Blog Post Extraction using Text-to-Tag Ratio and Maximum Scoring Subsequence
陳 陳 吳 志銘 柏志 文斌
985202018 995202017 995202021
國 立中央大學
資 訊工程學系
國 立中央大學
資 訊工程學系
國 立中央大學
資 訊工程學系
[email protected] [email protected] w
摘 要
近 年 來
, 部 落 格 為 主 的 相 關 研 究 蓬 勃 發 展
, 例 如
: 意 見
檢 索
、 情 緒 分 析
。 因 此
,
部落格主文擷取即是所需的前處理程序。由於
部 來 網 落格網頁 自於不同 站,
呈 , 現的樣式風格多變 無法簡單地
透 。 過正規表示式擷取主要文章
再 HTML 者,
網 頁 中 包 含 許 多 和 主
題 不 相 關 的 資 訊
, 例 如
: 廣 告
、 導 覽 列
… 等
, 使 得 擷 取 部 落 格 主 文 是 一 項 相 當 複
雜 的工作。因此,我們先計算網頁中每一行的
Text-to-Tag Ratio , Maximum 再利用
Scoring Subsequence
演 F- 算法擷取部落格主文,實驗結果顯示
Measure 可 89% 。 達到 此系統可應用於
PDA
、 手 機
… 等 螢 幕 較 小
的裝置,以及自然語言處理、文件自動摘要...
等 其 他 研
究 領域,並提供後續相關研究之參考與應用。
關 Content Extraction 、 鍵字:
Blog Post Extraction 、
1. 緒 論
部 Web 2.0 落格是
的 主 要 網 路 服 務 之 一
, 隨 著
部 落 格 蓬 勃 發 展
, 不 僅 只 有 純 文 字 格 式
,
還 可結合照片、音樂、影像等多元模式呈現,
部 落格的走向、定位、性格,不同於一般
BBS
、 討 論 區
, 其 所 記 錄 的 生 活 札 記
、 小 道
消 息
, 到 政 治 議
題、專業知識,完全取決於作者的自我論點,
並 可與讀者討論和互動。
近 幾 年
, 部 落 格 的 相
關研究受到越來越多的關注,例如:意見檢索
(opinion retrieval) 、 (sentiment 情緒分析
analysis) 、 (spam blog post 垃圾文章偵測
detection) 等
, 並 且 也 有 針 對 部 落 格 文 章 摘 要 與
留 言 評 論 的 相 關 應 用 和
論 文發表。由於上述提及的研究議題,皆需從
大 量 不 同 的 部 落 格 網 頁 中 抓 取 作 者 撰 寫 的 文 章 進 行 分 析
,
因 此擷取部落格主文便成為一項重要的工作。
部
落 格 網 頁 不 同 於 一 般 網 頁
, 文 章 內 容 可 能 是 圖 文 並 茂
, 有 時 使 用 者 會 因 個 人 喜 好 加
入 影
音 資 訊
, 亦
或只有簡短的句子和少量的詞彙。除此之外,
不 同 網 站 的
部落格網頁擺放主文的位置不固定,並且文章 附
近 經 常 包 含 許 多 各 式 各
樣的雜訊,例如:廣告、導覽列、選單列表...
等
。 正 因 如 此
, 如 何 擷 取 部 落 格
主 文
, 困難 複雜且相當 是一項
具 挑戰 性的工作。 有
使 用 正 規 表 示 式 擷 取 網 頁 中 的 主 要 文 章 是 最 直 接 的 方 法
, 但 需 針 對 特 定 網 站 撰 寫
特 定 規 則
, 然 而 部 落 格 網 頁 風 格 多 元
, 單 一 規 則 無 法 適 用 於 多 個 不 同 網 頁
。 除 此 之 外
,
部 落 格 網 頁 的 版 面 架 構 其 更 動 頻 率 相 當 高
, 可 能 會 造 成 原 本 的 擷 取
程式產生錯誤,需經常更新維護或重新撰寫,
是 一個
效 率
低 較 的 法。 落且 信任度 差 方
目
前 大多
數 於 擷取網頁 基 內 容 的演算法,是
DOM tree
的
架 割 , 著利用 構 將 網頁分 成許多區 塊 接
HTML 標 籤
語 法 的 特 性 或
是 器 機
學 的 法擷取主要文章 , 。 然 習 方 而 建構
DOM tree
並 運 用 此 架 構 所 花 費 的 時 間 複 雜 度 相 當 高
, 無 法 快 速 的 處 理 大 量 網 頁
。 另 外
, 機 器 學 習 的 方 法 需 要 標 記 訓 練 資 料
, 若
以人工標記則相當的耗時耗力。因此,我們將
Weninger 等 人提
出 的 Text-to-Tag Ratio
計 算 方 法 做 更 進 一
步的修改,使其能適用於部落格網頁,並結合 Maximum Scoring Subsequence 演
算
法擷取部落格網頁的主要文章。實驗結果顯示
F-Measure 可 達到
89% , 是一個有
效
率 的 法。 方
此
篇 告 報
架
構 如 , 相關研究, 下 第二節介紹
第
三 節描
述 擷
取 法 部 落 格主文的 方 ;第四節介紹
Adaptive Text-to-Tag Ratio 演 Naïve 算法及
Bayes 分
類 型 述 模 ; K-means 第五節描
分
群 和 Maximum Scoring Subsequence
演 算法
第 六 節 為 實 驗 的 環 境 建 置
; 第 七 節 為 實
驗 結果
;
最 後 結 介紹未 總 這篇 論文及 來研究。
2. 相 關研究
本
章 網頁內容擷 取 節介 (Content 紹
Extraction) 的 技術 。 相關研究與
一 般 說 來
, 許 多 之
前 的 研 究 會 將 網 頁 分 割 成 許 多 區 塊
, 接 著 計 算 區 塊 的 重 要 程 度
, 進 而 擷 取 網 頁 主
要 內文,並且實驗資
料
集 大多針對 新聞 網頁。
Cai 等 人提
出 Vision-based Page
Segment (VIPS)[1]演算法,不同於傳統基於
DOM tree 架
構 的 切 割 方 式
, 利 用 特 定 的 視 覺 線 索 規 則 將 網 頁 切 割 成 許 多 區 塊
, 但 需 要 設 定 參 數
並 能
精 才 出 確 標 記主文 可擷取 網頁的主要文章。
Cao 等 [2] 人
設 計 一 個 兩 階 段 的 方
法擷取部落格網頁的文章和評論。首先,基於 DOM
樹 的 架 構
, 計 算
每一個節點之有效內容機率,並透過網頁中的 CSS
語 法 獲 得 每 一 個 節 點 所 呈 現 的 視 覺
寬 度
, 藉 此 找 出 主 要 文 章 的 範 圍
。 接 著 尋 找 最
小 資 訊 量的位置作為文章和留言的區分點。
Pasternack 與 Roth 透 Naïve Bayes 過
分
類 ,計算 器 每 一 個 HTML
標 籤
、 詞 彙 與 標 點 符 號
包 含於主要內文的機
率 此機 率值轉換 成 ,並 將 -
0.5 至 0.5 之
間 , 後利用 的分 數 最 Maximum
Scoring Subsequence 演
算 法
, 求 得 唯 一 且 最 長 的 子 序 列
, 進 而 擷 取 網 頁 中 的 主 要 文 章
。 實 驗 資 料 集 主
要 新聞 網頁,且需 是針對
事 標 訓練 資 。 先 記 料
Weninger 等 人提
出
藉 由計算 HTML
檔 中每 Text-to-Tag Ratio 案 一 行 的
並
轉 成 型 接 換 二維 模 , 著透過 K-means
分 群
演 算 法 擷 取 主 要 文 章
。 實 驗 資 料 集 也 是 針 對 新 聞 網 頁
, 優
點 於不需 記 料 在 標 訓練 資 ,且實驗結果顯示
F-Measure平 可達 93.9%。 均 到
3. 部 落格主文擷取
當 搜尋 部落格時, 使用者以關鍵字
搜 尋 引 擎 即 傳 回 其 索
引 資 料 庫 中 相 關 部 落 格 網 頁 的 連 結
,此時需要針對部落格網頁進行主文的擷取以
提 更 供後續相關研究
進
一 步 的分析。
首 先
, 需 先 判 斷 搜 尋 引 擎 呈 現 的 相 關 連 結 是 否 為
部 落 格 網 頁
。 接 著
, 擷 取 部 落 格 作 者 撰 寫 的
主 要文章。
最 多 的 濾除 。 後, 將 餘 標籤 及雜訊
3.1. 辨
識 部 落 格網頁
如 何 辨 識 是
否為部落格網頁可當作是一個分類問題,2009 年
張 楊萍華 嘉 惠 教授 和 的論文當中,參考 Cao
等 Elgersma 和 Rijke 人以及
為 了
區 非 而 出 特徵 ,利用 分 部 落格與 部落格 提 的
LibSVM 建
立 部落格分 類器 ,實驗結果顯示 部 落 格與 非
F-measure 可 達
90.7%
, 因 此
我 們 假 設 此 分 類 器 存 在 的 狀 況 下
, 後 續 的 實 驗 資 料 集 是 從 各 式
各 蒐集而 樣的 來的部落格網頁。 部 落 格網站
3.2. 擷 取主要文章
我 嘗試 們 將
部 落 格 網
頁 別 分 以HTML
原 始碼
當 中
的 每 一 行和每一個 token
這 式 兩種方
做 切
割 ,token 可 能為一個
HTML 標 、 籤
詞
彙 或是 標 符號 點 。
接
著 , 計 算每一行的 Text-to-Tag Ratio
和 Naïve Bayes 計 token 利用 算每一個
包 含於主要文章的機
率 別 ,再 分 實作 K-
means 分
群 與 Maximum Scoring
Subsequence 演
算 法 擷 取 部 落 格 網 頁 的 主 要
文 章,
流 程如圖一 Text- 所 示 。實驗結果顯示,
to-Tag Ratio 和 Maximum Scoring
Subsequence 演 最佳 的 算法是
組 合, F-
Measure可 89% 。 達到
圖1. 系 流 統
程 圖
4. Computational Method
Weninger 等 人提
出 的 Text-to-Tag
Ratio 計 算 方 法 可 以 有 效
率 的 擷 取 新 聞 網 頁 中 的 主 要 內 容
。 然 而
, 部 落 格 網 頁 不 同 於 新 聞 網 頁
, 文 章 內 容 可 能 是
圖 文 並 茂
, 有 時 使 用 者 會 因 個 人 喜 好 加 入 影 音 資 訊
, 亦 或 只 有 簡 短 的 句 子 和 少 量 的 詞 彙
。 我 們 將 此 方 法 實
作於擷取部落格網頁的主要文章,其結果顯示
F-Measure 只 有
80%
。 因 此
, 我 們 根 據 部 落 格 網 頁 的 特 性 與 架 構 做 適 當 的 修 改
, 使
其 能 廣 泛 適
用 各 各 於 擷 取 式 樣部落格網頁的主 要 文 章。
4.1. Adaptive Text-to-Tag Ratio
簡 單來
說 , Text-to-Tag Ratio
即 HTML 是計算
標 籤 個 數 與 非 標 籤 的 字 元 長 度 之 比 例
。 在 部 落 格 網 頁
中 ,主要文章的呈現
方 各 各 只考 慮 法 式 樣, 若
HTML 標 籤 個 數 與
非 標 籤 的 字 元 長 度 之 比 例
, 會 遺 失
許多重要的資訊,例如:圖片、影音、表格...
等 非 文
字和特殊格式的內容,並間接影響到上下文的 Text-to-Tag Ratio 。
我 根 HTML 們 據
標 籤 語 法 特 性 做
適當的修改,<p>、 <br> 、 <blockquote>
此 類 型 的 標 籤 經 常
現 於 部 落 格 網 頁 的
主 要文章,因此我們
將 視 其 為內容相關的 標籤
(Content Tag)
, 在 計 算 的 過 程 中 給 予 較 高 的 權 重
。
另 ,針對 類型 的資訊,我們 在 外 圖 片 和影音
計 Text-to-Tag Ratio 時 算
考 慮 其 呈 現 寬 度 和 周 遭
非 標 籤 的 字 元 長 度
。 關 於 網 頁 中 表 格 類 型 的 內 容
, 我 們 藉 由
計算表格中的非標籤的字元長度當作每一行的 Text-to-Tag Ratio 。Adaptive Text-to-Tag
Ratio 演 2 所 算法如圖 示。
圖2. Algorithm for computing Adaptive Text-to- Tag Ratio
我 們以一個
典
型 的部落格網頁作 為 計 算
Adaptive Text-to-Tag Ratio 的
範 所示。圖 四 例, 三 為此網頁每一行的 如 圖
Adaptive Text-to-Tag
Ratio , 長條 圖表示。 以
圖3. 部 落格網頁
0 100 200 300 400 500 600 700
Line Number
TTR Array
圖4. AdaptiveText-to-Tag Ratio line by line from the blog page example
4.2. 模
糊 處理 化
對 Adaptive Text-to-Tag Ratio 做
模 糊 化 Input: D ← Blog page
Output: T ← Text-to-Tag Ratio
Define α ← text length threshold β ← image width threshold γ ← video width threshold for all i ← 1 to |D| do
x ← nonTagChars (Di) y ← tags (Di)
if (y > 0)
if Content Tag exists then if (y – Content Tag) > 0 then Ti ← x / (y – Content Tag) else
if (x > 0) then Ti ← x else Ti ← max (Ti-1, Ti-2) else Ti ← x / y
if image width > α then
if x > β then Ti ← image width + x / y else Ti ← (image width + x) / y if video width > γ then Ti ← video width if Table Tag exists then Ti ← table length else
if (x > 0) then Ti ← x else Ti ← 0
end for
處 理
, 可 避 免 在 擷 取 主 要 文 章 時 遺 失 和 文 章 內 容 有 關 的 資 訊
, 例 如
:
標 段 換 落 題、 日期 、 落 行、較短的句子或 段 ..
等 公 。
式
如 下 : Ti'=
∑
k=i−ri+r TTRArrayk
2r +1 ,
將
每 一 行 的 Adaptive Text-to-Tag Ratio
與 前 後 相
鄰 的 兩 個 值
相 ,即是模 糊化 後的結果。 加 計 算其 平均值
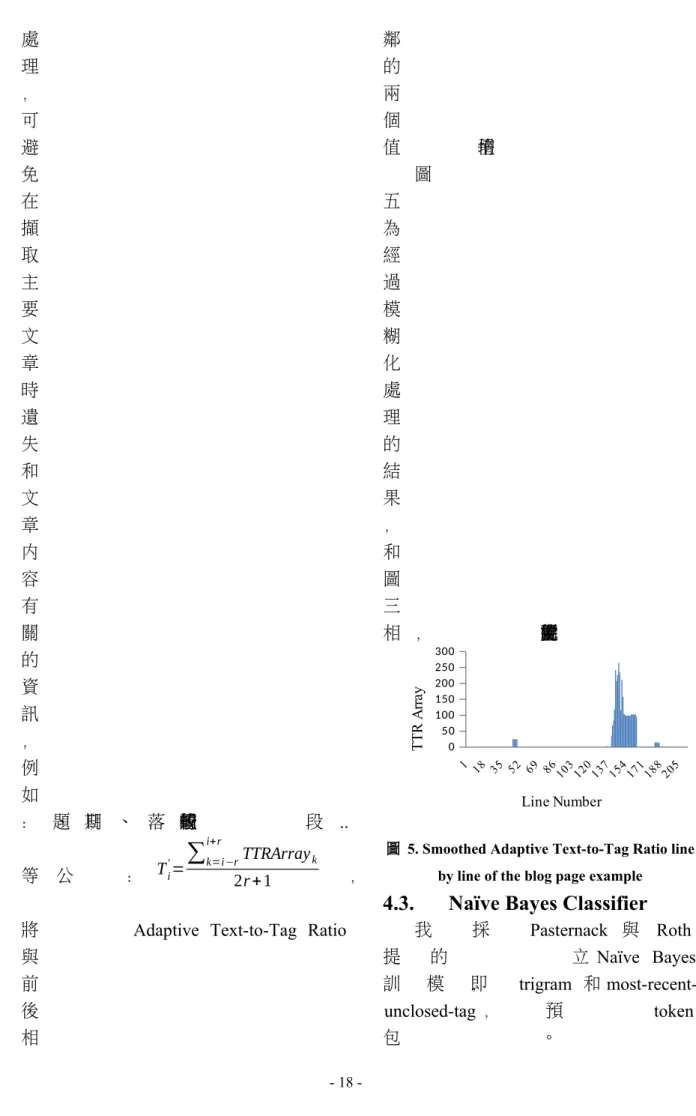
圖 五 為 經 過 模 糊 化 處 理 的 結 果
, 和 圖 三 相
比 更明 顯的表現 出 , 主要文章的可能位置。
0 50 100 150 200 250 300
Line Number
TTR Array
圖 5. Smoothed Adaptive Text-to-Tag Ratio line by line of the blog page example
4.3. Naïve Bayes Classifier
我 採 們
用 Pasternack 與 Roth
提
出 兩種特 徵 建 的 立 Naïve Bayes
訓 模 練
型 ,即 trigram 和 most-recent-
unclosed-tag , 預 用以
測 每 一 個 token
包 含於主要文章的機
率 。
假 一個 U = (u1, u2,..., un) 設 序 列
表 n 個 token , 示有
則 表 代 第 i 個 token 的
trigram 特徵為<ui, ui+1, ui+2> 。most-recent-
unclosed-tag 特 的計 堆疊 (stack) 徵 算 是 利用
形 式 的 資 料 結 構
, 將 起 始 標 籤 放 入 堆 疊
, 如 果 比 對
到相對應的結束標籤則將此起始標籤輸出,第i 個 token 的 most-recent-unclosed-tag 特
徵 即 是
目 堆疊頂端 的 若 試 料 前位 標籤 。 測 資 中的 於
trigram 特徵未出現於訓練資料,則將此token
包 含於主要文章的機
率 值 為 設
P(t|in )=P(t|out)=0. 5
。
5. Extraction Method 5.1. Algorithm
本 Maximum Scoring 節將介紹
Subsequence 的
運 方 的。 假設 一個序列 作 式及 目 S = (s1,
s2,..., sn) , si 其中
為 實 數
, 可 當 作
是一個分數。此演算法之目的即是找出在序列 S
當
中,分數加總最大的一個連續子序列,令其為
T = (sa, sa+1,..., sb) , 1 ≤ a ≤ b ≤ 其中
n 。 六 演算法如圖
所 示
,
時 間 為 複雜 度 O
(n) 。
圖6. Algorithm for finding the maximum scoring subsequence
5.2. Applying Maximum Scoring Subsequence
我 將 們
模 糊化 後的每一行 Text-to-Tag
Ratio 相 加 計
算 平均 其 值
,
再 藉 減去 此 由 平均值將 每一行的
Text-to-Tag Ratio
轉 成一 數 換 個 分
,
進 而 透過 Maximum Scoring
Subsequence
此 。 演算法擷取部落格網頁的主要文章
另 ,我 採 外 們 也
用 Pasternack與 Roth
提
出 方 由 由 的 法, 藉 將每 token 經 Naïve 一個
Bayes 預
測 率值 ,以 減去 包 含 於主要文章的機
0.5 的
方 轉換 成一個分 數 透過 式 ,進 而
Maximum Scoring Subsequence
此 。 演算法擷取部落格網頁的主要文章
5.3. Applying K-means Clustering
我 採 們
用 出 方 Weninger 等 的 法, 人提
先
將 糊化 後的每一行 模 Text-to-Tag
Ratio ,轉換成二維模型的資料。公式如下:
Gi=
∑
j=0 ω Ti+ j'ω −Ti' 。Ti’ 表示模糊化後的
Text-to-Tag Ratio , ω 於 設 實驗中
為
3 。 計算
出 來的 值代 表每一行 Text-to-Tag
Ratio 增
加 減少 的 最 或 趨勢 。 後, 將 Gi
取
絕 值 對 ,即 ^G=|Gi'|
作 第二 的資 料 為 維 度
。
另 ,每 token 經 外 一 個
由 Naïve Bayes
預 測 包 含 於 主 要 文 章 的 機 率
,
也依照上述方法轉換成二維模型的資料,此時
Ti’ 為 token 每一個
包 含於主要文章的機
率 值 。
我 K-means 們利用
演 算 Given: S = (s1, s2,...,sn)
Output: maxSS start = 0
sum = 0 maxSS = (-∞) for i = 1 to n do sum = sum + si
if sum > value (maxSS) then maxSS = (sstart, sstart+1,...,si) if sum < 0 then
start = i + 1 sum = 0 end for
法 對 二 維 資 料 做 分 群
, 將 中 心 最 接 近 原 點 的 群 視 為 非
主要文章,剩下的群皆視為包含於主要文章,K
於 設 實驗中
為 3 。
6. Experimental Setup 6.1. Data Set
我 Blogspot 、 Technorati 和 們從
Yahoo 這 三 個 部 落 格 網 站
, 蒐 集 十
個主題的部落格網頁,前五個主題抓取限定在 Blogspot.com
的 訓練 資 部落格網頁作為
料 ,並針對
Blogspot.com 部 Wrapper 落格網站撰寫
自 動 標 記 答 案
; 後 五 個 主 題 則 抓 取 上 述 三 個 部 落 格 網 站 的
網頁做為測試資料,並從每一個主題隨機挑選 25
篇 網 頁
,
以 方 人工的
式 記 所示。 標 答案 ,如表一和表 二
表1. 訓 資 練
料
Topic #pag e applebee 261
batman 582 beige book 512 iphone 522 obama 539
表2. 測
試 料 資
Topic #page #select page
bmw 351 25
phone fake 450 25 red sox 358 25
science
friday 433 25 south park 426 25
6.2. Preprocessing
以 HTML 原 始碼
當 中 的
每 一行
切
割 部落格網頁 之 前 , 我 們先利用
HTML Tidy 修
正 HTML
檔 中的 標籤錯誤 並自動格式 案
化 刪 除 ,再
JavaScript 、 CSS 語
法 和 開 發 人 員 撰 寫 的 程 式 碼
註 解
, 也 將 空 白 行 移 除
,
並讓不常使用或是自行定義的標籤名稱轉換成
<UNKNOWN> ,
接 找 “ 著 到 comment”
這 個 字 在 網 頁 中 最 後 出 現 的 位 置
, 將 其 後 面 的 內 容 刪
除。上述之前處理程序,其用意皆是避免計算 Text-to-Tag Ratio
時 受到雜訊 干
擾
而 致 生 導 實驗結果 產 誤差 。
至
於 以 token
的 方 式 切 割 部 落 格 網 頁
,其前處理程序同上,只需再經過Stemming 的
步 變 還 成 驟 將 詞型 及時 態 化 原 原型 ,提 升
Naïve Bayes
訓練模型的效率,本篇論文於實作上採用Porter
Stemming 演 算法。
6.3. Performance Metrics
我 Precision 、 Recall 和 F- 們以
Measure
三 計算 方 種
式 來 評 量
實 公 : 驗 的 結果。 式如 下
P=|WP∩WL|
|WP| , R=|WP∩WL|
|WL| , F1=2 PR P+R
WP 表 集 示擷取結果的字
, WL
表 標 示
記 。 答案 的字 集
7. Results 7.1. Baseline
我 們分
別
將 Weninger
等 人提
出 二
維 型 模 Text-to-Tag Ratio 搭 K- 配
means 分
群 演算 Pasternack 與 Roth 法 , 和
提
出 以Naïve Bayes 搭 Maximum Scoring 配
Subsequence演 算法實作於部落格網頁,由於
K-means 分
群 演
算 法 為 非 監 督 式
, 不 需 要 準 備 訓 練 資 料
, 因 此 實 驗
資料集為訓練資料加上隨機挑選的測試資料,
結 三 果如表
所 示
。
表 3. Baseline
Method Precision Recall F-Measure 2DTR
+ K- means
81.49% 84.79% 80.42%
Naïve Bayes + MSS
90.46% 86.83% 87.26%
我 將Weninger 等 們可以發現 人提
出
的
方 法 F-Measure 只 80% 有
左
右,並不適用於部落格網頁。原因在於,計算
Text-to-Tag Ratio 時只 慮 HTML 單純考