Privacy Preserving Record Linkage using LSH Blocking Approach and Secure
Multiparty Computation with Set Intersection Technique
Kirti Satpute, Prof. P.B.Mali
Department of Computer Engineering, Smt. Kashibai Navale College of Engineering
SavitribaiPhule, Pune University Pune, 411041, Maharashtra, India
Abstract
the need of creating this paper is to introduce a basic overview of Locality-Delicate Hashing which is base blocking methodology for saving the security of record linkage. For record pairs which sense the anonymous transmission, LSH framework is implemented. For L-fold Redundant Blocking System which is used for separating record sets that sensed an anonymization transmission, the Locality-Sensitive Hashing technique is act as a base. In this scenario we have demonstrate, how the method is useful and evaluation of the efficiency of various types of groups of hash capacities is used for blocking. We also demonstrated that the efficiency gained is linked to the distance preserving attributes of the anonymization group used. The blocking plan test is selected wisely so we complete the most elevated conceivable exactness at all conceivable running time. We also gives a protocol depending on SMC for comparing the formulated record pairs similarly also we prevented a possibility of security break of basic records as well as similarity to search the similar records.
Keywords: Bloom filter, Locality-sensitive hashing, SMC, Set Intersection, blocking.
I. INTRODUCTION
In today’s world high amounts of data is being collected by organizations in the private and public sectors, as well as by individuals. Among them most of the data is about the persons or created by the people such as financial, shopping, and travel transactions, Electronic health and financial records etc. mining this data can provide a huge benefits to businesses and governments. While mining such data which is stored on different sources need to be integrated and linked for improving the data quality, to improve data with additional information, and also to allow data analyses which is not possible on separate databases. But without having any unique entity identifiers means that linking is performed on personal information. When databases are linked within organizations, providing privacy and confidentiality will become more important. This is where privacy-preserving record linkage (PPRL) comes in picture.
Record linkage is one of the old statistical problem raised during the information of some population of individuals, is divided in multiple files. Record linkage has been a playing an important role as a building block for privacy preserving statistical analysis. Record linkage searches matching record pairs in two different data files. The process of linking records which represent the same entity in one or more databases such as patient, customer, business names etc. The challenge with record linkage is that unique entity identifiers are often not presenter if present they are not regular in the databases to be linked.
We have two ways for privacy protection those are, cryptographic and sanitization. Sanitization is used when identifiers in applications are encrypted. Anonymization is
sanitization technique which is commonly used for the privacy preservation.
Technique used for searching the nearest neighbor is called Locality Sensitive Hashing (LSH). We can make use of LSH for the solution of number of domain issues such as near duplication detection, hierarchical clustering, and image similarity detection and so on. It can identify the common records of large dataset.
There are many data-dependent blocking technique present which are very much application specific or depending on placing similar records in the same block, by making use of the techniques of LSH. LSH utilize every part of data present in every single record and will be modified to make sure that blocks are small, and then not allow for further record linkage within blocks.
II. LITERATURE SURVEY
Set Intersection Technique
In paper [2] they give a many-to-many information linkage as well as it is used to perform link in matching entities of different types. The internal node comprises of features from the one data set. The leaves of the tree represent features from other data set which is same as the first data set entities. The given method makes use of maximum-likelihood estimation for pre-pruning process that is used to make One-Class Clustering Tree effectively. In paper [3] authors aimed on the mining of similar patterns in a privacy protection context. They in the uppermost research the difference in sequential as well as item set patterns, also, 2ndthey broaden the definition of patterns by keeping in mind absence as well as presence of commotion in the information. This leads us in perceiving the patterns between of precise and noisy. For accurate pattern, they depict two new mining techniques that they lastly created. The essential system has been associated in a protecting privacy record linkage setting, where their answer is used to mine successive examples which are used in a safe transformation technique to connection records that are comparative. It enhances the mining utility outcomes using a two-stage methodology which grants to effectively mine persistent substrings as well as what's more prefixes patterns. For noisy patterns, first they formally describe the patterns by sort of noise as well as 2ndthey give a set of potential applications which needs the mining of these patterns.
In paper [4] authors proposed encrypted individual semi identifiers, such as, 1st names, surnames, as well as date, place of birth are used. These semi identifiers are not one of a novel individual identifiers themselves, be that as it may, singular qualities, so that their consolidation could be utilized to searching indistinguishable records in different databases. Regardless, semi identifiers of the for the most part contain error; as needs be, linking only the subset of records with exact coordinating identifiers is more frequently than unsuitable. To take into account mistakes in encrypted identifiers, uncommon procedures, for example, encrypted phonetic codes are regularly used. For example, various European disease registries outside of the Scandinavian countries use encrypted Sounded codes as substitutes for cases with non-matching exact identifiers.
This paper [5] proposes one more method for user-centric, global, probabilistic security, engaged throughout today's difficulties of making a various client to take care of with their privacy-sensitive information over a large of social networks, online communities, QA discussions, furthermore, search histories. Their technique needs an adversary which discusses global background knowledge as well as rich statistics to make educated predictions, which are, probabilistic derivations at careful information tool which shows such an effective adversary predicts privacy risks as well as directs the user.
An anonymous linking code [6] to accomplish Cryptographic Long-term Key. It consists of one bloom filter in which identifiers are in this manner stored. Experiments on reproduced databases yield linkage outcome worth of comparison to non-encoded identifiers as well as good than outcomes from present systems these algorithms will yield various different codes while having issues in the basic identifier qualities. In this paper, they
claim that this principle can likewise be made used for a new error-tolerant as well as for irreversible encrypted key. The paper [7] gives technique of statically informed create to bloom filter encodings which has bits from multiple fields. Tradeoff in security as well as accuracy is given utilizing a user-specified proposed technique. New encodings are escapes a cryptanalysis attack which successful against present technique of FBF encodings. This method gives the base for a private record linkage system. Record linkage tries to match instances which compare to the same entity. Record linkage is performed by analyzing of recognizing field values (e.g., Surname), in any condition, when databases are kept up by unique associations, the revelation of such information can break the protection of the relating individuals. Different privy record linkage methods have been introduced to cloud such identifiers; however they change generally in their ability to balance contending objectives of exactness, proficiency as well as security. Their aim is to modify a BF encoding method to moderate this type of attacks with insignificant sacrifices in precision and proficiency.
III. PROPOSED APPROACH
As a contribution we are making use of Cosine similarity for measuring similarities and set intersection technique. System applies anonymization method on DBLP bibliography database used as input. When cosine similarity algorithm finds similarity a bloom filter is used. Afterwards for secure matching records SMC-Secure set intersection is used. By making use of Secure Set Intersection framework in the SMC protocol we improved the data custodians to search the common key.
Techniques used for this system are as fallows:
1. Bloom filtering: A Bloom filter is a data structure used to store the annonymized records to save the time and space.
2. Set Intersection Technique: To improve the security, set intersection technique is used. In this all IDs are divided into shares by using Shamir algorithm. Each ID contains 20 shares.
3. Locality Sensitive Hashing: This is used to determine the similar record pairs on the basis of ID and annonymized data records. It finds the similar records in bloom filter of both users. 4. Homomorphism Operation: On receiving similar
records, users exchanged their records and generate intermediate variable and send to server to get more similar records.
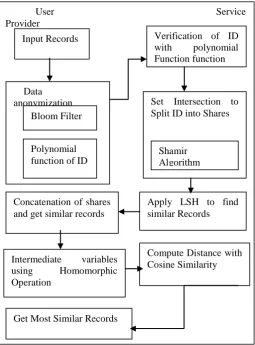
Fig. 1. Proposed System Architecture
3.1 Algorithm
Pseudo code for proposed system:
1. Initialize DB with records
2. Annonymize the records compare two records If (common record)
Then {give an id to common record Store the common record}
3. Generate hash of record ID Calculate (ASCII of ID) Apply (Polynomial function) Get (Hash OF ID)
Concatenate (ID and Hash) 4. Splits ID of records into Shares Apply (Shamir Algorithm) Get (Shares of ID)
5. Search for similar record
Apply (locality sensitive hashing technique) If (success)
{Encode two similar records into bloom filter} 6. Secure matching of record pairs
Get (common block using id) {
Compute (distance matric) }
SMC (distance) {
Generate for annonymize record Encrypt (Key + ID of record)
Divide ID pair into subset (i.e.SA and SB) Encrypt the sets
Apply set-intersection technique Matched pair added to M (set) }
3.2 Mathematical Model
Input: Records I= {i1, i2, i3…, in}
Where, I is the set of input record and i1, i2, i3… in are the number of records.
Process:
Anonymization of Records A= {a1, a2, a3, .., an}
Where, A is the set of anonymization record and a1, a2, a3... an, is the number of annonymize records.
Polynomial Function: Used to calculate Hash of record ID.
Where, x = ASCII value of ID
Efficient searching of similar records S= {J, E, H }
Cosine Coefficient = ………. (1)
Output:
Securing Matching of Records M= {m1, m2, m3, ..,mn}
Where, M is the set of Securing Matching of Record and m1, m2, m3, ..,mn are the number of matching records. User Service
Provider
Verification of ID with polynomial Function function Input Records
Data anonymization
Bloom Filter
Polynomial function of ID
Concatenation of shares and get similar records
Intermediate variables using Homomorphic Operation
Get Most Similar Records
Set Intersection to Split ID into Shares
Shamir Algorithm
Apply LSH to find similar Records
Set Intersection Technique
IV. RESULTS AND DISCUSSION
A. Experimental Setup
The system is built using Java framework on Windows platform. The Net beans are used as a development tool. The system doesn’t require any specific hardware to run. B. Dataset
For this system we used DBLP bibliography database which includes contents authors, title, year of publication etc. as a attributes for dataset, to evaluate the accuracy in finding the truly matched record pairs and the efficiency in reducing the number of candidate pairs.
C. Result
Fig 2 demonstrates the accuracy graph between Jaccard and cosine. The proposed system gives more accuracy than the existing system. Fig 3 demonstrates the time comparison graph between existing and proposed system where Jaccard is time consuming than the cosine.
Fig 2: Accuracy graph
Table 1: Accuracy graph
Jaccard Similarity
Cosine Similarity
A31,B30 0.65 0.87
A31,B31 0.65 0.77
A31,B34 0.65 0.85
A31,B35 0.65 0.67
A31,B32 0.65 0.66
A31,B33 0.65 0.75
A31,B12 0.65 0.72
A20,B13 0.67 0.78
A31,B13 0.65 0.88
Fig 3: Time graph
Table 2: Time Comparison Table Jaccard
Similarity
Cosine Similarity
Time(Sec) 575 438
V. CONCLUSION
In this paper we improve the existing privacy preserving record linkage technique with deploying multiple techniques in it. It is used to find out the similar records in two different dataset with preserving privacy. First we use data anonymization concept for protecting the data and stored it into bloom filter in hash format. Locality Sensitive Hashing is used to find out similar records. The accuracy of these similar records is improved by applying cosine similarity with distance computation. For this, intermediate variables are required which are obtained using Homomorphic operation. The performance of system is tested with Bibliographic dataset, which proves that the performance of system is better in terms of accuracy of matched records.
REFERENCES
[1] Dimitrios Karapiperis and Vassilios S. Verykios,"An LSH-Based Blocking Approach with a Homomorphic Matching Technique for Privacy-Preserving Record Linkage" IEEE transaction on knowledge and data engineering, vol. 27, no. 4, April 2015. [2] Frank Niedermeyer, Simone Steinmetzer, “Implementation of
Many-to-Many Data Linkage using OCCT for Matching and Non-Matching Pairs”, Dept of Information Technology, Regional Centre of Anna University, Coimbatore, India, 2014.
[4] Frank Niedermeyer, Simone Steinmetzer,“Cryptanalysis of Basic Bloom Filters Used for Privacy Preserving Record Linkage”, University of Duisburg-Essen, Germany, 2014.
[5] Joanna Biega, Ida Mele, Gerhard Weikum, Probabilistic “Prediction of Privacy Risks in User Search Histories”, Shanghai, China, 2014. [6] R. Schnell, T. Bachteler, and J. Reiher, “A novel error-tolerantanonymous linking code,” German Record Linkage Center,Working Paper Series No. WP-GRLC-2011-02, 2011. [7] E. Durham, M. Kantarcioglu, Y. Xue, C. Toth, M. Kuzu, and B.