Almost Unsupervised Content Filtering Using Topic
Models
Swapnil Hingmire
∗ Tata Research Developmentand Design Centre Pune, INDIA
[email protected]
Sandeep Chougule
Tata Research Developmentand Design Centre Pune, INDIA
[email protected]
Girish K. Palshikar
Tata Research Developmentand Design Centre Pune, INDIA
[email protected]
Sutanu Chakraborti
Indian Institute of Technology (IIT), Madras
Chennai, INDIA
[email protected]
ABSTRACT
One important way to help users deal effectively with docu-ment repositories is to automatically filter out those parts of the documents which are irrelevant to his/her goal at hand. While such a goal-driven content-filtering system is an ambi-tious target, we propose an almost unsupervised approach to separate useless (irrelevant) sentences in a document from useful (relevant) sentences. We automatically construct a topic model using a standard algorithm [2], manually divide the topics into useful and useless, then aggregate all useful topics into a single useful topic and all useless topics into a single useless topic and then automatically assign a label, “useful” or “useless” to each sentence, depending on whether it is “closer” to the aggregated useful or useless topic. We illustrate the approach on a real-life dataset of IT infrastruc-ture support (ITIS) tickets containing highly noisy problem descriptions and solutions to remove all sentences not rele-vant as solution steps. We experimentally demonstrate that our results, apart from requiring minimal user intervention, improve over other content-filtering approaches. The ap-proach can be generalized to remove useless sentences (from any perspective) from other types of documents.
Categories and Subject Descriptors
H.3.3 [Informational Storage and Retrieval]: Infor-mation Search and Retrieval—Information filtering; I.2.7 [Artificial Intelligence]: Natural Language Processing— Text analysis; I.5.4 [Pattern Recognition]: Applica-tions—Text processing
∗Research scholar at Indian Institute of Technology (IIT),
Madras, Chennai, India
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
AND’12 Mumbai, India,
Copyright 2012 ACM 978-1-4503-1919-5/12/12 ...$10.00.
General Terms
Theory, Performance, Experimentation, Verification
Keywords
Information Filtering, Text Mining, Noisy Text, Topic Mod-elling
1.
INTRODUCTION
With the advent of cheap and fast storage, there is an ex-plosive growth in the size and number of documents available in enterprise document repositories. An important part of text-mining is helping users make effective use of the knowl-edge and insights hidden in a large collection of complex documents. Techniques such as corpus visualization, topic modelling, document clustering, classification, summariza-tion, key-phrase identification are different approaches to-wards this end.
One important way to help the user deal effectively with a given document is to automatically filter out those parts of the given document(s) which are irrelevant to his/her goal or task at hand. These irrelevant parts in the document consti-tute noise, as far as the reader’s specific goal is considered. Thus, identifying irrelevant text for a given document anal-ysis goal can be considered as a problem of handling a new category of noise.
As an example, when analyzing a news item about an ac-cident, the reader may want to focus only on the different descriptions of the accident (e.g., as stated by the driver(s), passengers, witnesses or police). Or else, the reader may just want to read about the rescue actions taken (e.g., by-standers, police, fire-brigade etc.). In a help-desk applica-tion, the user may just want to focus on either the symp-toms, root-causes or solution actions taken for a particular problem (e.g., in a previously solved ticket for the problem “unable to print a WORD document”). Table 1 shows an example.
PROBLEM: Need new id file and password for Lotus Notes
SOLUTION: [User was getting the message -You are not authorised to access the database- upon clicking on the MAIL Icon on the welcome page.]symptoms
[Rea-son incorrect mail file location in the connection doc-ument. user had the connection document of a dif-ferent user selected.]diagnosis [created a new
connec-tion document.]solution [user was able to access the
mails.]outcome [Resolving the ticket with the user’s
per-mission. Please provide your valuable feedback before closing the ticket.]noise
Table 1: An example help-desk ticket containing the user’s problem and the resolver’s solution.
While such a goal-driven content-filtering system is an am-bitious target, we propose a simple approach to separate useless (irrelevant) sentences in a document from useful (rel-evant) sentences. For clarity, we focus on documents that contain highly noisy problem descriptions and solutions for IT infrastructure support (ITIS) tickets. The useful sen-tences are those that contain actions that solve the user’s problem; we consider all other types of sentences as useless. The approach can be easily generalized to remove useless sentences (from any perspective) from other types of docu-ments.
The main motivation for this work is the automatic construc-tion of runbooks (also called troubleshooting or problem solving manuals) from large datasets of such ITIS tickets. This is a well-known problem [7]. Such a runbook contains a sequence of well-organized and unambiguous steps that can be carried out by the support executive. Such runbooks codify extensive problem-solving knowledge obtained from experience (e.g., past tickets handled) and help in improving the productivity of the support executives and allow them to efficiently solve many tickets requiring different skills and backgrounds.
We are doing content filtering using almost unsupervised text classification. The central idea in our content filtering approach is to construct automatically a topic model using a standard algorithm [2], then manually divide the topics into useful and useless, then aggregate all useful topics into a single useful topic and all useless topics into a single useless topic and then automatically assign a label, “useful” or “use-less” to each sentence, depending on whether it is “closer” to the aggregated useful or useless topic.
We illustrate the approach on a real-life dataset of ITIS tick-ets. Our experiments demonstrate that our results, apart from requiring minimal supervision, are better than some other approaches.
The paper is organized as follows. Section 2 reviews the re-lated work. In section 3, we review dimensionality reduction and topic modelling. Section 4 contains our sentence filter-ing algorithm. In section 5, we demonstrate the effectiveness of our approach with experiments on real world data. We end our paper with conclusions and future prospects for our work in section 6.
2.
RELATED WORK
In this section we review related work in Case Based
Rea-soning (CBR), noisy text analysis and text classification us-ing unsupervised and semi-supervised techniques.
Case Based Reasoning (CBR): CBR is a widely used technique for knowledge management in help desk [7]. Most of these systems have manually created case bases. A suc-cessful CBR system requires a high quality case base, which provides rich and efficient solutions for solving real world problems [22]. Creating a case base of CBR system can be challenging if the problem solving experiences are captured as unstructured or semi-structured text [21, 23]. Our filter-ing approach can be used to create a high quality case base from noisy and unstructured ITIS tickets.
Noisy text analysis: Subramaniam et al. [19] survey different types of text noise and techniques to handle the noise. They have defined “noise” as any kind of difference in the surface form of an electronic text from the intended, correct or original text. Agarwal et al. [1] study the effect of different kinds of noise on automatic text classification. Usually a noisy text contains spelling errors, abbreviations, non standard words, false starts, repetitions, missing punc-tuations, missing letter case information, pause-filling words etc. [1]. Apart from the noise as defined above, we assume that text which is meaningless, useless, unwanted, off-topic and irrelevant with respect to a specific goal is also noise.
Noisy text analysis in help desk domain: Mishne et al. [15] introduced a method of estimating the domain-specific importance of conversation fragments, based on di-vergence of corpus statistics. They computed the signifi-cance level of a text fragment by combining the importance of each word in the fragment. Importance of a word is computed by comparing the frequency of the word in the domain-specific corpus to its frequency in an open-domain corpus using a statistical test for distribution difference such as χ2 or log likelihood measures. In this approach,
impor-tance of a word depends on the open domain corpus used for analysis.
Takeuchi et al.[20] proposed aχ2 statistic based technique
to find effective expressions from text segments. This ap-proach needs labeled dataset of effective and non-effective expressions.
Unsupervised text classification using labeled and unlabeled documents: Blum et al. [3] proposed a co-training method to build a text classifier from la-beled and unlala-beled documents. Nigam et al.[16] defined an algorithm for text classification from labeled and unla-beled documents based on the combination of Expectation-Maximization (EM) and a naive Bayes classifier. However, our approach does not require any labeled dataset.
Unsupervised text classification using keywords: Ko et al. [12] proposed a text classification method based on un-labeled documents and the title word of each category. In the first step of this method, documents are labeled using a bootstrapping technique, and in the second step, a feature projection technique is used to build a robust text classifier. McCallum et al. [14] described an approach to build a clas-sifier by labeling keywords on unlabeled dataset. Initially a small set of keywords from each class are used to assign approximate labels to unlabeled documents by term match-ing. These preliminary labels become the starting point for a bootstrapping process that learns a naive Bayes classifier using EM and hierarchical shrinkage.
is used to retrieve a set of positive documents from the un-labeled documents. In the second step, these positive doc-uments are used to extract more positive docdoc-uments from the unlabeled documents. In the third step, these positive and unlabeled documents are used to build a text classifier. This approach requires WordNet and a search engine. As WordNet has limited coverage, it might not be suitable for domains like help desk.
The approach defined in Qiu et al.[18] is similar to [17] and it differs in the first step where, a set of keywords is used to retrieve a set of related pages from Wikipedia. These Wikipedia pages are used in the second step. This approach requires access to Wikipedia and Wikipedia may not be suit-able to certain domains like help desk.
In the keyword based approaches discussed above, the key problem is to find the right sets of keywords for each class. One solution to this problem is to ask a user to provide a list of keywords. But it is difficult for the user to analyze the dataset and provide a complete list of keywords. Liu et al. [13] proposed an approach which uses hard clustering and feature selection techniques to assist the user to select keywords, and then it builds a text classifier using EM and naive Bayes algorithm.
We observed that the dataset contains words with polysemy (same word with different meanings). Also, importance of a word depends on its context. So while creating the list of keywords it is necessary to consider the context of each word.
In our approach, the topics learnt after the construction of a LDA based topic model, perform soft clustering on the documents and provide theircompact and interpretable rep-resentation. The topics capture contextual information of words, so it is easy for the user to find the most proba-ble words (keywords) along with their disambiguation. The results of LDA are presented in the form of probabilities, and thus can be directly incorporated into other probabilis-tic models and analyzed with standard statisprobabilis-tical techniques [4].
3.
DIMENSIONALITY REDUCTION AND
TOPIC MODELLING
In this section we review dimensionality reduction and topic modelling.
The Bag-of-words (BOW) representation of documents is widely used in text analysis. It has a very high dimension-ality. Also it does not capture polysemy and synonymy. A dimensionality reduction technique identifies lower dimen-sional representation of original documents and it also pre-serves important properties of the documents like similarity between documents. There are two important techniques of dimensionality reduction for documents: 1. Latent semantic indexing (LSI)[5] 2. Probabilistic topic models ([2], [10]).
3.1
Latent semantic indexing (LSI)
LSI is based on the Vector Space Model (VSM). VSM is an algebraic model based on the term-document matrix. LSI uses singular value decomposition (SVD) of the term-document matrix to project both the term-documents and terms into a lower dimensional space of concepts.
The concepts derived from LSI are difficult to interpret; they are expressed in the form of numbers so that they can not be mapped into natural language concepts. Also, these
con-cepts are unable to handle polysemy. LSI assumes that term count follows a Gaussian distribution. This assumption is hard to justify. So, LSI isad-hoc[11].
3.2
Probabilistic topic models
There are two important probabilistic topic models: 1. Probabilistic latent semantic indexing (pLSI)[10] 2. Latent Dirichlet Allocation (LDA) [2].
Probabilistic latent semantic indexing (pLSI)[10] is a prob-abilistic formulation of latent semantic indexing. Training a pLSI model on a document collection requires a large num-ber of parameters and it does not allow modelling of unseen documents.
Latent Dirichlet Allocation (LDA)[2] is an unsupervised gen-erative probabilistic model for collections of discrete data such as text documents. LDA has better modelling flexi-bility than pLSI. As compared to pLSI, LDA requires fewer parameters to be learned. Also, it can be used to infer topics for unseen documents. Crain et al. [4] provide a good survey of dimensionality reduction and topic modelling techniques.
3.3
Latent Dirichlet Allocation (LDA)
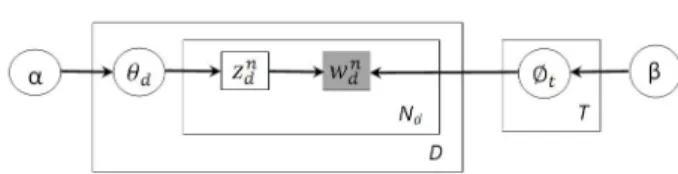
Figure 1: Diagram of the LDA graphical model
Figure 1 shows the graphical model of LDA. Generative process of LDA in figure 1 for documentdcan be interpreted as follows:
(Refer table 2 for description of notations used in this pa-per.)
1. fort= 1...T
(a) Select the word probabilities for topict:
φt∼Dirichlet(β)
2. for each documentd∈D
(a) Select the topic distribution for documentd:
θd∼Dirichlet(α)
(b) for each wordwat positionnind
i. Select the topic: zn
d ∼M ultinomial(θd)
ii. Select the word: wnd ∼M ultinomial(z n d)
Training an LDA model involves estimation of the word-topic distributions Φ and the word-topic distributions Θ for each documentdin the training corpus. The empirical likelihood
` of the training documents under a given LDA model is computed as:
`=
ND
Y
d=1 Nd
Y
n=1
p(wnd|z n d,Φ)p(z
n
d|θd)p(θd|α)p(Φ|β) (1)
D ={d} The set of all documents in the corpus
ND The number of documents in the corpus
Nd The number of words in documentd
W ={w} The set of all unique words in the corpus V The number of all unique words in the corpus T The number of topics specified as a parameter Z ={z} The set of all the topics
α The parameters of topic Dirichlet prior
β The parameters of word Dirichlet prior
wn
d The word at positionnin the documentd
znd The topic assigned to the word at positionnin the documentd
z¬dn The topics assigned to all words in the documentdexcept the word at positionn
ψw,t The count of wordwassigned to topict
Ωt,d The count of the topictassigned to some wordwin documentd
φt The word probabilities for topict
φw,t The probability of the wordwassigned to the topict
θd The topic probability distribution for documentd
θt,d The probability of the topictassigned to the documentd
Φ ={φw,t} The word-topic distributions for all words inW over all topicsZ
Θ ={θt,d} The topic-document distributions for all topics inZ over all documents inD
Table 2: Key notations
Gibbs sampling is a form of Markov Chain Monte Carlo (MCMC) technique. In Gibbs sampling, initially random values are assigned to each variable and then while sam-pling, each variable is conditioned on values of other vari-ables. The sampling process is executed until the sampled values approximate the target distribution.
In Collapsed Gibbs sampling, certain variables are marginal-ized out of the model. Griffiths and Steyvers [8] propose this sampling method for LDA in which both Θ and Φ are marginalized.
In this method, the probability p(znd = t) i.e. the topict
being assigned to the wordw∈W at the positionnin the documentdis conditioned on all other topic assignments to other words inW andα,β.
p(znd =t|z
¬n
d , w, W) =
ψw,t+βw−1
P
v∈W
ψv,t+βv
−1
× Ωt,d+αt−1 T
P
i=1
Ωi,d+αi
−1 (2)
where,
z¬dn= Nd
[
i=1&i6=n
zdi (3)
After performing Collapsed Gibbs sampling for LDA, word-topic distributions Φ and word-topic-document distributions Θ are computed as:
φw,t=
ψw,t+βw
P
v∈W
ψv,t+βv
(4)
θt,d=
Ωt,d+αt
T
P
i=1
Ωi,d+αi
(5)
3.4
The Dirichlet distribution
The Dirichlet distribution is defined as:
p(θ|α) = Γ(
T
P
t=1
αt)
T
Q
t=1
Γ(αt) T
Y
t=1
θαt−1
t (6)
where,θ={θ1, ..., θt, ..., θT}is a point on the (T−1) simplex
(i.e. 0< θt<1 andPTt=1θt= 1) andα= (α1, ..., αt, ..., αT)
is a set of parameters withαt>0. So,
θ= (θ1, ..., θt, ..., θT)∼Dirichlet(α1, ..., αt, ..., αT) (7)
Aggregation property of the Dirichlet distribution:
The Dirichlet distribution has a useful fractal like prop-erty called aggregation propprop-erty of the Dirichlet distribu-tion. It is defined as follows: The aggregation of any subset of Dirichlet distribution variables yields a Dirichlet distribu-tion, with corresponding aggregation of the parameters. If
{A1, A2, ..., Ar}is a partition of{1,2, ..., T}then,
θ0= ( P
t∈A1 θt, P
t∈A2
θt, ..., P t∈Ar
θt)
∼Dirichlet( P
t∈A1 αt, P
t∈A2
αt, ..., P t∈Ar
αt) (8)
Let Dirichlet(α1, α2, ..., α6) be the Dirichlet distribution
over six-sided dice with α ∈ <6
+. To compute the
prob-ability of rolling an odd number versus the probprob-ability of rolling an even number, aggregate (α1+α3+α5) intoαodd
and (α2+α4+α6) into αeven using the aggregation
prop-erty of the Dirichlet distribution. This aggregation yields the Dirichlet(αodd, αeven) over two event sample space of
odd versus even. The aggregation property of the Dirichlet distribution is explained and proved in detail in [6].
4.
SENTENCE FILTERING
In this section, we describe our sentence filtering algo-rithm.
sampling for LDA, “T” number of topics are learnt such thatZ ={z1, z2, ..., zT}. Now an expert will assign a label
to each topiczi∈Z as either “useless” or “useful”. Create
Z0={Z1, Z2}as a partition ofZsuch thatZ1={zi|z i∈Z
andziis useful}andZ2={zi|zi∈Zandziis useless}.
If for a documentdin the corpusD,
θd = (θ1,d, θ2,d, ..., θT ,d) ∼ Dirichlet(α1, α2, ..., αT) then
using the aggregation property of the Dirichlet distribution, defineθ0das:
θd0 = ( P zt∈Z1
θt,d, P zt∈Z2
θt,d)∼Dirichlet( P zt∈Z1
αt, P zt∈Z2
αt)
(9) Initialize Φ0and Θ0 using following equations:
ψw,Z1 = P
t∈Z1
[ψw,t+βw] ψw,Z2= P
t∈Z2
[ψw,t+βw]
(10)
φ0w,Z1 =
ψw,Z1
P
v∈W
ψv,Z1
φ0w,Z2 =
ψw,Z2
P
v∈W
ψv,Z2
(11)
ΩZ1,d=
P
t∈Z1
[Ωt,d+αt] ΩZ2,d=
P
t∈Z2
[Ωt,d+αt] (12)
θ0Z1,d=
ΩZ1,d
ΩZ2,d+ΩZ1,d θ
0
Z2,d=
ΩZ2,d
ΩZ2,d+ΩZ1,d (13)
Using Collapsed Gibbs sampling for LDA, update Φ0 and Θ0.
A sentenced∈Dis “useful” if θZ1,d> θZ2,dotherwise it is
“useless”. Remove all “useless” sentences from D. Now D
will contain only “useful” sentences. Algorithm for sentence filtering is described in algorithm 1.
Algorithm 1:Filtering useless sentences
input : D ={d}: A set of sentences
output: Useful sentences inD 1 begin
2 Learn “T” number of topics onDsuch that:
Z={z1, z2, ..., zT};
3 Compute Φ and Θ using equations 4 and 5 ;
4 Create a partitionZ0={Z1, Z2}such that:
Z1={zi|zi∈Z andziis useful}and
Z2={zi|z
i∈Z andziis useless};
5 Initialize Φ0 and Θ0using equations in 11 and 13 respectively;
6 Update Φ0 and Θ0using Collapsed Gibbs sampling;
7 ford∈D do
8 InferθZ1,d andθZ2,dusing equation 13;
9
dlabel=
useful if θZ1,d> θZ2,d
useless otherwise
(14)
10 end
11 Remove∀d∈Dsuch thatdlabel=useless;
12 end
5.
EXPERIMENTAL EVALUATION
In this section, we evaluate our proposed approach. We compare our approach with the following approaches: 1. Sentence filtering using labeled and unlabeled sentences with EM (EM LU) [16], 2. Sentence filtering using keywords and EM (EM keywords) [14] and 3. Clustering based sentence filtering.
5.1
Dataset
The dataset used for our experiments was collected from TCS Global Help Desk (GHD). Initially, we collected all so-lutions of“Lotus Notes”related problems from GHD. These solutions are then segmented into sentences. Using these segmented sentences, we created a corpus of 996 randomly selected sentences. We then manually labeled these sen-tences as either “useful” or “useless”. We represent our dataset as C = {c1, c2} where, c1 is the set of all useful
sentences andc2 is the set of all useless sentences.
5.2
Evaluation measure
We evaluated effectiveness of our approach by computing the Macro F-measure (F1). Though accuracy is a widely
used measure to evaluate a classifier, it is not suitable when-ever there is class imbalance. F1 of classci∈Cis harmonic
mean of the precision and recall values of classci. MacroF1
measure is the average ofF1 of each class. MacroF1 gives
overall effectiveness of a classifier. It is defined as:
MacroF1 =
1
|C|
X
ci∈C
2×P recision(ci)×Recall(ci)
P recision(ci) +Recall(ci)
(15)
where,
Precision (ci) =
number of correct classifications into classci
number of classifications into classci
(16)
Recall (ci) =
number of correct classifications into classci
number of sentences in classci
(17)
5.3
Experiment Settings
We did preprocessing on the corpus. We removed stop-words and non ASCII characters from the corpus. We re-placed each URL by the word URL and each email-id by the word EMAIL ID from the corpus using regular expres-sions.
5.3.1
LDA based sentence filtering (LDA)
We used Mallet1 to run LDA on the corpus. Mallet uses Gibbs sampling to estimate the parameters of LDA. We ex-perimented with different values of number of topics (T), ranging from 20 to 40. The Dirichlet parameterβwas cho-sen to be 0.01 and αwas 50/T . We performed 1000 steps for Gibbs sampling.
We also decided to find inter-expert agreement on labeling of topics and its relation with Macro-F1. For each T, we asked two experts to label each topic as either useful or use-less. Then we used Kappa coefficient to find inter-expert agreement.
5.3.2
Sentence filtering using labeled and unlabeled
sentences with EM (EM LU)
In this experiment, we followed the approach proposed in [16]. We experimented with various sizes of the labeled
1
Algorithm Classc1 Classc2 MacroF1
Precision Recall F1 Precision Recall F1
LDA (T = 32) 0.90 0.87 0.892 0.74 0.80 0.77 0.831 Clustering (N= 28) 0.88 0.86 0.87 0.72 0.75 0.74 0.805 EM LU [16] 0.85 0.86 0.855 0.70 0.68 0.69 0.7725 EM keywords [14] 0.85 0.88 0.865 0.72 0.66 0.69 0.7775
Table 3: Experimental results of sentence filtering
dataset. We used 10% to 50% of the corpus as labeled dataset and rest of the corpus as unlabeled dataset.
5.3.3
Sentence filtering using keywords and EM
(EM keywords)
In this experiment, we followed the approach proposed in [14]. We manually created a set of keywords for both, useful and useless classes and performed the experiment.
5.3.4
Clustering based sentence filtering
(Clustering)
In this approach, we want to measure the performance of LDA based approach with text clustering. We will cluster sentences into N clusters, then find representative words of each cluster, and using these representative words, an expert will label each cluster as useful or useless. We label a sentence useful if it belongs to the useful cluster otherwise we label it useless. For this experiment we are using CLUTO
2
. We are doing this experiment for different values of N
ranging from 20 to 40.
5.4
Experimental Results
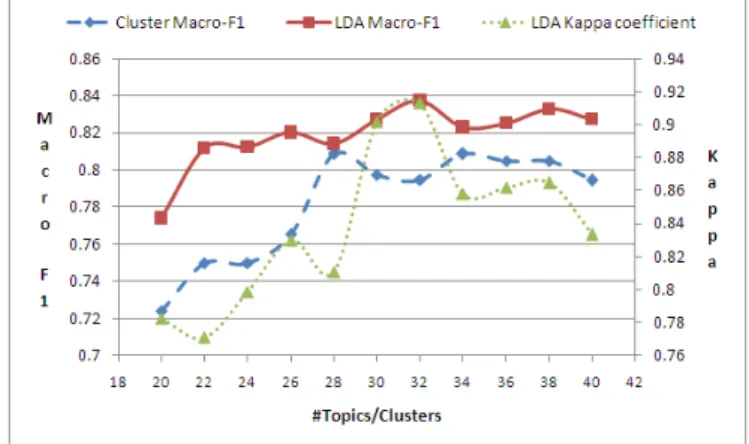
Figure 2 shows the graph of Kappa coefficient values vari-ation for LDA and Macro-F1 of LDA and clustering based approaches against the number of topics/clusters. In LDA based approach, we observed highest Macro-F1 and high-est Kappa coefficient atT = 32. We are trying to analyze Kappa coefficient variation against the number of topics. In clustering based approach, we observed highest Macro-F1 at
N= 28.
Table 4 shows topics obtained on our dataset withT = 32 and Table 5 shows examples of few correctly classified sen-tences.
Table 3 gives class wise performance and Macro-F1 of the
four approaches described above. We can see that LDA based sentence filtering performs better than the other three approaches. We can observe from the graph, that LDA based sentence filtering always performs better than clus-tering based sentence filclus-tering for different values of number of topics or clusters.
We observed that performance of sentence filtering using labeled and unlabeled sentences with EM depends on the labeled dataset and its size.
In keyword based approach, we have a set of keywords for each class. We observed that, there are some sentences where context of a keyword of one class contains keywords from other class. We can say that such type of sentences are at the boundary of two classes. Due to mixture of keywords from different classes these sentences are likely to get mis-classified.
We observed that in the context ofLotus Notesrelated prob-lems, the word “notes” is important. In the keyword based
2
http://glaros.dtc.umn.edu/gkhome/cluto/cluto/overview
Figure 2: Macro-F1 and Kappa coefficient variation against the number of topics/clusters
approach we can say that this word belongs to the class of “useful” words. In table 4, we can observe that the word “notes” is present in useless topics 14 and 19, as well as in many useful topics like 9, 11, 18 . So in unsupervised settings, it is incorrect to assign a single class to the word “notes”. But while providing list of keywords, context of a word is not considered. So there are chances of misclassifi-cation.
In LDA based approach, most prominent words in a topic frequently co-occur with each other in the dataset. Also LDA is a generative model, so that with the help of top-ics, it is easy for the user to understand the complete dataset, which is not feasible in the other approaches de-scribed above.
6.
CONCLUSION
In this paper, we suggested modifications to the definition of text noise and presented a novel, inexpensive and almost unsupervised approach to filter out text noise. We summa-rize our approach as follows: Filtering text noise is a text classification problem. As the size of the dataset is huge, it is very expensive to label the dataset and to use a supervised classifier. We use LDA and the aggregation property of the Dirichlet distribution for filtering text noise. We have also demonstrated the effectiveness of our approach by experi-ments on a real-life dataset of ITIS tickets containing highly noisy problem descriptions and solutions.
Topic ID Most prominent words in the topic
0 email, ultimatix, helpdesk, selection, global, address, hr, tcs, employee 1 steps, mentioned, follow, error, showing, unable, user, attachment, find 2 files, id, hidden, search, folders, pc, inside, kindly, discussed
3* tcs, call, free, toll, indy, voip, usa, ghd, queries
4 password, temporary, enter, sametime, webmail, login, url, set, accessing 5 file, id, password, hours, hour, note, work, log, wait
6 mail, server, web, tcs, copy, open, mails, network, forwarding
7* ticket, provide, close, request, feedback, valuable, service, solution, improve 8* contact, local, idm, call, issue, case, project, incase, person
9 id, file, password, login, notes, rename, replace, copy, folder 10 access, hrs, database, emp, user, replication, status, mails, message 11 lotus, data, settings, notes, number, employee, local, application, folder 12 id, file, ticket, attached, mention, problem, earlier, requested, certified 13 id, email, days, request, file, business, wait, kindly, raise
14* lotus, notes, configuration, document, configure, url, follow, attached, step 15* ticket, raise, request, user, note, unable, pl, reopen, behalf
16 location, hr, server, update, updated, mail, ultimatix, check, current 17 file, id, attached, password, pls, find, configure, recertified, hr
18 ticket, raise, configuration, lotus, notes, idfile, expired, case, certificate 19* issues, call, find, notes, configuration, incase, lotus, raise, helpdesk 20 dear, problem, kindly, changed, group, support, services, chat, mailbox 21* ticket, raise, issue, resolved, webmail, user, tickets, single, log
22* user, ticket, called, resolving, informed, phone, issue, reach, gave 23 file, id, attached, download, user, ticket, switch, save, desktop
24 password, change, follow, step, instructions, mentioned, im, carefully, link 25 password, reset, id, note, time, file, ist, pm, normal
26 mail, id, file, emp, nsf, server, access, change, password
27 notes, lotus, configured, user, connected, users, permission, system, archive 28 login, lotus, details, notes, open, client, sametime, exit, logon
29 password, lotus, notes, fine, default, working, user, account, update 30 password, user, change, file, reset, security, policy, enter, click 31 user, email, send, username, switched, format, checked, chn, ramesh
Table 4: Most prominent words of topics (* indicates useless topic)
Sentence Class Closest
Proba-topic bility Incase you find any issues or queries with respect to above information; please call us
at USA TOLL FREE : 1-877-TCS-INDY: PSTN: 080-6060 5555 OR VOIP: 500-5555
useless 3 0.90
Also requesting you to provide your valuable feedback to your request :.so that we can improve our service and please close the ticket after satisfactory solution
useless 7 0.87
Contacted user over the phone:As informed by user issue is already fixed by IDM and hence resolving the ticket
useless 22 0.78
Please access your mail box on server InMumM03//mail//mail3//EMPID.nsf and change the password immd: once Lotus Notes client is configured .
useful 26 0.70
Click on HR Management - Employee Self Service - Email selection and select your email address .
useful 0 0.86
b) Enter the temporary password:7NxUwX1Bcu6T(Please ensure to copy password correctly) .
useful 4 0.66
base for CBR based help desk system 3. skill profiling of help desk resolvers for effective workforce management in the help desk. We would like to generalize algorithm 1 to find the number of skills and ticket to skill mapping in help desk.
We would also like to use our content filtering approach to filter various aspects of financial reports and news articles.
7.
ACKNOWLEDGMENTS
The authors would like to thank K.V.S. Dileep of AIDB Lab at IIT Madras, Darshan Shirodkar and Sangameshwar Patil of SRL at TRDDC for their help and support.
8.
REFERENCES
[1] S. Agarwal, S. Godbole, D. Punjani, and S. Roy. How much noise is too much: A study in automatic text classification. InProceedings of the 2007 Seventh IEEE International Conference on Data Mining, pages 3–12, October 2007.
[2] D. M. Blei, A. Y. Ng, and M. I. Jordan. Latent dirichlet allocation.The Journal of Machine Learning Research, 3:993–1022, March 2003.
[3] A. Blum and T. Mitchell. Combining labeled and unlabeled data with co-training. InProceedings of the eleventh annual conference on Computational learning theory, pages 92–100, 1998.
[4] S. P. Crain, K. Zhou, S.-H. Yang, and H. Zha. Dimensionality reduction and topic modeling: From latent semantic indexing to latent dirichlet allocation and beyond. In C. C. Aggarwal and C. Zhai, editors, Mining Text Data, pages 129–161. Springer US, 2012. [5] S. Deerwester, S. T. Dumais, G. W. Furnas, T. K.
Landauer, and R. Harshman. Indexing by latent semantic analysis.JASIS, 41(6):391–407, 1990. [6] B. A. Frigyik, A. Kapila, and M. R. Gupta.
Introduction to the dirichlet distribution and related processes. Technical report. University of Washington, Seattle, 2012.https://www.ee.washington.edu/ techsite/papers/documents/UWEETR-2010-0006.pdf
[7] M. H. G¨oker and T. Roth-Berghofer. Development and utilization of a case-based help-desk support system in a corporate environment. InProceedings of the Third International Conference on Case-Based Reasoning and Development, pages 132–146, 1999. [8] T. L. Griffiths and M. Steyvers. Finding scientific
topics.PNAS, 101(suppl. 1):5228–5235, April 2004. [9] G. Heinrich. Parameter estimation for text analysis.
Technical report. University of Leipzig, Germany, 2004.http:
//www.arbylon.net/publications/text-est.pdf
[10] T. Hofmann. Probabilistic latent semantic indexing. In Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, pages 50–57, 1999.
[11] T. Hofmann. Unsupervised learning by probabilistic latent semantic analysis.Machine Learning, 42(1-2):177–196, January 2001.
[12] Y. Ko and J. Seo. Text classification from unlabeled documents with bootstrapping and feature projection techniques.Information Processing and Management, 45(1):70–83, January 2009.
[13] B. Liu, X. Li, W. S. Lee, and P. S. Yu. Text
classification by labeling words. InProceedings of the 19th national conference on Artifical intelligence, pages 425–430, 2004.
[14] A. Mccallum and K. Nigam. Text classification by bootstrapping with keywords, EM and shrinkage. In ACL-99 Workshop for Unsupervised Learning in Natural Language Processing, pages 52–58, 1999. [15] G. Mishne, D. Carmel, R. Hoory, A. Roytman, and
A. Soffer. Automatic analysis of call-center conversations. InProceedings of the 14th ACM international conference on Information and
knowledge management, pages 453–459, October 2005. [16] K. Nigam, A. K. McCallum, S. Thrun, and
T. Mitchell. Text classification from labeled and unlabeled documents using EM.Machine Learning -Special issue on information retrieval, 39(2-3), May-June 2000.
[17] Q. Qiu, Y. Zhang, and J. Zhu. Building a text classifier by a keyword and unlabeled documents. In Proceedings of the 13th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining, pages 564–571, 2009.
[18] Q. Qiu, Y. Zhang, J. Zhu, and W. Qu. Building a text classifier by a keyword and Wikipedia knowledge. In Proceedings of the 5th International Conference on Advanced Data Mining and Applications, pages 277–287, 2009.
[19] L. V. Subramaniam, S. Roy, T. A. Faruquie, and S. Negi. A survey of types of text noise and techniques to handle noisy text. InProceedings of The Third Workshop on Analytics for Noisy Unstructured Text Data, pages 115–122, 2009.
[20] H. Takeuchi, L. V. Subramaniam, T. Nasukawa, and S. Roy. Automatic identification of important segments and expressions for mining of
business-oriented conversations at contact centers. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and
Computational Natural Language Learning (EMNLP-CoNLL), pages 458–467, 2007. [21] R. O. Weber, K. D. Ashley, and S. Br¨uninghaus.
Textual case-based reasoning.Knowl. Eng. Rev., 20:255–260, September 2005.
[22] C. Yang, B. Farley, and B. Orchard. Automated case creation and management for diagnostic CBR systems. Applied Intelligence, 28:17–28, February 2008.