Effective Inference for Generative Neural Parsing
Mitchell Stern Daniel Fried Dan Klein
Computer Science Division University of California, Berkeley
{mitchell,dfried,klein}@cs.berkeley.edu
Abstract
Generative neural models have recently achieved state-of-the-art results for con-stituency parsing. However, without a fea-sible search procedure, their use has so far been limited to reranking the output of ex-ternal parsers in which decoding is more tractable. We describe an alternative to the conventional action-level beam search used for discriminative neural models that enables us to decode directly in these gen-erative models. We then show that by im-proving our basic candidate selection strat-egy and using a coarse pruning function, we can improve accuracy while explor-ing significantly less of the search space. Applied to the model ofChoe and Char-niak (2016), our inference procedure ob-tains 92.56 F1 on section 23 of the Penn Treebank, surpassing prior state-of-the-art results for single-model systems.
1 Introduction
A recent line of work has demonstrated the success of generative neural models for constituency pars-ing (Dyer et al.,2016;Choe and Charniak,2016). As with discriminative neural parsers, these mod-els lack a dynamic program for exact inference due to their modeling of unbounded dependencies. However, while discriminative neural parsers are able to obtain strong results using greedy search (Dyer et al., 2016) or beam search with a small beam (Vinyals et al.,2015), we find that a simple action-level approach fails outright in the genera-tive setting. Perhaps because of this, the applica-tion of generative neural models has so far been re-stricted to reranking the output of external parsers. Intuitively, because a generative parser defines a joint distribution over sentences and parse trees,
probability mass will be allocated unevenly be-tween a small number of common structural ac-tions and a large vocabulary of lexical items. This imbalance is a primary cause of failure for search procedures in which these two types of ac-tions compete directly. A notion of equal com-petition among hypotheses is then desirable, an idea that has previously been explored in gener-ative models for constituency parsing (Henderson,
2003) and dependency parsing (Titov and Hen-derson,2010;Buys and Blunsom, 2015), among other tasks. We describe a related state-augmented beam search for neural generative constituency parsers in which lexical actions compete only with each other rather than with structural actions. Ap-plying this inference procedure to the generative model ofChoe and Charniak(2016), we find that it yields a self-contained generative parser that achieves high performance.
Beyond this, we propose an enhanced candi-date selection strategy that yields significant im-provements for all beam sizes. Additionally, mo-tivated by the look-ahead heuristic used in the top-down parsers of Roark (2001) and Charniak
(2010), we also experiment with a simple coarse pruning function that allows us to reduce the num-ber of states expanded per candidate by several times without compromising accuracy. Using our final search procedure, we surpass prior state-of-the-art results among single-model parsers on the Penn Treebank, obtaining an F1 score of 92.56.
2 Common Framework
The generative neural parsers ofDyer et al.(2016) andChoe and Charniak(2016) can be unified un-der a common shift-reduce framework. Both sys-tems build parse trees in left-to-right depth-first or-der by executing a sequence of actions, as illus-trated in Figure1. These actions can be grouped
S
. VP
NP
idea an had NP
He
[image:2.595.311.525.63.184.2](S (NP He NP) (VP had (NP an idea NP) VP) . S)
Figure 1: A parse tree and the action sequence that produced it, corresponding to the sentence “He had an idea.” The tree is constructed in left-to-right depth-first order. The tree contains only non-terminals and words; part-of-speech tags are not included. OPEN(X)and CLOSE(X)are rendered
as “(X” and “X)” for brevity.
into three major types: OPEN(X)and CLOSE(X),
which open and close a constituent with nontermi-nal X,1 respectively, and SHIFT(x), which adds
the wordxto the current constituent. The proba-bility of an action sequence(a1, . . . , aT)is
P(a1, . . . , aT) = T
Y
t=1
P(at|a1, . . . , at−1)
=
T
Y
t=1
[softmax(Wut+b)]at,
where ut is a continuous representation of the parser’s state at time t, and [v]j denotes the jth component of a vectorv. We refer readers to the respective authors’ papers for the parameterization ofutin each model.
In both cases, the decoding process reduces to a search for the most probable action sequence that represents a valid tree over the input sentence. For a given hypothesis, this requirement implies sev-eral constraints on the successor set (Dyer et al.,
2016); e.g., SHIFT(x)can only be executed if the
next word in the sentence is x, and CLOSE(X)
cannot be executed directly after OPEN(X). 3 Model and Training Setup
We reimplemented the generative model described in Choe and Charniak (2016) and trained it on the Penn Treebank (Marcus et al., 1993) using
1The model described inDyer et al. (2016) has only a
single CLOSEaction, whereas the model described inChoe and Charniak(2016) annotates CLOSE(X)actions with their nonterminals. We present the more general version here.
(S (NP He NP) (VP had (NP an idea NP) VP) . S) -0.1
-0.5
-3.2 -0.0 -0.1
-4.6 -1.4
-3.9 -4.0 -0.1
-0.8 -0.0 -0.0
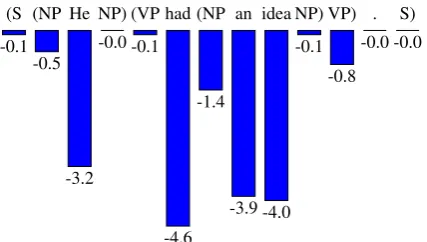
Figure 2: A plot of the action log probabilities
logP(at | a1, . . . , at−1) for the example in Fig-ure 1 under our main model. We observe that OPENand CLOSEactions have much higher
prob-ability than SHIFTactions. This imbalance is
re-sponsible for the failure of standard action-level beam search.
their published hyperparameters and preprocess-ing. However, rather than selecting the final model based on reranking performance, we instead form early stopping based on development set per-plexity. We use sections 2-21 of the Penn Tree-bank for training, section 22 for development, and section 23 for testing. The model’s action space consists of 26 matching pairs of OPEN and
CLOSE actions, one for each nonterminal, and
6,870 SHIFT actions, one for each preprocessed
word type. While we use this particular model for our experiments, we note that our subsequent dis-cussion of inference techniques is equally appli-cable to any generative parser that adheres to the framework described above in Section2.
4 Action-Level Search
Given that ordinary action-level search has been applied successfully to discriminative neural parsers (Vinyals et al., 2015; Dyer et al., 2016), it offers a sensible starting point for decoding in generative models. However, even for large beam sizes, the following pathological behavior is en-countered for generative decoding, preventing rea-sonable parses from being found. Regardless of the sequence of actions taken so far, the generative model tends to assign much higher probabilities to structural OPEN and CLOSE actions than it does
lexical SHIFTactions, as shown in Figure2. The
[image:2.595.129.228.66.151.2]Beam Sizek 200 400 600 800 1000 2000
kw=k 87.47 89.86 90.98 91.62 91.97 92.74
[image:3.595.308.527.63.352.2]kw=k/10 89.25 91.16 91.83 92.12 92.38 92.93
Table 1: Development F1 scores using word-level search with various beam sizeskand two choices of word beam sizekw.
sequence typically has much lower overall prob-ability than a plausible parse, but the model’s my-opic comparison between structural and lexical ac-tions prevents reasonable candidates from staying on the beam. Action-level beam search with beam size 1000 obtains an F1 score of just 52.97 on the development set.
5 Word-Level Search
The imbalance between the probabilities of struc-tural and lexical actions suggests that the two kinds of actions should not compete against each other within a beam. This leads us to consider an augmented state space in which they are kept separate by design, as was done by Fried et al.
(2017). In conventional action-level beam search, hypotheses are grouped by the length of their ac-tion history |A|. LettingAi denote the set of ac-tions taken since the ith shift action, we instead group hypotheses by the pair (i,|Ai|), where i ranges between 0 and the length of the sentence.
Let kdenote the target beam size. The search process begins with the empty hypothesis in the
(0,0) bucket. Word-level steps are then taken according to the following procedure for i = 0,1, . . ., up to the length of the sentence (inclu-sive). Beginning with the (i,0) bucket, the suc-cessors of each hypothesis are pooled together, sorted by score, and filtered down to the top k. Of those that remain, successors obtained by tak-ing an OPENor CLOSEaction advance to the(i,1)
bucket, whereas successors obtained from a SHIFT
action are placed in the(i+ 1,0)bucket ifiis less than the sentence length, or the completed list ifi
is equal to the sentence length. This process is re-peated for the(i,1)bucket, the (i,2)bucket, and so forth, until the(i+1,0)bucket contains at least
k hypotheses. If desired, a separate word beam size kw < k can be used at word boundaries, in which case each word-level step terminates when the(i+ 1,0)bucket haskw candidates instead of
k. This introduces a bottleneck that can help to promote beam diversity.
Development set results for word-level search
had
had
had
(NP (PP ... an (S (NP
... an (NP
(S ... an
(NP (VP ... an (NP (NX ... an an (NP
... (QP
an
an
an
(i,0) (i,1) (i,2) (i+ 1,0)
top-k fast-track
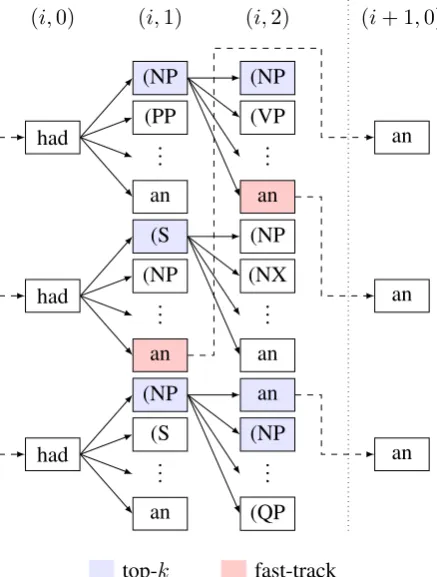
Figure 3: One step of word-level search with fast-track candidate selection (Sections5and6) for the example in Figure1. Grouping candidates by the current word i ensures that low-probability lexi-cal actions are kept separate from high-probability structural actions at the beam level. Fast-track selection mitigates competition between the two types of actions within a single pool of successors.
with a variety of beam sizes and withkw = kor
kw =k/10are given in Table1. We observe that performance in both cases increases steadily with beam size. Word-level search with kw = k/10 consistently outperforms search without a bottle-neck at all beam sizes, indicating the utility of this simple diversity-inducing modification. The top result of 92.93 F1 is already quite strong compared to other single-model systems.
6 Fast-Track Candidate Selection
The word-level beam search described in Section5
Beam Sizek 200 400 600 800 1000 2000
kw=k 91.33 92.17 92.51 92.73 92.89 93.05
kw=k/10 91.41 92.34 92.70 92.94 93.09 93.18
Table 2: Development F1 scores using the settings from Table1, together with the fast-track selection strategy from Section6withks=k/100.
together and filtered down as a single collection before being routed to their respective destina-tions. We therefore propose a more direct solution to the problem, in which a small numberks k of SHIFT successors are fast-tracked to the next
word-level bucketbeforeany filtering takes place. These fast-tracked candidates completely bypass competition with potentially high-scoring OPEN
or CLOSEsuccessors, allowing for higher-quality
results in practice with minimal overhead. See Figure3for an illustration.
We repeat the experiments from Section5with
ks=k/100and report the results in Table2. Note that the use of fast-tracked candidates offers sig-nificant gains under all settings. The top result im-proves from 92.93 to 93.18 with the use of fast-tracked candidates, surpassing prior single-model systems on the development set.
7 OPEN Action Pruning
At any point during the trajectory of a hypothesis, either 0 or all 26 of the OPENactions will be
avail-able, compared with at most 1 CLOSE action and
at most 1 SHIFTaction. Hence, when available,
OPENactions comprise most or all of a candidate’s
successor actions. To help cut down on this por-tion of the search space, it is natural to consider whether some of these actions could be ruled out using a coarse model for pruning.
7.1 Coarse Model
We consider a class of simple pruning models that condition on thec≥0most recent actions and the next word in the sentence, and predict a probabil-ity distribution over the next action. In the interest of efficiency, we collapse all SHIFT actions into
a single unlexicalized SHIFTaction, significantly
reducing the size of the output vocabulary. The inputvt to the pruning model at timetis the concatenation of a vector embedding for each action in the context(at−c, at−c+1, . . . , at−1)and a vector embedding for the next wordw:
vt= [eat−c;eat−c+1;. . .;eat−1;ew],
where eachej is a learned vector embedding. The pruning model itself is implemented by feeding the input vector through a one-layer feedforward network with a ReLU non-linearity, then applying a softmax layer on top:
P(at=a|a1, . . . , at−1,next-word=w)
=P(at=a|at−c, . . . , at−1,next-word=w)
= [softmax(W2max(W1vt+b1,0) +b2)]a.
The pruning model is trained separately from the main parsing model on gold action sequences de-rived from the training corpus, with log-likelihood as the objective function and a cross entropy loss.
7.2 Strategy and Empirical Lower Bound
Once equipped with a coarse model, we use it for search reduction in the following manner. As men-tioned above, when a hypothesis is eligible to open a new constituent, most of its successors will be obtained through OPENactions. Accordingly, we
use the coarse model to restrict the set of OPEN
actions to be explored. When evaluating the pool of successors for a given collection of hypothe-ses during beam search, we run the coarse model on each hypothesis to obtain a distribution over its next possible actions, and gather together all the coarse scores of the would-be OPEN
succes-sors. We then discard the OPENsuccessors whose
coarse scores lie below the top1−pquantile for a fixed0< p <1, guaranteeing that no more than a
p-fraction of OPEN successors are considered for
evaluation. Takingp = 1corresponds to the un-pruned setting.
This strategy gives us a tunable hyperparameter
p that allows us to trade off between the amount of search we perform and the quality of our re-sults. Before testing our procedure, however, we would first like to investigate whether there is a principled bound on how low we can expect to set
pwithout a large drop in performance. A simple estimate arises from noting that the pruning frac-tion pshould be set to a value for which most or all of the outputs encountered in the training set are retained. Otherwise, the pruning model would prevent the main model from even recreating the training data, let alone producing good parses for new sentences.
c 1 2 3 4 5 6 7 8 9 10 0 20.0 58.4 82.4 91.0 94.9 96.8 97.9 98.6 98.9 99.2 1 54.9 80.5 91.1 95.9 97.7 98.8 99.5 99.8 99.9 100.0 2 61.2 85.0 93.8 97.4 98.6 99.5 99.8 99.9 100.0 100.0
Table 3: Cumulative distributions of the number of unique OPEN outputs per input for an order-cpruning function, computed over pruning inputs with at least one OPENoutput.
p 6/26 7/26 8/26 9/26 10/26 11/26 1 Dev F1 92.78 93.00 93.08 93.13 93.19 93.19 93.18
Table 4: Results when the best setting from Sec-tion6is rerun with OPENaction pruning with
con-text size c = 2 and various pruning fractions p. Lower values ofpindicate more aggressive prun-ing, whilep= 1means no pruning is performed.
compute the number of unique OPEN actions
as-sociated with inputs occurring at least 20 times, and restrict our attention to inputs with at least one OPEN output. The resulting cumulative
dis-tributions for context sizes c = 0,1,2 are given in Table 3. If we require that our pruning frac-tion p be large enough to recreate at least 99% of the training data, then since there are 26 to-tal nonterminals, approximate2 lower bounds for pare10/26 ≈0.385forc= 0,7/26≈0.269for
c= 1, and6/26≈0.231forc= 2.
7.3 Pruning Results
We reran our best experiment from Section6with an order-2 pruning function and pruning fractions
p = 6/26, . . . ,11/26. The results are given in Table 4. We observe that performance is on par with the unpruned setup (at most 0.1 absolute dif-ference in F1 score) forpas low as8/26≈0.308. Setting p to 7/26 ≈ 0.269 results in a drop of 0.18, and settingp to 6/26 ≈ 0.231results in a drop of 0.40. Hence, degradation begins to occur right around the empirically-motivated threshold of6/26given above, but we can prune1−8/26≈ 69.2%of OPENsuccessors with minimal changes
in performance.
8 Final Results and Conclusion
We find that the best overall settings are a beam size ofk= 2000, a word beam size ofkw = 200, andks = 20fast-track candidates per step, as this
2These thresholds are not exact due to the fact that our
pruning procedure operates on collections of multiple hy-potheses’ successors at inference time rather than the succes-sors of an individual hypothesis.
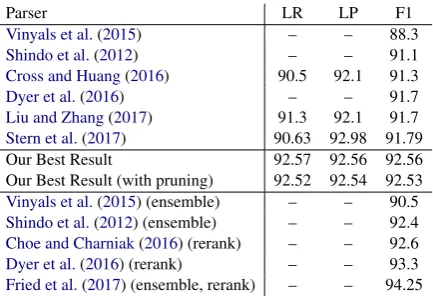
Parser LR LP F1
Vinyals et al.(2015) – – 88.3
Shindo et al.(2012) – – 91.1
Cross and Huang(2016) 90.5 92.1 91.3
Dyer et al.(2016) – – 91.7
Liu and Zhang(2017) 91.3 92.1 91.7
Stern et al.(2017) 90.63 92.98 91.79
Our Best Result 92.57 92.56 92.56
Our Best Result (with pruning) 92.52 92.54 92.53 Vinyals et al.(2015) (ensemble) – – 90.5 Shindo et al.(2012) (ensemble) – – 92.4 Choe and Charniak(2016) (rerank) – – 92.6
Dyer et al.(2016) (rerank) – – 93.3
[image:5.595.73.292.63.99.2]Fried et al.(2017) (ensemble, rerank) – – 94.25
Table 5: Comparison of F1 scores on section 23 of the Penn Treebank. Here we only include models trained without external silver training data. Re-sults in the first two sections are for single-model systems.
setup achieves both the highest probabilities un-der the model and the highest development F1. We report our test results on section 23 of the Penn Treebank under these settings in Table5both with and without pruning, as well as a number of other recent results. We achieve F1 scores of 92.56 on the test set without pruning and 92.53 when 1 −8/26 ≈ 69.2% of OPEN successors
are pruned, obtaining performance well above the previous state-of-the-art scores for single-model parsers. This demonstrates that the model ofChoe and Charniak (2016) works well as an accurate, self-contained system. The fact that we match the performance of their reranking parser using the same generative model confirms the efficacy of our approach. We believe that further refinements of our search procedure can continue to push the bar higher, such as the use of a learned heuristic function for forward score estimation, or a more sophisticated approximate decoding scheme mak-ing use of specific properties of the model. We look forward to exploring these directions in fu-ture work.
Acknowledgments
MS is supported by an NSF Graduate Research Fellowship. DF is supported by an NDSEG fel-lowship.
References
Association for Computational Linguistics and the 7th International Joint Conference on Natural Lan-guage Processing (Volume 2: Short Papers), pages 863–869, Beijing, China. Association for Computa-tional Linguistics.
Eugene Charniak. 2010. Top-down nearly-context-sensitive parsing. InProceedings of the 2010 Con-ference on Empirical Methods in Natural Language Processing, pages 674–683. Association for Com-putational Linguistics.
Do Kook Choe and Eugene Charniak. 2016. Parsing as language modeling. InProceedings of the 2016 Conference on Empirical Methods in Natural Lan-guage Processing, pages 2331–2336, Austin, Texas. Association for Computational Linguistics.
James Cross and Liang Huang. 2016. Span-based con-stituency parsing with a structure-label system and provably optimal dynamic oracles. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1–11, Austin, Texas. Association for Computational Linguistics. Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros,
and Noah A. Smith. 2016. Recurrent neural network grammars. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 199–209, San Diego, Califor-nia. Association for Computational Linguistics. Daniel Fried, Mitchell Stern, and Dan Klein. 2017.
Im-proving neural parsing by disentangling model com-bination and reranking effects. InProceedings of the 55th Annual Meeting of the Association for Compu-tational Linguistics (Volume 2: Short Papers), Van-couver, Canada. Association for Computational Lin-guistics.
James Henderson. 2003. Inducing history represen-tations for broad coverage statistical parsing. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computa-tional Linguistics on Human Language Technology-Volume 1, pages 24–31. Association for Computa-tional Linguistics.
Jiangming Liu and Yue Zhang. 2017. Shift-reduce constituent parsing with neural lookahead features. Transactions of the Association for Computational Linguistics, 5:45–58.
Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. 1993. Building a large annotated corpus of English: The Penn Treebank. Computa-tional Linguistics, 19(2):313–330.
Brian Roark. 2001. Probabilistic top-down parsing and language modeling. Computational linguistics, 27(2):249–276.
Hiroyuki Shindo, Yusuke Miyao, Akinori Fujino, and Masaaki Nagata. 2012. Bayesian symbol-refined tree substitution grammars for syntactic parsing. In
Proceedings of the 50th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1: Long Papers), pages 440–448, Jeju Island, Korea. Association for Computational Linguistics.
Mitchell Stern, Jacob Andreas, and Dan Klein. 2017. A minimal span-based neural constituency parser. In Proceedings of the 55th Annual Meeting of the As-sociation for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada. Association for Computational Linguistics.
Ivan Titov and James Henderson. 2010. A latent variable model for generative dependency parsing. In Trends in Parsing Technology, pages 35–55. Springer.