2016 International Congress on Computation Algorithms in Engineering (ICCAE 2016) ISBN: 978-1-60595-386-1
1 INTRODUCTION
In the 1970s, the running speed of the processor was very slow, and the running speed of the memory is faster than that of the microprocessor. In the 1980s, with the development of the microelectronics tech-nology, the running speed of the processor rapidly increased, but the running speed of memory was slow, the speed of the memory lagged behind the speed of processor, and the parallel programming and commu-nication bottleneck burden became the main problem. When the speed of the processer and memory de-signed gradually achieved its physical limits, mul-ti-processor becomes a major research and develop-ment trend in order to further enhance the computing speed. Two mainstream parallel systems are the shared memory multi-processor (also called as the shared memory system) and the distributed memory multi-processor (also called as the distributed memory system). The shared memory system provides a com-prehensive and convenient programming model with a good structural universality, portability and easy pro-gramming, but it is difficult to extend to a large scale and meet today’s fast-growing demand for computing power of the computer; the distributed memory mul-ti-processor provides a possibility for high computing speed with a good scalability, but it is not conducive
to programming. The distributed shared memory combines with the advantages of the shared memory system and distributed memory system, and integrates with the programmability and scalability. The concept of the distributed shared memory (DSM) was first proposed by Li Kai in 1986 [1]. The early design is inspired by the traditional virtual memory system. In a virtual memory system, when the processor assess is not in a real memory page, the page will be interrupt-ed, which will be taken in the real memory from the hard disk by the operating system. The design of Li Kai is similar to this process, but the difference is that the missing pages are not taken out from the hard disk, but taken from the local memory of other processors via the network. The memory space of the system is physically distributed on different processors, but it constitutes a virtual shared memory space. Therefore, the distributed shared memory system is also called as a virtual shared memory system.
The shared memory programming can be done in the distributed shared memory. Its basic structure is shown in Figure 1. As can be seen from the figure, the hardware structure of the distributed shared memory system and distributed memory system are the same, and each processor has its own local memory, but these local memories are mapped into a unified shared memory space by DSM system. It provides the
pro-Overview of IO Queuing Algorithm in Distributed Memory
Feng Gao1, Wancheng Luo1 & Changyang Li2
1
School of Software Engineering, Chongqing University of Arts and Sciences, Chongqing, China 2
School of Computer Science, Beijing Institute of Technology, Beijing, China
ABSTRACT: The distributed shared memory system provides a development road for establishment of a large-scale easy-to-use parallel computer, and the improvement of its corresponding algorithm can optimize the distributed shared memory. This paper mainly summarizes the spatial data memory system and parallel cessing methods, thus providing the specific theoretical guidance for the parallel spatial data memory and pro-cessing. This paper also analyzes and improves the basic distributed shared IO algorithm of the central server algorithm, migration algorithm, read-replication algorithm and full-replication algorithm, and then focuses on discussion of the consistency model of the distributed shared memory, and analyzes the direction of using differ-ent consistency models, and points out the shortcomings of traditional methods to store and process massive spatial data, thus providing a theoretical direction for the future improvement of the memory.
grammer a unified address space logically. Any pro-cessor can directly implement read-write operations for this address space. The programmer can carry out programming by the shared memory model, so the parallel programming in the distributed memory sys-tem becomes easier.
Figure 1. Distributed shared memory model.
Meanwhile, the distributed shared memory system retains the features of easy construction and expansion of the distributed memory system, thus providing a development road to build a large-scale easy-to-use parallel computer. Overall, the distributed shared memory has the following advantages:
1. It facilitates the programmer’s programming. 2. The algorithm of the shared memory system and
software are allowed to be used in the distributed system.
3. The distributed systems can be extended on a larger scale due to the lack of software bottle-necks.
4. The low-power consumption memory is possible.
This paper focuses on summarizing the IO algo-rithm of the distributed shared memory and con-sistency model.
2 ALGORITHM RESEARCH OF THE DISTRIBUTED SHARED MEMORY
The distributed shared memory system must be able to automatically change inter-process communication of the shared memory access. It requires the algorithm to storage and access the shared data, and maintain data
consistency and data replacement. The algorithm is implemented in DSM, so as to solve the following two issues:
1. Minimize the time for system to access shared data under the static and dynamic state.
2. Maintain the consistency of shared data and minimize the consistency consumption of man-agement.
This section will describe four types of basic dis-tributed shared IO algorithm, which will be classified based on whether they have migrated or copied data. Four types of algorithm are respectively the central server algorithm, migration algorithm, read-replication algorithm and full-replication algorithm. As shown in Figure 2, the migration algorithm and the read- repli-cation algorithm require to migrate data in order to locally access the data, and these two should reduce the number of remote access, thus avoiding commu-nication consumption; the read-replication algorithm and full-replication algorithm require to process data in order to multiple access at the same time. Next, four types of algorithm will be introduced in detail.
2.1 Central server algorithm
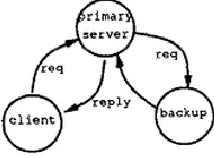
The central server algorithm is a kind of algorithm without data migration and replication, which is the simplest algorithm implemented by the distributed shared memory. The central server algorithm uses a central server to be responsible for providing services for access to the shared data, and keep a sole duplicate of the shared data. The read-write operation involves in the process of the operation sending the request message to the data server. Data server executes re-quest and answer. The read operation answers the data item, while the write operation answers the recogni-tion, as shown in Figure 3. The central server algo-rithm requires send information twice for each data access: first, the request of the process accessing the data server; second, the answer of the data server.
However, the potential problem of this algorithm is that the central server is likely to be a bottleneck, be-cause it needs to respond to all customer service re-quests. The organizational structure of the central server algorithm is free of any physical distribution of shared data. A simple improvement is to distribute the shared data to multiple different servers. However, in this case, the client must find the correct server when
[image:2.516.124.393.586.658.2]accessing data. A better solution is to divide the data through the virtual address and simple matching, so as to determine the servers to be connected.
2.2 Migration algorithm
In other literatures, the migration algorithm is also known as “a single-reader/single-writer algorithm”. When it is accessed, the data of the algorithm is al-ways migrated to the specified location. Reading or writing of a given data can only be done once on one host, as shown in Figure 4.
The advantages of this algorithm: 1) When the pro-cess acpro-cesses the current local data, there is not any communication consumption. If an application pro-gram reveals a very high locality, the cost of data mi-gration will be amortized by multiple accesses. 2) If the selected module size is the same with the page size of the virtual memory, the algorithm can be integrated with the virtual memory system of the master operat-ing system.
In case of a longer access, it is possible for one processor to uninterruptedly access the sequence of
other processors. In this case, the migration algorithm can perform well. However, the migration algorithm has a very low performance, because it does not take full advantage of the parallel potential of multiple read-only duplicates, which is also a reason to rarely use the migration algorithm.
2.3 Read-replication algorithm
The read-replication algorithm is also known as mul-ti-reader/single-writer algorithm, which can reduce the average power consumption of the read operation.
The difference between the read-replication algo-rithm and the migration algoalgo-rithm is that, when a node accesses the remote data block, it duplicates the data block rather than migration. Thus, a data block may have multiple read-only duplicates in different nodes.
If one node is allowed to read and write the dupli-cate of the specified block, or multiple nodes are al-lowed to read only the duplicate of this block, the replication algorithm can be naturally turned into the migration algorithm, as shown in Figure 5.
[image:3.516.138.376.47.400.2]The read-replication algorithm can be divided into:
[image:3.516.141.374.59.220.2]Figure 3. Central server algorithm.
Figure 4. Migration algorithm.
[image:3.516.142.371.300.394.2](1) Central manager algorithm
(2) Improved central manager algorithm (3) Fixed distribution manager algorithm (4) Broadcast distribution manager algorithm (5) Dynamic distribution manager algorithm
2.4 Full-replication algorithm
The full-replication algorithm is also known as mul-ti-reader/multiple-writer algorithm. All data of this algorithm have duplicates at all nodes. It allows that the data blocks can also be replicated while writing. The maintenance of data consistency of the full- rep-lication algorithm is the most complex. One possible approach is to use a global sequencer for globally sequencing all write operations, and just sequence the read operations related to write operations on the nodes of executing read operations.
[image:4.516.53.253.334.430.2]For the read operation without local module data, there is a need to communicate with far nodes to ob-tain read-only replication before completion of read operations, and then rewrite read-only replication as replication. For the write operation without local module data, the replication of the same module with all other nodes will be an invalid state before write process. The algorithm operation is shown in Figure 6:
Figure 6. Full-replication algorithm.
2.5 Fault-tolerant DSM algorithm
One of the biggest problems of the above DSM algo-rithm is that they do not have a fault-tolerant function. Michael Stumm and Songnian Zhou expand the above four primary algorithms to the algorithm that can tol-erate the fault of a single host, and prove that the fault-tolerant ability under these degrees is effective in many applications.
The central server fault-tolerant algorithm is shown in Figure 7:
Figure 7. Central server fault-tolerant algorithm.
The central server fault-tolerant algorithm only adds a backup server on the basis of the original central server algorithm, so the algorithm can tolerate a single fault.
In the migration algorithm, the error recovery pro-gram is very simple.
All host pages will be recovered by their backup when they go wrong. Establishing a module needs to obey the command: If the host could not place the module to be accessed, it will place the backup of the module. If this backup is local, a new backup will be migrated to a remote host and set to be invalid; other-wise, this backup will be migrated to the host that can be accessible. Because the recovery time which is caused by making the host module obey command again is unable to be determined, determining and recovering the missing module becomes more im-portant as long as the wrong host is found out.
3 CONSISTENCY MODEL OF THE DISTRIBUTED SHARED MEMORY
In the distributed shared memory system, the shared data can be accessed simultaneously by multiple pro-cessors. If all shared data in the system keep only one backup, it may lead to access a lot of faults and trans-fer data, so the performance is greatly reduced. To improve the performance, the shared data are allowed to have multiple accessible backups. However, multi-ple backups of the shared data bring a new problem: how to ensure that these backups are consistent? Therefore, the memory consistency model is a key problem of the distributed shared memory IO algo-rithm.
Currently, the consistency models of the distributed shared memory are as follows:
- Strict consistency model - Sequential consistency model - Causal consistency model - PRAM consistency model
3.1 Strict consistency model
If any read access to any memory unit will be returned to the written value of the last write access to the same unit, this memory system is strictly consistent. Strict consistency is the strictest among all memory con-sistency models. The strict concon-sistency model is de-rived directly from the memory model of the unipro-cessor system, which requires that the multi-prounipro-cessor system is the same with a stand-alone system. If a processor issues a write operation, the operation will be completed immediately globally, that is, immedi-ately found out by other processors. Figure 8 displays the execution of strict consistency. The write opera-tion of processing P1 is “immediately” seen by P2.
[image:4.516.98.205.578.656.2]strictions on the sequence of memory events. It re-quires all machines (including the processors issuing the write operation) not to do new memory operations before global completion of write operation issued by a processor. The cost of meeting this requirement is very high, but it is almost impossible to realize the distributed shared memory system.
Figure 8. Schematic diagram of strict consistency model.
3.2 Sequential consistency model
The sequential consistency is proposed by Lamport, which is defined as: In a multi-processor system, the results obtained by the implementation of any pro-grams and the operation of all processors are operated in a particular order, and the results obtained by the operation of each processor in accordance with the order specified by its program are the same, so we say that the system is sequential consistency. Figure 9 shows the execution of the sequential consistency and the subsequent orders after P1 processing:
2( )1 1( )1 2( )2
w x r x w x
Figure 9. Schematic diagram of sequential consistency model.
The memory behavior specified by the sequential consistency is consistent with the intuition of most programmers. Each processor sequentially issues the memory requests in accordance with its program, while the memory just serves for one request once, and serves between various processors according to an arbitrary order, and ensures that the requests of all processors will be served.
3.3 Causal consistency model
The causal consistency model is proposed by Hutto and Ahamad, which is defined as: In the causal con-sistency model, two write operations with a causal relationship must be completed in the same order with respect to various processors; the concurrent write operation can be completed in different orders with respect to various processors.
The execution of Figure 10 is in line with causal
[image:5.516.78.227.136.186.2]consistency, because W (A) 1 of P1 and W (A) 2 of P4 are concurrent. The examples in Figure 3 and Figure 4 violate the causal consistency, because the read opera-tion R (A) 1 of P4 makes W (A) 1 of P1 and W (A) 2 of P4 become the causal operation.
Figure 10. Schematic diagram of causal consistency model.
The causal consistency model reduces the require-ments of the sequential consistency model on the ato-micity of memory operation. The concurrent write operations are not required to be completed in the same order with respect to various processors. How-ever, it is very difficult to achieve the causal con-sistency model, because it requires determine whether there is a causal relationship between various memory operations.
3.4 PRAM consistency model
PRAM refers to the “random access memory”, which is proposed by Lipton and Salldberg. In the PRAM consistent system, the write operation issued by the same processor shall be completed in the same order with respect to other processors, while the write oper-ation issued by different processors can be completed in different orders with respect to various processors.
[image:5.516.67.236.358.440.2]4 CONCLUSION
In IO algorithm, the time complexity and space com-plexity are two common measurement standards. However, in the distributed system, there is generally not the concept of time, especially in the multiple systems. A more popular measurement standard in the distributed system is the information complexity. It is the total number of information exchanged by the algorithm. We measure by the use of the information complexity in most cases unless the considered system includes many long messages and short messages. Many distributed algorithms are uncertain. And the performance tests may vary due to different operations. Therefore, this paper summarizes IO algorithm and consistency of the distributed system.
REFERENCES
[1] Han Dezhi, Xie Changsheng, Li Huaiyang. 2004. Analy-sis of memory backup technology. Compute Application. [2] Xu Fei, Yang Guangwen, Ju Dapeng. 2004. Design of distributed memory system based on Peer-to-Peer.
Journal of Software, 2(15): 268-277.
[3] Wei Qingsong, Lu Xianliang, Lei Yu. 2003. FTDSS: High fault-tolerance distributed shared memory mecha-nism. Computer Science, 30 (8): 172-175.
[4] Sun Ronghui, Liu Xianlin, Zhao Wenji. 2006. Research on Shapefile data memory based on Oracle Spatial.
Journal of Capital Normal University (Natural Science).
Phase 5.
[5] Zhao Chunyu, Meng Lingkui, Lin Zhiyong. 2006. Re-search on data partitioning algorithm for parallel spatial database. Journal of Wuhan University, 31(11). [6] Hey T., Tansley S., Tolle K.M. 2012. The Fourth
Para-digm: Data-Intensive Scientific Discovery. Berlin Hei-delberg: Springer.
[7] Graham M.J., Djorgovski S., Mahabal A., et al. 2012. Data challenges of time domain astronomy. Distributed
and Parallel Databases, pp: 1-14.
[8] Sadalage P.J., Fowler M. 2012. NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence. New York: Addison-Wesley.
[9] Gong Jing, Lei Junzhi, Long Yang, et al. 2013. Cloud
Memory Parsing. Beijing: People’s Posts and
Telecom-munications Press.
[10] Liu Peng, Luo Shengmei, Zhao Gansen. 2013. Chinese
Cloud Memory Development Report. Beijing: Electronic
Industry Press.
[11] Li Xin. 2010. Research on Metadata Management
Strategy in the Distributed File System. Wuhan:
Huazhong University of Science and Technology. [12] Yang Dezhi. 2008. Research on Key Issues of
Extenda-ble Metadata Service of the Distributed File System. Beijing: Graduate School of Chinese Academy of Sci-ences (Institute of Computing Technology).
[13] Liu Likun. 2011. Metadata Query Methods and Tech-niques of Massive File System. Beijing: Tsinghua Uni-versity.
[14] Wu Wei. 2010. Research on Metadata Management of
Mass Memory System. Wuhan: Huazhong University of
Science and Technology.
[15] He Feiyue. 2004. Research on Metadata Management of
Parallel File System. Wuhan: Huazhong University of
Science and Technology.
[16] Xiong J., Hu Y., Li G., et al. 2011. Metadata distribution and consistency techniques for large-scale cluster file systems. IEEE Transactions on Parallel and Distributed Systems, 22(5): 803-816.
[17] Niu D.J., Cai T., Zhan Y.Z., et al. 2012. Metadata in-dexing sub-system for distributed file system. Applied
Mechanics and Materials, 143: 864-868.
[18] Alam S.R., El-Harake H.N., Howard K., et al. 2011. Parallel I/O and the metadata wall. Proceedings of the sixth workshop on Parallel Data Memory, Seattle,
Washington, USA, pp: 13-18.
[19] Hackl G., Pausch W., Schönherr S., et al. 2010. Syn-chronous metadata management of large memory sys-tems. Proceedings of the Fourteenth International Da-tabase Engineering & Applications Symposium, pp: 1-6. [20] Díaz A.F., Anguita M., Camacho H.E., et al. 2012. Two-level Hash/Table approach for metadata manage-ment in distributed file systems. The Journal of