3913
HAMS, PARALLEL AVERAGE PARTITIONING
AND SORTING ALGORITHM
Ahmed Hammad Helal, Masoud E Shaheen
Abstract— Sorting is a vital operation in computer science. Sequential sorting algorithms consume much time with large data, so many attempts are headed to make these algorithms working in parallel but the main obstacle is how to divide the given data into equal partitio ns to achieve resource utilization and load balance in all processes and consume less time with load balance. This paper presents a new parallel partitioning algorithm which uses dividing large list of numbers into approximately equal partitions better than any other partitioning algorithms and then use quicksort algorithm to sort these parts in parallel depending on the average.
Index Terms—quick sort , pivot element , parallel algorithm ,Multiple program to multiple data (MPMD),Master/slave, Message Passing Interface(MPI),resource utilization , load balance .
—————————— ——————————
1 INTRODUCTION
SORTING is a mechanism that used to rearrange list’s elements according to some criteria. This operation has a vital role in computer operations as nearly Quarter of computer operations is sorting [1], and it’s considered a basic operation for other operations like searching, reading, or writing in particular [2]. There are many sorting algorithms like quick sort, insertion sort, and heap sort [3]. Quick sort algorithm, for example, is a divide and conquer algorithm that works in a sequential way as follow [4]:
1. First ,choose an element from the list as a pivot , - the pivot may be the first , the last or any
random number in the list
2. Compare the list’s elements with the pivot
3. Put the elements which are smaller than the pivot at the left of the pivot
4. Put the elements which are greater than the pivot at the right of the pivot
5. Now the pivot is at its true position
6. Repeat the previous steps recursively till the list is sorted
The sequential quick sort algorithm consumes much time while sorting a large list of numbers. So that, many efforts are headed to cause this algorithm works in parallel [5] as the pivot element divides the given list to independent unequal partitions. As a result, the main obstacle is still, which is how to divide the given data into equal partitions to achieve resource utilization and load balance in all processes. Thus, less time will be consumed as a result of load balance and resource utilization [6].
The median is the best value that divides the given list into two equal partitions [7], but it isn’t known unless the list is sorted so many attempts are done to divide the given list to approximately equal parts .
2
RELATED
WORK
2.1 Hyper Quicksort
Hyper quicksort is a parallel sorting algorithm. This algorithm partitioning depends on a median of one sub list that produced after implementing a sequential quick sort algorithm in all processes [8]. Then exchange parts of data between each coupled processes and recur the steps until each process has a sorted local sub list without overlapping.
2.2 Fast Parallel Sorting Algorithm Using Subsets and Quick Sort
Fast parallel sorting algorithm using subsets and quick sort is another parallel sorting algorithm. But this algorithm partitioning depends on maximum number in the given list, and produces the bounds of parts from the maximum number and exchange the data between processes so that every process will have a subset without overlapping and then sort these parts in parallel using sequential quicksort [9], [10].
The rest of this paper is organized as follows. Section 3 presents the proposed parallel average partitioning and sorting algorithm, Hams, and the complexity analysis of it. Section 4 shows simulation study and results. Conclusion is presented in Section 5.
3 THE
PROPOSED
ALGORITHM
"Parallel average partitioning and sorting algorithm called Hams" is a new efficient algorithm used for dividing a given list of numbers in parallel into almost equal partitions using the average of this list, then uses quick sort to sort partitioned sub lists in parallel .
Arithmetic mean (average) is calculated by summing the values of a list and dividing the result by count of the numbers in this list using equation (1).
A = (a1+a2+a3+…..+an)/n (1) Where
- A is the Arithmetic mean
- a1+a2+a3+…..+an is the summation of the numbers in the list
- n is count of number in the list[11].
The arithmetic mean may be equal to the median if the list numbers increase arithmetically but may differ slowly if not, For example, the comparison of the median and the arithmetic mean income calculated in American United States [12]. ————————————————
Computer Science Department, Faculty of Computers and
Information, Fayoum University, Egypt, [email protected]
Computer Science Department, Faculty of Computers and
Information,
Multiple program to multiple data (MPMD) model [13] is used with master /slaves style [14] to implement the algorithm.
3.1 Algorithm Steps
1. Master process opens input data file and takes the data into a main array
2. Master process divides the main array into equal sub lists and sends it to other processes
3. Every process calculates the sum of the local sub list
4. Master process gathers the sums, calculates the average, and broadcasts it to the other processes. 5. Every process divides its local sub list into two
partitions; one of them is less or equal to the average and the second is greater than the average.
6. Exchange the partitions between each two-coupled processes
7. Repeat the steps from 3 to 6 for lower half and upper half process log p times where p is the number of processes which are available to work in parallel
8. Every process sorts its local data in parallel using quick sort
9. Master process gathers the sorted data and writes it into output data file.
3.2 Communication Between Processes
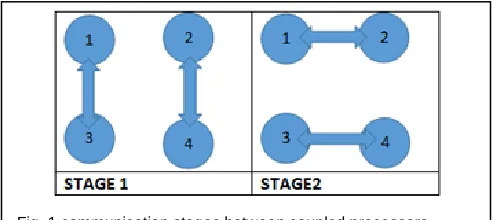
Two processes must be coupled together to exchange the data (step 6) throw the log p stages of the algorithm (step 7) So the process P[i] will be connected to another process through this relation
P[i] ↔p[i+p/c] Where
P is the number of processes, which are available to work in parallel
c= 1, 2, 3…log p
Suppose there are four processes so two communication stages between each coupled processors will exist which are presented in fig .1. In stage 1 data will be exchanged between upper half and lower half of processes after choosing the first average, and in stage 1 data will be exchanged in every half of the processes as the same in stage 1 after choosing the second average .
3.3 Complexity Analysis
Assume that input data file has n elements of numbers to be
sorted and available p processes
Calculate the average =O ((n/p)* log (p)) (2)
Comparison for Dividing into two sub lists using average= O ((n/p)* log (p))
(3)
Exchange sub lists = O ((n/2*p)* log (p)) (4) Quick sort for local sub list =O ((n/p)*log (n/p)) (5)
3.4 Case Study
Suppose there are four processes that can work in parallel and an input data file that has data as shown in fig .2.
1. The process 1 reads these data into a main array, divide into four sub lists.
2. Every process receive an equal sub list.
3. Every process calculates the sum of its sub list and send it to process 1.
4. Process 1 calculates the average of sums and broadcast it.
5. Every process divides its sub list into two parts one less or equal to the average and the other one is greater than the average.
6. Each two-coupled processes exchange the parts. 7. Every process calculates the sum of its sub list
and send it to its coupled process.
Every coupled process calculate its new average and share it.
8. Every process divides its sub list into two parts one less or equal to the new average and the other is greater than this average.
9. Each two-coupled processes exchange the parts. 10. Each process sorts its sub list without overlapping
in parallel.
11. Now data can be gathered from processes in one output file.
4 RESULTS
C++ programming language with MPI [15] was used to implement Hams, Fast parallel quick sort parallel sub row and hyper quicksort algorithms on a virtual machine with a four cores processor with 2.1 GHz and five-gigabyte RAM.
The experiment was made on 1000, 10000 and 100000 numbers with a range from 0 t 1000000, these numbers are generated randomly using the uniform_int_distribution class and the generated numbers were saved in the input file then sort them in an ascending order using four processes . The result of partitioning compared with optimal partitioning as below:
4.1 input file has 1000 numbers
Fig.3 shows that Hams algorithm is the nearest to the optimal partitioning in all processes with standard division 7.78 followed by hyper quicksort algorithm [Hyper] with standard division 51.62. Followed by Fast Parallel Sorting Algorithm using Subsets and Quick Sort [Max] with standard division 96.17 but Max has better partitioning in processes 2and 3 than Hyper as shown in table 1.
3915 4.2 input file has 10000 numbers
fig .4 shows that Hams algorithm is the nearest to the optimal partitioning in all processes with standard division 7.07, followed by hyper quicksort algorithm [Hyper] with standard division 105.36 followed by Fast Parallel Sorting Algorithm Using Subsets and Quick Sort [Max] with standard division 318.91 but Max has better partitioning in processes 2and 4 than Hyper as shown in table 2.
4.3 input file has 100000 numbers
Fig .5 shows that Hams algorithm is the nearest to the optimal partitioning in all processes with standard division 323.15, followed by hyper quicksort algorithm [Hyper] with standard division 1814.42 followed by Fast Parallel Sorting Algorithm using Subsets and Quick Sort [Max] with standard division 3905.35 but Max has better partitioning in processes 1 ,2 and 3 than Hyper as shown in table 3 .
TABLE 1
1000 NUMBERS PARTITIONING WITH VARIANCE AND STANDARD DIVISION FROM OPTIMAL PARTITIONING
TABLE 2
10000 NUMBERS PARTITIONING WITH VARIANCE AND STANDARD DIVISION FROM OPTIMAL PARTITIONING
Fig. 2 recursive sorting using HAMS algorithm
Fig. 3 1000 numbers partitioning
4.4 input file has a real data of 831308 numbers
Moreover, the algorithm was applied to sort Ascending Total Compensation column of a real data of the salary and benefits paid to The San Francisco employees with the file version updated on 09.05.2019, which has 831308 row [16].
The result of partitioning comparing with optimal partitioning were as in fig .6 and table 4.
fig .6 shows that Hams algorithm is the nearest to the optimal partitioning in processes 1,3,4 with standard division 69122, followed by hyper quicksort algorithm [Hyper] with standard division 106582 followed by Fast Parallel Sorting Algorithm
Using Subsets and Quick Sort [Max] with standard division 548086.2 as shown in table4 . Hyper is nearer to Optimal partitioning than max in all processes and than Hams in process 2 .
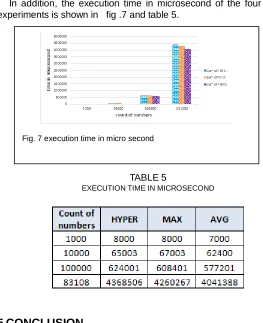
In addition, the execution time in microsecond of the four experiments is shown in fig .7 and table 5.
5
CONCLUSION
Optimal data partitioning is the best way to achieve resource utilization and load balance, in this paper a new partitioning algorithm depends on average called Hams algorithm achieve the nearest data partitioning to optimal partitioning with less standard division and less execution time than Fast parallel quick sort parallel sub row and Hyper quicksort using random generated data and real data.
REFERENCES
[1] Knuth D., The art of computer programming, V3. Sorting and Searching, Addison Wesley Publishing Company, 1973.
[2] R. Kaushal, Why Sorting is So Important in Data Structures, International Journal for Scientific Research & Development| Vol. 5, Issue 07, 2017
[3] Gary Pollice, Stanley Selkow, George T. Heineman, Algorithms in a Nutshell, O'Reilly Media, Inc,2008
[4] C.A.R. Hoare, Quicksort, Computer Journal, Vol. 5, 1, 10-15(1962)
[5] Addison Wesley, Introduction to Parallel Computing, Second Edition (2003)
[6] F.Ali, R.Zaman Khan, THE STUDY ON LOAD BALANCING STRATEGIES IN DISTRIBUTED COMPUTING SYSTEM, International Journal of Computer Science & Engineering Survey (IJCSES) Vol.3, No.2, April 2012
[7] .Medhi , Statistical Methods: An Introductory Text , New Age International. pp. 53–69,1992
[8] M. J. Quinn, Parallel Programming in C with MPI and TABLE 3
100000 NUMBERS PARTITIONING WITH VARIANCE AND STANDARD DIVISION FROM OPTIMAL PARTITIONING
TABLE 5
EXECUTION TIME IN MICROSECOND
TABLE 4
TOTAL COMPENSATION COLUMN PARTITIONING WITH VARIANCE AND STANDARD DIVISION FROM OPTIMAL PARTITIONING Fig. 5 100000 numbers partitioning
Fig. 6 Total Compensation column partitioning
3917 OpenMP, Tata McGraw Hill Publications, 2003, p. 338.
[9] Bosakova-Ardenska A., Vasilev N., Kostadinova-Georgieva L., Fast Parallel Sorting Algorithm using Subsets and Quick sort, Balkan Journal of Electrical & Computer Engineering, 2015, Vol.3, No.1, ISSN: 2147-284X, pp.27-29
[10] A. Bosakova-Ardenska , A.Miroslav, IMPLEMENTATION OF FAST PARALLEL SORTING ALGORITHM WITH C AND MPI, INTERNATIONAL SCIENTIFIC CONFERENCE 18 – 19 November 2016, GABROVO
[11] J.Medhi , Statistical Methods: An Introductory Text , New Age International. pp. 53–59,1992
[12] P. Krugman, The Rich, the Right, and the Facts: Deconstructing the Income Distribution Debate , The American Prospect,2014
[13] C.Chang† , G. Czajkowski† , T.v.Eicken† , and C.Kesselman,‖Evaluating the Performance Limitations of MPMD Communication‖,proc,ACM/IEEEsupercomuting .pp.1.Nov.1997
[14] Rouse, M. (2008). What is master/slave? – Definition from WhatIs.com. [online]
[15] searchnetworking.techtarget.com. Available at: http://searchnetworking.techtarget.com/definition/master-slave
[16] M.snir,s>.olto,S.Huss-lederman,D.Walker and J.Dongarra ,MPI the complete reference ,MIT press ,Cambridge ,MA,USA,1996