System of Systems for Quality-of-Service
Observation and Response in Cloud Computing
Environments
Bhavana Lalwani1, Afshan Jabeen2, Raana Syeda4
1, 2, 3, 4
Computer Science & Engineering, Jawaharlal Nehru Technical University, Computer Science & Engineering, RTMNU, Computer Science & Engineering, RTMNU
Abstract: Cloud computing suppliers have setup a few server farms at various land areas over the Internet so as to ideally serve needs of their clients around the globe. In any case, existing frameworks don't bolster instruments and strategies for powerfully planning load conveyance among various Cloud-based server farms keeping in mind the end goal to decide ideal area for facilitating application administrations to accomplish sensible QoS levels. Further, the Cloud processing suppliers can't foresee geographic dissemination of clients devouring their administrations, subsequently the heap coordination must happen naturally, and conveyance of administrations must change in light of changes in the heap. To counter this issue, we advocate making of unified Cloud figuring condition (Inter Cloud) that encourages without a moment to spare, pioneering, and versatile provisioning of utilization administrations, reliably accomplishing QoS focuses under factor workload, asset and system conditions. The general objective is to make a processing domain that backings dynamic development or compression of abilities (VMs, administrations, stockpiling, and database) for taking care of sudden varieties in benefit requests. A solid illustration is given to utilization of this new SoS way to deal with a certifiable situation (viz., conveyed refusal of administration). Reproduced comes about affirm the viability of the approach
Keywords:Cloud computing, distributed denial of service (DDoS), enterprise systems, information assurance, net centric, quality of service (QoS), security, service-oriented architecture (SOA), systems of systems (SoS)
I. INTRODUCTION
Cloud computing has developed in ubiquity as of late on account of specialized and temperate advantages of the on request limit administration demonstrate. Many cloud administrators are presently dynamic available, giving a rich offering, including Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service (SaaS) arrangements. The cloud innovation stack has additionally progressed toward becoming standard in big business server farms, where private and cross breed cloud structures are progressively received. Despite the fact that the cloud has significantly improved the limit provisioning process, it represents a few novel difficulties in the zone of Quality-of-Service (QoS) administration. QoS indicates the levels of execution, dependability, and accessibility offered by an application and by the stage or foundation that hosts it. QoS is central for cloud clients, who anticipate that suppliers will convey the publicized quality attributes, and for cloud suppliers, who need to locate the correct tradeoffs between QoS levels and operational expenses. Notwithstanding, finding ideal tradeoff is a troublesome choice issue, regularly exacerbated by the nearness of administration level understandings (SLAs) indicating QoS targets and temperate punishments related to SLA infringement.
While QoS properties have gotten steady consideration a long time before the approach of Cloud computing, execution heterogeneity and asset seclusion components of cloud stages have altogether entangled QoS investigation, expectation, and confirmation. This is provoking a few specialists to explore robotized QoS administration strategies that can use the high programmability of equipment and programming assets in the cloud. This paper goes for supporting these endeavors by giving a study of the cutting edge of QoS demonstrating approaches relevant to distributed computing and by depicting their underlying application to cloud asset administration.
The point of this review is to give an outline of early research works in the cloud QoS displaying space, arranging commitments as indicated by applicable territories and strategies utilized. Our approach endeavours to amplify scope of works, instead of surveying particular specialized difficulties or acquainting peruses with displaying methods. Specifically, we concentrate on late demonstrating works distributed from 2006 onwards concentrating on QoS in cloud frameworks. We additionally talk about a few methods initially produced for displaying and dynamic administration in big business server farms that have been progressively connected in the cloud setting. Moreover, the review considers QoS demonstrating systems for intelligent cloud administrations, for example, multi-level applications. Works concentrating on bunch applications, for example, those in view of the Map Reduce worldview, are along these lines not studied. Notwithstanding, complex frameworks that utilization distributed computing, for example, appeared in Fig. 1, are inclined to disappointment and security trade off in five principle territories
.
Fig.1. Complex cloud computing environment [3]
TABLE I : SOS CHRACTERICS
[image:3.612.169.445.450.655.2]Inter Cloud. Section IV details the experimental results obtained in the prototype system created to verify the SOS approach. Section V presents benefits and conclusions
.
II. CLOUD WORKLOAD MODELING
The definition of accurate workload models is essential to ensure good predictive capability for QoS models. Here, we survey workload characterization studies and related modeling techniques.
A. Workload characterization
Sending condition: Several investigations have endeavoured to portray the QoS appeared by cloud arrangement situations through benchmarking. Factual portrayals of exact information are valuable in QoS displaying to evaluate dangers without the need to lead a specially appointed estimation ponder. They are key to assess practical esteems for QoS display parameters, e.g., organize data transmission difference, virtual machine (VM) startup times, begin disappointment probabilities. Perceptions of execution fluctuation have been accounted for various sorts of VM occurrences. Equipment heterogeneity and VM impedance are the essential driver for such fluctuation, which is additionally unmistakable inside VMs of a similar occasion class. Different works portray the inconstancy in VM startup times, which is corresponded specifically with working framework picture measure. A few investigations on Amazon EC2 have discovered superior conflict in CPUm bound obsand organize execution overheads. A couple of portrayal contemplates particular to open and private PaaS facilitating arrangements likewise showed up in the writing, together with examinations of cloud database and capacity administrations. Likewise, a correlation of various suppliers on a wide arrangement of measurements is introduced
B. Workload inference
The capacity to evaluate asset requests is a pre-imperative to parameterize most QoS models for big business applications. Surmising is frequently legitimized by the overheads of profound observing and by the trouble of following execution ways of individual solicitations. A few works have researched throughout the most recent two decades the issue of evaluating, utilizing circuitous estimations, the asset request put by an application on physical assets, for instance CPU necessities. From the point of view of cloud suppliers and clients, surmising procedures give a way to evaluate the workload profile of individual VMs running on their foundations, considering shrouded factors because of absence of data.
III. SYSTEM ARCHITECTURE AND ELEMENTS OF INTERCLOUD
Fig.2 shows the high level components of the service-oriented architectural framework consisting of client’s brokering and coordinator services that support utility-driven federation of clouds: application scheduling, resource allocation and migration of workloads. The architecture cohesively couples the administratively and topologically distributed storage and computes capabilities of Clouds as parts of single resource leasing abstraction. The system will ease the cross-domain capabilities integration for on demand, flexible, energy-efficient, and reliable access to the infrastructure based on emerging virtualization technologies.
Fig.2. Federated network of clouds mediated by a Cloud exchange.
Such markets empower administrations to be commoditized and in this manner, would make ready for production of dynamic market foundation for exchanging in light of SLAs. A SLA indicates the points of interest of the administration to be given as far as measurements settled upon by all gatherings, and motivations and correctional ties for meeting and disregarding the desires, individually. The accessibility of a saving money framework inside the market guarantees that monetary exchanges relating to SLAs between members are done in a safe and trustworthy condition. Each customer in the combined stage needs to instantiate a Cloud Brokering administration that can powerfully build up benefit contracts with Cloud Coordinators by means of the exchanging capacities uncovered by the Cloud Exchange.
A. Cloud Coordinator (CC)
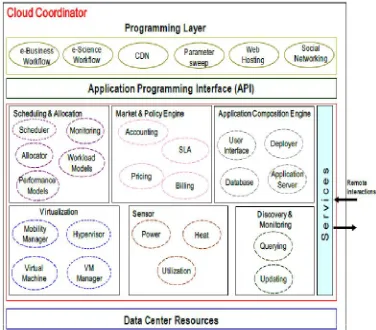
[image:5.612.217.405.249.414.2]The Cloud Coordinator service is responsible for the management of domain specific enterprise Clouds and their membership to the overall federation driven by market-based trading and negotiation protocols. It provides a programming, management, and deployment environment for applications in a federation of Clouds. Fig.3 shows a detailed depiction of resource management components in the Cloud Coordinator service.
Fig.3. Cloud Coordinator software architecture
IV. RESULTS
Here, we portray the exploratory setup and our bits of knowledge into the QoS in a SoS setup. We constructed a model of an online exchange preparing application. While each layer of the application was facilitated on an alternate cloud occasion, the cloud itself was sent in a private system. This enables us to show the reliance of execution measurements on the part incited debasement or, in our case, an absence of such corruption. For instance, in light of the fact that the setup was sent in a private gigabit Ethernet bolstered organize, we can scarcely feel the nearness of a system initiated delay in the exchanges. System prompted delay is a critical segment of instigated debasement in big business frameworks that have a worldwide nearness. Our setup copies the setup took after by a large number of the online exchange handling applications in the undertaking condition. The spellbinding insights of the recorded postponement for application occurrence are appeared in Table II. With a vast standard deviation, the postpone varieties are extensive. Likewise, we take note of that the information are skewed with a gigantic distinction amongst least and greatest postponements. These information are like genuine applications.
[image:5.612.206.403.597.696.2]A. Delay
[image:6.612.211.400.308.413.2]As discussed in, delay is one of the primary parameters considered while evaluating the QoS of a system and can be introduced into the system because of various reasons, including mis configuration of the software stack, blocked ports in the network, and data processing delays. In our work, we monitor delay at various levels of EMMRA CC. We notice that the delay perceived at the business or governance level in our work is the sum total of delay experienced at every level of EMMRA. This follows the relation established. Table III indicates that the SoS perspective of delay metric is additive in nature, as discussed.
Table Iii: Recorded In Ten Sample Delay Transactions
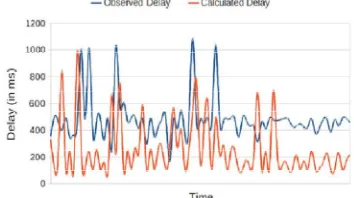
Fig.4. Variation in delay recorded over time.
Monitoring and characterizing delay helps determine the necessary configuration for a particular type of application stack to be deployed on the cloud. Delay modeling is an attempt to achieve the same. The experimental evidence provided here supports the model defined earlier. Although characterization of delay in a deployment is advantageous, it has been noted that that delay is not a constant in the system. The following section describes the variation in delay and its implications.
B. Variability in Delay
Although delay is an important performance metric, characterizing and monitoring delay alone is not sufficient in a system. Due to various factors, the delay in the system varies with time and operation being performed. For instance, when processing a data stream, the delay may vary based on the size and type of data being processed. In addition, there are various component-induced factors that affect delay in the system. As a simple example, consider Ethernet cards manufactured by different manufacturers, although the cards have same rating, owing to the raw material used or difference in manufacturing technologies, the delay induced by these cards may be different on deployment. Observing the delay variation over time (see Fig. 4) helps to identify a particular set of operations that cause maximum
[image:6.612.216.393.617.716.2]Fig.6. Throughput: Number of transactions per minute.
delay in the setup. For example, a regular pattern in spikes clearly indicates a set of operations that cause repeated delay in the system. Such operations can be isolated, and remedial actions can be suggested to the users to avert a QoS breach. Another relevant variation in delay is the variation in the observed delay and the delay computed using the modeling (without the correction factors This variation accounts for the component-induced performance degradation due to which delay is induced in the system. In Fig.5, we notice this variation in the observed delay and the computed delay value. To account for this component-induced performance degradation, we need to include some correction factors in delay modeling, and hence, it is apt to have piat each level in EMMRA
CC. It may be necessary to perform a calibration run to determine the accurate values of piin a particular setup.
C. Throughput
Throughput is an indicator of the overall system performance. It is desired to have a high-throughput system in the cloud. In our work, we measured throughput at the application and the database layers. The overall system throughput is represented in Fig. 6. Like delay, throughput is a variant in the system. Analysing the throughput variation pattern allows us to have an insight into the behaviour of the deployment (physical and software components).
Our application comprises two phases: the first phase is independent of the database transactions, whereas the second phase needs three database transactions. We tabulated the findings independently and presented them in Table V. Since all these operations are at the same layer in EMMRA CC, we notice that throughput is additive in nature. The factor in the table represents the number of database transactions needed to complete phase 2 of our application. The total throughput shown in Table IV follows the additive rule presented.
Table Iv: Throughput Of Ten Sample Transactions
V. CONCLUSION
[image:7.612.191.423.473.601.2]resources to adaptively transform service requests. We will use a broad range of analytical models and statistical curve-fitting techniques such as multi-class queuing models and linear regression time series. These models will drive and possibly transform the input to a service provisioner, which improves the efficiency of the system. Such improvements will better ensure the achievement of performance targets, while reducing costs due to improved utilization of resources. It will be a major advancement in the field to develop a robust and scalable system monitoring infrastructure to collect real-time data and re-adjust these models dynamically with a minimum of data and training time. We believe that these models and techniques are critical for the design of stochastic provisioning algorithms across large federated Cloud systems where resource availability is uncertain.
REFERENCES
[1] Paul C. Hershey, Senior Member, IEEE, ShrishaRao, Senior Member, IEEE, Charles B. Silio, Jr., Life Senior Member, IEEE, and Akshay Narayan, Student Member, IEEE, “System of Systems for Quality-of-Service Observation and Response in Cloud Computing Environments”, IEEE Systems Journal.
[2] P. Mell and T. Grance, “The NIST definition of cloud computing,” Natl. Inst. Standards Technol. (NIST), U.S. Dept. of Commerce, Gaithersburg, MD, USA, NIST Special Publication 800-145, Sep. 2011. [Online]. Available: http://csrc.nist.gov/publications/nistpubs/800-145/ SP800-145.pdf
[3] L. Badger, T. Grance, R. Patt-Corner, and J. Voas, “Cloud computing synopsis and recommendations,” Natl. Inst. Standards Technol. (NIST), U.S. Dept. of Commerce, Gaithersburg, MD, USA, NIST Special Publication 800-146, May 2012. [Online]. Available: http://csrc.nist.gov/ publications/nistpubs/800-146/sp800-146.pd
[4] M. F. Mithani, M. Salsburg, and S. Rao, “A decision support system for moving workloads to public clouds,” in Proc. Annu. Int. Conf. CCV, Singapore, May 2010, pp. 3–9.
[5] J. Spring, “Monitoring cloud computing by layer, Part 1,” IEEE Security Privacy, vol. 9, no. 2, pp. 66–68, Mar./Apr. 2011. [6] J. Spring, “Monitoring cloud computing by layer, Part 2,” IEEE Security Privacy, vol. 9, no. 3, pp. 52–55, May/Jun. 2011
[7] Y. Wei and M. Blake, “Service-oriented computing and cloud computing: Challenges and opportunities,” IEEE Internet Comput., vol. 14, no. 6, pp. 72–75, Nov./Dec. 2010.
[8] Q. Zhang, L. Cheng, and R. Boutaba, “Cloud computing: State-of-the-art and research challenges,” J. Internet Serv. Appl., vol. 1, no. 1, pp. 7–18, May 2010 [9] R. Calheiros, R. Ranjan, and R. Buyya, “Virtual machine provisioning based on analytical performance and QoS in cloud computing environments,” in Proc.
ICPP, 2011, pp. 295–304
[10] B. Rochwerger, D. Breitgand, A. Epstein, D. Hadas, I. Loy, K. Nagin, J. Tordsson, C. Ragusa, M. Villari, S. Clayman, E. Levy, A. Maraschini, P. Massonet, H. Muoz, and G. Tofetti, “Reservoir—When one cloud is not enough,” Computer, vol. 44, no. 3, pp. 44–51, Mar. 2011.
[11] T. Gwo-Hshiung, G. H. Tzeng, and J.-J. Huang, Multiple Attribute Decision Making: Methods and Applications. Boca Raton, FL, USA: CRC Press, Jun. 2011. [12] L. Zeng, B. Benatallah, A. H. H. Ngu, M. Dumas, J. Kalagnanam, and H. Chang, “QoS-aware middleware for web services composition,” IEEE Trans. Softw.
![Fig.1. Complex cloud computing environment [3]](https://thumb-us.123doks.com/thumbv2/123dok_us/8302753.854984/3.612.169.445.450.655/fig-complex-cloud-computing-environment.webp)