Servicing Seismic and Oil Reservoir
Simulation Data
through Grid Data Services
Sivaramakrishnan Narayanan, Tahsin Kurc,
Umit Catalyurek and Joel Saltz
Multiscale Computing Lab
Biomedical Informatics Department The Ohio State University
Joel Saltz Gagan Agrawal Umit Catalyurek Shannon Hastings Vijay S Kumar Tahsin Kurc Steve Langella Scott Oster Tony Pan Benjamin Rutt Narayanan Sivaramakrishnan, Li Weng Michael Zhang
Multiscale Computing Lab
Analysis
Production rates, bypass oil, net present value
Workflow
Run new reservoir simulations
Data
Seismic, well pressures, reservoir
simulations
Generate requests for new simulations, new
seismic studies
Obtain initial, boundary conditions,
input parameters for simulations Store and index simulation results Summary data from datasets Spatio-temporal queries • Simulate multiple realizations of multiple geostatistical models and production strategies
• Evaluate geologic
uncertainty and production strategies simultaneously • Enable on-demand
exploration and comparison of multiple scenarios
– Integration of a robust, Grid-based computational and data handling
infrastructure
– Distributed databases of reservoir and
geophysical data
– Storage and computing resources at multiple institutions
Characteristics and Issues
• Spatio-temporal datasets
– Simulations carried out/data captured on 3D meshes over many time steps
– Multiple data attributes per data point (gas pressure, oil saturation, seismic traces, etc).
• Very large datasets
– Tens of gigabytes to 100+ TB data
• Lots of simulation runs
– Up to thousands of runs for a study are possible
• Data can be stored in distributed collection of files
• Distributed datasets
– Data may be captured at multiple locations by multiple groups – Simulations are carried out at multiple sites
• Common operations: subsetting, filtering, interpolations,
projections, comparisons, frequency counts
Data Management, Access and Integration
• Tracking of metadata associated with data
– Metadata defining simulation parameters, mesh description, files associated with simulations, etc.
– Metadata defining seismic measurements (location, year, files storing data, etc.)
• Support for data subsetting and filtering on
file-based, distributed datasets
• Support for on-demand data product generation
– Track metadata associated with data analysis workflows
• Grid data services and distributed querying
– Make data and data products available through Grid service interfaces
Applications developers generally prefer storing data in files
Support high level queries on multi-dimensional distributed
datasets
Many possible data abstractions, query interfaces
Grid virtualized object-relational database or XML database Grid virtualized objects with user defined methods invoked to
access and process data
Data Virtualization
Our Approach
• Support a basic SQL Select query with a virtual relational table view or a virtual XML database view
• A lightweight layer on top of datasets
Middleware Support
• Data Virtualization: STORM
– Large data querying capabilities, layered on DataCutter – Distributed data virtualization
– Indexing, Subsetting, Data Cluster/Decluster, Parallel Data Transfer
• Data Analysis/Processing Workflows: DataCutter
– Component Framework for Combined Task/Data Parallelism
– Filtering/Program coupling Service: Distributed C++ component framework
– On demand data product generation
• Distributed Metadata and Data Management: Mobius
– Create, manage, version data definitions – Management of metadata and data instances – Data integration
• Grid Data Services (OGSA-DAI)
– Defines services and interfaces that can be used by clients to specify operations on data resources and data
Data Management, Access, Integration
• Grid-level data services via OGSA-DAI • Management of data definitions and
metadata, XML virtualization via Mobius
• Object-relational virtualization and subsetting of file based datasets via STORM
• On-demand data product generation via DataCutter
• STORM, Mobius, DataCutter support data operations on heterogeneous collections of storage and compute clusters Schema Management Mobius Data Product Generation DataCutter SQL Virtualization of Files STORM XML Virtualization Metadata Management Mobius OGSA-DAI OGSA-DAI OGSA-DAI OGSA-DAI Grid Protocols
Data Management, Access, and Integration
Schema Management Mobius Data Product Generation DataCutter SQL Virtualization of Files STORM XML Virtualization Metadata Management MobiusGrid-data Service (OGSA-DAI) Grid-data Service (OGSA-DAI)
Data Product Generation DataCutter SQL Virtualization of Files STORM XML Virtualization Data Product Generation DataCutter SQL Virtualization of Files STORM XML Virtualization Metadata Management
Grid-data Service (OGSA-DAI) Grid Service
Protocols Grid-data Service
(OGSA-DAI)
Array # Component # Component # Component # Sp (or CDP) # & position Receiver group # & position Receiver group # & position Receiver group # & position 50. 00 50. 00 50 .00 Component # Component # Component # Array # Receiver group # & position Receiver group # & position Receiver group # & position 50 .00 50 .00 5 0.00 Component # Component # Component # Array # Receiver group # & position Receiver group # & position Receiver group # & position 50.00 50.00 50.0 0
Data Querying and Processing
Seismic Data
Geostatistics Model 1 Model 2 Model n … … m realizations Well Pattern p Production Strategies Well Pattern 1 … Well Pattern 2Reservoir Simulations
STORM
Support efficient selection of the data of interest from
distributed scientific datasets and transfer of data
from storage clusters to compute clusters
• Data Subsetting Model
– Virtual Tables – Select Queries – Distributed Arrays
SELECT <DataElements>
FROM Dataset-1, Dataset-2,…, Dataset-n
WHERE <Expression> AND <Filter(<DataElement>)>
STORM Services • Query • Meta-data • Indexing • Data Source • Filtering • Partition Generation • Data Mover
Grid Data Resource
• Grid has emerged as an integrated infrastructure for distributed computation
• OGSA-DAI initiative is to deliver high level data management functionality for the Grid.
– Defines services and interfaces that can be used by clients to specify operations on data resources and data
• OGSA-DAI services can be configured to expose a specific database management system.
• To be a GDS, a service must accept perform documents and return results
– Interpretation of perform documents is open to interpretation – Traditionally wrap SQL queries
STORM Data Resource
Extractor Filter Data Mover Storm Daemon JDBC Driver GDS STORM instance Data ResourceExperimental Setup
• All nodes running linux • Gigabit switch 7.3 TB FAStT600 disk array 4 GB memory 2 Xeon 2.4 GHz 16 Xio 1.5 TB local disk 8 GB memory Dual 1.4 GHz AMD Optron 8 nodes mob Mob,01 24 * X / 1M X 24 bytes 6 TXm Xio,16 1,056 247 4240 bytes 16 Seismic Mob,03 315 3,840 84 bytes 21 Oil Reservoir Cluster, Num nodes Dataset (GB) Records (millions) Record Size Attributes Dataset
STORM Results
STORM I/O Performance
0 500 1000 1500 2000 2500 3000 3500 4000 4500 1 2 4 8 16 # XIO nodes B and w idt h ( M B /s ) 2 Threads 4 Threads Max
Seismic Datasets
10-25GB per file.
About 30-35TB of Data.
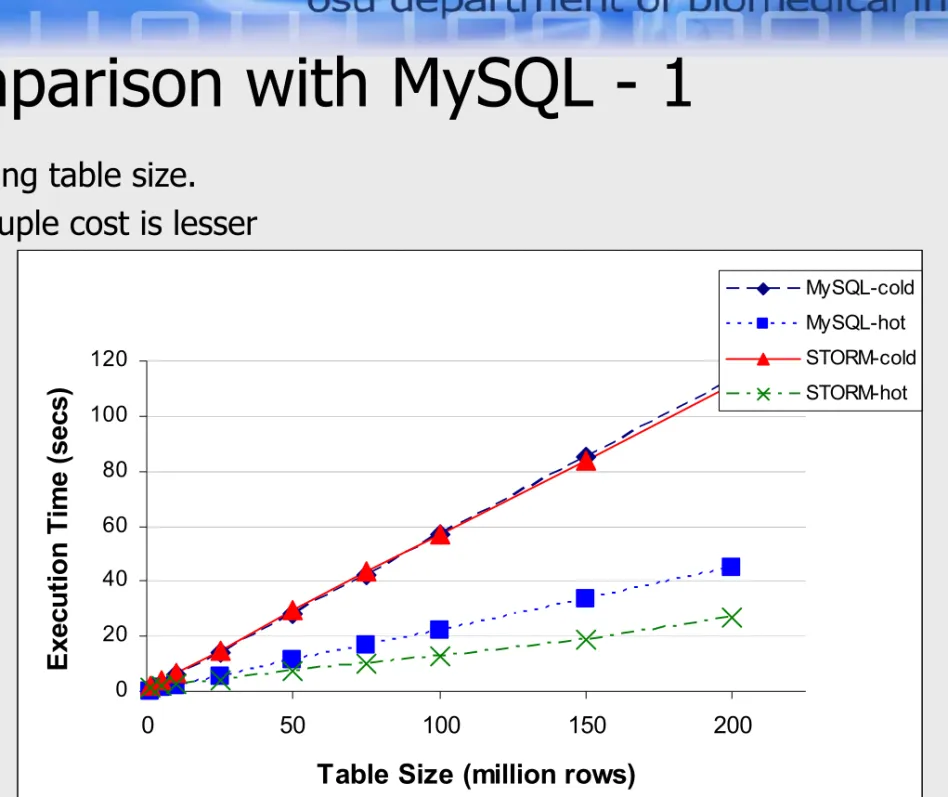
Comparison with MySQL - 1
• Varying table size. • Per tuple cost is lesser
0 20 40 60 80 100 120 0 50 100 150 200
Table Size (million rows)
E xe cut ion Tim e ( se cs ) MySQL-cold MySQL-hot STORM-cold STORM-hot
Comparison with MySQL - 2
• Varying query size
• Also compare them as data resources
0 10 20 30 40 0 250000 500000 750000 1000000
Query Size (num of records)
Ex ec u ti o n T im e (s ec s) MySQL STORM MySQL-DAI STORM-DAI
Oil Reservoir Data Results
• Improvements due to: treating records as array of bytes, combining results at client 0 40 80 120 160 0 100000 200000 300000 400000
Query Size (number of records)
E xe cut ion Tim e ( se cs ) STORM STORM-DAI-o STORM-DAI-1 STORM-DAI-50 3 DAIs
Seismic Data Results
0 10 20 30 40 50 0 2000 4000 6000 8000 10000 12000 14000Query Size (number of records)
E xecu ti o n T ime ( secs) STORM STORM-DAI-o STORM-DAI-1 2-DAIs • 96 x 11GB files on 16 nodes
Conclusions
• Overview of work related to Large Scale Scientific Data
Management at Multi-Scale Computing Lab
• Exposed STORM as a Grid Data Service
– Results on use case: Oil reservoir management
• For more info / to download STORM, DataCutter, Mobius
http://www.multiscalecomputing.org
or