Technology (IJRASET)
A Graph Oriented: Text Database for Knowledge
Exposure
Navneet Kr. Kashyap
Research Scholar, Department of Information Technology, College of Technology
Govind Ballabh Pant University of Agriculture and Technology, Pantnagar-263145, Uttarakhand, India
Abstract: While we hope to find information in the writings accessible on the Web, such revelation more often than not requires numerous perplexing examination steps, the vast majority of which require different content taking care of operations, for example, comparable content inquiry or content grouping. Drawing a similarity from the relational, we master represent a content representation display that simplifies the strides. The model speaks to writings in a formal way, Subject Graphs, depicted, gives content taking care of operations whose inputs and yields are indistinguishable in structure, i.e. an arrangement of subject graphs. We build up a graphs based content database, which depends on the model, and an intuitive information disclosure framework. Trials of the framework demonstrate that it permits the client to intelligently and naturally find information in Web pages by consolidating content taking care of operations defined on subject graphs in different requests.
INDEX TERMS: Data query and recovery – recovery models, examination process, Subject Graphs, information exposure, And user friendly Search
I. INTRODUCTION
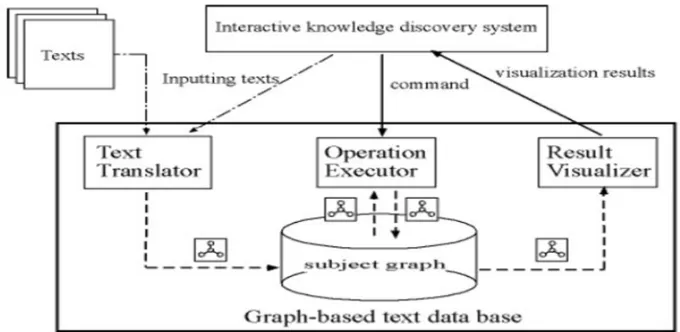
[image:2.612.152.492.475.641.2]The Web is an enormous, different and dynamic data source, and learning can be found on it. Information is defined here as imperative actualities that sup-port a man in settling on a choice. Learning disclosure more often than not requires complex examination steps that comprise of a heterogeneous mix of content taking care of operations, for example, seeking, grouping, outlining, and looking at [3]. With respect to organized information, Relational Data Model (RDM) empowers a few information taking care of operations to be joined, on the grounds that it speaks to information in a formal way, i.e. relations, and ace vides information taking care of operations whose inputs and yields are indistinguishable in structure, i.e. an arrangement of relations [1]. By relationship with RDM, we propose a chart based content representation demonstrate that speaks to writings in a formal manner, i.e. Subject Graphs[6] and gives content taking care of operation elations whose inputs and yields are indistinguishable in structure, i.e.
Figure 1: Graphical record-based text database and user friendly information disclosure setup
Technology (IJRASET)
database (GTB) taking into account the model and an interactive information disclosure framework those utilizations GTB. Trials of the framework demonstrate our model can be effective for information revelation.
[image:3.612.92.522.286.483.2]II. GRAPH-BASED TEXT DATABASE
Figure 1 graph the GTB and a related intuitive information revelation framework. The content interpreter translates every content into a subject graph by 1) extracting terms from the content, 2) figuring the significance of every term from its event recurrence utilizing a variation of the BM25 method [4], and 3) calculating the significance of every term-term relationship from the co-event recurrence of two terms in a unit, for example, sentence, provision, or a word window. The operation agent executes graph taking care of musical drama tions whose inputs and yields are an arrangement of subject graph. To accomplish a full arrangement of investigation steps, we define 6 musical drama tions: (a)searching for comparative graph, (b) grouping graphs, (c) extricating incomplete graphs, (d) including graphs (combining and averaging graphs), (e)subtracting graphs, (f) selecting graph by qualities. The subtle elements of these operations are de-scribed in [6] and the following segment. These operations can be consolidated in any request, since every one of them information and yield an arrangement of subject graphs. In spite of the fact that we define here just 6 operation erations, any operation whose inputs and yields are an arrangement of subject graphs can be joined into the module. The outcome visualizer imagines the operation results by utilizing the spring model[2]. Clients can comprehend the significant terms and the term-term relationship from the perception results, thus can get a handle on the substance of the discovered writings.
[image:3.612.129.517.525.674.2]Figure 2: The graphical user interface of the user friendly information disclosure setup
Technology (IJRASET)
III. ASSESSMENTS
Figure 2 demonstrates the client interface of the framework. The user can summon content taking care of operations in different orders interactively and instinctively through these windows. 247,489 Web pages in the WT2G test collection1 were utilized as the focused on content information. The objective of the client is to find knowledge, for example, 'Who is the best social database merchant?', How do clients rate the items?' and 'Are there any competitive items?'. Utilizing the framework, the most likely investigation steps are as per the following.
The client inputs the expression 'social database' and summons (a). The framework finds 253 Web pages like it. The client summons (f) with the condition indicating an a characteristic contains the name of database merchant. The client finds that the Oracle site has the most references, 11. The client summons (d) to make a combined graph (go) to diagram of the considerable number of pages referencing the Oracle site, and (b) to bunch them with comparable substance. The framework classifies them into 5 classes (7,3,1,1,1). The client conjures (d) for the pages in every class, (e) to subtract go from each blended graph, and (c) utilizing 'social database' as the condition. The framework consolidates graphs in each violent, subtracts go from each combined diagram, and concentrates the incomplete graph that has hubs neighboring to 'social database' from each subtracted diagram. These operations think about the substance of every class by concentrating on 'relational database'. Figure 3 indicates two graph from Cluster 1 and Cluster 2. From Figure 3, Cluster 1 is by all accounts relevant to InterOffice, while Cluster 2 appears to contrast Oracle and Infomix or DB22.
To sum things up, from these intelligent strides, the client can find information, for example, (A) The social database seller that is drawing in consideration is Oracle. (B)The name of Oracle's item is InterOffice. The rating and specification of the item might be found in the pages in Cluster 1. (C) Its rivals are Informix and DB2. Correlations might be found in the pages of Cluster 2. Along these lines, the interactive strides offered by the framework diminish the client's effort in finding learning in Web pages.
IV. RELATED WORKS
Term vectors are broadly utilized for formal content representation. Contrasted with term vectors, Subject Graphs permit the similitude between writings to be figured all the more decisively and give better representation results by joining term-term affiliations. Besides, Subject Graphs bolster complex operations, for example, removing fractional charts, which is unrealistic if just term vectors are utilized. Applied Graphs[5] can be utilized to speak to writings. In spite of the fact that they may speak to the substance of a content adroitly, applying them to Web pages is difficult. This is on the grounds that they depend on profound investigation, thus require all around kept up lexicons and an unnecessary measure of time to work.
V. CONCLUSION
We proposed a content representation demonstrate that permits a wide assortment of content taking care of operations to be consolidated for understanding the intricate investigation steps expected to find learning. We executed the model by utilizing Subject Graphs as the formal content representation. A chart construct content database based with respect to the model and an intuitive knowledge revelation framework were actualized. Trials confirmed that the proposed model diminishes the client's effort and is effective for finding information in writings on the Web.
VI. ACKNOWLEDGEMENTS
I am immensely indebted and owe my due regard to Dr. H. L. Mandoria, Professor, Information Technology Department, Mr. Binay Kumar Pandey, Assistant Professor, Information Technology Department, Mr. Ashok Kumar & Mr. Rajesh Shyam Singh, Assistant Professor, Information Technology Department and the members of my advisory committee for their persistent encouragement and support.
REFERENCES
[1] Agrawal R, Srikant R. Fast algorithms for mining association rules. In: VLDB’94, Sept. 1994, 1994. pp. 487–99.
[2] Cook DJ, Holder LB. Graph-based data mining, IEEE Intell Syst 2000;15(2)p.p 21-35.
[3] Inokuchi A, Washio T, Motoda H. An apriori-based algorithm for mining frequent substructures from graph data. In: PKDD’00, 2000. pp. 13–23.
[4] Kuramochi M, Karypis G. Frequent subgraph discovery. In: ICDM’01, Nov. 2001. 2001. pp. 313–20.
[5] Yan X, Han J. gSpan: graph-based substructure pattern mining. In: Technical report UIUCDCS-R-2002-2296. Champaign: Department of Computer Science,
Technology (IJRASET)
ACM, 2004. New York, pp. 335–46.
[8] Niewiadomski R, Amaral J, Holte R. A parallel external-memory frontier breadth-first traversal algorithm for clusters of workstations. In: IEEE ICPP, 2006.
[9] Wang J, Hsu W, Li ML, Sheng C. A partition-based approach to graph mining. In: Proceedings of the 22nd international conference on data engineering
(ICDE’06)8-7695-2570-9/06 $20.00 © 2006 IEEE.
[10] Eichinger F, Böhm K, Huber M. Improved software fault detection with graph mining. In: Appearing in the 6th international workshop on mining and learning
with graphs, Helsinki, Finland, 2008.
[11] Sequeda J, Arenas M, Miranker DP. On directly mapping relational databases to RDF and OWL. In WWW, pp. 49-58, 2012.
[12] Navneet Kumar Kashyap, Binay Kumar Pandey, H. L. Mandoria & Ashok Kumar,“A Comprehensive Study Of Various Kinds Of Frauds & It’s Impact”,
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) ISSN(P): 2249-6831; ISSN(E): 2249-7943 Vol. 6, Issue 3, Jun 2016, 47-58,
[13] Navneet Kumar Kashyap, Binay Kumar Pandey, H. L. Mandoria & Ashok Kumar, “A Review Of Leading Database: Relational & Non-Relational Database”,
I-Manager's Journal On Information Technology (JIT) ISSN (P): 2277-5110; ISSN (E): 2277-5250, (Accepted On May 31, 2016)
[14] Navneet Kumar Kashyap, Binay Kumar Pandey, H. L. Mandoria & Ashok Kumar, “Comprehensive Study of Different Pattern Recognition Techniques”,