c e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 12, December 2015
International Journal of Research (IJR)
Available at http://internationaljournalofresearch.orgProvocation in Big Data using Data Mining Techniques
1
N.Naveen chand &
2U.Usha Rani
1
M.Tech (CSE), Priyadarshini Institute of Technology & Science 2
Associate Professor ( Dept.of CSE), Priyadarshini Institute of Technology & Science Abstract:
Big data is an enormous accumulation of unstructured data where it can gather data from different sources like online networking, topographical sources, chronicled sources etc.In the request to extricate the helpful data among unstructured stockpiling database, we utilize data mining methods which coordinate Big data properties. We utilize enormous data Properties like HACE and Hadoop Procedures which utilizes parallel handling (Map Decrease Programming) to perform the data extraction errand in time which leads tedious process and produce extricate data in less time.
Keywords: MapReduce; Data Mining; Hadoop;
HACE; Unstructured Data; Structured Data
1. INTRODUCTION
In a broad range of application areas, data is being collected at unprecedented scale. Decisions that previously were based on guesswork, or on painstakingly constructed models of reality, can now be made based on the data itself. Such Big Data analysis now drives nearly every aspect of our modern society, including mobile services, retail, manufacturing, financial services, life sciences, and physical sciences. Scientific research has been revolutionized by Big Data .The Sloan Digital Sky Survey has today become a central resource for astronomers the world over. The field of Astronomy is being transformed from one where taking pictures of the sky was a large part of an astronomer’s job to one where the pictures are all in a database already and the astronomer’s task is to find interesting objects and phenomena in the database. In the biological sciences, there is now a well-established tradition of depositing scientific data into a public repository, and also of creating public databases for use by other scientists. In
fact, there is an entire discipline of bioinformatics that is largely devoted to the curation and analysis of such data. As technology advances, particularly with the advent of Next Generation Sequencing, the size and number of experimental data sets available is increasing exponentially. Big Data has the potential to revolutionize not just research, but also education. A recent detailed quantitative comparison of different approaches taken by 35 charter schools in NYC has found that one of the top five policies correlated with measurable academic effectiveness was the use of data to guide instruction. Imagine a world in which we have access to a Big database where we collect every detailed measure of every student's academic performance. This data could be used to design the most effective approaches to education, starting from reading, writing, and math, to advanced, college-level, courses.
c e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 12, December 2015
International Journal of Research (IJR)
Available at http://internationaljournalofresearch.orgmaterials (through the new materials genome initiative, computational social sciences 2 (a new methodology fast growing in popularity because of the dramatically lowered cost of obtaining data) [LP+2009], financial systemic risk analysis (through integrated analysis of a web of contracts to find dependencies between financial entities), homeland security (through analysis of social networks and financial transactions of possible terrorists), computer security (through analysis of logged information and other events, known as Security Information and Event Management (SIEM)), and so on. In 2010, enterprises and users stored more than 13 Exabyte’s of new data; this is over 50,000 times the data in the Library of Congress. The potential value of global personal location data is estimated to be $700 billion to end users, and it can result in an up to 50% decrease in product development and assembly costs, according to a recent McKinsey report [1]. McKinsey predicts an equally great effect of Big Data in employment, where 140,000-190,000 workers with “deep analytical” experience will be needed in the US; furthermore, 1.5 million managers will need to become data-literate. Not surprisingly, the recent PCAST report on Networking and IT R&D [4] identified Big Data as a “research frontier” that can “accelerate progress across a broad range of priorities.” Even popular news media now appreciates the value of Big Data as evidenced by coverage in the Economist [6], the New York Times [8], and National Public Radio [4, 8].
While the potential benefits of Big Data are real and significant, and some initial successes have already been achieved (such as the Sloan Digital Sky Survey), there remain many technical challenges that must be addressed to fully realize this potential. The sheer size of the data, of course, is a major challenge, and is the one that is most easily recognized. However, there are others. Industry analysis companies like to point out that there are challenges not just in Volume, but also in Variety and Velocity [4], and that companies should not focus on just the first of these. By Variety, they
usually mean heterogeneity of data types,
representation, and semantic interpretation. By
Velocity, they mean both the rate at which data arrive and the time in which it must be acted upon. While these three are important, this short list fails to include additional important requirements such as privacy and usability. The analysis of Big Data involves multiple distinct phases as shown in the figure below, each of
which introduces challenges. Many people
unfortunately focus just on the analysis/modeling phase: while that phase is crucial, it is of little use without the other phases of the data analysis pipeline. Even in the analysis phase, which has received much attention, there are poorly understood complexities in the context of multi-tenanted clusters where several users’ programs run concurrently. Many significant challenges extend beyond the analysis phase. For example, Big Data has to be managed in context, which may be noisy, heterogeneous and not include an upfront model.
c e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 12, December 2015
International Journal of Research (IJR)
Available at http://internationaljournalofresearch.orgFig 1. Analysis of Bigdata
II. TYPES OF BIG DATA AND
SOURCES:
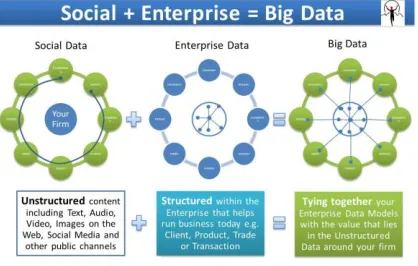
There are two kinds of big data: structured and unstructured. Structured data are numbers and words that can be effectively ordered and broke down. These data are created by things like system sensors implanted in electronic gadgets, cell phones, and global positioning system (GPS) gadgets. Structured data additionally incorporate things like deals statistics, record parities, and exchange data. Unstructured data incorporate more unpredictable data, for example, client surveys from business sites, photographs and other mixed media, and remarks on long range informal communication destinations. These data cannot effectively be isolated into classes or broke down numerically. "Unstructured big data is the things that people are saying," says big data counseling firm VP Tony Jewitt of Plano,Texas. "It utilizes common language."Analysis of unstructured data depends on keywords, which permit clients to control the data taking into account searchable terms. The sensitive expansion of the Web as of late implies that the collection and measure of big data keep on developing. Quite a bit of that development originates from unstructured data.
Fig 2. Big data Sources
III. HACE Theorem.
c e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 12, December 2015
International Journal of Research (IJR)
Available at http://internationaljournalofresearch.orgFig.3. A Big Data processing framework:
Exploring the Big Data in this scenario is equivalent to aggregating heterogeneous information from different sources (blind men) to help draw a best possible picture to reveal the genuine gesture of the camel in a real-time fashion. Indeed, this task is not as simple as asking each blind man to describe his feelings about the camel and then getting an expert to draw one single picture with a combined view, concerning that each individual may speak a different language (heterogeneous and diverse information sources) and they may even have privacy concerns about the messages they deliberate in the information exchange process. The term Big Data literally concerns about data volumes, HACE theorem suggests that the key characteristics of the Big Data are A. Big with heterogeneous and diverse data sources:-One of the fundamental characteristics of the Big Data is the Big volume of data represented by heterogeneous and diverse dimensionalities. This Big volume of data comes from various sites like Twitter,Myspace,Orkut and LinkedIn etc. B. Decentralized control:- Autonomous data sources with distributed and decentralized controls are a main characteristic of Big Data applications. Being autonomous, each data source is able to generate and collect information without involving (or relying on) any centralized control. This is similar to the World Wide Web (WWW) setting where each web server provides a certain amount of information and each server is able to fully function without necessarily relying on other servers C. Complex data and knowledge
associations:-Multistructure,multisource data is complex data, Examples of complex data types are bills of materials, word processing documents, maps, time-series, images and video. Such combined characteristics suggest that Big Data require a “big mind” to consolidate data for maximum values.
Fig 4.Datamining Process on Unstructured data
c e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 12, December 2015
International Journal of Research (IJR)
Available at http://internationaljournalofresearch.orgV. DATA MINING FOR BIG DATA
Generally, data mining (sometimes called data or knowledge discovery) is the process of analyzing data from different perspectives and summarizing it into useful information - information that can be used to increase revenue, cuts costs, or both. Technically, data mining is the process of finding correlations or patterns among dozens of fields in large relational database. Data mining as a term used for the specific classes of six activities or tasks as follows: 1. Classification 2. Estimation 3. Prediction 4. Association rules 5. Clustering
A. Classification: Classification is a process of generalizing the data according to different instances. Several major kinds of classification algorithms in data mining are Decision tree, k-nearest neighbor classifier, Naive Bayes, Apriori and AdaBoost. Classification consists of examining the features of a newly presented object and assigning to it a predefined class. The classification task is characterized by the well-defined classes, and a training set consisting of reclassified examples.
B. Estimation: Estimation deals with continuously valued outcomes. Given some input data, we use estimation to come up with a value for some unknown continuous variables such as income, height or credit card balance.
C. Prediction: It‟s a statement about the way things will happen in the future, often but not always based on experience or knowledge. Prediction may be a statement in which some outcome is expected. D.Association Rules :An association rule is a rule which implies certain association relationships among a set of objects (such as “occur together” or “one implies the other”) in a database.
E.Clustering: Clustering can be considered the most important unsupervised learning problem; so, as every other problem of this kind, it deals with finding a structure in a collection of unlabeled data.
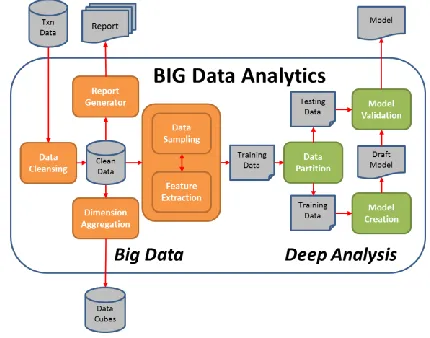
Fig 5. Big data Analytics
VI.CONCLUSION:
Big data is the term for a gathering of complex data sets, Data mining is an explanatory procedure intended to investigate data (usually vast measure of data regularly business or business sector related-otherwise called "big data") in hunt of reliable examples and afterward to validate the discoveries by applying the distinguished examples to new subsets of data. To bolster Big data mining, elite figuring stages are required, which force systematic plans to unleash the full force of the Big Data. We view Big data as a rising pattern and the requirement for Big data mining is ascending in all science and building spaces. With Big data advances, we will ideally have the capacity to provide most relevant and most precise social detecting criticism to better comprehend our general public at a continuous.
REFERENCES:
[1] Bakshi, K.,(2012),” Considerations for big data: Architecture and approach”
c e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 12, December 2015
International Journal of Research (IJR)
Available at http://internationaljournalofresearch.org[3] Aditya B. Patel, Manashvi Birla, Ushma Nair ,(6-8 Dec. 2012),“Addressing Big Data Problem Using Hadoop and Map Reduce”
[4] Wei Fan and Albert Bifet “ Mining Big Data:Current Status and Forecast to the Future”,Vol 14,Issue 2,2013
[5] Algorithm and approaches to handle large Data-A Survey,IJCSN Vol 2,Issue 3,2013
[6] Xindong Wu , Gong-Quing Wu and Wei Ding
“ Data Mining with Big data “, IEEE Transactions on Knoweledge and Data Enginnering Vol 26 No1 Jan 2014
[7] Xu Y etal, balancing reducer workload for skewed data using sampling based partioning 2013.
[8] X. Niuniu and L. Yuxun, “Review of Decision Trees,” IEEE, 2010 .
[9] Decision Trees for Business Intelligence and Data Mining: Using SAS Enterprise Miner “Decision Trees-What Are They?”
[10] Weiss, S.H. and Indurkhya, N. (1998),