Building a Domain-Specific Document Collection for Evaluating Metadata
Effects on Information Retrieval
Walid Magdy, Jinming Min, Johannes Leveling, Gareth J.F. Jones
Centre for Next Generation LocalisationSchool of Computing Dublin City University
Dublin, Ireland
{wmagdy, jmin, jleveling, gjones}@computing.dcu.ie
Abstract
This paper describes the development of a structured document collection containing user-generated text and numerical metadata for exploring the exploitation of metadata in information retrieval (IR). The collection consists of more than 61,000 documents extracted from YouTube video pages on basketball in general and NBA (National Basketball Association) in particular, together with a set of 40 topics and their relevance judgements. In addition, a collection of nearly 250,000 user profiles related to the NBA collection is available. Several baseline IR experiments report the effect of using video-associated metadata on retrieval effectiveness. The results surprisingly show that searching the videos titles only performs significantly better than searching additional metadata text fields of the videos such as the tags or the description.
1.
Introduction
A huge amount of community-generated data is being created on the web. Web blogs, images, videos, and even Wikipedia are examples of this rapidly growing data. The nature of this data is different in type and content from standard web pages. Finding efficient methods for searching this kind of data becomes a growing demand, and using these resources as language resources has found much attention recently. A video websites such as YouTube1 is one of these sources of data. The YouTube website contains millions of videos that are uploaded by users to share it with everybody using the web. Videos on YouTube are associated with a huge amount of metadata about the content of the video, and this metadata is generated by the poster of the video (video title and tags). In addition, some different kind of metadata is generated over time about the popularity of the video itself (e.g. rating and number of views).
In this paper, we present design of an information retrieval (IR) test collection based on a snapshot of a collection of video web pages from YouTube. The collection of video pages was crawled in the period before 03/03/2009. The collection is created for the specific domain of basketball to allow research on domain- specific data. All different types of the data and metadata associated with videos were captured and stored.
Several experiments have been conducted to test the usage of different fields of the associated metadata on the effectiveness of IR. The results surprisingly show that using short fields, such as the title of videos, for indexing the data achieves significantly higher retrieval effectiveness than when using additional text that
1
http://www.youtube.com
describes the content of the video, such as video tags and description.
The data consists of 61,340 XML documents representing the video pages, 40 topics with corresponding manual relevance assessments to enable IR experiments, and 250k user profiles. These user profiles are for every user who has interacted with the videos (posted the video or commented on it), and it carries some information about users such as, age, gender, location, and may be hobbies. The data structure motivates its usage in various research fields, including information retrieval, adaptive hypermedia, information extraction, ontology generation, sentiment analysis, and others.
The rest of this paper is organized as follows: Section 2 introduces some related work for the usage of this kind of data; Section 3 explains the characteristics of the data and describes the methodology used for crawling it; Section 4 describes the creation of the topics and the relevance assessments; Section 5 discusses the experimental setup and reports the baseline results; Section 6 discusses the applicability of the provided data for video retrieval research; finally, Section 7 concludes the paper and provides the link to obtain the data collection.
2.
Related Work
Figure 1: Metadata associated with a YouTube video page
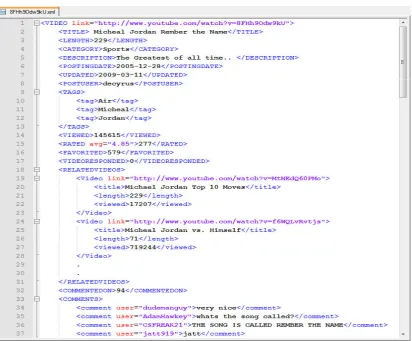
Figure 2: Sample XML document from the YouTube NBA collection
Metadata Min Max Mean Median Std Dev
# tags 0 84 12 10 10
# views 0 21,710,757 35,707 3,329 221,091
# comments 0 23,147 58 6 328
Video length 00:00:00 02:38:20 00:02:53 00:02:10 00:02:54
# ratings 0 27,029 52 8 303
Average rating 0 5 4 5 1
# favorited 0 72,230 94 7 687
# video responses 0 232 0 0 2
Table 1: Some statistics of YouTube NBA video pages collection
Document
Tags
- Video URL
- Video Title
PostingUser
Posting date
Description
Crawling Date
Number of Views Length
Responded Videos
Related Videos
Comments
Number of Ratings Number of
Figure 4: Web tool used for document relevance judgment
0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45
TI TI+TA TI+TA+DE TI+TA+DE+RA
M
A
P with no PRF
with PRF
Figure 5: MAP for experiments using different indexed fields of the NBA video page collection with and without pseudo-relevance feedback (PRF)
78% 80% 82% 84% 86% 88% 90% 92% 94% 96% 98% 100%
` TI+TA TI+TA+DE TI+TA+DE+RA
R
e
c
a
ll with no PRF
with PRF