion-compensated temporal prediction, which is the most common of these approaches, has been shown to be effective at concealing lost MBs by simply exploiting the strong temporal correlation between the current decoded frame and the previous one [1]. However, this approach requires knowledge of the motion information of the lost MBs. Because of the variable length coding that is employed, the mo-tion vector of the corrupted MB might also be lost, in which case it needs to be estimated. One way to handle this case is to re-place an impaired MB by the spatially corresponding MB from the previous frame. However, this approach may cause objec-tionable artifacts if the motion between frames is significant. A more robust method uses the motion vectors of the neighboring MBs. Haskell et al. used the median of the motion vectors from the spatially adjacent MBs as an estimate of the missing motion 1057-7149/02$17.00 © 2002 IEEE
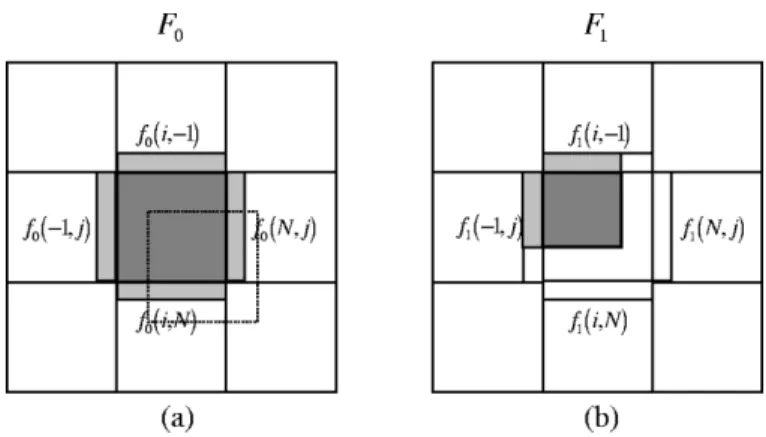
Fig. 1. Illustration of the multiframe recovery principle. In the spatial domain, the spatially interpolated MB (center) in (b) should maximize the boundary smoothness measure atF and the following frames. In the temporal domain, the lost motion vector is selected such that the motion compensated MB maximizes the boundary smoothness measure atF and F . The arrows in (b) and (c) indicate where the boundary smoothness is imposed.
vector [11]. This can be further extended to search for a motion vector that best matches the neighboring pixels of the lost MB in the previous frame. Lam et al. proposed a boundary matching algorithm (BMA) to search for the motion vector based on a spatial smoothness constraint on the boundaries of a lost MB [12]. The drawback of this method is that the boundary infor-mation may not be sufficient to estimate the motion vector ac-curately, especially if the left and right MBs are not available. In addition, slanting edges and rapid gray-level changes may cause a large variation and the BMA may fail [13]. Park et al. proposed an improved BMA to estimate the motion vector by imposing additional smoothness properties on the diagonal and anti-diagonal directions for slanting edges and subpixel sam-ples for rapid gray-level changes [13]. Feng et al. also proposed a similar method to handle the cases when there are diagonal and anti-diagonal edges on the boundaries [14]. In addition to BMA-based methods, block-matching (BM) methods have also been proposed to recover the lost MBs. Zhang et al. presented an approach that estimates the motion vector by searching the most similar neighbors of the lost MB in the previous frame [15]. Tsekeridou developed a block-matching algorithm to match the upper and lower adjacent MBs of the lost one to conceal the damage [16]. Again, the unavailability of the left and right MBs may cause an improper motion vector estimate.
Although these spatial and temporal error concealment approaches can effectively conceal lost or erroneous MBs, all of them only consider spatial and/or temporal correlation in a single frame (the corrupted one). In other words, these existing error concealment approaches do not consider the fact that errors propagate to succeeding intercoded frames. This limits their ability to get an optimal recovery. Since errors propagate to the next few motion-compensated frames in the presence of lost MBs in an or frame, the operation of recovering the lost MBs should simultaneously minimize the errors not only in the current decoded frame but also in succeeding and frames. Motivated by this observation, we propose a novel multiframe recovery principle that analyzes the propagation of a lost MB in succeeding frames. Then, MPEG-compatible spatial and temporal error concealment approaches using this multiframe recovery principle are proposed, where the lost
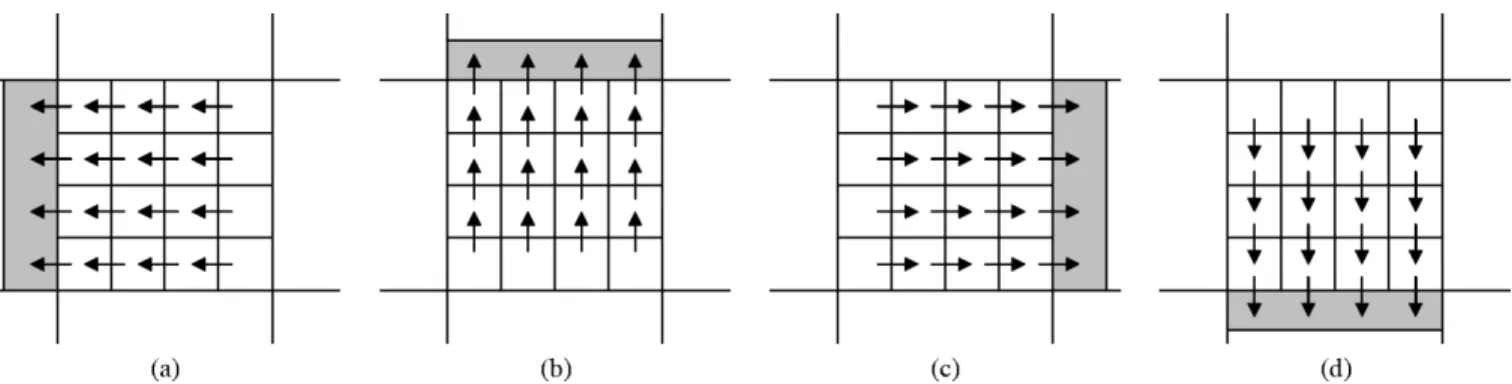
Fig. 2. Illustration of multiframe spatial error concealment algorithm.
MBs are recovered in such a way that the error propagation is minimized.
The rest of this paper is organized as follows. The proposed approach is described in Section II. Section III presents spa-tial and temporal error concealment approaches using the mul-tiframe recovery principle. The simulation results are illustrated in Section IV. Finally, our conclusions are given in Section V.
II. MULTIFRAMERECOVERYPRINCIPLE
Motion-compensation is used in MPEG-like video coding standards to reduce temporal redundancy. It exploits the tem-poral correlation between frames and establishes a frame depen-dence using motion vectors. However, this frame dependepen-dence causes errors in one frame to propagate to succeeding frames until an intracoded MB is encountered. This error propagation degrades the video quality in the succeeding frames, even when the succeeding data is received correctly. Thus, an error conceal-ment procedure should not only minimize the immediate impact of packet loss (or bit errors) on the current frame, but should also minimize the propagation of errors to any dependent frames. Here, we propose a multiframe recovery principle that explic-itly analyzes the error propagation of the lost MB and directly minimizes the propagation of errors across multiple frames.
Let us assume that a MB is lost in frame . This lost mac-roblock is depicted in the center position in Fig. 1(b). Frame
Fig. 3. Four directions of the smoothness measure for the lost MB, for a 42 4 MB example in frame F in Fig. 2: (a) left, (b) right, (c) above, and (d) below. The arrows denote the subtraction of the intensities of two adjacent pixels.
Fig. 4. Illustration of multiframe temporal error concealment algorithm.
TABLE I
PSNR COMPARISONS OFDIFFERENTSPATIALERRORCONCEALMENTMETHODS FOREACHI FRAME IN THETESTSEQUENCEFLOWERGARDEN
is a motion-compensated frame that references , as illus-trated in Fig. 1(b) and (c). The dashed squares in Fig. 1(b) rep-resent the MBs from which the intercoded MBs that are labeled as 1, 3, and 5 in are copied. Because of motion compensa-tion, the error propagates to , where it affects the gray areas shown in Fig. 1(c). For spatial error concealment, almost all al-gorithms maximize a spatial smoothness measure over a local neighborhood of the lost MB. For temporal error concealment, this boundary smoothness property is also successfully applied to search for the lost motion vector by minimizing intensity
vari-ations along the MB boundaries. With either spatial or temporal error concealment, this boundary smoothness property should be simultaneously applied to both frames and . Thus, the optimal solution for estimating this lost MB should apply the maximal boundary smoothness measure to both and the af-fected parts of . This is shown in Fig. 1(b) and (c), where the arrows indicate the boundaries where the smoothness constraint is to be imposed. If the boundary smoothness measure of the lost MB is defined as on , and on , the estimate of the lost MB should simultaneously maximize and . Thus, our
TABLE II
PSNR COMPARISONS OFDIFFERENTSPATIALERRORCONCEALMENTMETHODS FOREACHI FRAME IN THETESTSEQUENCETABLETENNIS
Fig. 5. PSNR comparisons of multiframe spatial error concealment for differentp for consecutive 72 frames in the test sequence FLOWERGARDEN. goal is to find either the optimal interpolated MB (spatial error
concealment) or the motion vector to perform motion com-pensation to recover the lost MB (temporal error concealment), shown in Fig. 1(a) and (b), such that the boundary smoothness
on both and is maximized.
A more general and precise treatment can be given as follows: For a lost MB in frame , assume that there are intercoded MBs that are affected by its loss in frame . Based on the multi-frame recovery principle, the optimal estimate should minimize the error not only in the impaired frame but also in the suc-ceeding affected motion-compensated frames. Therefore, the optimal interpolated MB can be obtained by maximizing an ob-jective function defined as a sum of the boundary smoothness measures in each frame
(1)
Notice that is the number of dependent frames that are used to conceal the lost MBs. It controls the quality of the concealed images. Equation (1) can be reduced to single-frame error con-cealment if is set to zero.
III. ERRORCONCEALMENT USING THEMULTIFRAME RECOVERYPRINCIPLE
In this section, two MPEG-compatible spatial and temporal error concealment methods that use the multiframe recovery principle are described. Both methods recover the lost MBs by utilizing the available boundary pixels of the local neigh-borhood. In the spatial case, the lost MB is recovered by maximizing a smoothness measure across multiple frames. In the temporal case, the motion-compensated MB uses an estimated motion vector that exhibits the minimal boundary variation in the current decoded frame as well as in the depen-dent succeeding intercoded frames.
Fig. 6. PSNR comparisons of multiframe spatial error concealment for differentp for consecutive 72 frames in the test sequence TABLETENNIS. A. Multiframe Spatial Error Concealment
In this section, we present a spatial error concealment al-gorithm based on the multiframe recovery principle. For sim-plicity, assume that only one MB with pixel intensities,
, , , in frame is lost, as shown
in Fig. 2(a). Based on the smoothness property underlying the image, this lost MB can be recovered by maximizing a smooth-ness measure within the lost MB as well as on the boundary pixels of the neighboring MBs [3]. This smoothness measure can be defined using a function that calculates the differences of pixel intensities of the boundary pixels of the local neighbor-hood in four directions (left, right, above, and below), as shown in Fig. 3. Following [3] this can be expressed as the following:
(2) represents the vector of the recovered (estimated) pixel in-tensities, , which are arranged in a row-major order. , , , and are weighting matrices for the left, right, above, and below directions, respectively. , , , and are the vectors formed individually from the boundary pixel values,
, , and , respectively, of
the local neighborhood, as depicted by the light gray areas in Fig. 2(a). For example, for a 4 4 block, the elements of and can be defined as the following:
(3)
where
(4)
, , are the weights for smoothing two
adjacent pixels in the left direction. Since some of the neigh-boring MBs may not be available to perform the estimation, we can simply drop the terms in (2) corresponding to unavailable boundaries. An alternative approach is to set the boundary vec-tors and the corresponding weights in the weighting matrices to zero to still maintain the smoothing operation within the esti-mated MB. We adopted the second approach in the simulation section. Additional details about these weight matrices can be found in [3], and can be specified in such a way that they are equivalent to the second-order derivative smoothness measure proposed in [6]. Note that the maximization of the smoothness measure is equivalent to the minimization of the magnitude of (2).
Consider an intercoded MB in that references the lost MB in as shown in Fig. 2(b). The affected part of this intercoded MB is shown as the dark gray area in Fig. 2(b), and the dashed square in Fig. 2(a) denotes its motion-compensated MB. The reconstruction of the affected part can be represented as
Fig. 7. Spatial error concealment of frame 60 of the sequence FLOWERGARDENat the packet loss rate 10 . (a) Original image. (b) Corrupted image. (c) Error concealed image using single-frame spatial error concealment. (d)–(f) Error concealed images using multiframe spatial error concealment whenp = 1, p = 3, andp = 6, respectively.
where is the motion vector and is the residual
signal. Since only the affected part is of interest, (5) can be fur-ther expressed in a matrix form that only considers the affected region
(6) and represent the pixel intensities and residual signal of the intercoded MB in vector form and are formed by setting the elements corresponding to the unaffected part to zero. is a matrix that transforms into according to the motion vector . Thus, (6) establishes a direct relation between the af-fected intercoded MB in frame and the lost MB in frame .
The boundary smoothness measure in frame can be speci-fied in the same way as in (2) and can be further written in terms of
Fig. 8. Spatial error concealment of frame 60 of the sequence TABLETENNISat the packet loss rate 10 . (a) Original image. (b) Corrupted image. (c) Error concealed image using single-frame spatial error concealment. (d)–(f) Error concealed images using multiframe spatial error concealment whenp = 1, p = 3, andp = 6, respectively.
It is noted that the boundary vectors, , , and ,
which are adjacent to the affected areas, as depicted the light gray areas in Fig. 2(b), are used in (7). In [3], the minimization of (2) is performed in the frequency domain using the available DCT coefficients. However, in an MPEG bitstream, because of the variable length coding, a single packet lost or bit error might cause the loss of all DCT coefficients. Here, we assume none of the DCT coefficients are received for the lost MB; therefore, the minimization of (2) is performed in the spatial domain. In this case, single-frame spatial error concealment amounts to min-imizing by taking a derivative with respect to and setting the result to zero. Using the multiframe recovery
prin-ciple, both and have to be minimized. Their sum,
, is the total objective function:
(8) Since is a quadratic function of , the minimal point occurs where the derivative with respect to is zero:
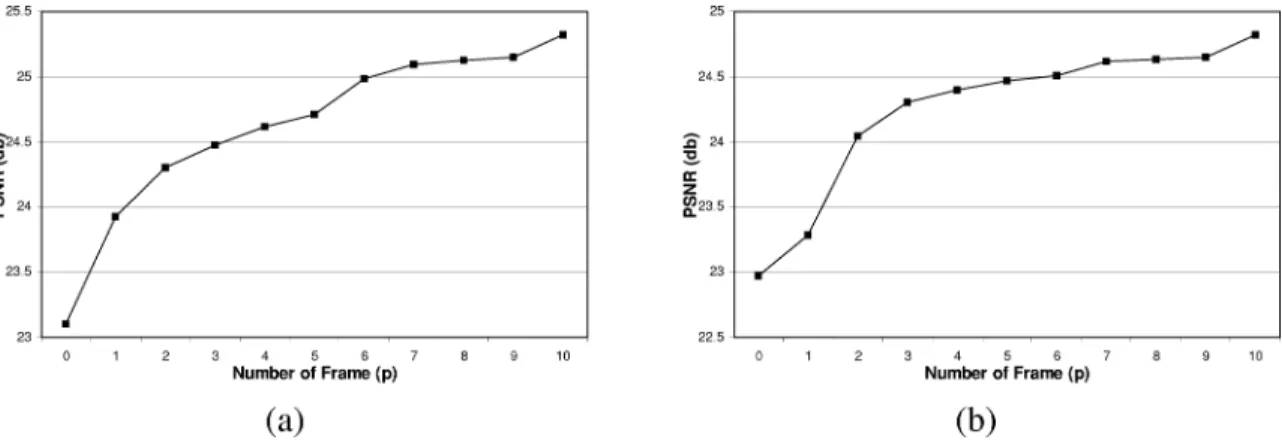
Fig. 9. PSNR of (a) frame 24 and (b) frame 60 versusp in the sequence FLOWERGARDENfor multiframe spatial error concealment.
Fig. 10. PSNR of (a) frame 24 and (b) frame 60 versusp in the sequence TABLETENNISfor multiframe spatial error concealment. TABLE III
PSNR COMPARISONS OFDIFFERENTTEMPORALERRORCONCEALMENTMETHODS FOREACHP FRAME IN THETESTSEQUENCEFLOWERGARDEN
where
The optimal solution for using two frames is given as (10) In the case where there are frames that reference frame and intercoded MBs that are affected by the lost MB in each frame, (8) can be straightforwardly extended to the following:
(11)
Therefore, the optimal estimate of a given lost MB using frames can be obtained from
(12)
B. Multiframe Temporal Error Concealment
Another class of error concealment algorithms exploits the interframe correlation to recover the lost MB by a motion-com-pensated MB using an estimated motion vector, , as illus-trated in Fig. 4(a) and (b). This approach usually performs better
TABLE IV
PSNR COMPARISONS OFDIFFERENTTEMPORALERRORCONCEALMENTMETHODS FOREACHP FRAME IN THETESTSEQUENCETABLETENNIS
Fig. 11. PSNR comparisons of different temporal error concealment methods for 24 consecutive frames in the test sequence FLOWERGARDEN. than spatial error concealment when the lost MB can be
pdicted from the previous decoded frame. This prediction re-quires a motion estimation. A simple approach is to use a zero motion vector; i.e., the lost MB is replaced by the spatially cor-responding MB in the previous decoded frame. This can be im-proved by employing the spatial correlation of motion vectors of the neighboring available MBs. A more robust approach of esti-mating this motion vector is to perform a search among a set of candidate vectors in the previous frame. This approach also ex-ploits boundary smoothness and the motion vector is selected to minimize the boundary variation between the boundaries of the current damaged MB and those of the adjacent ones [12]. How-ever, the boundary information may not be sufficient to obtain an accurate motion vector. Here, we present a better temporal error concealment using the multiframe recovery principle and the boundary smoothness property. The proposed algorithm can be viewed as an extension of the method in [12].
Again, assume only one MB with pixel intensities,
, , , in frame is lost, as shown in
Fig. 4(b). This lost MB is replaced by a motion-compensated MB from frame using a candidate motion vector , as de-picted in Fig. 4(a) and (b). The boundary variation in using
this prediction can be defined as the squared difference between the pixel intensities of the predicted MB and those of the neigh-boring MBs
(13) where
ifleft MB is available; otherwise;
ifright MB is available; otherwise;
ifupper MB is available; otherwise;
Fig. 12. PSNR comparisons of different temporal error concealment methods for 24 consecutive frames in the test sequence TABLETENNIS.
iflower MB is available; otherwise.
is the pixel intensity of the reconstructed frame and is the pixel intensity of the predicted MB using the
mo-tion vector from frame . , , , and are the
boundary pixel vectors of this motion-compensated MB, as de-picted by the dark gray areas in Fig. 4(b). , , , and are the boundary pixel vectors from the boundary pixel values of the local neighborhood, as depicted by the light gray areas in Fig. 4(b).
Consider that an intercoded MB in references the lost MB in as shown in Fig. 4(c). The dashed square in Fig. 4(b) denotes its motion-compensated MB. The boundary variation of the affected part in is defined as the following:
(14) Since only the affected part is of interest, the boundary variation calculates the difference only on the boundary pixels from the left and above directions, and , as shown in the dark gray areas in Fig. 4(c). and only contain the boundary pixels adjacent to the affected part in the local neighborhood, as shown in the light gray areas in Fig. 4(c). If the boundary information is not available, then the terms corresponding to the unavailable boundaries are set to zero. Based on the multiframe recovery principle, in this simplified scenario, the motion vector should be selected to minimize and simultaneously (15) The general framework works as follows: Assuming that there are frames that reference frame and intercoded MBs that are affected by the lost MB in each frame, a selected motion
vector should minimize the total boundary variation, which is simply the sum of individual boundary variations of the affected MBs for a given lost MB in frame
(16) where
(17) is the index of the affected intercoded MB. Notice that only the boundary pixels in the affected area are used to calculate the boundary variation . If any boundary is not available or is not of interest, we simply drop the term in (17) corresponding to the unavailable boundary. The predicted MB using the estimated motion vector that minimizes the total boundary variation is chosen to restore the lost MB in frame
(18)
is the set of all possible candidates. Since a full search algo-rithm is too complicated to be implemented in the decoder, an alternative way to determine is to search in a smaller range based on the following motion vectors:
• motion vector of the spatially corresponding MB in the previous frame;
• motion vectors of the available neighboring MBs; • zero motion vector.
Because the motion vectors of the neighboring MBs are highly correlated, it is reasonable to estimate the MB based on those motion vectors. A search range is specified in order to allow small variation.
Fig. 13. Temporal error concealment of frame 87 of the sequence FLOWERGARDENat the packet loss rate 10 . (a) Original image. (b) Corrupted image. (c) Concealed image using the copying method. (d) Concealed image using the boundary matching algorithm (BMA). (e) Concealed image using multiframe spatial error concealment whenp = 3. (f) Magnified portion of (d) and (e), respectively.
IV. SIMULATIONS
Two standard video sequences, FLOWER GARDEN and TABLE TENNIS, are used to evaluate the performance of the proposed multiframe error concealment algorithms. These video sequences are in the format 4 : 2 : 0, 352 240 pixels per frame, coded using MPEG-1 at the rate of 1.5 Mb/s. Each
GOP consists of 12 frames ( , ), and a slice is
composed of 22 MBs. In the simulation, spatial and temporal error concealment approaches using the multiframe recovery principle are performed individually. The peak signal-to-noise ratio (PSNR) is adopted for objective measurement. Trans-mission errors are simulated according to a two-state Markov model, namely the Gilbert channel model, with a 10 average
packet loss rate (PLR). The probability of transiting from bad state to good state is 0.25. To simplify the simulations, we assume the picture header is not damaged and always received. The packetization approach is simply to partition the bitstream into equal-sized packets.
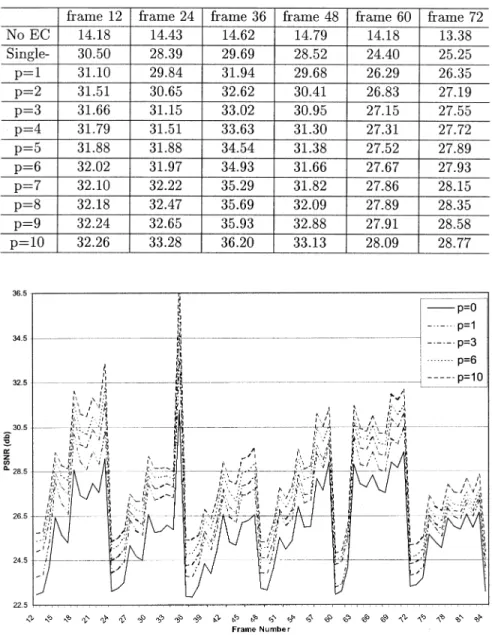
Tables I and II demonstrate the PSNR for the multiframe spa-tial error concealment method in FLOWERGARDENand TABLE TENNIS, respectively. Only the PSNRs of frames are com-pared. In both video sequences, multiframe error concealment always outperforms single-frame error concealment. The per-formance can be further improved as the number of frames in-creases. It is noted that the maximum number of frames that can be used for concealment is limited to the number of frames in one GOP. Here, single-frame spatial error concealment simply
Fig. 14. Temporal error concealment of frame 51 of the sequence TABLETENNISat the packet loss rate 10 . (a) Original image. (b) Corrupted image. (c) Concealed image using the copying method. (d) Concealed image using the boundary matching algorithm (BMA). (e) Concealed image using multiframe spatial error concealment whenp = 3. (f) Magnified portion of (d) and (e), respectively.
Fig. 16. PSNR of (a) frame 63 and (b) frame 75 versusp in the sequence TABLETENNISfor multiframe temporal error concealment.
Fig. 17. Spatial error concealment of frame 48 of the sequence FLOWERGARDENat the packet loss rate 10 . (a) Original image. (b) Corrupted image. (c) Error concealed image using single-frame spatial error concealment. (d)–(f) Error concealed images using multiframe spatial error concealment whenp = 1, p = 3, andp = 6, respectively.
Fig. 18. Spatial error concealment of frame 12 of the sequence TABLETENNISat the packet loss rate 10 . (a) Original image. (b) Corrupted image. (c) Error concealed image using single-frame spatial error concealment. (d)–(f) Error concealed images using multiframe spatial error concealment whenp = 1, p = 3, andp = 6, respectively.
sets to zero in (12) so that only the boundary information around the lost MBs is utilized. This single-frame error con-cealment can also be treated as a special case of Wang’s method when all DCT coefficients are lost, if layered coding or data par-titioning is not used [3]. Note that, in Wang’s method, the op-eration of concealing the lost block is done iteratively in order to reduce the blocking artifacts on the left and right boundaries. However, since all the DCT coefficients are not available in our simulation, the iterative operation changes only the DC value around the boundaries of the lost MBs and does not help to recover the detail. Hence, in order to reduce the computation complexity, the operation of concealment is applied only once for both the single-frame and multiframe cases. Figs. 5 and 6 illustrate the PSNR comparisons of the impaired frames as well as the succeeding frames. The proposed multiframe error
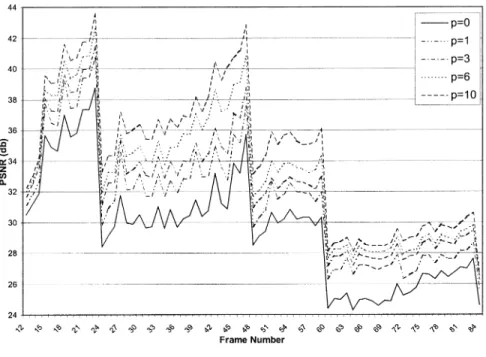
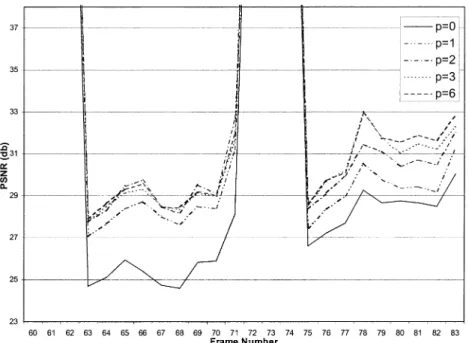
con-cealment method not only improves the quality of the corrupted frames ( frames) in both test video sequences, but also reduces the error propagation in the succeeding frames.
The visual comparisons of the spatial error concealment are given in Figs. 7 and 8. The recovered MBs using single-frame error concealment are obviously blurred, and the detailed con-tents are completely lost, as demonstrated in Figs. 7(c) and 8(c). The blurring effects result from the smoothing operation in four directions in (2). Since the left and right boundary information may not be available, single-frame EC only utilizes the upper and lower boundary information to interpolate the lost MBs. Therefore, it only works well when the lost MBs are within an intensity-smooth area, as shown in the middle of the sky and the tennis table in Figs. 7(a) and 8(a), individually. For multi-frame EC, the detail of the lost MBs is gradually recovered as
Fig. 19. Temporal error concealment of frame 111 of the sequence FLOWERGARDENat the packet loss rate 10 . (a) Original image. (b) Corrupted image. (c) Concealed image using the copying method. (d) Concealed image using the boundary matching algorithm (BMA). (e) Concealed image using multiframe spatial error concealment whenp = 3.
the number of frames increases, as illustrated in Figs. 7(d)–(f) and 8(d)–(f). Moreover, the blocking artifacts are also reduced because the motion-compensated MBs in the succeeding frames may lie across the borders of the lost MBs and the smoothing operation reduces the discontinuities between two MBs. The number of frames, in (12), controls the quality of concealed images. Note that the incremental improvement of the video quality decreases as increases, because of the weakening of the frame dependence, as illustrated in Figs. 9 and 10. Figs. 17 and 18 depict the images for the packet loss rate of 1%.
For temporal error concealment, three methods have been im-plemented in our simulation: the copy method, the boundary matching algorithm (BMA) [12], and the proposed multiframe method. The copy method simply replaces the lost MBs with the spatially corresponding MBs in the previous frame. BMA
is equivalent to setting to zero in (18). The search range, , is set to 5 to allow small variations. The PSNR comparisons, as shown in Tables III and IV demonstrate that the motion vector can be estimated more accurately by using the information in multiple frames. Figs. 11 and 12 illustrate the PSNR compar-isons of the impaired frames and the succeeding frames. Again, the proposed multiframe error concealment method not only im-proves the quality of the corrupted frames ( frames) in both video sequences, but also reduces the error propagation in the succeeding frames. Figs. 13 and 14 present the visual compar-isons. For the copy method, we can easily observe the objec-tionable artifacts caused by motion, as shown in Figs. 13(c) and 14(c). In Figs. 13(d) and 14(d), the BMA can produce an accept-able recovered image. However, since it only exploits boundary information above and below (the left and right MB are not
Fig. 20. Temporal error concealment of frame 39 of the sequence TABLETENNISat the packet loss rate 10 . (a) Original image. (b) Corrupted image. (c) Concealed image using the copying method. (d) Concealed image using the boundary matching algorithm (BMA). (e) Concealed image using multiframe spatial error concealment whenp = 3.
available in the middle of the lost slice), it cannot successfully recover the MBs which contain edges across the left and right boundaries. The artifacts can be easily observed at the edges of the table in Fig. 14(d). Multiframe temporal error concealment provides a better recovery, as demonstrated in Figs. 13(e) and 14(e). We clearly observe that the lost MBs at the edges can be recovered without noticeable errors. Figs. 13(f) and 14(f) show magnified portions of images using BMA and multiframe tem-poral error concealment. These sections demonstrate the ability of the multiframe temporal error concealment to exploit the in-terior information of the predicted MB to estimate the motion vector. As a result it has the capability of resolving the ambi-guity caused by slanting edges and rapid gray-level changes on the boundaries [13], [14]. Note that the quality does not change much as further increases, as shown in Figs. 15 and 16. This
shows that two or three more frames are usually sufficient to ac-curately estimate the lost motion vector. Figs. 19 and 20 depict the images for the packet loss rate of 1%.
There are two main issues associated with implementing the multiframe error concealment in a real-time MPEG video streaming system: the delay and the computational complexity. A certain time delay is essential in any MPEG decoder because a buffer is needed to hold the incoming data to handle the delay variation of the packets and provide a constant decoding time. In addition, this buffer is used to change the encoding order into display order. With respect to computational complexity, Park [8] and Alkachouh [17] proposed fast algorithms to reduce the computing complexity of Wang’s method for spatial error concealment. These fast algorithms can also be applied to the multiframe case. For the temporal case, it is difficult
to provide an analytical expression for the computational complexity because it depends on how the error propagates to the succeeding frames. Roughly speaking, the computation complexity of the multiframe temporal error concealment increases linearly as the number of frames, , increases as compared to BMA. For BMA, each candidate in the search range has 16 2 boundary pixels that need to be considered. This is the case when the left and right MBs are not available. Therefore, if the search range is , and neighboring motion vectors are available, the computing complexity requires
multiplications and
additions/sub-tractions. For the multiframe case, if frames are used, the maximum computation complexity is multiplications
and additions/subtractions. This is still
acceptable in a real-time streaming system since the number of frames can be adaptively set according to the computing power of the end users. Moreover, the complexity also depends on the patterns of error propagation in succeeding frames; that is, if the lost MB is referenced by every frame within the same GOP (e.g., on an frame), it requires more computation to get the optimal recovery. On the other hand, if there are no frame references to the lost MB (e.g., on a frame), it reduces to the computation of single-frame error concealment. In short, the proposed approach may have applications in real-time streaming or video-on-demand systems.
V. CONCLUSIONS
This paper proposes a novel multiframe recovery principle that explicitly analyzes the error propagation of the lost MB and directly minimizes the propagation of the errors across mul-tiple frames. MPEG-compatible spatial and temporal error con-cealment approaches using the multiframe recovery principle are also developed to obtain the optimal recovery. The experi-mental results show that by using multiframe error concealment the quality of the corrupted frames can be improved by 1–4 dB in two test video sequences, and the error propagation into suc-ceeding motion-compensated frames can also be reduced. The visual improvements are observed to be more significant than the PSNR improvements.
REFERENCES
[1] Y. Wang and Q.-F. Zhu, “Error control and concealment for video com-munication: A review,” Proc. IEEE, vol. 86, pp. 974–997, May 1998. [2] S. Aign and K. Fazel, “Temporal & spatial error concealment techniques
for hierarchical MPEG-2 video codec,” in Proc. GLOBECOM, 1995, pp. 1078–1083.
[3] Y. Wang, Q. F. Zhu, and L. Shaw, “Maximally smooth image recovery in transform coding,” IEEE Trans. Commun., vol. 41, pp. 1544–1551, Oct. 1993.
[4] Q.-F. Zhu, Y. Wang, and L. Shaw, “Coding and cell loss recovery for DCT-based packet video,” IEEE Trans. Circuits Syst. Video Technol., vol. 3, pp. 248–258, June 1993.
[5] W. Kwok and H. Sun, “Multi-directional interpolation for spatial error concealment,” IEEE Trans. Consumer Electron., vol. 39, pp. 455–460, Aug. 1993.
[6] W. Zhou, Y. Wang, and Q. F. Zhu, “Second-order derivative-based smoothness measure for error concealment in DCT-based codecs,”
IEEE Trans. Circuits Syst. Video Technol., vol. 8, pp. 713–718, Oct.
1998.
[7] S. Hemami and T. Meng, “Transform coded image reconstruction ex-ploiting interblock correlation,” IEEE Trans. Image Processing, vol. 4, pp. 1023–1027, July 1995.
[8] J. Park, J. Kim, and S. Lee, “DCT coefficients recovery-based error con-cealment technique and its application to the MPEG-2 bit stream error,”
IEEE Trans. Circuits Syst. Video Technol., vol. 7, pp. 845–854, Dec.
1997.
[9] H. Sun and W. Kwok, “Concealment of damaged block transform coded images using projections onto convex sets,” IEEE Trans. Image
Pro-cessing, vol. 4, pp. 470–477, Apr. 1995.
[10] X. Lee, Y.-Q. Lee, and A. Leon-Garcia, “Information loss recovery for block-based image coding techniques—A fuzzy logic approach,” IEEE
Trans. Image Processing, vol. 4, pp. 259–273, Mar. 1995.
[11] P. Haskell and D. Messerschmitt, “Resynchronization of motion com-pensated video affected by ATM cell loss,” in Proc. ICASSP, vol. 3, March 1992, pp. 545–548.
[12] W. M. Lam, A. R. Reibman, and B. Liu, “Recovery of lost or erro-neously received motion vectors,” in Proc. ICASSP, vol. 5, Mar. 1993, pp. 417–420.
[13] C. S. Park, J. Ye, and S. U. Lee, “Lost motion vector recovery algorithm,” in Proc. ISCAS, vol. 3, 1994, pp. 229–232.
[14] J. Feng, K. T. Lo, H. Mehrpour, and A. E. Karbowiak, “Cell loss concealment method for MPEG video in ATM networks,” in Proc.
GLOBECOM, vol. 3, 1995, pp. 1925–1929.
[15] J. Zhang, J. F. Arnold, and M. R. Frater, “A cell-loss concealment technique for MPEG-2 coded video,” IEEE Trans. Circuits Syst. Video
Technol., vol. 10, pp. 659–665, June 2000.
[16] S. Tsekeridou and I. Pitas, “MPEG-2 error concealment based on block-matching principles,” IEEE Trans. Circuits Syst. Video Technol., vol. 10, no. 4, pp. 646–658, June 2000.
[17] Z. Alkachouh and M. G. Bellanger, “Fast DCT-based spatial domain interpolation of blocks in images,” IEEE Trans. Image Processing, vol. 9, pp. 729–732, Apr. 2000.
Yen-Chi Lee (S’00) received the B.S. and M.S. degrees in computer science and information engineering from National Chiao Tung University, Hsinchu, Taiwan, R.O.C., in 1997 and 1999, respectively. He is currently pursuing the Ph.D. degree in the School of Electrical and Computer Engineering, Georgia Institute of Technology, Atlanta, where he is also a Research Assistant since 2000.
His current research interests are in the area of error-resilient image/video communications, including post-processing error concealment, joint source and channel coding, and multimedia transport protocol design.
Yucel Altunbasak (S’94–M’97–SM’01) received the B.S. degree from Bilkent University, Ankara, Turkey, in 1992 with highest honors. He received the M.S. and Ph.D. degrees from the University of Rochester, Rochester, NY, in 1993 and 1996, respectively. His Ph.D. research involved object-scalable mesh-based video representation and coding with emphasis on interactive multimedia appli-cations.
He joined Hewlett-Packard Research Laboratories (HPL), Palo Alto, CA, in July 1996. His position at HPL provided him with the opportunity to work on a diverse set of research topics, such as video processing, coding and communi-cations, multimedia streaming and networking, and inverse problems in signal processing. He also taught digital video and signal processing courses at Stan-ford University, StanStan-ford, CA, and San Jose State University, San Jose, CA, as a Consulting Assistant Professor. He joined the School of Electrical and Computer Engineering, Georgia Institute of Technology, Atlanta, in 1999 as an Assistant Professor. His research agenda involves both telecommunications and DSP, par-ticularly bridging these two fields. He is currently working on industrial- and government-sponsored projects related to media communications, networked video, and interactive video. His research interests include video and multi-media signal processing, inverse problems in imaging, and network distribution of compressed multimedia content. His research efforts resulted in 24 journal papers, seven patents, five patent applications, and 45 conference publications. He is an area/associate editor for Signal Processing: Image Communications and for the Journal of Circuits, Systems and Signal Processing.
Dr. Altunbasak is an area/associate editor for the IEEE TRANSACTIONS ON
IMAGEPROCESSING. He is a member of the IEEE Signal Processing Society’s IMDSP Technical Committee. He serves as a co-chair for “Advanced Signal Processing for Communications” Symposia at ICC’03. He also serves as a ses-sion chair in technical conferences, as a panel reviewer for government funding agencies, and as a technical reviewer for various journals and conferences in the field of signal processing and communications. He received the National Sci-ence Foundation (NSF) CAREER Award in 2002.
Russell M. Mersereau (S’69–M’73–SM’78–F’83),received the S.B. and S.M. degrees in 1969 and the Sc.D. in 1973 from the Massachusetts Institute of Tech-nology, Cambridge.
He joined the School of Electrical and Computer Engineering at the Georgia Institute of Technology, Atlanta, in 1975. His current research interests are in the development of algorithms for the enhancement, modeling, and coding of computerized images, synthetic aperture radar, and computer vision. In the past, this research has been directed to problems of distorted signals from partial in-formation of those signals, computer image processing and coding, the effect of image coders on human perception of images, and applications of digital signal processing methods in speech processing, digital communications, and pattern recognition. He is the coauthor of the text Multidimensional Digital Signal
Pro-cessing.
Dr. Mersereau has served on the editorial board of the PROCEEDINGS OF THE IEEE and as Associate Editor for signal processing of the IEEE TRANSACTIONS ONACOUSTICS, SPEECH,ANDSIGNALPROCESSINGand IEEE SIGNALPROCESSINGLETTERS. He is the corecipient of the 1976 Bowder J. Thompson Memorial Prize of the IEEE for the best technical paper by an author under the age of 30, a recipient of the 1977 Research Unit Award of the Southeastern Section of the ASEE, and three teaching awards. He was awarded the 1990 Society Award of the Signal Processing Society. He was the Vice President for Awards and Membership of the Signal Processing Society from 1999 to 2001.