2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN: 978-1-60595-458-5
Network Traffic Feature Selection Based on
the Evaluation of Every Attribute
Jian SHEN
1,*and Jing-bo XIA
21Institute of Information and Navigation, Air Force Engineering University, Xi’an, Shaanxi, China 2Tan KahKee College, Xiamen University, Xiamen, Fujian, China
*Corresponding author
Keywords: Network traffic classification, Feature subset selection, Hybrid methods, Remaining features.
Abstract. Traffic classification is making a significant difference in network resource scheduling, safety analysis and future tendency prediction. As the essential step for machine learning based traffic classification, feature subset selection is often used to realize dimension reduction and redundant information decrease. A three-stage hybrid feature subset selection method is proposed to improve the classification performance of hybrid methods at low evaluation consumption. The proposed algorithm disposes features by the rank in the level of block and also evaluates all the remaining features that are verified as useless to take advantage of the interactions among all the features. Our theoretical analysis and experimental observations reveal that the proposed method selects feature subset with impressive classification performance on every index while depleting fewer evaluations.
Introduction
Feature Subset Selection (FSS) is often used as a pre-processing step for machine learning based network traffic classification [1]. Feature selection can not only point out critical features, but also decrease the noisy features from the original feature set.
The conventional filter-based and wrapper-based FSS methods have the intrinsic drawbacks. Recently the literatures have contained numerous references to the use of hybrid FSS algorithms to combine the superiority of different methods. Xie included a feature ranking in a sequential forward search method with the application of the F-score measure to rank the features [2], while Peng added a random sampling method to choose features from the ranking [3]. Zhang [4] and Bonilla-Huerta [5] proposed the similar methods including a ReliefF estimation based ranking, which were also applied to compress the searching space. These methods have made much improvement on feature selection, but they are still stuck with the restriction of computational complexity and classification accuracy.
In this paper, a three-stage hybrid algorithm is proposed to improve the efficiency and performance of network traffic classification. We still utilize the ranking strategy to take the advantages of simplicity and scalability. Then, features are disposed in the level of block to save the consumption of iteration. Meanwhile, all the features and their interactions are estimated, including the ones with less value by itself and ranking at the bottom.
The rest of the paper is organized as follows. The following section presents the proposed three-stage FSS algorithm in detail. The third section contains experiment and the corresponding analyses. We provide a summary of the paper in the last section.
Methodology
Filter-based Ranking
breaks down on continuous data. It is applicable to multi-class problems. If A is a feature and C is the class, (1) and (2) give the entropy of the class before and after observing the feature.
2 ( ) ( ) log ( )
c C
H C p c p c
(1)2
( ) ( ) ( ) log ( )
a A c C
H C A p a p c a p c a
(2)The amount by which the entropy of the class decreases reflects the additional information about the class provided by the feature [7]. Each feature is assigned a score based on the information gain between itself and the class as formula (3). The higher the IG value is, the more correlated the feature with the classes will be. Then, the features are sorted in descending order according to the score.
( ) ( )
= ( ) ( )
= ( ) ( ) ( , )
i i
i i
i i
IG H C H C A
H A H A C
H A H C H A C
(3)
Iterative Feature Selection in the Level of Block
In the second stage, the features are separated into blocks according to the ranking order. The size of block should be large enough to supply sufficient combination of features to be evaluated by wrapper-based method, but not so large that the advantages of iteration process fade away. The size of 30 is thought to be suitable to keep the balance [8]. We start feature selection from the first block with wrapper-based method. In this stage, we apply the widely used SFS method which is one of the wrapper algorithms. Let Fa be the subset of features selected from the block. The classification
performance of Fa is evaluated by the same classifier that is embedded in SFS. Then, the same
progress moves to the second block but taking into account the features that have already been selected into Fa. The newly selected features from the second block are also added into Fa. The
process is iterated until no new features are selected from the block or the classification performance of S stops increasing.
Selection from the Remaining Features
In the previous stage, it can be seen that the selection process ceases at the stopping criterion. The rest of the features ranking in the bottom have not been evaluated. Our purpose in this stage is to take the advantage of the remaining features, because the features with little value by themselves, which are usually abandoned, may make significant improvement when they are combined with the others.
In this stage, every remaining feature is evaluated with the combination of the features selected from stage 2. If the classification performance of Fa improves, the feature would be selected into the
feature subset Fb, otherwise it is omitted. This stage can extract the potential value of the features that
are usually ignored. As we know, the subset Fa selected from the features ranking in the top has strong
classification ability. What is more, with the complement of the chosen remaining features in subset Fb, the classification performance can make a further improvement.
Experiment
Experiment Setup
filter-based, wrapper-based and hybrid FSS methods, which are presented as the comparisons of the proposed algorithm in this paper.
The experiment adopts Naivebayes as the classifier. The 10-fold cross-validation method is used to estimate the data. We take the average of the experiment which is conducted ten times as the result.
Results and Analyses
This experiment is designed to compare the classification performance of the feature subsets selected by different algorithms. In this part of experiment, the block size of the proposed algorithm and IWSSrR is set to be 30. Therefore, the collection of 248 features is divided into 9 blocks.
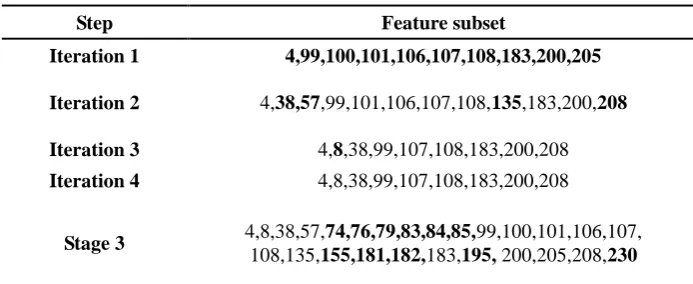
[image:3.595.122.469.331.473.2]From Table 1, we can observe the result of every step of the proposed algorithm. The features are targeted in bold when they are selected into the feature subset for the first time. It is obvious that there are new features being selected in the first three iterations. The second stage of algorithm gets to the stop criterion when it selects the same feature subset on the fourth iteration. And then, 11 remaining features ranking in the second half of the rank are selected into the subset on stage 3. Stage 4 filters away the redundant features to simplify the subset to be smaller. From the analysis of the final feature subset, we can see that 9 of the 11 selected remaining features are chosen into the final subset, which account for the half amount.
Table 1. Result of every step when the size of block is set to be 30.
Step Feature subset
Iteration 1 4,99,100,101,106,107,108,183,200,205
Iteration 2 4,38,57,99,101,106,107,108,135,183,200,208
Iteration 3 4,8,38,99,107,108,183,200,208
Iteration 4 4,8,38,99,107,108,183,200,208
Stage 3 4,8,38,57,74,76,79,83,84,85,99,100,101,106,107, 108,135,155,181,182,183,195, 200,205,208,230
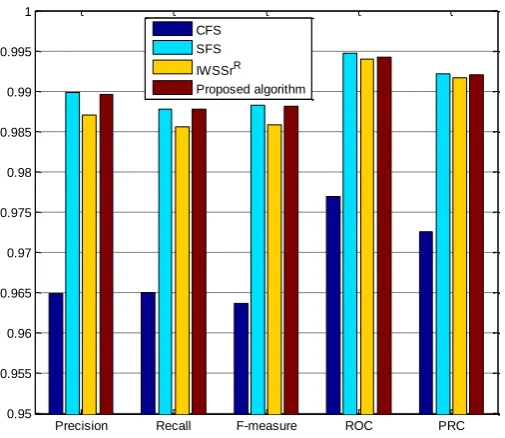
Figure 1 compares the performance of different algorithms on five indexes. The precision and recall represent for the ratio of correctly classified flows over all predicted flows and all flows respectively. The F-measure is the statistical technique to examine the classification performance of a system. It is defined to describe the synthetical performance of precision and recall [9]. In this paper, F-measure is weighted equally to both precision rate and recall rate as shown in equation (4).
2( )
- Precision Recall
F measure
Precision Recall
(4)
Precision Recall F-measure ROC PRC 0.95
0.955 0.96 0.965 0.97 0.975 0.98 0.985 0.99 0.995 1
[image:4.595.171.424.73.292.2]CFS SFS IWSSrR Proposed algorithm
Figure 1. Performance of different algorithms.
Though SFS has the best performance on most of the aspects, its computational complexity of O(n2) is intolerable for the feature selection process. Table 2 shows the number of evaluations carried
out by different algorithms. It can be seen that the two hybrid methods the proposed algorithm and IWSSrR cost nearly the same quantity of evaluations, which is only the half consumption of SFS. The evaluations carried out by CFS are the least among all the methods, but considering its classification performance, it is still not an appropriate choice for accurate classification.
Table 2. Evaluations of different algorithms.
CFS SFS IWSSrR Proposed
Algorithm Evaluations 147
9
635 1
2797 2600
Concerning all the comparisons above, we can come to the conclusion that the proposed method succeeds the advantages of hybrid approaches on the overhead of evaluations. Moreover, its classification performance can reach the same level of the wrapper-based method SFS.
Conclusion
A three-stage hybrid feature subset selection mechanism has been proposed and tested in this paper. The idea is based on full coverage of all the features. The novelty is that the remaining features of the selection in the level of blocks are reassessed by the interactions with the selected features one by one, and then the promising ones are brought into the feature subset. The advantage of this approach is that all the features are evaluated through the three stages, while the features filtered out by the stop criterion are reassessed to enrich the feature subset to enhance the classification performance.
[image:4.595.134.462.428.478.2]Acknowledgment
We would like to express our gratitude to all those who gave kind encouragement and useful instructions all through the writing. A special acknowledgement should be extended to the library assistants who supplied with reference materials of great value.
References
[1] Liu, Zhen, et al. “A class-oriented feature selection approach for multi-class imbalanced network traffic datasets based on local and global metrics fusion.” Neurocomputing 168. (2015):365-381.
[2] Xie, Juanying, and C. Wang. “Using support vector machines with a novel hybrid feature selection method for diagnosis of erythemato-squamous diseases.” Expert Systems with Applications An International Journal 38.5(2011):5809-5815.
[3] Peng, Yonghong, Z. Wu, and J. Jiang. “A novel feature selection approach for biomedical data classification.”Journal of Biomedical Informatics43.43(2010):15-23.
[4] Zhang, Li Xin, et al. “A novel hybrid feature selection algorithm: using ReliefF estimation for GA-Wrapper search.” International Conference on Machine Learning and Cybernetics IEEE, 2003:380-384 Vol.1.
[5] Bonilla-Huerta, Edmundo, et al. “Hybrid Filter-Wrapper with a Specialized Random Multi-Parent Crossover Operator for Gene Selection and Classification Problems.” Bio-Inspired Computing and Applications -, International Conference on Intelligent Computing, Icic 2011, Zhengzhou,china, August 11-14. 2011, Revised Selected PapersDBLP, 2011:453-461.
[6] Song, Qinbao, J. Ni, and G. Wang. “A Fast Clustering-Based Feature Subset Selection Algorithm for High-Dimensional Data.” Knowledge & Data Engineering IEEE Transactions on 25.1(2013):1-14.
[7] Salzberg, Steven L. “C4.5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc. 1993.”Machine Learning16. 3(1994):235-240.
[8] Bermejo, Pablo, et al. “Fast wrapper feature subset selection in high-dimensional datasets by means of filter re-ranking.”Knowledge-Based Systems25.1(2012):35-44.