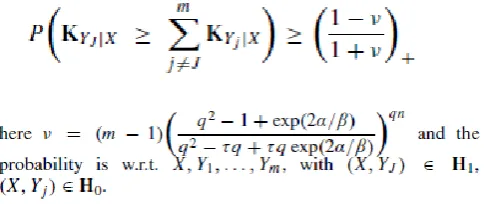ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
Copyright to IJAREEIE 10.15662/ijareeie.2015.0404074 2153
Context-Dependent Logo Matching and
Recognition
K.Avinash
1, M.Venkata Vinod
2M.Tech Student, Dept of Electronics & Communication Engineering, Siddhartha Educational Academy Group of Institutions, Ananthapuramu, Andhra Pradesh, India1
M.Tech Assistant, Dept of Electronics & Communication Engineering, Siddhartha Educational Academy Group of Institutions, Ananthapuramu, Andhra Pradesh, India2
ABSTRACT: We contribute, through this paper, to the outline of a novel variational system ready to match and perceive various occurrences of different reference logos in picture chronicles. Reference logos and test pictures are seen as star groupings of nearby peculiarities (investment focuses, districts, and so forth.) and matched by minimizing a vitality capacity blending: 1) a fidelity term that measures the nature of gimmick matching, 2) an area paradigm that catches characteristic co-event/geometry, and 3) a regularization term that controls the smoothness of the matching arrangement. We likewise present an identification/distinguishment methodology and study its hypothetical consistency. At last, we demonstrate the legitimacy of our technique through broad examinations on the testing MICC-Logos dataset. Our system overwhelms, by 20%, gauge and also cutting edge matching/distinguishment methodology
KEYWORDS: Context-dependent kernel, logo detection, logo recognition.
I. INTRODUCTION AND RELATED WORK
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
logo identity. But the distinctiveness of logos is more often given by a few details carefully studied by graphic designers, semiologists and experts of social communication. The graphic layout is equally important to attract the attention of the customer and convey the message appropriately and perma-nently. Different logos may have similar layout with slightly different spatial disposition of the graphic elements, localized differences in the orientation, size and shape, or – in the case of malicious tampering – differ by the presence/absence of one or few traits [see Fig. 1(b)].
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
Copyright to IJAREEIE 10.15662/ijareeie.2015.0404074 2155
the detection of near-duplicate logos and unauthorized uses [8], [9]. Special applications of social utility have also been reported such as the recognition of groceries in stores for assisting the blind [10].
A nonexclusive framework for logo discovery and distinguishment in pictures taken in genuine situations must follow differentiating prerequisites. From one perspective, invariance to a vast scope of geometric and photometric changes is obliged to follow all the conceivable states of picture/feature recording. Since in true pictures logos are not caught in detachment, logo discovery and distinguishment ought to additionally be strong to fractional impediments. In the meantime, espe-cially on the off chance that we need to find malignant altering or recover logos with so me nearby eccentricities, we should likewise oblige that the little contrasts in the neighborhood structures are caught in the nearby descriptor and are sufficiently recognizing for distinguishmen
A.Related Work
Early take a shot at logo discovery and distinguishment was concerned with giving some programmed backing to the logo enrollment process. The framework must check whether other enlisted logos in documents of millions, exist that have comparative appearance to the newcoming logo picture, keeping in mind the end goal to guarantee that it is sufficiently unique and dodge perplexity [8], [11]–[14]. Kato's framework [15] was among the soonest ones. It mapped a standardized logo picture to a 64 pixel matrix, and ascertained a worldwide gimmick vector from the recurrence conveyances of edge pixels. All the more as of late, Wei et al. [9] proposed a vary ent arrangement, where logos were depicted by worldwide Zernike minutes, neighborhood curve and separation to centroid. Different techniques have utilized distinctive worldwide descriptors of the full logo picture either representing logo shapes or misusing shape descriptors, for example, shape setting [16], [17]. All these systems expect that a logo picture is completely unmistakable in the picture, is not tainted by clamor and is not subjected to changes. As per this, they can't be connected to genuine pictures. In any case, the utilization of worldwide descriptors for logo recognition in genuine pictures has been proposed by a few creators [18]–[20]. Phan et al. [19], [20] considered sets of shading pixels in the edge neighborhoods and collected contrasts between pixels at distinctive spatial separations into a Color-Edge Co-occurence Histogram [18]. This worldwide descriptor licenses to perform quick rough discovery of logos, yet is unsuited to manage inadequate data or changed renditions of the first logo, nor to record for an exact representation of the territory of logo characteri. Investment focuses and neighborhood descriptors were utilized by numerous creators and seem significantly more fitting to help location and distinguishment of realistic logos in true pictures. Actually, neighborhood visual descriptors like MSER [21], SIFT [22], SURF [23], have been turned out to be ready to catch sufficiently discriminative nearby components with some invariant properties to geometric or photometric changes and are hearty to impediments. In their fundamental work, Sivic and Zisser-man [24], [25], misused the sack of visual words way to speak to affine covariant neighborhood districts from a code of SIFT descriptors; visual words were weighted with tf-idf
for large-scale retrieval. They showed good capability to discriminate between objects, and gave also examples of logo matching in unconstrained environments. In their methodology they didn't represent connections between close keypoints yet just defined a spatial nearness paradigm, by checking the neighborhood connection of the 15 closest neighbors of every gimmick match. In [26], logos were portrayed as pack of SIFT gimmicks for logo discovery and distinguishment in groupings of games feature. Taking pack of SIFTs rather than sacks of visual words has the playing point that just a couple of very unique keypoints are hunt down matching and the arrangement of the visual vocabulary is kept away from. They represented spatial connections between nearby peculiarities by performing iterative strong spatial grouping of the matched gimmicks, utilizing M-estimation and anomaly dismissal. In spite of the fact that trials demonstrated that logos can be identified in extremely discriminating conditions and under incomplete impediments with both frameworks, both techniques represent nonexclusive vicinity and are thusly not able to catch the little contrasts in subtle elements or spatial formats, and find close copies.
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
between pictures. In their methodology, matched peculiarities are refined by applying grouping and model verification in view of semi-neighborhood spatial requirements. Mate and Matas [33] considered an exceptional situation where characteristic appearance is disregarded and just spatial relations between sets of gimmicks are utilized. Pantofaru et al. [34] introduction duced a system for article identification and limitation which joins locales produced by picture division with neighborhood patches. Specifically, they defined the Region-bas Gimmick as the histogram of the (quantized) neighborhood gimmicks close a divided locale, where the size of the neighborhood patches is utilizedto define spatial closeness. Also, Mortensen et al. [35] joined SIFT descriptors with a shape descriptor of the point neighborhood (the "Worldwide Context") fundamentally the same to shape setting. These systems don't seem proper to segregate between marginally contrasting characteristics. Bronstein and Bronstein [36] have as of late proposed to straightforwardly join spatial data in the gimmick descriptor. They defined spatially delicate sacks of sets of peculiarities, i.e. the dissemination of close matches of peculiarities. Especially they demonstrated that such sets may have affine invariance if the gimmick change
what's more the sanctioned neighborhoods of the focuses are affine covariant. However in this approach, the representation is just affine covariant and has a high dimensionality. Arrangements for logo discovery in unconstrained genuine pictures, with unequivocal record
of nearby connections were as of late introduced by a couple of creators. Among them, Gao et al. [37] proposed a two-stage calculation that records for neighborhood connections of keypoints. They considered spatial-ghostly saliency to evade the effect of jumbled foundation and accelerate the logo location and limitation. Shockingly, their answer has uncovered to be extremely touchy to impediments. Kleban et al. [38] utilized a more perplexing approach that considers affiliation tenets between regular spatial configuration of quantized SIFT characteristics at numerous resolutions [39]. As reported likewise by the creators, a significant impediment of this methodology is picture determination since numerous neighborhood peculiarities are obliged to mine vigorous spatial configurations. This makes the system extremely feeble if there should arise an occurrence of little or somewhat.
B. Paper Contribution and Organization
In this paper, we exhibit a novel answer for logo discovery also distinguishment which is in view of the definition of a "Setting Subordinate Similarity" (CDS) portion that straightforwardly joins
the spatial connection of neighborhood gimmicks [40], [41]. The proposed strategy is without model, i.e. it is not confined to any from the earlier arrangement model. Connection is considered regarding each single SIFT keypoint and its definition reviews shape connection with some essential contrasts: given a set of SIFT investment focuses X , the connection of x ∈ X is defined as the situated of focuses spatially near to x with specific geometrical limitations. Formally, the CDS capacity is defined as the fixed-purpose of three terms: (i) a vitality capacity which adjusts a fidelity
term; (ii) a connection measure; (iii) an entropy term. The fidelity term is conversely corresponding to the desire of the Euclidean remove between the undoubtedly adjusted investment focuses The connection foundation measures the spatial intelligibility of the arrangements: given a couple of investment focuses ( f p , f q ) individually in the inquiry and target picture with a high arrangement score, the connection foundation is corresponding to the arrangement scores of every last one of sets near to ( f p , f q ) yet with a given spatial configuration. The "entropy" term goes about as a smoothing variable, expecting that with no from the earlier information, the joint likelihood dispersion of arrangement scores is flat. It goes about as a regularizer that controls the entropy of the restrictive likelihood of matching, thus the vulnerability serving to find a direct explanatory arrangement. Utilizing the CDS bit, the geometric design of nearby areas can be thought about crosswise over pictures which demonstrate coterminous and rehashing nearby structures as regularly on account of realistic logos. The arrangement is turned out to be exceedingly viable and reacts to the prerequisites of logo discovery and distinguishment in certifiable pictures. Whatever remains of the paper is sorted out as takes after. In Section II, we report the definition of the "Connection Dependent Similarity" capacity. Henceforth, in Section III, we talk about the adjustment of this comparability capacity to the issue of logo recognition in genuine world pictures, and apply this capacity to adjust investment focuses. We talk about the likelihood of point arrangement in difficult conditions; invariance properties are additionally examined. Results what's more near assessments are exhibited in Section
II.CONTEXT DEPENDENT SIMILARITY
A. Context
The connection is defined by the nearby spatial configuration of investment focuses in both S X and SY . Formally, so as to take into record spatial data, an investment point x i ∈ S X is defined as x i = (ψg (x i ), ψ f (x i ), ψo (x i ), ψs (x i ), ω(x i )) where the image ψg (x i ) ∈ R2 remains for the 2D directions of x i while ψ f (x i ) ∈ Rc compares to the peculiarity of x i (in hone c is equivalent to 128, i.e. the coefficients of the SIFT descriptor [22]). We have additionally an
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
Copyright to IJAREEIE 10.15662/ijareeie.2015.0404074 2157 (indicated ψs (x i )). At long last, we utilize ω(x i ) to recognize the picture from which the investment point originates from, so two investment focuses with the same area, characteristic and introduction are viewed as distinctive when they are not in the same picture; this is inspired by the way that we need to take into record the connection of the investment point in the picture it fits in with. Let d(x i , y j ) = ψ f (x i ) − ψ f (y j ) 2 measure the divergence between two investment point characteristics, where • 2 is the "entrywise" L 2 -standard (i.e. the aggregate of the square values of vector coefficients). The definition of neighborhoods {N θ,ρ (x i )}θ,ρ reflects the co-event of diverse nvestment focuses with specific spatial geometric limitations.
containing the same logo ("Heineken"); the figure reports the connection definition for two relating keypoints, demonstrating a comparable spatial configuration. All the definitions about investment focuses in SY and their context are similar to S X .
B. Similarity Design
We define k as a function which, given two interest points(x, y) ∈ S X × SY , provides a similarity measure between them. For a finite collection of interest points, the sets S X ,SY are finite. Provided that we put some (arbitrary) order on S X , SY , we can view function k as a matrix K, i.e. Kx,y = k(x, y), in which the “(x, y)−element” is the similarity between x and y. We also represent with Pθ,ρ , Qθ,ρ
the intrinsic adjacency matrices that respectively collect theadjacency relationships between the sets of interest points S Xand SY , for each context segment; these matrices are defined as Pθ,ρ,x,x = gθ,ρ (x, x ), Qθ,ρ,y,y = gθ,ρ (y, y ) where gis a decreasing
function of any (pseudo) distance involving(x, x ), not necessarily symmetric. In practice, we considergθ,ρ (x, x ) = 1{ω(x)=ω(x
)} × 1{x ∈N θ,ρ (x)} , so the matrices P,Q become sparse and binary. Finally, let Dx,y = d(x, y) = ψ f (x) − ψ f (y) 2 .
Using this notation, the similarity K between the two objects S X , SY is obtained by solving the following minimization problem
Here α, β ≥ 0 and the operations log (characteristic), ≥ are connected
separately to each passage of the grid (for occasion, log K is the network with (log K)x,y = log k(x, y)), • 1 is the "entrywise" L 1 -standard (i.e., the total of indisputably the estimations of the network coefficients) and Tr indicates framework follow. The first term, in the above compelled minimization problem, measures the nature of matching between two peculiarities ψ f (x), ψ f (y). For our situation this is conversely corresponding to the separation, d(x, y), between the 128 SIFT coefficients of x and y. A high estimation of Dx,y ought to result into a little esteem of Kx,y and the other way around. The second term is a regularization criterion which considers that without any a priori knowledge about the aligned interest points, the probability distribution {Kx,y : x ∈ S X , y ∈ SY } should be flat so the negative of the entropy is minimized. This term also helps defining a direct analytic solution of the constrained minimization problem (1). The third term is a neighborhood criterion which considers that a high value of Kx,y should imply high values in the neighborhoods N θ,ρ (x) and N θ,ρ (y). This criterion also makes it possible to consider the spatial configuration of the neighborhood of each interest point in the matching process. This minimization problem is formulated by adding an equality constraint and bounds which ensure a normalization of the similarity values and allow to see K as a probability distribution.
Let S X = {x 1 , .
. . , x n }, SY = {y1
, . . . , ym } be respectively the list of interest points taken from a reference logo and a
test image (the value of n, m may vary with S
X , SY ). We borrow the definition of context and similarity design from
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
C. Solution
We should consider the nearness networks {Pθ,ρ }θ,ρ , {Qθ,ρ }θ,ρ identified with a reference logo S X and a test picture SY individually,
each of which gathers the nearness connections between the picture investment focuses for a specific connection section θ, ρ. It is conceivable to demonstrate that the improvement issue (1) concedes a
˜unique arrangement K, under some constrains
Proof: This solution is a variant of the one found in [41].The demonstration given in [41] still holds in this case. Notice that at the convergence stage, we omit t in all K(t ) so the latter will simply be denoted as K.
III. LOGO DETECTION AND RECOGNITION
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
Copyright to IJAREEIE 10.15662/ijareeie.2015.0404074 2159
The intuition behind the strong criterion above comes from the fact that when KY J |Xj =J KY j |X , the entropy ofthe conditional probability distribution K.|X will be close to 0, so the uncertainty about the possible matches of X will be reduced. The reference logo S X is declared as present into the test image if, after that the match in SY has been found for each interest point of S X , the number of matches is sufficiently large (at least τ |S X | for a fixed τ ∈ [0, 1], being 1 − τ the occlusion factor tolerated). We summarize the full procedure for logo detection and recognition in Algorithm 1.
A. Theoretical Foundation of Our Matching Algorithm
A hypothetical lower bound to the likelihood of finding right matches utilizing paradigm (7) can be gotten from Eq. 5, under the theory of right matches in S X × SY (i.e. the reference logo exists in the picture). This theory is alluded to as H1 . Additionally H0 (the invalid speculation) remains for the inaccurate matches in S X × SY .
Expecting without a loss of sweeping statement, that all the passages of the left-hand side term of Eq. 5 (i.e, exp(−D/β)) are indistinguishable, for a fixed τ ∈ [0, 1], it shows up obviously that the connection term (the right-hand side term inside the exponential) is exceptionally influential and that the likelihood of finding right matches is reliant on setting of the parameters α/β and q = Na Nr (i.e. the fixed number of cells in the setting) furthermore n (i.e. the quantity of SIFT focuses in the query image).
Fig. 4 contrasts hypothetical desires and measured execution, as a capacity of α/β, q, n and demonstrates that with suitable settings of these parameters, basis (7) has the capacity find (pretty much all) the right matches while disposing of the mistaken ones. Observational matchings are acquired on a approval set including a subset of "matches" and a subset of "non matches." The two sets were consequently created (i) by installing reference logos into test pictures at irregular areas so the ground-truth of "matches" and "non-matches" can be naturally recouped (these reference logos and test pictures have a place with the MICC-Logos dataset), and (ii) by adding a consistently appropriated clamor to the test pictures. Since logos can be part of the way impeded, it has been accepted that the reference logo is still noticeable despite the fact that half-blocked in the test picture, so setting τ = 0.5 in the first three bends reported in the figure.
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
profoundly specific, so it can be utilized viably additionally to identify detect near duplicates.
B. Properties and Considerations
The contiguousness networks Pθ,ρ , Qθ,ρ in K (see Eq. 4 and 5), give the setting and the inherent geometry of the reference furthermore the test logos S X , SY . It is anything but difficult to see that Pθ,ρ , Qθ,ρ are interpretation and revolution invariant and can likewise be made scale invariant when the help (circle) of the connection (i.e. its range p ) is adjusted to the sizes of ψg (S X ) and ψg (SY ) separately. It takes after that the right-hand side of our closeness K is invariant to any 2D closeness change. Notice, likewise, that the left-hand side of K may include closeness invariant gimmicks ψ f (.) (really SIFT characteristics), thusly K furthermore our matching paradigm (7) – is comparability invariant. The connection can likewise be defined on different backings (rectangles, and so on.) and can be made invariant to different changes counting affin and non-linear.
By taking β "not very expansive," one can guarantee that (3) holds.
At that point by taking "sufficiently little" α, imbalance (2) can likewise be satisfied. Note that α = 0 relates to a similitude which is not setting ward (i.e. setting free, after our classification). In this way, for this situation, the likenesses between neighbors are not considered to evaluate the similitude between two investment focuses. Other than our decision of K(0) is precisely the ideal (and fixed point) for α = 0.
One essential part of the technique that has influence on the execution and suits to logo identification/distinguishment is that the nearby setting is recursively defined. Specifically, we survey that two investment focuses match if their nearby neighbors match, what's more if the neighbors of their neighborhood neighbors match as well, and so on. The recursive type of our answer permits us to iteratively diffuse the likeness utilizing bigger and more exact setting so giving expanded exactness of matching (see Fig. 5). An alternate intriguing perspective is that the vitality work in (1) is without model, so no from the earlier arrangement model is utilized as a part of request to plan the closeness and to find the set of matches in S X × SY . This dodges to expect from the earlier speculation that couldn't fit with the per observations.
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
Copyright to IJAREEIE 10.15662/ijareeie.2015.0404074 2161 Then again, when the setting is part into diverse parts, we wind up with a connection term, in the right-hand side of the exponential (5), which becomes gradually contrasted with the one exhibited in our past work [40] and becomes just in the event that comparative spatial configurations of investment focuses have high likeness values. Subsequently, numerically, the assessment of that term is still tractable for substantial estimations of α which obviously produces an all the more decidedly influencing (and exact) setting ward term in (1). Fig. 6 demonstrates a case of our connection ward matching and recognition results (figures on the privilege) concerning connection free ones (figures on the left). Bottom histograms demonstrate the contingent likelihood dissemination K.|X for a specific investment point X in the reference logo. This circulation is crested when utilizing setting depen mark similitude so the hidden entropy is close to 0 furthermore the instability about conceivable matches is significantly lessened. From model (7) and its hypothetical bound (8), few considerations take after. Under the H1 theory, i.e. the speculation that the reference logo exists in the picture, the lower bound in (8) increments as for n, q, while it diminishes with appreciation to m. Notice that commonly nm furthermore that this bound is pointless when q = 1 (i.e., when the setting is isotropic) and when q → ∞ (i.e., when the quantity of cells in the connection is to a great degree substantial prompting overfitting).
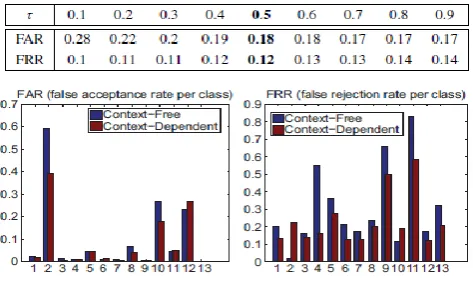
The τ component gives a measure of the part of investment focuses that are viewed as sufficient to survey the vicinity/nonattendance of a reference logo in a test picture. Regularly we can't know from the earlier what is the measure of we may have in test pictures. Setting τ to a little esteem makes the false acknowledgement rate high, while setting it to a high quality makes the false dismissal rate high; in this manner, setting τ to 0.5 is a sort of bargain that works palatably when no learning is accessible. In the event that we need to recognize an allotment of a logo despite the fact that controlled or even it has numerous variations, at that point we ought to have resilience to impediment. As an illustration of this perspective, Fig. 7 shows logo identifications with distinctive qualities of τ . Bound (8) demonstrates that execution does not corrupt lot of when logo structure is diverse, i.e. a few focuses in reference logo don't have matches in test pictures. Connection stays steady and discriminative. In the event that we need to identify just "accurate duplicates" of logos with just some clamor and geometric (likeness) changes, then we ought to set τ near to 1 (Fig. 4 additionally confirms this viewpoint demonstrating that the technique is exceptionally specific without the need of climbing the edge as well much). Under H0 , foundation (7) is exceptionally solid and difficult tofulfill (i.e. its likelihood of achievement is O(1/m) → 0) and this keeps from making incorrectly matches.
IV. BENCHMARKING
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
a gathering of 720 pictures (see Fig. 8).1 The picture determination differs from 480 × 360 to 1024 × 768 pixels. Interest points are extracted from test ages as well as reference logos, and encoded using SIFT features. Each test image SY is processed in order to evaluate the similarity function (shown previously in Eq. 4) with respect to each reference logo S X , using Gaussian power assist setting: K(0) =x,y exp(−d(x, y)/β).
A. Setting
The setting of β is identified with the Gaussian similitude (i.e., exp(−D/β)) as the recent relates to one side hand side (and the pattern structure) of K(t ), i.e. at the point when α = 0. Since the 128 dimensional SIFT gimmicks, used to figure D, have an unit L 2 standard and thus fit in with a hypersphere of span r (r = 1), a sensible setting of β is 0.1r which likewise satisfies condition (3) in our analyses. The influence (and the every formance) of the right-hand side of K(t ), α = 0 (setting term) increments as α increments by and by and as indicated prior, the merging of K(t ) to a fixed point is ensured just if Eq. 2 is satisfied. Naturally, the weight parameter α ought to then be moderately high while likewise fulfilling condition (2). Taking after the lower limits and the experimental measures
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
Copyright to IJAREEIE 10.15662/ijareeie.2015.0404074 2163 B. Logo Detection Performance
Logo location is attained to by finding for every investment point in a given reference logo S X its best match in a test picture SY ; if the quantity of matches is bigger than τ |S X | (for a fixed τ ∈]0, 1]), then the reference logo will be proclaimed as present into the test picture. Diverse estimations of τ were tested furthermore exhibitions are measured utilizing False Acceptance andFalse Rejection Rates (meant as FAR and FRR, respectively)
Table I reports these FAR and FRR results; setting τ to 0.5 certifications a high identification rate at the inconvenience of a little increment of false cautions. Outlines in Fig. 9 show FAR and FRR for the distinctive classes in the MICC-Logos dataset. We obviously see the out-execution of our connection subordinate likeness (i.e., K(t ), t ∈ N+ ) regarding the pattern connection free likeness (i.e., K(0)). For pretty much all the classes, the change brought by CDS is clear and predictable. Figure 11 demonstrates a few cases of logo identification results, acquired utilizing the parameters reported as a part of the past subsection.
C. Comparison and Discussion
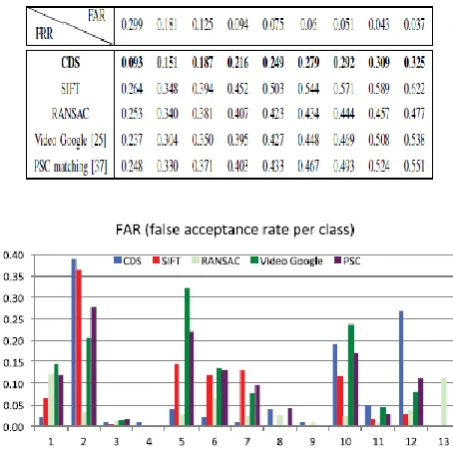
Firstly, we think about our proposed CDS matching and detection methodology against closest neighbor SIFT matching and closest neighbor matching with RANSAC verification.
Filter based logo discovery takes after the thought in [26] where reference logo is recognized, in a test picture, if the in general number of SIFT matches is over a fixed edge. Filter matches are acquired by registering for every investment point in S X its uclidean separation to all investment focuses in SY , furthermore keeping just the closest neighbors. RANSAC based logo location takes after the same thought however it presents a model (change) based paradigm not so much steady in rehearse. This model chooses just the matches that fulfill an affine change between reference logos and test pictures.
The (iterative) RANSAC matching procedure, is connected as a "refinement" of SIFT matching (a comparable methodology is tilized
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
The Video Google approach [25] is nearly identified with our system as it presents a spatial consistency foundation, as per which just the
matches which have comparable spatial formats are chosen. The spatial format (setting) of a given investment point incorporates 15 closest neighbors that are spatially near to it. Given X ∈ S X , Y ∈ SY , focuses in the formats of X and Y which additionally match makes a choice for the final matching score between X and Y . The essential thought is hence like our own, yet the primary distinction dwells in the definition of connection in Video Google which is entirely local.2 In our strategy the setting is additionally eighborhood yet recursive; two investment focuse local neighbors match, and if the neighbors of their local neighbors match too, etc, resulting into a recursive diffusion of the similarity through the context (see Fig. 5).
Incomplete Spatial Context (PSC) logo matching [37] depends on a comparative connection definition. Given a set of matching investment focuses, it defines the spatial circulation for this
set (i) by selecting a round district that contains all these focuses, (ii) by registering the scale and introduction of the set as the normal estimation of, individually, all the scales and introductions of the focuses, (iii) by dividing the dissemination of these focuses in 9 cells. Beginning from this setting definition, PSC histograms are figured for both reference logos andtest pictures. A PSC histogram is defined as the quantity of matches lying in every cell, and logo matching is performed by registering the comparability between two PSC histograms. This composition is efficient and speedy to be figured, however its spatial (connection) definition is harsh and is extremely sensible to exceptions.
Table II and Fig. 10 demonstrate a correlation of the outcomes gotten by the five routines. Table II delineates the FRR execution for fixed FAR qualities and plainly demonstrates that our Discs system creates the most reduced mistake rates contrasted with the different strategies. Fig. 10 demonstrates the FAR and FRR mistakes class- by-class on the MICC-Logos dataset.
D. Experiments on FlickrLogos-27
We report additionally comes about on an alternate open dataset, the
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
Copyright to IJAREEIE 10.15662/ijareeie.2015.0404074 2165 In their paper [42] are accounted for results acquired utilizing a typical pack of-words (bow) model versus their multi-scale Delaunay Triangulation approach (msDT). Both these techniques utilize a codebook of quantized SIFT characteristics. Exhibitions are accounted for as far as exactness by changing the quantity of preparing pictures every class (inside the interim [5, 30]).
We performed examinations on the FlickrLogos-27 dataset utilizing our CDS system and taking after the same trial convention proposed by the creators (please allude to [42] for more subtle elements). Since our system does not give a learning stage, we took after the same system exhibited in the pre vious areas utilizing the "preparation pictures" as reference logos. Thusly, in the event that we have k preparing pictures, we emphasize k times our logo discovery technique (as reported in Algorithm 1) and finally we appoint to every test picture the name comparing to the reference picture that amplifies foundation (7). We report the outcomes in Fig. 12 contrasted with bow and msDT. As exhibited by this figure, our system ensures great execution likewise utilizing a solitary reference logo (i.e. 0.57 in exactness, that is near to the best execution got by
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
E. Computational Cost
The computational cost of our logo detection procedure is mainly dominated by CDS evaluation. In particular, the key part of the lgorithm is the computation of the context term. Assuming K(t −1) known for a given pair of points (x, y), the complexity is
O(max(N 2 , s)); here s is the dimension of ψ f (x) (i.e. 128 since we use SIFT features) and N is given by the maxx,θ,ρ #{
N
θ,ρ(x)}(i.e. the max number of points in all the neighborhoods). When N <√s, evaluating our CDSis equivalent to efficient kernels such as linear or intersection. In worst cases N √s and the evaluation of CDS should be prohibitive. In practice it may only happen when the context is too large (see Fig. 13). Anyway, using the same setting for CDS used in the previous experiments, our method is able to process images and checks for the existence of a reference logo in less than 1 s. This running time is achieved, on average on our MICC-Logos dataset, on a standard 2.6 GHZ PC with2 GB memory.
V. CONCLUSION
The strength of the proposed method resides in several aspects: (i) the inclusion of the information about the spatial configuration in similarity design as well as visual features, (ii) the ability to control the influence of the context and the regularization of the solution via our energy function, (iii) the tolerance to different aspects including partial occlusion, makes it suitable to detect both near-duplicate logos as well as logos with some variability in their appearance, and (iv) the theoretical groundedness of the matching framework which shows that under the hypothesis of existence of a reference logo into a test image, the probability of success of matching and detection is high. Further extensions of this work include the application of the method to logo retrieval in videos and also the refinement of the definition of context in order to handle other rigid and non-rigid logo transformations.
REFERENCES
[1] L. Ballan, M. Bertini, A. Del Bimbo, L. Seidenari, and G. Serra, “Event detection and recognition for semantic annotation of video,” Multimedia Tools Appl., vol. 51, no. 1, pp. 279–302, 2011.
[2] Y. Jing and S. Baluja, “Pagerank for product image search,” in Proc. WWW, Beijing, China, 2008, pp. 307–316.
[3] L. Ballan, M. Bertini, and A. Jain, “A system for automatic detection and recognition of advertising trademarks in sports videos,” in Proc.ACM Multimedia, Vancouver, BC, Canada, 2008, pp. 991–992.
[4] A. Jain and A. Vailaya, “Shape-based retrieval: A case study with
trademark image databases,” Pattern Recognit., vol. 31, no. 9, pp. 1369– 1390, 1998.
[5] J. P. Eakins, J. M. Boardman, and M. E. Graham, “Similarity retrieval of trademark images,” IEEE Multimedia, vol. 5, no. 2, pp. 53–63, Apr.– Jun. 1998.
[6] J. Schietse, J. P. Eakins, and R. C. Veltkamp, “Practice and challenges in trademark image retrieval,” in Proc. ACM Int. Conf. Image Video Retr., Amsterdam, The Netherlands, 2007, pp. 518–524.
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875
I
nternational
J
ournal of
A
dvanced
R
esearch in
E
lectrical,
E
lectronics and
I
nstrumentation
E
ngineering
(An ISO 3297: 2007 Certified Organization)
Vol. 4, Issue 4, April 2015
Copyright to IJAREEIE 10.15662/ijareeie.2015.0404074 2167 22, no. 10, pp. 761–767, 2004.
[8] D. Lowe, “Distinctive image features from scale-invariant keypoints,” Int. J. Comput. Vis., vol. 60, no. 2, pp. 91–110, 2004.
[9] H. Bay, A. Ess, T. Tuytelaars, and L. Van Gool, “Speeded-up robust features (SURF),” Comput. Vis. Image Understand., vol. 110, no. 3, pp. 346–359, 2008.
[10] J. Sivic and A. Zisserman, “Video Google: A text retrieval approach to object matching in videos,” in Proc. Int. Conf. Comput. Vis., vol. 2. Nice, France, 2003, pp. 1470–1477.
[11] J. Sivic and A. Zisserman, “Efficient visual search of videos cast as text retrieval,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 4, pp. 591–606, Apr. 2009.
[12] R. Fergus, P. Perona, and A. Zisserman, “Object class recognition
by unsupervised scale-invariant learning,” in Proc. Conf. Comput. Vis. Pattern Recognit., vol. 2. Madison, WI, 2003, pp. 264–271.
[13] G. Carneiro and A. Jepson, “Flexible spatial models for grouping local image features,” in Proc. Conf. Comput. Vis. Pattern Recognit., vol. 2. Washington, DC, 2004, pp. 747–754.
[14] O. Chum and J. Matas, “Unsupervised discovery of co-occurrence in sparse high dimensional data,” in Proc. Conf. Comput. Vis. Pattern Recognit., San Francisco, CA, 2010, pp. 3416–3423.
[15] C. Pantofaru, G. Dorko, C. Schmid, and M. Hebert, “Combining regions and patches for object class localization,” in Proc. Conf. Comput. Vis. Pattern Recognit. Beyond Patches Workshop, 2006, pp. 1–8.
BIOGRAPHY
K.AVINASH, was received his post-graduation in the specialization of COMMUNICATION SYSTEMS from