Vol. 5, Issue 7, July 2016
Study of Anonymization of Tree Structured
Personal Records through Structural Links
Penmatsa Sai Lakshmi, Dr.I.Hemalatha
PG Scholar, Dept. of IT, Sagi Rama Krishnam Raju Engineering College, Bhimavaram, India
Associate Professor, Dept. of IT, Sagi Rama Krishnam Raju Engineering College, Bhimavaram, India
ABSTRACT: Today many companies and organizations have been collecting personal information in a very detailed level. Therefore the data management community is facing a big challenge to protect personal information of individuals from attackers who try to disclose the information. So data anonymization strategies have been proposed so as to permit handling of individual information without compromising user’s privacy. Data anonymization is a type of information sanitization whose intent is privacy protection. It is the process of either encrypting or removing personally identifiable information from data sets, so that the people whom the data describe remain anonymous. In this paper, we concentrate on the anonymization of tree organized individual records where qualities are connected through auxiliary connections. The paper characterizes k(m,n)-secrecy, which gives security against personality revelation and proposes an algorithm which satisfies k(m,n)-secrecy and is able to sanitize datasets.
KEYWORDS: Privacy, Tree data, Anonymity, Structuralknowledge,Generalization, Disassociation.
I. INTRODUCTION
Vol. 5, Issue 7, July 2016
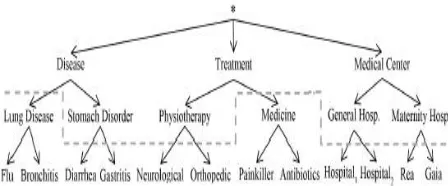
met when all the more effective sureties are connected, b) there is regularly failure to portray qualities as delicate or no sensitive and c) the security insurance law in many nations for the most part spotlights on character. The paper proposes k(m,n)- obscurity, which ensures that an aggressor who knows up to m components of a record and to n basic relations between the m components won't have the capacity to match her experience information to not as much as k coordinating records in the anonymized information. The anonymization methodology does not just sum up qualities that partake in uncommon thing blends additionally rearranges the structure of the records. The improvement is performed by expelling hubs from long ways and making new littler ways. We can guarantee that both records will be undefined to an aggressor who realizes that a patient was dealt with for "Gastritis" in "Hospital1", by setting "Gastritis" as a kin to the doctor's facility. By analyzing these records, an aggressor can gather that both these patients were dealt with for "Gastritis" and that they have both been to "Hospital1" and "Hospital2". The data that one patient was dealt with for gastritis in the specific clinic is concealed, so the assailant can no more recognize the two records in light of her experience learning. We propose an anonymization calculation in this course. Our AllCutSearch (ACS) calculation investigates in a top-down manner the cross section of every single conceivable blend of worth speculations, and for each diverse speculation it investigates the conceivable auxiliary changes, and finds an answer that fulfills k(m,n)- secrecy.
Fig.1. Records of a medical tree database TD.
II. EXISTING SYSTEM
The issue of anonymizing tree organized information has just been tended to in existing examination writing, with regards to multirelational k-anonymity. In our methodology we consider a more broad case for tree organized information and we propose an anonymization technique that does not depend exclusively on the speculation of qualities, but rather additionally on the rearrangements of the information tree. The data concerning a solitary individual for the most part traverses more than a few tables or it is kept in a more adaptable representation as a XML record.
III. PROPOSED SYSTEM
Vol. 5, Issue 7, July 2016
IV. PRIVACY GUARANTEE
We propose a security ensure that secures the personality of the people who are connected with tree records from aggressors by augmenting the km-anonymity guarantee [6] to address auxiliary information. Km-namelessness ensures that any assailant, who knows up to m components of a record, won't have the capacity to distinguish not as much as k records in the distributed information. We characterize k(m,n)- obscurity as:
Definition 1: (k(m,n)- obscurity ensure) A tree database D is considered k(m,n)- unknown if any assailant who has foundation information of m hub names and n auxiliary relations between them (ancestor descendant), is not ready to utilize this learning to distinguish not as much as k records in D.
V. SYSTEM ARCHITECTURE
VI. ANONYMIZATION OPERATIONS
A tree dataset D can be transformed to a dataset D0 which complies to k(m,n)- anonymity, by a series of transformations.The key idea is to replace rare values with a common generalized value and to remove ancestor-descendant relations when they might lead to privacy breaches.
6.1 Generalization:
Vol. 5, Issue 7, July 2016
typical summed one up, e.g., in Fig.2. "Flu" and "Bronchitis" have been summed up to "Lung Disease". To agree to the information model, we blend the two appearances of "Lung Disease" and their subtrees, i.e., all ways under "Flu" and "Bronchitis" show up now under "Lung Disease".
Fig. 2. A cut on the generalization hierarchy.
6.2 Basic Disassociation:
Value generalization cannot address the structural background knowledge of the attacker to provide k(m,n)- secrecy. For the latter, we need to hide the ancestor descendant relationships that are rare enough to be identifying. We call this operation structural disassociation SD and we term it in this paper as Basic Disassociation. Let S be a path r → ∙ ∙ ∙ sa →
a →∙ ∙ ∙ → sb → b → sb → ∙ ∙ ∙ → l. If we disassociate the relation a → b, then this operation will take place in all the
records of D i.e., global recoding approach [7] so that the anonymized data does not have any occurrence of a → b.
VII. ANONYMIZATION ALGORITHM
The issue we need to unravel is the accompanying: Given a dataset D, the parameters of k(m,n)- secrecy and a speculation chain of command H, we need to change by speculation and basic disassociation the dataset D to a dataset D0 for which k(m,n)- namelessness holds and the data misfortune is least. The answer for this issue is a couple (C; SD) of a speculation cut C and an arrangement of basic disassociation rules SD. By applying (C; SD) to D we get a k(m,n)- mysterious dataset D0. Because of the high trouble of the issue (we demonstrate that it is NPHard), we propose a heuristic calculation that finds a "decent" (nearby ideal) however not ideal arrangement. To catch the data misfortune, we utilize an estimation capacity in view of RPD, the RPDa, which we characterize later in the segment. For every speculation cut we have numerous diverse basic disassociations. The complete arrangement space includes every one of the mixes of speculation cuts and basic disassociation changes. Finding the ideal arrangement is NP-Hard. This takes after from the way that the issue of finding the ideal k-anonymization of a social table, which is known not NP-Hard [8], can be decreased to a particular instance of the k(m,n)- anonymization of tree records. Expect that a social table R is spoken to as a gathering D of tree organized records that all have the same structure: a root hub and all the fields of the table as immediate offspring of the root. Finding the ideal k(m,n)- anonymization for D, for m; n equivalent to R's arity takes care of likewise the issue of finding the ideal k-obscurity for R. Since the last is a NP-Hard issue, then so is the distinguishing proof of the ideal k(m,n)- anonymization. In view of the issue many-sided quality we abstain from performing a thorough inquiry of the arrangement space, rather we give a heuristic that investigates promising subspaces. We propose a top-down calculation which at first considers all qualities to be summed up to "*". The calculation navigates the speculation progressive system start to finish by practicing one hub at every iterative stride. Every specialization makes another pecking order cut. In the event that the cut does not ensure k(m,n)- obscurity for the distributed dataset, then we investigate the conceivable auxiliary disassociations for this cut. Checking whether a blend of a speculation cut and basic disassociation principles can give k(m,n)- secrecy if connected to D is not an insignificant errand. To perform the check proficiently we utilize a memory structure termed outline tree, which we display in the accompanying area.
Input: D, DGHierarchy, k, n, m
Vol. 5, Issue 7, July 2016
1: Create synopsis tree S from D
2: Create inverted list L // L is created for generalized terms too 3: stack STK = ϕ
4: bestCost = ∞; //Minimum Loss
5: root = ⃰
6: mark root as closed 7: STK.push(root)
8: while STK not empty do
9: cCut=STK.pop() //current cut cCut 10: for all children C of cCut do 11: if C not closed then
12: mark C as closed 13: STK.push(C)
14: if ValueCheck(cCut, S, L) then 15: Create ScCut //we project S to cCut 16: cSD = FixStructure(ScCut, L, cCut)
17: cCost = cost(cCut, cSD) //estimated cost of current solution 18: if cCost < bestCost then
19: bestCost = cCost 20: (C, SD) = (cCUT, cSD) 21: return (C, SD);
Algorithm.1. AllCutSearch(ACS) Algorithm
VIII. CONCLUSION
In this paper, we are tending to the issue of anonymizing tree organized information within the sight of basic learning. We propose k(m;n)-secrecy protection ensure which addresses foundation information of both esteem and structure. We present an anonymization algorithm which can make k(m;n)-mysterious datasets, by utilizing esteem speculation and a novel information change, which we term basic disassociation.
IX. FUTURE WORK
The AllCutSearch (ACS) algorithm avoids exploring the whole solution space, but can still be quite expensive if the data domain or the dataset is large. To deal with bigger and more expressive datasets, we plan to work with the Greedy Cut Search Algorithm GCS, which we assume would follow the most promising paths and can significantly reduce the search space and computational time.
REFERENCES
[1] Australian Privacy Act. www.austlii.edu.au/au/legis/cth/consol act/pa1988108. [2] Canadian Privacy Act. laws-lois.justice.gc.ca/eng/acts/P-21/.
[3] Data Protection Act 1998, UK. www.legislation.gov.uk/ukpga/1998/29/contents. [4] GR Law. www.dpa.gr/portal/page? pageid=33,43560& dad=portal.
[5] M. Nergiz, C. Clifton, and A. Nergiz. Multirelational k-anonymity. IEEE TKDE, pages 104–1117, 2009.
[6] M. Terrovitis, N. Mamoulis, and P. Kalnis. Privacy- preserving Anonymization of Set-valued Data. PVLDB, 1(1), 2008.
[7] M. Terrovitis, N. Mamoulis, and P. Kalnis. Local and global recoding methods for anonymizing set-valued data. The VLDB Journal, 2010. [8] A. Meyerson and R. Williams. On the Complexity of Optimal Kanonymity. In PODS, pages 223–228, 2004.
[9] O. Gkountouna and M. Terrovitis. Anonymizing Collections of Tree-Structured Data. In IEEE, 2015.
[10] R. J. Bayardo and R. Agrawal. Data Privacy through Optimal k-Anonymization. In ICDE, pages 217–228,2005. [11] TPC-H Homepage. http://www.tpc.org/tpch/.
[12] G. Aggarwal, T. Feder, K. Kenthapadi, S. Khuller, R. Panigrahy,D. Thomas, and A. Zhu. Achieving Anonymity via Clustering. InPODS, 2006. [13] G. Aggarwal, T. Feder, K. Kenthapadi, R. Motwani, R. Panigrahy,D. Thomas, and A. Zhu. Approximation Algorithms for k-Anonymity. Journal of Privacy Technology, 2005.
Vol. 5, Issue 7, July 2016
[15] Y. Tao, X. Xiao, J. Li, and D. Zhang. On anti-corruption privacy preserving publication. In ICDE, 2008.
[16] M. Terrovitis, J. Liagouris, N. Mamoulis, and S. Skiadopoulos. Privacy preservation by disassociation. PVLDB, 5(10), 2012.
[17] P. Samarati and L. Sweeney. Generalizing Data to Provide Anonymity when Disclosing Information (abstract). In PODS (see also Technical Report SRI-CSL-98-04), 1998.
[18] X. Xiao and Y. Tao. Anatomy: simple and effective privacy preservation. In VLDB, pages 139–150, 2006.
[19] J. Xu, W. Wang, J. Pei, X. Wang, B. Shi, and A. Fu. Utility-Based Anonymization Using Local Recoding. In KDD, 2006. [20] Y. Xu, K. Wang, A. W.-C. Fu, and P. S. Yu. Anonymizing transaction databases for publication. In KDD, pages 767–775, 2008. [21] TPC-H Homepage. http://www.tpc.org/tpch/.
BIOGRAPHY
Penmatsa Sai Lakshmi is currently pursuing her M.Tech(IT) in Information Technology Department, Sagi Rama Krishnam Raju Engineering College, West Godavari, A.P. She received her B.Tech in Computer Science and Engineering Department from Sagi Rama Krishnam Raju Engineering College, Bhimavaram.