2018 International Conference on Computer, Communication and Network Technology (CCNT 2018) ISBN: 978-1-60595-561-2
A Method of Gesture Recognition Using CNN-SVM Model with Error
Correction Strategy
Jian LI
1,2, Zhi-quan FENG
1,2,*, We XIE
3and Chang-sheng AI
41
School of information Science and Engineering, University of Jinan, Jinan 250022, China
2
Shandong Provincial Key Laboratory of Network Based Intelligent Computing, Jinan 250022, China
3
School of Information and Electrial Engineering, Harbin Institute of Technology at Weihai, 264209, China
4
School of Mechanical Engineering, University of Jinan, Jinan 250022, China
*Corresponding author
Keywords: Gesture recognition, Convolution neural network, Support vector machine, Probability estimation, Error correction strategy.
Abstract.The gesture recognition methods based on artificial feature extraction are time-consuming and low recognition rate. The generalization ability of hand gesture recognition using convolution neural network is not strong. Therefore, this paper combines the advantages of CNN and SVM to propose a hybrid model to automatically extract the features and improve the generalization ability, in addition, we use an error correction strategy to reduce the error recognition rate of confusing gestures. First, the segmentation preprocessing of gesture data collected by Kinect. Then, the hybrid model automatically extracts features from the data and generates the predictions. Finally, using the error correction strategy to adjust the prediction result. We get a recognition rate of 95.81% without error correction strategy on our database, the average recognition rate of 97.32% with error correction strategy.
Introduction
As computers are becoming more and more popular, a convenient and natural human-computer interaction (HCI) approach is particularly important for users [1]. In many ways of human-computer interaction, gestures are being paid more and more attention as a natural, concise and intuitive human-computer interaction, and in a variety of real scene it can play an important role, such as somatosensory games, sign language recognition, intelligent wearable devices and intelligent teaching [2]. In order to achieve human computer interaction accurately, the gesture recognition algorithm should have good recognition ability in all kinds of light, angle, background and other complex environments [3].
Convolution neural network can get local and global features of input images through training and learning, it can solve the problem of inadequate feature extraction caused by manual extraction. Thus convolution neural networks have been successfully applied to image retrieval [4], face recognition [5], expression recognition [6] and target detection [7]. Some scholars have applied CNN to recognize gestures, Jawad Nagi [8] combined convolution and max-pooling (MPCNN) for hand gesture recognition. Takayoushi [9] proposed an end-to-end deep convolution network to implement gesture recognition. These methods have achieved high recognition rates, but the methods of using CNN alone for gesture recognition lack generalization ability and recognition ability for confusing gestures. Inspired by [11], we use a hybrid CNN-SVM model to improve the generalization ability and propose an error strategy to reduce the false recognition rate of the model to the confusing gestures.
Data Acquisition
gesture database. The gesture database consists of 17 kinds of gestures, which are composed of static images collected by 300 university students. We chosen 9 kinds of gestures, as shown in Fig. 1, each gesture contains 3300 pictures. The database contains a total of 27000 training samples and 2700 test samples.
0 1 2
4 5
7 8
0 1 2
3 4
7
5
8
[image:2.612.157.468.123.243.2]3
Figure 1. Left: color images; right: depth images.
The whole process of preprocessing is shown in Fig. 2, preprocessing of the collected gestures is mainly aimed at eliminating the influence of other parts of the human body and complex background.
Color Image
Depth Image Mask Image
General Gesture Area Image after Segmention Conjuncion Skin color extraction
Figure 2. The process of segmenting hand gesture.
Hybrid CNN-SVM with Error Correction Strategy (HECS)
Hybrid CNN-SVM Model
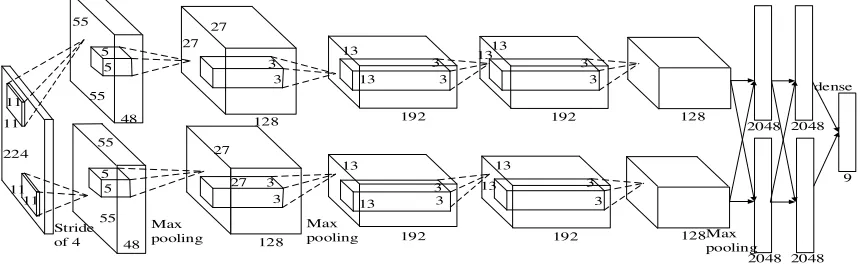
We used LIBSVM [12] to build SVM, LIBSVM can not only predict the classification results, but also provide the classification probability information for each test sample [11]. In our experiments, SVM was trained to predict the classification results with probabilities, those probability values of the classification results would be applied to decide whether the classification results were accepted directly or to be modified by the error correction strategy, which will be shown in section 3.2.This paper uses a complex convolution neural network CaffeNet mentioned in the [13], where the network structure and main parameters are shown in Fig. 3.
11 11 224 11 11 Stride of 4 55 55 48 5 5 5 5 55 55 48 128 128 27 27 3 3 3 3 27 27 Max pooling 3 3 13 13 3 3 13 13 3 3 13 13 3 3 13 13 192 192 192 192 128 128 2048 2048 2048 2048 Max pooling Max pooling 9 dense
Figure 3. Structure of the adopted CNN.
[image:2.612.99.529.565.697.2]many times until the training process converges or the maximum number of iterations is reached. Then, the training samples are input into the trained CNN model, the feature vectors of the training samples are obtained, and then the feature vectors are put into the SVM classifier to be trained again. After the training is completed, the CNN-SVM model is obtained, and the test samples are input to the model to get the classification results.
Error Correction Strategy Based on Probability Estimations
[image:3.612.91.518.232.317.2]LIBSVM gives the probability estimations for each sample in the final prediction results, and the final selected result is the largest one. Table 1 lists the final probability distributions of some of the test samples that are wrong in predicting the classification results.
Table 1. Some probability estimations of test samples by LIBSVM (we keep the values of the probability estimations 3 decimal bits, the true value of “0.000” is not 0 but only close to 0).
Trut
h Prediction 0 1 2 3 4 5 6 7 8
0 8 0.052 0.022 0.004 0.001 0.001 0.000 0.000 0.000 0.895
6 4 0.000 0.000 0.002 0.000 0.963 0.001 0.016 0.000 0.000
3 2 0.000 0.000 0.841 0.155 0.001 0.000 0.002 0.000 0.000
2 3 0.000 0.002 0.005 0.989 0.002 0.000 0.000 0.000 0.001
5 6 0.000 0.000 0.000 0.000 0.000 0.006 0.990 0.002 0.000
In the N-classification problem, the similarity between the two classes is usually expressed by distance. In the final decisions of LIBSVM, we can see from Table 1, the distance between the fist and the second best values is minimal, it means that the classes of two values are easily confused, but it doesn’t mean the results of the two categories must be wrong. So in the error correction strategy, we design a thresholdMi,jError! Reference source not found., when the distance is less thanMi,j, there may be a classification error between the two classes.Mi,jis described above:
i,j n=S
i,j n=0 n
i,j
1
M = (P (i)-P(j))
S
∑
(1)whereP (i)>P (j)n n ,P (i)n represents the maximum probability estimation of nth test sample in all the pictures predicted as ith class, andP (j)n represents the second largest value.Si,jrepresents the number of all test samples which predicted is ith class and the second max probability estimation value is jth class. ThusMi,jError! Reference source not found.actually is the thresholds vector which contains
the mean distance between the first and the second max values for the ith class.
When the classification estimation satisfies the following conditions, the corresponding class of the maximum value is modified to the class corresponding to the secondary large value.
ij
n
n i,j
p
-w (i,j)
w (i,j)<M
1
s.t. >rand(0,1)
1+e
(2) Error! Reference source not found.indicates the distance between the maximum and the secondary values of the predicted results for the ith class. That is, Error! Reference source not found.Error! Reference source not found.Mi,jis equal toError! Reference source not found..
i,j
p represents the probability that the prediction results is i but the true value is j, it is obtained by by
Experiment and Analysis
Experimental Environment
In this experiment, gesture recognition model running on the Windows operating system, the CNN network is built by Caffe. This paper used the LIBSVM software package to implement the SVM classifier, all the algorithms run on the Matlab2014a platform. The hardware configuration is CPU: Intel(R)Core(TM)i5-6500; GPU: NVIDIA GeForce GT 730; Memory is 8G and 2G.
Experimental Results and Analysis
In order to prove the effectiveness of the preprocessing, we do CNN training on different data sets. The accuracy of the color image can only be up to 37.92%, the accuracy of the depth image is 79.07%, the accuracy of preprocessed image is 88.35%. This because that the preprocessed image can not only effectively remove the noise information, but also retain the complete color information of the gesture area. It makes it possible to extract more rich features for classification in CNN network training.
We used the RBF kernel to build the SVM, and determined the optimal kernel parameter g and penalty parameter C by applying the 5-fold cross validation method on the training dataset. The best validation rate was achieved when g=0.00024414 and C=64.These parameters were used to train hybrid model, the final training accuracy rate was 99.94%, and the accuracy rate on the test set was 95.81%.
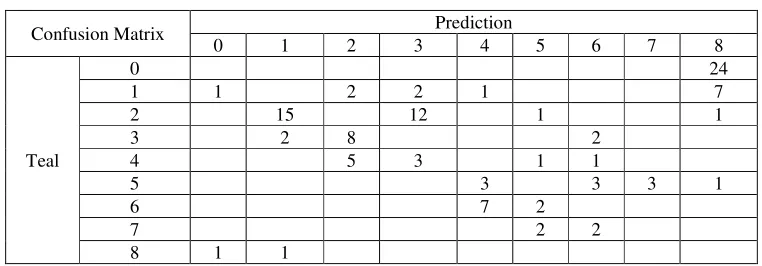
[image:4.612.115.496.380.513.2]Table 2 presents the confusion matrix of the hybrid model, we use the statistical information of the matrix to solve the Error! Reference source not found. in Eq. 2, and then the Error! Reference source not found. is used to the error correction strategy.
Table 2. Confusion matrix of the CNN-SVM model on the testing dataset.
Confusion Matrix Prediction
0 1 2 3 4 5 6 7 8
Teal
0 24
1 1 2 2 1 7
2 15 12 1 1
3 2 8 2
4 5 3 1 1
5 3 3 3 1
6 7 2
7 2 2
8 1 1
[image:4.612.176.432.605.690.2]In the 100 experiment, the error correction rate is mainly between 3% and 5%, and the accuracy rate is the most concentrated in [97%, 98%]. The average error rate was 4.12%, and the average accuracy rate was 97.32%. The error correction strategy in this paper actually is an algorithm based on statistical probability. Although most of error classification decisions can be corrected, sometimes there are cases of failure to correct the error or amend the original decisions.
Table 3. Comparisons of testing results on our test dataset.
Method Test Accuracy(%)
MPCNN [9] 68.89
Bottom-Up Deep CNN [10] 85.43
SAE-PCA [11] 93.32
CaffeNet [14] 88.35
CNN-SVM 95.81
HECS 97.32
Summary
This paper presents a gesture recognition method based on hybrid CNN-SVM model with error correction strategy. On the one hand, our method combines the advantages of CNN and SVM, hybrid model automatically extracts the salient features and improves the generalization ability. On the other hand, the error correction strategy provides a method to solve the mispredictions for confusing gestures. A large number of experimental results show that this method can effectively identify gestures, and to a certain extent, optimize the ability of CNN-SVM model to classify easily confused gestures. The error correction algorithm proposed in this paper can improve the accuracy of the final recognition, but the stability of the algorithm is still insufficient. How to stabilize the error rate of the easily confused gesture to improve the recognition rate is the next research topic.
Acknowledgement
This paper is supported by the National Key R&D Program of China (No. 2016YFB1001403) and the National Natural Science Foundation of China (No. 61472163).
References
[1] S.S. Rautaray, A. Agrawal, Vision based hand gesture recognition for human computer interaction, J. Artificial Intelligence Review. 43 (2015) 1-54.
[2] X. Wang, Intelligent classroom gesture recognition algorithm research and interactive prototype system design, D. Xidian University (2009)
[3] H. Hasan, S. Abdul-Kareem, Retracter Article: Static hand gesture recognition using neural networks, J. Artificial Intelligence Review. 41 (2014) 147-181.
[4] A. Babenko, A. Slesarev, Chigorin A., et al., Neural Codes for Image Retrieval, C. European Conference on Computer Vision. 2014, pp. 584-599
[5] Gil. Levi, T. Hassner, Age and Gender Classification Using Convolutional Neural Networks, C. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 2015, pp. 34-42.
[6] A. Mol, D. Chan, Going deeper in facial expression recognition using deep neural networks, C. Applications of Computer Vision (WACV). 2016, pp. 1-10.
[7] H. Jiang, et al., Face Detection with the Faster R-CNN, C. Automatic Face & Gesture Recognition. (2017)
[8] J. Nagi, F. Ducatelle, et al., Max-Pooling convolutional neural networks for vision-based hand gesture recognition, C. 2011 IEEE International Conference, Signal and Image Processing Applications (ICSIPA). 2011, pp. 342-437.
[9] T. Yamashita, T. Watasue, Hand posture recognition based on bottom-up structured deep conbolutional neural network with curriculum learning, C. IEEE International Conference, Image Processing (ICIP). 2014, pp. 853-857.
[10] S.Z. Li, B. Yu, et al., Feature learning cased on SAE-PCA network for human gesture recognition in RGBD images, J. Neurocomputing. 151(2015) 565-573
[11] X.X. Niu, et al., A novel hybrid CNN-SVM classifier for recognizing handwritten digits, J. Pattern Recognition 45(2012) 1318-1325
[12] C.C. Chang, C.J. Lin, LIBSVM: A library for support vector machines, J. ACM Transactions on Intelligent Systems and Technology (TIST). 2 (2011) 1-27