Oyeleye et al. World Journal of Engineering Research and Technology
DEVELOPMENT OF A HYBRID PSO-SVM-BASED OFFLINE
OPTICAL CHARACTER RECOGNITION SYSTEM
Oyeleye Christopher Akinwale*, Alo Oluwaseun Olubisi, Sijuade Adeyemi, Alade Oluwaseun Modupe,Akinpelu James Abiodun, Egbetola Funmilola Ikeolu
Department of Computer Science and Engineering, Ladoke Akintola University of
Technology, Ogbomoso, Nigeria.
Article Received on 21/03/2018 Article Revised on 11/04/2018 Article Accepted on 01/05/2018
ABSTRACT
Optical Character Recognition (OCR) is the mechanical or electronic
translation of images of handwritten, typewritten or printed text into
machine-editable text. However, with support vector machine, it is
difficult to take the proper threshold value and thus end up losing the
necessary pixels. On the other hand, SVM only supports atomic
concepts rather than complex concepts which makes its applications
partially limited. This further makes it difficult to take the scan sample
of the forms which includes lots of boxes. In addition, with large size / dimension of features,
support vector machine often produce Inaccurate classification results Therefore in this paper,
a hybrid of Particle Swarm Optimization (PSO) and Support Vector Machine (SVM) is
developed for optical handwritten character recognition. The PSO was used for feature
extraction and dimensionality reduction of the resultant features while SVM was used for
classification at both training and testing stages. The performance of developed hybrid
PSO-SVM for OCR was evaluated using accuracy and time. The evaluation results when
compared with support vector machine reveal that the developed hybrid PSO-SVM for OCR
outperforms the conventional SVM.
INTRODUCTION
Humans have developed highly sophisticated skills for sensing their environment and taking
actions according to what they observe, for example, recognizing a face, understanding
World Journal of Engineering Research and Technology
WJERT
www.wjert.org
SJIF Impact Factor: 5.218*Corresponding Author Oyeleye Christopher Akinwale,
spoken words, reading handwriting and distinguishing fresh food from its smell via adaptive
pattern recognition capability. Pattern recognition aims to make the process of learning and
detection of patterns explicit, such that it can partially or entirely be implemented on
computers. Automatic (machine) recognition, description, classification (grouping of patterns
into pattern classes) have become important problems in a variety of engineering and
scientific disciplines such as biology, psychology, medicine, marketing, computer vision,
artificial intelligence and remote sensing.
In almost any area of science in which observations are studied but the underlying
mathematical or statistical models are not available, pattern recognition can be used to
support human concept acquisition or decision making (Kumar, Koshti and Govilkar, 2014).
Given a group of objects, there are two ways to build a classification or recognition system:
supervised, that is, with a teacher, or unsupervised, without the help of a teacher. Interest in
pattern recognition has been renewed recently due to emerging applications which are not
only challenging but also computationally more demanding such as data mining, document
classification, organization and retrieval of multimedia databases. However, one of the most
trending pattern classifier is the Support vector machine (SVM). SVM is a computer
algorithm that learns by example to assign labels to objects. For instance, an SVM can learn
to recognize fraudulent credit card activity by examining hundreds or thousands of fraudulent
and non-fraudulent credit card activity reports.
Alternatively, an SVM can learn to recognize handwritten digits by examining a large
collection of scanned images of handwritten zeroes, ones and so forth. SVMs have also been
successfully applied to an increasingly wide variety of biological applications. A common
biomedical application of support vector machines is the automatic classification of
microarray gene expression profiles. However, SVM suffers from high misclassification rate
when the dimension of the features is very large (Fagbola, Olabiyisi and Adigun, 2012). To
this end, modified and improved versions of SVM are sought-after requirements for accurate
recognition of optical handwritten characters.
Optical character recognition (OCR) is often used to convert different types of documents,
such as scanned paper documents, PDF files or images captured by a digital camera into
editable and searchable data. Basically, there are three types of OCR. These include the
offline handwritten text, online handwritten text and the machine printed text (Kumar, Koshti
a. Offline Handwritten Text: The text produced by a person by writing with a pen/ pencil on a paper medium and which is then scanned into digital format using scanner is called
Offline Handwritten Text.
b. Online Handwritten Text: Online handwritten text is the one written directly on a digitizing tablet using stylus. The output is a sequence of x-y coordinates that express pen
position as well as other information such as pressure (exerted by the writer) and speed of
writing.
c. Machine Printed Text: Machine printed text can be found commonly in daily use. It is produced by offset processes, such as laser, inkjet and many more.
In a related manner, Particle Swarm Optimization (PSO) has been a fundamental
metaheuristic approach for optimizing the performance of most conventional algorithms.
PSO is a global optimization method invented by Eberhart and Shi in 2001 based on social
conduct of birds (Clerc, 2002). PSO incorporates swarming conduct identified in schools of
fish, swarms of bees, flocks of birds from which the idea is emerged (Eberhart, 2001). In this
paper, a hybrid PSO-SVM classification technique is developed for the optical handwritten
character recognition system.
2.0 Related Works
Optical character recognition allows for automatically recognizing characters through an
optical mechanism. It is capable of recognizing both handwritten and printed text. However,
anymber of works recently developed are discussed. Bansal and Sharma (2010) developed an
isolated handwritten words segmentation technique in Gurmukhi Script. The work elaborates
the segmentation of various irregular text words written in Gurumukhi script as well as words
containing skewed, broken, irregular headline, touching and overlapped characters. Some of
the new techniques like counter tracing methods are used along with horizontal and vertical
projections. In the same vein, Garg, Kaur and Jindal (2011) worked on the segmentation of
half characters in Handwritten Hindi.
Text Character recognition is an important stage of any text recognition system. In Optical
Character Recognition (OCR) system, the presence of half characters decreases the
recognition rate. Due to touching of half character with full characters, the determination of
presence of half character is very challenging task. The work leveraged on the structural
results obtained, the developed algorithm achieves an accuracy of 83.02% for half characters
in handwritten text and 87.5% for printed text.
Kumar, Koshti and Govilkar (2014) developed a segmentation technique for handwritten
Gurumukhi characters defining the whole process for segmentation including digitization
process and pre-processed techniques. Water Reservoir method was applied for identification
and segmentation of touching characters. Kumar and Singh (2011) also developed an
algorithm to detect and segment Gurmukhi Handwritten text into lines, words and characters.
To get the character, the coordinates of detected lines and words are used. Their character
segmentation process was divided in two part: (i) to get the segmented region R (ii) to check,
if R has a meaningful symbol or not. This can be a reverse approach to ensure correct
segmentation, that is, if R does not have a meaningful symbol then R is readjusted. It was
tested on different documents and the results obtained are remarkable. More importantly, it
was able to interpret the lines which were having some characters in the lower zone almost
correctly.
Kumar, Jindal and Sharma (2010) developed a variable sized window technique for the
segmentation of scanned document image which is treated as one large window. The large
window was splitted into smaller windows as lines and once the lines are recognized then
each window consisting of a line is used to recognize a word that is present in a line, and at
the end, character is recognized. Patil, Rajharsh and Rohini (2015) developed an offline
handwritten alphabetical character recognition system using multilayer feed forward neural
network. Others include but not limited to OCR using hierarchical optimization (Kirill, Igor
and Heinz, 2007), hand written English character recognition using column-wise
segmentation of image matrix (Rakesh and Manna, 2012), Devnagari script character
recognition using genetic algorithm (Vedgupt and Rao, 2013), scene text recognition in
mobile applications by character descriptor and structure configuration (Chucai and Yingli,
2014), an enhanced artificial neural network-based offline signature verification and
recognition system (Shilpa and Anagha, 2013) and an offline signature verification and
recognition based on four speed stroke angle (Sudhakar, 2009).
3.0 MATERIALS AND METHOD
In this paper, the basic steps used in developing the PSO-SVM-based Optical Character
Recognition system include the image acquisition, preprocessing, feature extraction, training
3.1 Support Vector Machine (SVM)
Support Vector Machines (SVMs) are learning systems that utilize a hypothesis space of
separating functions in a high dimensional feature space. The algorithm is depicted as follows
(Fagbola, Olabiyisi and Adigun, 2012):
Input: sample x to classify, Training set
, ,…, }
Output: decision [-1,1]
Compute SVM solution w, b for data set with inputed labels Compute outputs = for all in positive bags
Set = sign ( ) for every
For (every positive bag Bi) If
Compute
Set =1
End
While (inputed labels have changed) Output (w, b)
Put values w, b in and get the result
3.2 Particle Swarm Optimization (PSO)
PSO uses swarm to perform searches in a given population. The population comprises
particles, which represent a metaphor of birds in flocks. These particles were amended
through iteration process (Adigun, Fagbola and Adegun, 2014). In PSO, a set of particles or
solutions traverse the chase space with energy based on their experience and that of their
neighbours in the community. This progression is subjected to repeated iteration until a
perfect solution is obtained. The basic operation of the PSO is detailed beneath (Adigun,
Fagbola and Adegun, 2014; Karl, 2005; Lin et al., 2008).
Step 1: Initialization. The speed rate and location of all features are set to within specified ranges.
(1)
where and represent the location and rate of speed of feature i, separately; and
translates to the position with the „best‟ objective value by particle i and the entire
populace separately; is the factor controlling the flying dynamics; R1 and R2 mean random
variables within the boundary [0, 1]; and translates to parameters controlling the
weighting of related terms. The inclusion of random variables enhances the PSO with the
power of stochastic hunting. The weighting factors, and , compromise inevitable tradeoff
between discovery and utilisation After updating, is checked to avoid excess random
movement within the specified range.
Step 3: Position Updating. Consider a unit time interval between successive rehearsal, the locations of all features are renewed according to:
(2)
After updating, is checked to ensure precision.
Step 4: Memory updating. Update and when requirement is met. If f ( ) > f ( )
If f ( ) > f ( ) (3)
Where f (x) represent the objective function.
Step 5: Termination-Checking. The algorithmic process iterates Steps 2 to 4 until certain demands are met. After termination, the values of and f ( ) are reported as its
optimum solution.
3.3 Design of the Proposed SVM-PSO Technique for Offline Optical Character Recognition
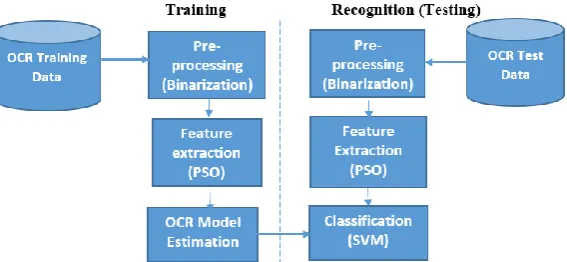
The design of the proposed SVM-PSO technique for offline optical character recognition is
presented in Figure 1. This consists of the data acquisition phase for training and testing the
PSO-SVM based OCR, pre-processing via binarization, feature extraction using PSO and
Figure 1: The Block Diagram of the Proposed SVM-PSO technique for Offline Optical Character Recognition.
3.4 Implementation of the Proposed SVM-PSO for Offline Optical Character Recognition
Microsoft.Net framework and C# programming language were used for the implementation
of the PSO-SVM-based OCR developed in this paper due to their platform-independent and
scalability characteristics.
3.4.1 Preprocessing
This is done to boost the probabilities of undefeated recognition. Through binarization,
segmentation of fixed-pitch fonts is accomplished comparatively just by orientating the
image to an identical grid supported wherever vertical grid lines can least typically ran into
black areas.
3.4.2 Feature Extraction
Feature extraction is performed after preprocessing step is completed successfully. The PSO
algorithm is designed for obtaining character as solutions in order to reduce the high number
of characters to be later classified. Particle swarm optimization was used for feature
extraction. The features extracted include (1) Height of the character; (2) Width of the
character; (3) Numbers of horizontal lines present—short and long; (4) Numbers of vertical
lines present—short and long; (5) Numbers of circles present (6) Numbers of horizontally
oriented arcs; (7) Numbers of vertically oriented arcs; (8) Centroid of the image; (9) Position
of the various features; (10) Pixels in the various regions.
3.4.3 Training and Recognition
Support Vector Machines, a technique derived from statistical learning theory, is used to
mainly a (binary) 2-class classification. For linearly separable data, SVM obtains the hyper
plane which maximizes the margin (distance) between the training samples and the class
boundary. For non-linearly separable cases, samples are mapped to a high dimensional space
where such a separating hyper plane can be found. The assignment is carried out by means of
a mechanism called the kernel function. The SVM classifier is used whenever the fitness
evaluation of a tentative character subset is required. However, the system is trained using the
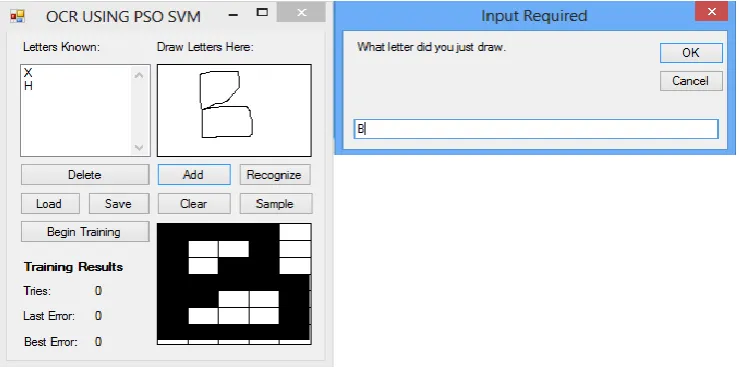
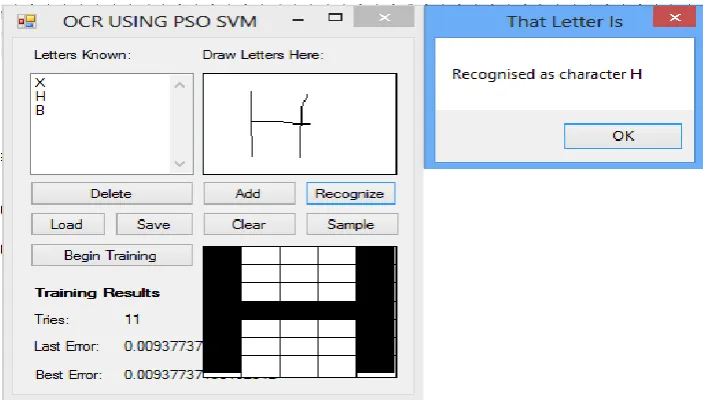
foreground and background color of the character. Figures (2 and 3) present sample training
process of the PSO-SVM based OCR with some characters while Figures (4 and 5) present
sample recognition (testing) process of the PSO-SVM-based OCR.
Figure 2: Training PSO-SVM-based OCR to Recognize Character X.
Figure 4: Recognized Character H.
Figure 5: Recognizing Character B.
3.5 Performance Evaluation Metrics
The performance evaluation metrics considered in this paper are recognition accuracy and
recognition time.
i. Recognition Accuracy: This is the percentage of all characters that are correctly recognition over the total characters identified.
ii. Recognition Time
This is total finite time in seconds for the OCR system to recognize the character and display
4.0 Experimental Results and Discussion
The summary of the experimental results obtained for the developed PSO-SVM-based optical
character recognition system is presented in Table 1.
Table 1: Summary of Experimental results obtained.
Algorithms Recognition Accuracy (%) Recognition Time (s)
Support Vector Machine 87 457
Hybrid PSO-SVM 93 202
SVM produced an accuracy of 87% at a recognition time of 457s while the hybrid PSO-SVM
produced a recognition accuracy of 93% at a recognition time of 202s. This indicates that the
performance of conventional classifier can be improved by combining them with
metaheuristic optimizers.
5.0 Conclusion and Future Work
In this paper, a hybrid PSO-SVM algorithm for recognizing optical character was developed.
Reaching an accuracy rate of 93% during testing with sets corresponding to small and capital
letters, SVM-PSO based OCR performs more accurately and efficiently than SVM that
achieved 87% accuracy at the expense of computational efficiency. Hence, enhancing the
conventional recognition systems with metaheuristic optimizers is a key to extending their
performance capability and efficiency. However, future works can consider the development
of OCR based on modified metaheuristic algorithms and/or hybridization of same for
improved OCR performance. Automatic determination of the optimal parameters of the
kernel functions of the hybrid PSO-SVM can also be investigated.
REFERENCES
1. Abimbola Adebisi Adigun, Temitayo Matthew Fagbola and Adekanmi Adegun
Swarmdroid: Swarm Optimized Intrusion Detection System for the Android Mobile
Enterprise. International Journal of Computer Science Issues, Mauritius (IJCSI),
Mauritius, 2014; 11(3): 62-69.
2. Bansal G., Sharma D., “Isolated Handwritten Words Segmentation Techniques in Gurmukhi Script”, International Journal of Computer Applications, 2010; 1(24): 104-111.
3. Chucai Yi and Yingli Tian Scene Text Recognition in Mobile Applications by Character
Descriptor and Structure Configuration, Transaction on image processing, 2014; 23(7).
5. Eto, Y., and Suzuki, M. Mathematical formula recognition using virtual link network. In
Sixth International Conference on Document Analysis and Recognition (ICDAR), IEEE
Computer Society Press, 2001; 430-437.
6. Fagbola Temitayo, Olabiyisi Stephen and Adigun Abimbola “Hybrid GA-SVM for
Efficient Feature Selection in E-Mail Classification”. Journal of Computer Engineering
and Intelligent Systems, International Institute of Science, Technology and Education
(IISTE), New York, USA, 2012; 3(3): 17-28.
7. Garg N.K., Kaur L., Jindal M.K. “The segmentation of half characters in Handwritten Hindi Text”, Springer Verlag Berlin Heidelberg, 2011; 48-53.
8. Hsu, C.-W., and Lin, C.-J. A comparison of methods for multi-class support vector
machines. IEEE Transactions on Neural Networks, 2002; 13: 415-425.
9. Hsu, C.-W., Chang, C.-C., and Lin, C.-J. A practical guide to support vector classification. http://www.csie.ntu.edu.tw/%7Ecjlin/papers/guide/guide.pdf, 2003.
10. Keerthi, S. S., and Lin C.-J. Asymptotic behaviors of support vector machines with
Gaussian kernel. Neural Comput, 2003; 15(7).
11. Kirill Safronov, Igor Tchouchenkov and Heinz Wörn Optical Character Recognition
Using Optimisation Algorithms, Workshop on Computer Science and Information
Technologies CSIT‟, Ufa, Russia, 2007; 1-8.
12. Kumar D., Koshti, Govilkar S. “Segmentation of Touching Characters in Handwritten Devanagri Script”, International Journal of Computer Science and its Applications, 2014;
2(2): 83-87.
13. Kumar M., Jindal M.K., Sharma R.K. “Segmentation of Isolated and Touching Characters in Offline Handwritten Gurmukhi Script Recognition”, International Journal Information
Technology and Computer Science, 2010; 58- 63.
14. Kumar R., Singh A. “Algorithm to Detect and Segment Gurmukhi Handwritten Text into Lines, Words and Characters”, IACSIT International Journal of Engineering and
Technology, 2011; 3(4).
15. Patil V.V., Rajharsh Vishnu Sanap and Rohini Babanrao Kharate Optical Character
Recognition Using Artificial Neural Network, International Journal of Engineering
Research and General Science, 2015; 3(1): 73-76.
16. Rakesh Kumar Mandal and N R Manna” Hand Written English Character Recognition
using Column-wise Segmentation of Image Matrix (CSIM)” WSEAS Transactions on
17. Shilpa Adke and Anagha. P. Khekar An Enhanced Artificial Neural Network Based
Offline Signature Verification and Recognition System, International Journal of
Engineering Research & Technology (IJERT), 2013; 2(12): 175-178.
18. Sudhakar R.D “Offline signature verification and recognition: An approach Based on
Four Speed Stroke Angle” International Journal of Recent Trends in Engineering, 2009;
2(3).
19. Suzuki, M., Tamari, F., Fukuda, R., Uchida, S., and Kanahori, T. Infty an integrated OCR
system for mathematical documents. In Doc Eng '03: Proceedings of the ACM
symposium on Document engineering, ACM Press, 2003.
20. Suzuki, M., Uchida, S., and Nomura, A. A ground-truthed mathematical character and
symbol image database. In ICDAR '05: Proceedings of the Eighth International
Conference on Document Analysis and Recognition, Washington, DC, USA, IEEE
Computer Society, 2005.
21. Vedgupt Saraf and D.S. Rao Devnagari script character recognition using genetic
algorithm for get better efficiency; International Journal of Soft Computing and