International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
891
VLSI Implementation of Cryptography Hash Algorithms
Gowthaman. A
1, Arockia E J Ferdin
2, Freeben David Robinson. N
31,3II nd
Year Department of VLSI Design in Sathyabama University, Chennai. 2II nd
Year Department of NANOTECHNOLOGY in Sathyabama University, Chennai
Abstract— Providing security to data and information which is to be transferred to and fro has its increasing demand where various remedy measures are to be undertaken for that. It is ensured by providing out some cryptographic algorithms for enhanced security. A few among these were MD5 (Message Digest Algorithm), SHA (Secured Hash Algorithm), Blake and so on. The ultimate objective of this project is to develop a VLSI based cryptographic hash algorithms which are being employed in network security. The light is thrown mainly on Blake algorithm and also comparisons are examined between MD5, SHA and Blake. The synthesized result obtained with reference to the device Spartan 6 (XC6SLX45-2CSG324) FPGA.
Keywords—Cryptography,MD5 and SHA Family of (sha 0,sha 1,sha 2)BLAKE Algorithm, Implementation, Xilinx and FPGA implementation.
I. INTRODUCTION
Cryptography means Crypto- Security; graph- Writing. It conceals the context of some message from all except the sender and the recipient. It ensures authentication and verifies the correctness of the message to the recipient. Cryptography refers to the art or science encompassing the principles and methods of transforming an intelligible message into one that is unintelligible and then retransforming that message back to its original form.
Data Security is the main aspect of secure data transmission over unreliable network. Data Security is a challenging issue of data communications today that touches many areas including secure communication channel, strong data encryption technique and trusted third party to maintain the database. The rapid development in information technology, the secure transmission of confidential data herewith gets a great deal of attention.
The conventional methods of encryption can only maintain the data security. The information could be accessed by the unauthorized user for malicious purpose.
Therefore, it is necessary to apply effective
encryption/decryption methods to enhance data security. An algorithm for transforming an intelligible message into an unintelligible one using a code-book
Cipher is an algorithm for transforming an intelligible message into unintelligible by transposition and/or substitution. A Key is any critical information used by the cipher, known only to the sender and receiver.
II. LITERATURE SURVEY
Various measures were set to be undertaken in the late 1980‟s to ensure protection for network data and information transfer. „Network Security and Cryptographic Algorithms‟ was the main source to walk through various cryptographic algorithms to ensure complete understanding of the algorithms. Not only the concept but also it paved the way for better enhancement to implement such algorithms in various forms just like VLSI. On basis of regular research through this book, we were enclosed with the following details:
In 1993, NIST published the first Secure Hash Standard SHA-0, which two years later was superseded by SHA-1 to improve the original design. SHA-1 was still deemed secure by the end of the millennium, when researchers‟ attention turned to block ciphers through the AES competition. Shortly after an avalanche of results on hash functions culminated with collision attacks for MD5 and SHA-1. Meanwhile NIST had introduced the SHA-2 family, unbroken until now. Some years later NIST announced the SHA-3 program, calling for proposals for a hash function that will augment the SHA-2 standard. BLAKE is our candidate for SHA-3. We did not reinvent the wheel; BLAKE is built on previously studied components, chosen for their complementarities. The heritage of BLAKE is threefold:
• BLAKE‟s iteration mode is HAIFA, an improved
version of the Merkle-Damg°ard paradigm proposed by Biham and Dunkelman. It provides resistance to long-message second pre image attacks, and explicitly handles hashing with a salt.
• BLAKE‟s internal structure is the local wide-pipe,
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
892
• BLAKE‟s compression algorithm is a modified version
of Bernstein‟s stream cipher ChaCha, whose security has been intensively analyzed and performance is excellent, and which is strongly parallelizable. The iteration mode HAIFA would significantly benefit to the new hash standard, for it provides randomized hashing and structural resistance to second-pre image attacks. The LAKE local wide-pipe structure is a straightforward way to give strong security guarantees against collision attacks. Finally, the choice of borrowing from the stream cipher ChaCha comes from our experience in cryptanalysis of Salsa20 and ChaCha, when we got convinced of their remarkable combination of simplicity and security.
III. MESSAGE DIGEST ALGORITHM (MD5)
MD5 algorithm was developed by Professor Ronald L. Rivest in 1991. According to RFC 1321, “MD5 message-digest algorithm takes as input a message of arbitrary length and produces as output a 128-bit "fingerprint" or "message digest" of the input. The MD5 algorithm is intended for digital signature applications, where a large file must be "compressed" in a secure manner before being encrypted with a private (secret) key under a public-key cryptosystem such as RSA.”
This approach comprises of the 128-bit hash algorithm for secure message digest. The results show that the 128-bit Message Digest Algorithm code is more secured. This effort can alternate efficiently the accessible Message Digest Algorithm and hash function implementations for security design, so this approach proves a high security step towards design. Message Digest Algorithm is a widely used cryptographic function with a 128- bit hash value.
MD5 has been employed in a wide variety of security applications, and is also commonly used to check the integrity of files. An MD5 hash is typically expressed as a 32-digit hexadecimal number. MD5 processes a variable-length message into a fixed-variable-length output of 128 bits. A hash value computes a permanent length output called the 9message digest from an input message of different lengths. The MD5 message digest algorithm was developed by Ron Rivest at MIT [1].
Until the last few years when both burst force and cryptanalytic concerns have arose, MD5 was most widely used secure hash algorithm. It is a widely-used 128-bit hash function, used in various applications Including SSL/TLS, IPSec, and many other cryptographic protocols.
The MD5 algorithm breaks a sleeve into 512 bit input blocks. Every block is run from side to side a series of functions to produce a exceptional bit hash value for the sleeve.
A hash function H is a transformation that takes a variable-size input m and proceeds a fixed-size string, which is called the hash value h. Hash functions with just this property have a variety of general computational uses, but when working in cryptography the hash functions are regular chosen to have some supplementary properties. This is a contract in lots of programming languages that allocate the user to dominate equality and hash functions for an object, that if two objects are the same their hash codes must be the same.
Hash functions compress a n (arbitrarily) large number of bits into a small number of bits [3].
The hash function properties are:-
a)Output does not reveal information on input.
b)Hard to find collisions (different messages with same hash).
c)One way cannot be reversed.
Data integrity assertion and data basis authentication are important security services in an economic statement, electronic business, electronic mail, software distribution, data storeroom and so on. The messages are broadest of verification within computing systems Encompasses uniqueness authentication, meaning source Authentication and message contented authentication.
One that deals with individual message only without regard to large context generally provides protection against message modification only. Data integrity is compulsory within a record at its design steps. from beginning to the end use of standard rules and procedures, and is maintained through the use of error inspection and validation routines.
Entity integrity
Domain integrity
Referential integrity
User-defined integrity
3.1 Entity integrity
Entity Integrity ensures that there are no replica reports within the table and that the field that identifies each documents within the table is matchless and never null.
3.2 Domain integrity
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
[image:3.612.72.280.144.278.2]893 Fig 3.2.1 Data Integrity System
3.3 Referential integrity
Referential integrity is a main property of data which are required for one attribute. Referential integrity is a record thought that ensures that associations between tables remain consistent. Referential integrity works for RDBMS.
3.4User-defined integrity
User Define Integrity most commonly define by user that involve in the business. User-defined integrity allows you to define precise business rules that do not descend into one of the other integrity categories.
3.5Padding Bits
The message is "padded" (extended) so that its length (in bits) is congruent to 448, modulo 512. That is, the message is extended so that it is just 64 bits shy of being a multiple of 512 bits long. Padding is always performed, even if the length of the message is already congruent to 448, modulo 512.
Padding is performed as follows:
A single "1" bit is appended to the message, and then "0" bits are appended so that the length in bits of the padded message becomes congruent to 448, modulo 512. In all, at least one bit and at most 512 bits are appended.
3.6Append length
A 64-bit representation of b (the length of the message before the padding bits were added) is appended to the result of the previous step. In the unlikely event that b is greater than 2^64, then only the low-order 64 bits of b are used.
3.7 Initialize MD Buffer
[image:3.612.340.542.152.299.2]A Four-word buffer (A, B, C, D) is used to compute the message digest. Here each of A, B, C, D is a 32-bit register.
Fig 3.5.1 MD5 Algorithm structure[1]
3.8Steps to perform MD 5
The input message is broken up into chunks of 512-bit blocks (sixteen 32-bit little indian integers),the message is padded so that its length is divisible by 512.
The padding works as follows:
1. First a single bit, 1, is appended to the end of the message.
2. This is followed by as many zeros as are required to bring the length of the message up to 64 bits fewer than a multiple of 512.
3. The remaining bits are filled up with a 64-bit integer representing the length of the original message, in bits.
4. The MD5 algorithm uses 4 state variables, each of which is a 32 bit integer (an unsigned long on most systems). These variables are sliced and diced and are (eventually) the message digest.
The variables are initialized as follows: A = 0x67452301
B = 0xEFCDAB89 C = 0x98BADCFE D = 0x10325476
5. Now on to the actual meat of the algorithm: the main part of the algorithm uses four functions to thoroughly goober the above state variables. Those functions are as follows:
F(X,Y,Z) = (X & Y) | (~(X) & Z) G(X,Y,Z) = (X & Z) | (Y & ~(Z)) H(X,Y,Z) = X ^ Y ^ Z
I(X,Y,Z) = Y ^ (X | ~(Z))
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
894 6. These functions, using the state variables and the
message as input, are used to transform the state variables from their initial state into what will become the message digest. For each 512 bits of the message, the rounds performed (this is only pseudo-code, don‟t try to compile it)
7. After this step, the message digest is stored in the state variables (A, B, C, and D). To get it into the hexadecimal form you are used to seeing, output the hex values of each the state variables, least significant byte first.[2]
For example, if after the digest:
A = 0x01234567 B = 0x89ABCDEF C = 0x1337D00D D = 0xA5510101
Then the message digest would be:
67452301EFCDAB890DD03713010151A5 (required
hash value of the input value).
III.I. Implementation Steps Step1.Append padding bits
The input message is "padded" (extended) so that its length (in bits) equals to 448 mod 512. Padding is always performed, even if the length of the message is already 448 mod 512.
[image:4.612.62.283.509.700.2]Padding is performed as follows: a single "1" bit is appended to the message, and then "0" bits are appended so that the length in bits of the padded message becomes congruent to 448 mod 512. At least one bit and at most 512 bits are appended.
Fig 3.1 MD5 compression function diagram[1]
Step2.Append length
A 64-bit representation of the length of the message is appended to the result of step1. If the length of the message is greater than 2^64, only the low-order 64 bits will be used.
The resulting message (after padding with bits and with b) has a length that is an exact multiple of 512 bits. The input message will have a length that is an exact multiple of 16 (32-bit) words.
Step3.Initialize MD buffer
A four-word buffer (A, B, C, D) is used to compute the message digest. Each of A, B, C, D is a 32-bit register. These registers are initialized to the following values in hexadecimal, low-order bytes first):
word A: 01 23 45 67 word B: 89 ab cd ef word C: fe dc ba 98 word D: 76 54 32 10
Step4.Process message in 16-word blocks
Four functions will be defined such that each function takes an input of three 32-bit words and produces a 32-bit word output.
F (X, Y, Z) = XY or not (X) Z G (X, Y, Z) = XZ or Y not (Z) H (X, Y, Z) = X xor Y xor Z I (X, Y, Z) = Y xor (X or not (Z))
Step 5 Output
The message digest produced as output is A,B,C,D. Thus, the output starts with lower order byte A and ends with higher order byte D.
The MD5 algorithm is simple to implement and provides a fingerprint or message digest of a message of a arbitrary length. The difficulty of coming up with two messages with
the same message digest is in the order of 264
operations[2][3].
IV. SECURE HASH ALGORITHM (SHA)
The Secure Hash Algorithm is one of a number of cryptographic hash functions. There are currently three generations of Secure Hash Algorithm:
SHA-0 is two messages that hash to nearly the same value; in this case, 142 out of the 160 bits are equal. They also found full collisions of SHA-0 reduced to 62 out of its 80 rounds.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
895
SHA-2 is a family of two similar hash functions, with different block sizes, known as 256 and SHA-512. They differ in the word size; SHA-256 uses 32-bit words where SHA-512 uses 64-32-bit words.
SHA-3 is a future hash function standard still in development.
4.1 SHA-0
At CRYPTO 98,two French researchers, Florent
Chabaud and Antoine Joux, presented an attack on SHA-0 (Chabaud and Joux, 1998): collisions can be found with
complexity 261, fewer than the 280 for an ideal hash
function of the same size.
In 2004, Biham and Chen found near-collisions for SHA-0—two messages that hash to nearly the same value; in this case, 142 out of the 160 bits are equal. They also found full collisions of SHA-0 reduced to 62 out of its 80 rounds.
Subsequently, on 12 August 2004, a collision for the full SHA-0 algorithm was announced by Joux, Carribault, Lemuet, and Jalby. This was done by using a generalization of the Chabaud and Joux attack. Finding the collision had
complexity 251 and took about 80,000 CPU hours on
a supercomputer with 256 Itanium 2 processors.
(Equivalent to 13 days of full-time use of the computer.) On 17 August 2004, at the Rump Session of CRYPTO 2004, preliminary results were announced by Wang, Feng, Lai, and Yu, about an attack on MD5, SHA-0 and other hash functions. The complexity of their attack on SHA-0 is
240, significantly better than the attack by Joux et al
In February 2005, an attack by Xiaoyun Wang, Yiqun Lisa Yin, and Hongbo Yu was announced which could find
collisions in SHA-0 in 239 operation.[5]
In light of the results for SHA-0, some experts suggested
that plans for the use of SHA-1 in
new cryptosystems should be reconsidered. After the CRYPTO 2004 results were published, NIST announced that they planned to phase out the use of SHA-1 by 2010 in favor of the SHA-2 variants
4.2 SHA-1 Basic Properties:
● OUTPUT SIZE:- 160(bits)
● INTERNAL STATE SIZE: 160(bits) ● BLOCK SIZE: 512(bits)
● MAX MESSAGE SIZE 264 − 1 ● LENGTH SIZE 64(bits) ● WORD SIZE 32(bits)
● COLLISION ATTACKS No (251 attack) ● ROUNDS 80
4.2.1Description
SHA1 stands for “Secure Hashing Algorithm”. It is a hashing algorithm designed by the United States National Security Agency and published by NIST. It is the improvement upon the original SHA0 and was first published in 1995. SHA1 is currently the most widely used SHA hash function, although it will soon be replaced by the newer and potentially more secure SHA2 family of hashing functions.
It is currently used in a wide variety of applications, including TLS, SSL, SSH and PGP. SHA1 outputs a 160bit digest of any sized file or input. In construction it is similar to the previous MD4 and MD5 hash functions, in fact sharing some of the initial hash values. It uses a 512 bit
block size and has a maximum message size of 264-1
bits.[4]
4.2.2 SHA1 Algorithm Description
4.2.1. Padding
Pad the message with a single one followed by zeroes until the final block has 448 bits.
Append the size of the original message as an unsigned 64 bit integer.
4.2.2. Initialize the 5 hash blocks (h0,h1,h2,h3,h4) to the
specific constants defined in the SHA1 standard.
4.2.3. Hash (for each 512bit Block)
Allocate an 80 word array for the message schedule Set the first 16 words to be the 512 bit block split into 16 words. The rest of the words are generated using the following algorithm. Word[i3]XOR word[i8] XOR word[i14] XOR word[i16] then rotated 1 bit to the left.
Loop 80 times doing the following
Calculate SHA function() and the constant K (these are based on the current round number.
e=d d=c
c=b (rotated left 30) b=a
a = a (rotated left 5) + SHAfunction() + e + k + word[i] 4. Add a,b,c,d and e to the hash output.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
[image:6.612.56.273.113.338.2]896 Fig 4.2.3 SHA 1 compression function diagram
Even a small change in the message will, with overwhelming probability, result in a completely different hash due to the avalanche effect. For example, changing dog to cog produces a hash with different values for 81 of the 160 bits
4.3 SHA 2
SHA-2 is a set of cryptographic hash functions (SHA-224, SHA-256, SHA-384, SHA-512) designed by the U.S. National Security Agency (NSA) and published in 2001 by the NIST as a U.S. Federal Information Processing Standard. A hash function is an algorithm that transforms (hashes) an arbitrary set of data elements, such as a text file, into a single fixed length value (the hash).
The computed hash value may then be used to verify the integrity of copies of the original data without providing any means to derive said original data. This irreversibility means that a hash value may be freely distributed or stored, as it is used for comparative purposes only. SHA stands for Secure Hash Algorithm. SHA-2 includes a significant number of changes from its predecessor, SHA-1. SHA-2 consists of a set of four hash functions with digests that are 224, 256, 384 or 512 bits.
The security provided by a hashing algorithm is entirely dependent upon its ability to produce a unique value for any specific set of data. When a hash function produces the same hash value for two different sets of data then a collision is said to occur[6].
Collision raises the possibility that an attacker may be able to computationally craft sets of data which provide access to information secured by the hashed values of pass codes or to alter computer data files in a fashion that would not change the resulting hash value and would thereby escape detection.
A strong hash function is one that is resistant to such computational attacks. A weak hash function is one where a computational approach to producing collisions is believed to be possible. A broken hash function is one where a computational method for producing collisions is known to exist.
In 2005, security flaws were identified in SHA-1, namely that a mathematical weakness might exist, indicating that a stronger hash function would be
desirable.[2] Although SHA-2 bears some similarity to the
SHA-1 algorithm, these attacks have not been successfully extended to SHA-2.
The NIST hash function competition selected a new hash
function, SHA-3, in 2012.[3] The SHA-3 algorithm is not
derived from SHA-2.[5]
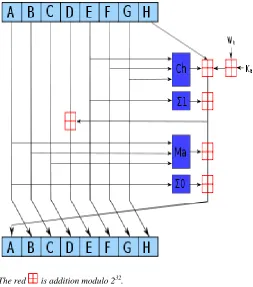
The red is addition modulo 232.
FIG.4.3 SHA 2 compression function diagram
[image:6.612.326.579.389.676.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
897
4.3.1 Comparison Of SHA Functions
In the table below, internal state means the “internal hash sum” after each compression of a data block[7].
Algorithm and variant
Output size (bits)
Internal state size (bits)
Block size (bits)
Max message size (bits)
Word size (bits)
Rounds Operations Collisions found?
SHA-0
160 160 512 264 − 1 32 80 add, and, or, xor, rotate,
mod
Yes
SHA-1 Theoretical attack
(251)[6]
SHA-2
SHA-256/224 256/224 256 512 2 64
− 1 32 64
add, and, or, xor, rotate,
mod, shift No
SHA-512/384 512/384 512 1024 2
128 − 1 64 80
V. BLAKE
BLAKE is cryptographic hashfunction submitted to the NIST hash function competition by Jean-Philippe Aumasson, Luca Henzen, Willi Meier, and Raphael C.-W. Phan. It is based on Dan Bernstein's ChaCha stream cipher, but a permuted copy of the input block, XORed with some round constants, is added before each ChaCha round. BLAKE was chosen as one of the five finalists of the competition.
Like SHA-2, there are two variants differing in the word size. ChaCha operates on a 4×4 array of words. BLAKE repeatedly combines an 8-word hash value with 16 message words, truncating the ChaCha result to obtain the next hash value. BLAKE-256 uses 32-bit words, while BLAKE-512 uses 64-bit words.
Before the BLAKE algorithm in discussed in detail, this section describes hash functions in general, as well as their cryptographic applications.[9]
5.1 Hash Overview
By definition, hash functions are transformations which produce a numeric “hash” or “digest” of a predefined length from an input message of arbitrary length (both typically measured in bits). These are often used in digital systems for checking the integrity of transmitted data, quickly looking up messages in a database, or mapping messages to table indexes.
In the field of cryptography, hashes have further applications, including the creation of authentication codes, digitally signing documents, and generation of statistically random data streams
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
898 Finally, any change in the input message (regardless of significance) should produce a drastic and seemingly-random change in the output hash.
The algorithm is considered weak if it does not meet these requirements. (For example, the Message Digest 5 [MD5] algorithm has been “broken”, as researchers found methods to generate different messages which map to identical hashes.) These qualities distinguish cryptographic hash functions from general purpose hash functions, at the cost of complexity, computation time, and output size. For the purposes of this document, any mention of hash
functions refers to cryptographic hash functions
specifically.
The National Institute of Standards and Technology (NIST) has established a set of standardized hash functions called the Secure Hash Algorithm (SHA). The first version, called SHA-0, was published in 1993. Its design was influenced by cryptographer Ronald L. Rivest and his work on the MD4 and MD5 hashes. Since its 1995 revision as SHA-1, it has generally been accepted as the worldwide standard for digital data authentication and signing.
A newer function called SHA- 2 was published in 2001 to address some potential weaknesses, but it never surpassed the original in widespread adoption. Despite attempts, neither has been broken as of 2011.
NIST announced a global competition to find a new SHA function in 2007, and submissions were accepted for approximately one year. The algorithms are being analyzed and narrowed down through elimination rounds, based on the security, performance, and design of each function.[8]
5.2 Background
The BLAKE function was designed by a team of four individuals based in Switzerland. Its principal designer is Jean-Philippe Aumasson, a distinguished cryptography and computer science researcher. BLAKE‟s algorithm is based on the “ChaCha” variant of the Salsa20 stream cipher, whose integrity had already been researched and discussed by Aumasson.
Although hashes are fundamentally different from the two-way nature of ciphers, it is common for them to share operations since they require similar cryptographic qualities. The original specification was submitted to NIST in 2008, but it has been revised slightly through 2010
There are four official variants of BLAKE, distinguished by their output hash size, as required for the SHA-3 competition. The sizes are 224, 256, 384, and 512 bits, as designated after the algorithm name (eg. BLAKE-256).
The sizes were chosen as the SHA-2 sizes doubled, since increases in computing power require increases in hash sizes to maintain acceptable levels of security (against brute force or other attacks). The variants also have slight differences in the size of words processed and maximum message length.
BLAKE is an iterative algorithm based on the well-known and highly-regarded Hash Iterative Framework (HAIFA) structure. An initial hash, h0, is loaded from a predefined initialization vector. The BLAKE designers chose to reuse the same vectors as SHA-2 for their strong pseudo-random distributions.
The input message is then segmented into a set of N equallysized blocks (padded as necessary) and passed with the current hash through a compression function. The result is a new hash, and this process is repeated until the entire message has been “digested”. The last compression result is returned as the final message hash. This structure is summarized.
A major advantage of the HAIFA structure is that a long message can be hashed as it is streamed in, rather than requiring the entire message in available memory at once. The compress function is a general feature of the HAIFA structure, but its exact functionality is defined by each hash‟s specification. BLAKE‟s compression is described in the next section. It is important to note that a “timer” value is passed to the function, counting the number of bits processed so far.
This ensures that identical blocks at different locations in the input message will return different hash values. The BLAKE designers also chose to include a salt variable in the compression function, adding more security since the user can produce a set of different hashes for any given message. The inclusion of a salt is not required by NIST, and it defaults to zero when not implemented (reducing hardware area slightly) or not specified by the user [7].
5.3Design principles
The BLAKE hash functions were designed to meet all NIST criteria for SHA-3, including:
• message digests of 224, 256, 384, and 512 bits • same parameter sizes as SHA-2
• one-pass streaming mode
• maximum message length of at least 264 − 1 bits In addition, we imposed BLAKE to:
• explicitly handle hashing with a salt • be parallelizable
• allow performance trade-offs
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
899
We briefly justify these choices:
First, a built-in salt simplifies a lot of things; it provides an interface for an extra input, avoids insecure homemade modes, and encourages the use of randomized hashing.
Parallelism is a big advantage for hardware
implementations, which can also be exploited by certain large microprocessors. In addition, BLAKE allows a trade-off throughput/area to adapt the implementation to the hardware available.
Oppositely, we excluded the following goals:
• have a reduction to a supposedly hard problem • have homomorphic or incremental properties • have a scalable design
• have a specification for variable length hashing
We justify these choices: The relative unsuccess of provably secure hash functions stresses the limitations of the approach: though of theoretical interest, such designs tend to be inefficient, and their highly structured constructions expose them to attacks with respect to notions other than the proved one. The few advantages of homomorphic and incremental hash functions are not worth their cost; more importantly, these properties are undesirable in many applications.
Scalability of the design to various parameter sizes has no real advantage in practice, and the security of scalable designs is difficult to assess. Finally, we deemed unnecessary to complicate the function with variable-length features, for users can just truncate the hash values for shorter hashes, and there is no demand for hash values of more than 512 bits.
To summarize, we made our candidate as simple as possible, and combined well-known and trustable building blocks so that BLAKE already looks familiar to cryptanalysts. We avoided superfluous features, and just provide what users really need or will need in the future (like hashing with a salt). It was essential for us to build on
previous knowledge—be it about security or
implementation—in order to adapt our proposal to the low resources available for analyzing the SHA-3 candidates.
BLAKE is an iterative algorithm based on the well-known and highly-regarded Hash Iterative Framework (HAIFA) structure. An initial hash, h0, is loaded from a predefined initialization vector. The BLAKE designers chose to reuse the same vectors as SHA-2 for their strong pseudo-random distributions. The input message is then segmented into a set of N equallysized blocks (padded as necessary) and passed with the current hash through a compression function.
The result is a new hash, and this process is repeated until the entire message has been “digested”. The last compression result is returned as the final message hash. This structure is summarized. A major advantage of the HAIFA structure is that a long message can be hashed as it is streamed in, rather than requiring the entire message in available memory at once.
The compress function is a general feature of the HAIFA structure, but its exact functionality is defined by each hash‟s specification. BLAKE‟s compression is described in the next section. It is important to note that a “timer” value is passed to the function, counting the number of bits processed so far. This ensures that identical blocks at different locations in the input message will return different hash values.
The BLAKE designers also chose to include a salt variable in the compression function, adding more security since the user can produce a set of different hashes for any given message. The inclusion of a salt is not required by NIST, and it defaults to zero when not implemented (reducing hardware area slightly) or not specified by the user [11].
5.4 BLAKE-256 Algorithm
The details of the BLAKE-256 variant will be described here. For simplicity, the other variants will only be described by the differences between them. (This is the format used by the designers‟ specification.) BLAKE-256 produces a 256-bit hash which is treated as eight 32-bit words. It accepts a message of length 0 _ ` < 264. The message is appended with a 1 bit, a sequence of 0 bits, and its length ` in 64-bit representation.
The number of 0 bits is determined such that the total stream length is a multiple of 512 bits. This allows it to be partitioned into 512-bit blocks to be passed to the compress function for processing. The compress function takes four inputs: the 256-bit current hash (hi), a 512-bit block of the input message (mi), a 128-bit salt (s), and a cumulative 64-bit message 64-bit count (`i).
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
[image:10.612.77.259.147.220.2]900 Fig 5.4.1 Initial step implementation
Within the compress function, a 512-bit state v is maintained, treated as a 4x4 matrix of 32-bit words. This state is initialized from the current hash, salt value, timer value t, and a 256-bit constant c, (The timer is the `i value passed in; it is called a timer, rather than a length, inside the compress function.)
Fig 5.4.2 BLAKE compression function block diagram
The digits of constant c are directly taken from the hexadecimal representation of _, chosen for its irrational nature. After initializing the state matrix, it is iteratively processed through 14 rounds. The BLAKE designers chose security through a small number of complex ounds, whereas some researchers prefer a large number of less complicated rounds [9].
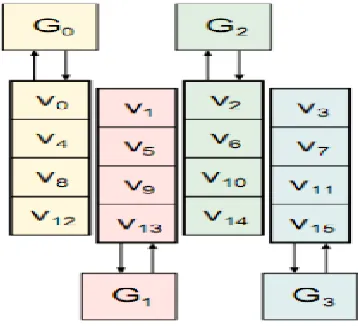
Both paradigms have supporters, but neither has been absolutely proven to provide greater security. (“Security” in this sense implies difficulty to invert, such that function inputs cannot be determined from function outputs.) Each round consists of eight state transformations, labelled G0 through G7.
[image:10.612.337.558.288.435.2]These are responsible for the confusion (changes to data) and diffusion (dispersion of data) of the BLAKE algorithm. Each operates on and modifies only 4 of the 16 state words, generalized as a, b, c, and d. The transformations (consisting of addition, bit-rotations, and exclusive or [XOR] operations) are listed.
Fig 5.4.3 BLAKE compression function[9]
The index _r refers to one of ten permutations of the numbers 0 through 15, indexed by the round number r modulo 10. This is crucial for proper diffusion of input data. The state words on which each G transformation operates were specifically chosen for efficiency. The first four operate on independent columns, and can be performed entirely in parallel.
[image:10.612.70.270.337.565.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
[image:11.612.86.265.148.311.2]901 Fig.5.4.4 COLUMN wise compression function diagram
After fourteen rounds of G transformations, the compress function performs a finalization step. This generates the new 256-bit hash, hi+1, as the large XOR of the previous hash hi, the salt s, and the 512-bit state matrix v. If the final be viewed as two large operations (called the column step and diagonal step), rather than eight sequential operations.
[image:11.612.59.280.473.632.2]This essentially reduces round calculation time by 75% in hardware and some software implementations. This parallelization is illustrated showing which words are affected by each operation.
FIG 5.4.5 DIAGONAL wise compression function diagram
After fourteen rounds of G transformations, the compress function performs a finalization step. This generates the new 256-bit hash, hi+1, as the large XOR of the previous hash hi, the salt s, and the 512-bit state matrix v (see Fig. 9).
If the final block of the padded input stream has been processed, then this result is the final output of the BLAKE hash function [9].
Similarly, the transformation could be viewed as follows:
1. make a column-step
2. rotate the ith row by i positions left, for i = 0, . . . , 3 3. make a column-step again
Finally, another equivalent definition of a round is
G0 (v0 , v4 , v8 , v12) G2 (v1 , v5 , v9 , v13) G4 (v2 , v6 , v10, v14) G6 (v3 , v7 , v11, v15) G8 (v0 , v5 , v10, v15) G10(v1 , v6 , v11, v12) G12(v2 , v7 , v8 , v13) G14(v3 , v4 , v9 , v14)
Where Gi(a, b, c, d) is redefined to
5.5 Finalization
After the rounds sequence, the new chain value h00, . . . , h07, is extracted from the state v0, . . . , v15 with input of the initial chain value h0, . . . , h7 and the salt s0, . . . , s3:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
902
5.6 Variant Differences
The other three variants are very similar to BLAKE-256. The 512-bit version doubles the bit sizes of most variables: all intermediate hashes, the compress state matrix, the maximum message size, the salt, and the timer. The initialization vector is taken from SHA-512, and the c constants simply extend to more digits of _. The _ permutation table remains the same.
The only non-trivial difference is in the G step: the bit-rotation amounts are defined differently, rather than simply doubling the previous amounts. It is also recommended that the number of ounds be increased from 14 to 16; technically this parameter is selectable by the user as a tuneable trade off between speed and security. The 224-bit and 384-bit variants actually utilize the 256-bit and 512-bit algorithms, then truncate the output hash accordingly.
This implies performance identical to the two variants
already discussed. The only differences are the
initialization vectors matching SHA-224 and SHA-384) and the exclusion of the 1 bit when padding the input message.
5.7 Strengths
The design of all cryptographic hashes involves a balancing of security and performance (and power consumption, in hardware implementations). The major parameter in BLAKE that balances these is the number of rounds per compression. With the unofficial goal of providing plenty of security while outperforming SHA-2, the original round counts were 10 (and 14) for the 256 (and 512) bit variants; these were increased to 14 and 16 in December 2010 for further security.
The algorithm was designed with much attention to data diffusion. “Full diffusion” means that a single changed input bit (message, salt, or initialization vector) can affect every output bit, and occurs after two transformation rounds. The compression function and G transformations were also designed to minimize the probability of local collisions, which occurs when two different messages produce the same internal state after the same number of rounds[8].
5.8 Synthesis
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
903
MD5:
SHA:
Timing Summary:
Speed Grade: -2
Minimum period: No path found
Minimum input arrival time before clock: No path found
Maximum output required time after clock: No pathfound
Maximum combinational path delay: 107.645ns
VI. ADVANTAGES AND LIMITATIONS
We summarize the advantages and limitations of BLAKE:
6.1 ADVANTAGES
Design
• simplicity of the algorithm • interface for hashing with a salt
Performance
• fast in both software and hardware
• parallelism and throughput/area trade-off for
hardware implementation
• simple speed/confidence trade-off with the tunable
number of rounds
Security
• based on an intensively analyzed component
(ChaCha)
• resistant to generic second-preimage attacks
• resistant to side-channel attacks
• resistant to length-extension
6.2 Limitations
• message length limited to respectively 264 and 2128
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
904
• resistance to Joux‟s multicollisions similar to that of
SHA-2
• fixed-points found in less time than for an ideal
function (but not efficiently)
We have introduced the BLAKE hash function, one of five finalists in the SHA-3 hash competition. Its history, uses, and relative strengths have been discussed. Its cryptographic structure and algorithm have also been examined in detail, leading to general conclusions about its security and performance. Software and hardware tests on real-world systems have been performed to judge its practical performance, allowing for informed comparisons with other hashes.
The future of the BLAKE algorithm and its potential worldwide adoption will be determined in 2012, when NIST announces which hash function will become the new SHA-3 standard. There is still time for much analysis and discussion; all five candidates remain under intense public scrutiny. This will ensure that the selection provides an
optimal balance between performance, resources,
efficiency, and security [10].
VII. CONCLUSION
This project has introduced the BLAKE hash function, one of five finalists in the SHA-3 hash competition. Its history, uses, and relative strengths have been discussed. Its cryptographic structure and algorithm have also been examined in detail, leading to general conclusions about its security and performance. Software and hardware tests on real-world systems have been performed to judge its practical performance, allowing for informed comparisons with other hashes.
The future of the BLAKE algorithm and its potential worldwide adoption will be determined in 2012, when NIST announces which hash function will become the new SHA-3 standard. There is still time for much analysis and discussion; all five candidates remain under intense public scrutiny. This will ensure that the selection provides an
optimal balance between performance, resources,
efficiency, and security.
REFERENCES
[1] R.Rivest. The MD5 Message-Digest Algorithm [rfc1321]
[2] Goldwasser, S. and Bellare, M."Lecture Notes on Cryptography".Summer course on cryptography, MIT, 1996-2001 [3] Salomon,David, Foundations of Computer Security Springer-Verlag
London Limited 2006.
[4] Schneier, Bruce, “Opinion: Cryptanalysis of MD% and SHA: Time for a new standard”, Computer World, August 2004.
[5] Stallings,William,Cryptography and Network Security, Prentice Hall, 1999.
[6] Tanenbaum, Andrew,Computer Networks, Prentice Hall, 2003. [7] J. Aumasson, L.Henzen, W. Meier, R. Phan. BLAKE cryptographic
hash function, SHA-3 proposal finalist, 2010.
http://www.131002.net/blake/blake.pdf accessed 16 Mar 2012. [8] SHA-3 proposal BLAKE. Webpage http://www.131002.net/blake/
accessed 16 Mar 2012.
[9] J. W. Bos and D. Stefan, “Performance analysis of the SHA-3candidates on exotic multi-core architectures,” 2010. [10] S.Neves,“ChaChaimplementation,”2009,http://eden.dei.uc.pt/
sneves/ chacha/chacha.html
![Fig 3.5.1 MD5 Algorithm structure[1]](https://thumb-us.123doks.com/thumbv2/123dok_us/8712570.882300/3.612.340.542.152.299/fig-md-algorithm-structure.webp)
![Fig 3.1 MD5 compression function diagram[1]](https://thumb-us.123doks.com/thumbv2/123dok_us/8712570.882300/4.612.62.283.509.700/fig-md-compression-function-diagram.webp)
![Fig 5.4.3 BLAKE compression function[9]](https://thumb-us.123doks.com/thumbv2/123dok_us/8712570.882300/10.612.70.270.337.565/fig-blake-compression-function.webp)