An Algorithm for Pronominal Anaphora
Resolution
Shalom Lappin"
SOAS, University of L o n d o n
H e r b e r t
J.
Leass t
Sietec SystemtechnikThis paper presents an algorithm for identifying the noun phrase antecedents of third person pronouns and lexical anaphors (reflexives and reciprocals). The algorithm applies to the syntactic representations generated by McCord's Slot Grammar parser and relies on salience measures derived from syntactic structure and a simple dynamic model of attentional state. Like the parser, the algorithm is implemented in Prolog. The authors have tested it extensively on computer manual texts and conducted a blind test on manual text containing 360 pronoun occurrences. The algorithm successfully identifies the antecedent of the pronoun for 86% of these pronoun occurrences. The relative contributions of the algorithm's components to its overall success rate in this blind test are examined. Experiments were conducted with an enhancement of the al- gorithm that contributes statistically modelled information concerning semantic and real-world relations to the algorithm's decision procedure. Interestingly, this enhancement only marginally improves the algorithm's performance (by 2%). The algorithm is compared with other approaches to anaphora resolution that have been proposed in the literature. In particular, the search proce- dure of Hobbs'algorithm was implemented in the Slot Grammar framework and applied to the sentences in the blind test set. The authors" algorithm achieves a higher rate of success (4%) than Hobbs' algorithm. The relation of the algorithm to the centering approach is discussed, as well as to models of anaphora resolution that invoke a variety of informational factors in ranking antecedent candidates.
1. Introduction
We present an algorithm for identifying b o t h intrasentential a n d intersentential an- tecedents of p r o n o u n s in text. We refer to this algorithm as R A P (Resolution of Ana- p h o r a Procedure). R A P applies to the syntactic structures of M c C o r d ' s (1990, 1993, in press) Slot G r a m m a r parser, a n d like the parser, it is i m p l e m e n t e d in Prolog. It relies o n m e a s u r e s of salience d e r i v e d from syntactic structure a n d a simple d y n a m i c m o d e l of attentional state to select the antecedent n o u n phrase (NP) of a p r o n o u n f r o m a list of candidates. It does n o t e m p l o y semantic conditions ( b e y o n d those implicit in
grammatical n u m b e r a n d g e n d e r agreement) or real-world k n o w l e d g e in evaluating candidate antecedents; n o r does it m o d e l intentional or global discourse structure (as in Grosz a n d Sidner 1986).
* School of Oriental and African Studies, University of London, London WCIH OXG, UK. E-mail:
slappin@clusl .ulcc.ac.uk
Most of the first author's work on this paper was done while he was a Research Staff Member in the Computer Science Department of the IBM T.J. Watson Research Center.
t Sietec Systemtechnik (Siemens AG), D-13623 Berlin, Germany. E-mail: [email protected]
In Section 2 we present RAP and discuss its main properties. We p r o v i d e examples of its o u t p u t for different sorts of cases in Section 3. Most of these examples are taken from the c o m p u t e r m a n u a l texts on which w e trained the algorithm. We give the results of a blind test in Section 4, as well as an analysis of the relative contributions of the algorithm's c o m p o n e n t s to the overall success rate. In Section 5 we discuss a p r o c e d u r e d e v e l o p e d b y D a g a n (1992) for using statistically m e a s u r e d lexical preference patterns to reevaluate RAP's salience rankings of a n t e c e d e n t candidates. We present the results of a c o m p a r a t i v e blind test of RAP and this procedure. Finally, in Section 6 w e c o m p a r e RAP to several other a p p r o a c h e s to a n a p h o r a resolution that have b e e n p r o p o s e d in the c o m p u t a t i o n a l literature.
2. The Anaphora Resolution Algorithm
RAP contains the following main components.
• An intrasentential syntactic filter for ruling out anaphoric d e p e n d e n c e of a p r o n o u n on an N P on syntactic g r o u n d s (This filter is p r e s e n t e d in L a p p i n and M c C o r d 1990a.)
• A m o r p h o l o g i c a l filter for ruling out anaphoric d e p e n d e n c e of a p r o n o u n o n an N P d u e to n o n - a g r e e m e n t of person, number, or g e n d e r features
• A p r o c e d u r e for identifying pleonastic (semantically e m p t y ) p r o n o u n s • An a n a p h o r b i n d i n g algorithm for identifying the possible a n t e c e d e n t b i n d e r of a lexical a n a p h o r (reciprocal or reflexive p r o n o u n ) within the same sentence (This algorithm is p r e s e n t e d in L a p p i n a n d M c C o r d 1990b.)
• A p r o c e d u r e for assigning values to several salience p a r a m e t e r s (grammatical role, parallelism of grammatical roles, f r e q u e n c y of
mention, proximity, a n d sentence recency) for an NP. (Earlier versions of these p r o c e d u r e s are p r e s e n t e d in Leass a n d Schwall 1991.) This
p r o c e d u r e e m p l o y s a grammatical role hierarchy according to w h i c h the evaluation rules assign higher salience weights to (i) subject o v e r non-subject NPs, (ii) direct objects o v e r o t h e r c o m p l e m e n t s , (iii) a r g u m e n t s of a verb o v e r adjuncts a n d objects of prepositional p h r a s e (PP) adjuncts of the verb, a n d (iv) h e a d n o u n s o v e r c o m p l e m e n t s of h e a d nouns. 1
• A p r o c e d u r e for identifying anaphorically linked NPs as an equivalence class for w h i c h a global salience value is c o m p u t e d as the s u m of the salience values of its elements.
• A decision p r o c e d u r e for selecting the p r e f e r r e d e l e m e n t of a list of a n t e c e d e n t candidates for a p r o n o u n .
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
2.1 Some Preliminary Details
RAP has been implemented for both ESG and GSG (English and German Slot Gram- mars); we will limit ourselves here to a discussion of the English version. The differ- ences between the two versions are at present minimal, primarily owing to the fact that we have devoted most of our attention to analysis of English. As with Slot Gram- mar systems in general (McCord 1989b, 1993, in press), an architecture was adopted that "factors out" language-specific elements of the algorithm.
We have integrated RAP into McCord's (1989a, 1989b) Logic-Based Machine Trans- lation System (LMT). (We are grateful to Michael McCord and Ullrike Schwall for their help in implementing this integration.) When the algorithm identifies the antecedent of a p r o n o u n in the source language, the agreement features of the head of the NP cor- responding to the antecedent in the target language are used to generate the pronoun in the target language. Thus, for example, neuter third person pronouns in English are m a p p e d into pronouns with the correct gender feature in German, in which inanimate nouns are marked for gender.
RAP operates primarily on a clausal representation of the Slot Grammar analysis of the current sentence in a text (McCord et al. 1992). The clausal representation consists of a set of Prolog unit clauses that provide information on the h e a d - a r g u m e n t and head-adjunct relations of the phrase structure that the Slot Grammar assigns to a sentence (phrase). Clausal representations of the previous four sentences in the text are retained in the Prolog workspace. The discourse representation used by our algorithm consists of these clausal representations, together with additional unit clauses declaring discourse referents evoked by NPs in the text and specifying anaphoric links among discourse referents. 2 All information pertaining to a discourse referent or its evoking NP is accessed via an identifier (ID), a Prolog term containing two integers. The first integer identifies the sentence in which the evoking NP occurs, with the sentences in a text being numbered consecutively. The second integer indicates the position of the NP's head word in the sentence.
2.1.1 The Syntactic Filter on Pronoun-NP Coreference. The filter consists of six con- ditions for N P - p r o n o u n non-coreference within a sentence. To state these conditions, we use the following terminology. The
agreement features
of an NP are its number, person, and gender features. We will say that a phrase P is in theargument domain
of a phrase N iff P and N are both arguments of the same head. We will say that P is in theadjunct domain
of N iff N is an argument of a head H, P is the object of a preposition PREP, and PREP is an adjunct of H. P is in theNP domain
of N iff N is the determiner of a noun Q and (i) P is an argument of Q, or (ii) P is the object of a preposition PREP and PREP is an adjunct of Q. A phrase P iscontained in
a phrase Q iff (i) P is either an argument or an adjunct of Q, i.e., P isimmediately contained in
Q, or (ii) P is immediately contained in some phrase R, and R is contained in Q.A pronoun P is non-coreferential with a (non-reflexive or non-reciprocal) noun phrase N if any of the following conditions hold:
1. P and N have incompatible agreement features.
2. P is in the argument domain of N. 3. P is in the adjunct domain of N.
.
.
6.
P is an a r g u m e n t of a head H, N is not a pronoun, a n d N is contained in H.
P is in the NP d o m a i n of N.
P is a determiner of a n o u n Q, a n d N is contained in Q.
Examples of coindexings that w o u l d be rejected by these conditions are given in Figure 1.
Condition 1:
The womani said that he/is funny.
Condition 2: Shei likes her/.
John/seems to want to see himi.
Condition 3:
She/sat near her/.
Condition 4:
He/believes that the mani is amusing. This is the man/hei said John/wrote about.
Condition 5:
John/s portrait of himi is interesting.
Condition 6:
Hisi portrait of John/is interesting.
Hisi description of the portrait by John/is interesting.
Figure 1
Conditions on NP-pronoun non-coreference (examples).
2.1.2 Test for Pleonastic Pronouns. The tests are partly syntactic a n d partly lexical. A class of m o d a l adjectives is specified. It includes the following items (and their corre- sponding morphological negations, as well as comparative a n d superlative forms).
necessary possible certain likely important good useful advisable convenient sufficient economical easy desirable difficult legal
A class of cognitive verbs with the following elements is also specified.
recommend think believe know anticipate assume expect
It appearing in the constructions of Figure 2 is considered pleonastic (Cogv-ed = passive
participle of cognitive verb); syntactic variants of these constructions (It is not~may be Modaladj..., Wouldn't it be Modaladj . . . . etc.) are recognized as well.
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
Figure 2
Pleonastic uses of it.
It is M o d a l a d j that S
It is M o d a l a d j (for NP) to V P It is C o g v - e d that S
It s e e m s / a p p e a r s / m e a n s / f o l l o w s (that) S
NP
m a k e s / f i n d s it M o d a l a d j (for NP) to VP It is time to VPIt is thanks to N P that S
analysis grammars. 3
2.1.3
The Anaphor Binding Algorithm.
The notion higher argument slot used in the following f o r m u l a t i o n of the binding algorithm is defined b y the following hierarchy of a r g u m e n t slots:subj > agent > obj > (iobjlpobj)
Here subj is the surface subject slot, agent is the deep subject slot of a verb heading a passive VP, obj is the direct object slot, iobj is the indirect object slot, and pobj is the
object of a PP c o m p l e m e n t of a verb, as in put N P on NP. We a s s u m e the definitions of a r g u m e n t domain, adjunct d o m a i n , and N P d o m a i n given above.
A n o u n p h r a s e N is a possible a n t e c e d e n t b i n d e r for a lexical a n a p h o r (i.e., re- ciprocal or reflexive p r o n o u n ) A iff N a n d A d o not have incompatible a g r e e m e n t features, a n d one of the following five conditions holds.
1.
,
3. 4.
.
A is in the a r g u m e n t d o m a i n of N, and N fills a higher a r g u m e n t slot than A.
A is in the adjunct d o m a i n of N. A is in the N P d o m a i n of N.
N is an a r g u m e n t of a verb V, there is an N P Q in the a r g u m e n t d o m a i n or the adjunct d o m a i n of N such that Q has no n o u n determiner, a n d (i) A is an a r g u m e n t of Q, or (ii) A is an a r g u m e n t of a preposition PREP and PREP is an adjunct of Q.
A is a d e t e r m i n e r of a n o u n Q, a n d (i) Q is in the a r g u m e n t d o m a i n of N and N fills a higher a r g u m e n t slot than Q, or (ii) Q is in the adjunct d o m a i n of N.
Examples of bindings licensed b y these conditions are given in Figure 3.
2.1.4
Salience Weighting.
Salience weighting is accomplished using salience factors. A given salience factor is associated with one or m o r e discourse referents. These dis- course referents are said to be in the factor's scope. A w e i g h t is associated with eachCondition 1:
They/wanted to see themselves/.
Mary knows the people/who John introduced to each other/.
Condition 2:
Hei worked by himself/.
Which friends/plan to travel with each other/?
Condition 3:
John likes Bill/s portrait of himselfi.
Condition 4:
They/told stories about themselves/.
Condition 5:
[John and Mary]/like each otheri's portraits.
Figure 3
Conditions for antecedent NP-lexical anaphor binding.
factor, reflecting its relative c o n t r i b u t i o n to the t o t a l salience of i n d i v i d u a l discourse referents. Initial w e i g h t s are d e g r a d e d in the course of processing.
The u s e of salience factors in o u r a l g o r i t h m is b a s e d o n A l s h a w i ' s (1987) context m e c h a n i s m . O t h e r t h a n sentence recency, the factors u s e d in R A P differ f r o m A l s h a w i ' s a n d are m o r e specific to the task of p r o n o m i n a l a n a p h o r a resolution. A l s h a w i ' s f r a m e - w o r k is d e s i g n e d to deal w i t h a b r o a d class of l a n g u a g e i n t e r p r e t a t i o n p r o b l e m s , including reference resolution, w o r d sense d i s a m b i g u a t i o n , a n d the i n t e r p r e t a t i o n of implicit relations. While A l s h a w i d o e s p r o p o s e e m p h a s i s factors for m e m o r y entities that are "referents for n o u n p h r a s e s p l a y i n g syntactic roles r e g a r d e d as f o r e g r o u n d i n g the referent" (Alshawi 1987, p. 17), o n l y topics of sentences in the p a s s i v e voice a n d the agents of certain be clauses receive such e m p h a s i s in his system. O u r e m p h a s i s salience factors realize a m u c h m o r e detailed m e a s u r e of structural salience.
D e g r a d a t i o n of salience factors occurs as the first step in p r o c e s s i n g a n e w sentence in the text. All salience factors that h a v e b e e n a s s i g n e d p r i o r to the a p p e a r a n c e of this sentence h a v e their w e i g h t s d e g r a d e d b y a factor of two. W h e n the w e i g h t of a g i v e n salience factor reaches zero, the factor is r e m o v e d .
A sentence recency salience factor is created for the c u r r e n t sentence. Its s c o p e is all discourse referents i n t r o d u c e d b y the c u r r e n t sentence.
The discourse referents e v o k e d b y the c u r r e n t sentence are tested to see w h e t h e r other salience factors s h o u l d apply. If at least o n e discourse referent 4 satisfies the conditions for a g i v e n factor type, a n e w salience factor of that t y p e is created, w i t h the a p p r o p r i a t e discourse referents in its scope.
In a d d i t i o n to sentence recency, the a l g o r i t h m e m p l o y s the following salience fac- tors:
Subject emphasis
Existential emphasis:
p r e d i c a t e n o m i n a l in an existential construction, as inT h e r e a r e o n l y a few restrictions on LQL q u e r y c o n s t r u c t i o n f o r WordSmith.
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
Table 1
Salience factor types with initial weights
Factor type Initial weight
Sentence recency 100
Subject emphasis 80
Existential emphasis 70
Accusative emphasis 50
Indirect object and oblique complement emphasis 40
Head noun emphasis 80
Non-adverbial emphasis 50
A c c u s a t i v e e m p h a s i s : direct object (i.e., v e r b a l c o m p l e m e n t in accusative case) I n d i r e c t o b j e c t a n d o b l i q u e c o m p l e m e n t e m p h a s i s
H e a d n o u n e m p h a s i s : a n y N P not contained in a n o t h e r NP, using the Slot G r a m m a r notion of " c o n t a i n m e n t w i t h i n a p h r a s e " (see Section 2.1.1). This factor increases the salience v a l u e of an N P that is not e m b e d d e d within a n o t h e r N P (as its c o m p l e m e n t or adjunct). E x a m p l e s of N P s
not
receiving h e a d n o u n e m p h a s i s arethe configuration information copied by
Backup configuration
t h e a s s e m b l y i n
bay C
t h e c o n n e c t o r l a b e l e d
P3
ontheflatcable
N o n - a d v e r b i a l e m p h a s i s : a n y N P not c o n t a i n e d in an a d v e r b i a l PP d e m a r c a t e d b y a separator. Like h e a d n o u n e m p h a s i s , this factor penalizes N P s in certain e m b e d d e d constructions. E x a m p l e s of N P s
not
receiving n o n - a d v e r b i a l e m p h a s i s areT h r o u g h o u t
thefirstsection
ofthisguide,
used ...I n
the Panel definition panel,
a c t i o n b a r .these symbols are also
select the C~Specify'' option from the
The initial w e i g h t s for each of the a b o v e factor t y p e s are g i v e n in Table 1. N o t e that the relative w e i g h t i n g of s o m e of these factors realizes a hierarchy of g r a m m a t i c a l roles. 5
2.1.5 E q u i v a l e n c e Classes. We treat the a n t e c e d e n t - a n a p h o r relation in m u c h the s a m e w a y as the "equality" condition of Discourse R e p r e s e n t a t i o n T h e o r y (DRT) ( K a m p 1981), as in
u---y.
This indicates that the discourse referent u, e v o k e d b y an a n a p h o r i c NP, is a n a p h o r i - cally linked to a p r e v i o u s l y i n t r o d u c e d discourse referent y. To a v o i d confusion w i t h
mathematical equality (which, unlike the relation discussed here, is symmetric), we represent the relation b e t w e e n an a n a p h o r u a n d its a n t e c e d e n t y b y
y antecedes u.
Two discourse referents u a n d y are said to be co-referential, 6 written as
coref(u~y)
if a n y of the following holds:
• y antecedes u • u antecedes y
• z antecedes u for some discourse referent z and coref(z.y) • z antecedes y for some z a n d coref(z.u)
Also, coref(u,u) is true for a n y discourse referent u. The coref relation defines equiva- lence classes of discourse referents, with all discourse referents in an " a n a p h o r i c chain" f o r m i n g one class:
equiv(u) = {y I coref(u,y)}
Each equivalence class of discourse referents (some of w h i c h consist of only one m e m b e r ) has a salience weight associated with it. This w e i g h t is the s u m of the c u r r e n t w e i g h t of all salience factors in w h o s e scope at least one m e m b e r of the equivalence class lies.
Equivalence classes, along with the sentence recency factor a n d the salience degra- dation mechanism, constitute a d y n a m i c s y s t e m for c o m p u t i n g the relative attentional p r o m i n e n c e of denotational NPs in text.
2.2 T h e R e s o l u t i o n P r o c e d u r e
RAP's p r o c e d u r e for identifying antecedents of p r o n o u n s is as follows.
.
.
a.
b.
C.
Create a list of IDs for all N P s in. the current sentence a n d classify t h e m as to their type (definite NP, pleonastic p r o n o u n , o t h e r p r o n o u n ,
indefinite NP).
Examine all N P s occurring in the current sentence.
Distinguish a m o n g NPs that e v o k e n e w discourse referents, those that e v o k e discourse referents w h i c h are p r e s u m a b l y coreferential with already listed discourse referents, a n d N P s that are u s e d non-referentially.
A p p l y salience factors to the discourse referents e v o k e d in the p r e v i o u s step as appropriate.
A p p l y the syntactic filter a n d reflexive b i n d i n g algorithm (first phase).
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
d. (i)
(ii)
If the current sentence contains any personal or possessive pronouns, a list of pairs of IDs from the current sentence is generated. This list contains the pronoun-NP pairs in the sentence for which coreference can be ruled out on syntactic grounds (using the
conditions stated above).
If the current sentence contains any lexical anaphors (i.e., reciprocal or reflexive pronouns), a list of ID pairs is generated. Each lexical anaphor is paired with all of its possible antecedent binders.
If any non-pleonastic pronouns are present in the current sentence, attempt to identify their antecedents. Resolution is attempted in the order of pronoun occurrence in the sentence.
In the case of lexical anaphors (reflexive or reciprocal pronouns), the possible an- tecedent binders were identified by the anaphor binding algorithm. If more than one candidate was found, the one with the highest salience weight was chosen (see second example of Section 3.1).
In the case of third person pronouns, resolution proceeds as follows:
1. A list of possible antecedent candidates is created. It contains the most recent discourse referent of each equivalence class. The salience weight of each candidate is calculated and included in the list. The salience weight of a candidate can be modified in several ways:
a. If a candidate follows the pronoun, its salience weight is
reduced substantially (i.e., cataphora is strongly penalized).
b. If a candidate fills the same slot as the pronoun, its weight is
increased slightly (i.e., parallelism of grammatical roles is rewarded).
It is important to note that, unlike the salience factors described in Section 2.1.4, these modifications of the salience weights of candidates are local to the the resolution of a particular pronoun.
2. A salience threshold is applied; only those candidates whose salience
weight is above the threshold are considered further.
3. The possible agreement features (number and gender) for the pronoun
are determined. The possible sg (singular) and pl (plural) genders are determined; either of these can be a disjunction or nil. Pronominal forms in many languages are ambiguous as to number and gender; such ambiguities are taken into account by RAP's morphological filter and by the algorithm as a whole. The search splits to consider singular and plural antecedents separately (steps 4--6) to allow a general treatment of
number ambiguity (as in the Spanish possessive pronoun su or the
German pronoun sie occurring as an accusative object).
4. The best sg candidate (if any) is selected:
a. If no sg genders were determined for the pronoun, proceed to
Step 5.
c. The syntactic filter is applied, using the list of disjoint pronoun-NP pairs generated earlier. The filter excludes any candidate paired in the list with the pronoun being resolved, as well as any candidate that is anaphorically linked to an NP paired with the pronoun.
d. If more than one candidate remains, choose the candidate with
the highest salience weight. If several candidates have (exactly) the highest weight, choose the candidate closest to the anaphor. Proximity is measured on the surface string and is not
directional.
e. The remaining candidate is considered the best
sg
candidate.5. The best
pl
candidate (if any) is selected. The procedure parallels that outlined above for the bestsg
candidate:a. If no
pl
gender is specified for the pronoun, proceed to Step 6.b. Otherwise, apply the morphological filter.
c. Apply the syntactic filter.
d. If more than one candidate remains, choose the candidate with
the highest salience weight; if several candidates have the highest weight, choose the candidate closest to the anaphor.
e. The remaining candidate is considered the best
pl
candidate.6. Given the best
sg
andpl
candidates, find the best overall candidate: a. If asg
candidate was found, but nopl
candidate, or vice versa,choose that candidate as the antecedent.
b. If both a
sg
and apl
candidate were found, choose the candidatewith the greater salience weight (this will never arise in analysis of English text, as all English pronominal forms are
unambiguous as to number).
7. The selected candidate is declared to be the antecedent of the pronoun.
The following properties of RAP are worth noting. First, it applies a powerful syntactic and morphological filter to lists of pronoun-NP pairs to reduce the set of possible NP antecedents for each pronoun. Second, NP salience measures are specified largely in terms of syntactic properties and relations (as well as frequency of occur- rence). These include a hierarchy of grammatical roles, level of phrasal embedding, and parallelism of grammatical role. Semantic constraints and real-world knowledge play no role in filtering or salience ranking. Third, proximity of an NP relative to a pro- noun is used to select an antecedent in cases in which several candidates have equal salience weighting. Fourth, intrasentential antecedents are preferred to intersentential candidates. This preference is achieved by three mechanisms:
• An additional salience value is assigned to NPs in the current sentence.
• The salience values of antecedent candidates in preceding sentences are
progressively degraded relative to the salience values of NPs in the current sentence.
• Proximity is used to resolve ties among antecedent candidates with
equal salience values.
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
3. Examples of RAP's Output
RAP generates the list of non-coreferential p r o n o u n - N P pairs for the current sentence, the list of pleonastic pronouns, if any, in the current sentence, the list of possible antecedent NP-lexical a n a p h o r pairs, if any, for the current sentence, a n d the list of p r o n o u n - a n t e c e d e n t N P pairs that it has identified, for which antecedents m a y appear in preceding sentences in the text. Each NP appearing in a n y of the first three lists is represented by its lexical head followed by the integer that corresponds to its position in the sequence of tokens in the input string of the current sentence. The NPs in the pairs of the p r o n o u n - a n t e c e d e n t list are represented by their lexical heads followed b y their IDs, displayed as a list of two integers. 7
3.1 Lexical Anaphors
A f t e r i n s t a l l a t i o n of t h e o p t i o n , the b a c k u p c o p y of t h e R e f e r e n c e D i s k e t t e was s t a r t e d f o r t h e c o m p u t e r to a u t o m a t i c a l l y c o n f i g u r e itself.
A n t e c e d e n t N P - - l e x i c a l a n a p h o r p a i r s . c o m p u t e r . 1 8 - i t s e l f . 2 2
A n a p h o r - - A n t e c e d e n t links. i t s e l f . ( 1 . 2 2 ) to c o m p u t e r . ( 1 . 1 8 ) J o h n t a l k e d to B i l l a b o u t h i m s e l f . A n t e c e d e n t N P - - l e x i c a l a n a p h o r pairs. J o h n . 1 - h i m s e l f . 6 , B i l l . 4 - h i m s e l f . 6 A n a p h o r - - A n t e c e d e n t links.
h i m s e l f . ( l . 6 ) to J o h n . ( 1 . 1 )
In the second example, ]ohn.(1.1) was preferred to 8i11.(1.4) owing to its higher salience weight.
3.2 Pleonastic and Non-Lexical Anaphori¢ Pronouns in the Same Sentence
M o s t of the c o p y r i g h t n o t i c e s are e m b e d d e d in the EXEC, b u t t h i s k e y w o r d m a k e s it p o s s i b l e f o r a u s e r - s u p p l i e d f u n c t i o n to h a v e its o w n c o p y r i g h t n o t i c e .
N o n - c o r e f e r e n t i a l p r o n o u n - - N P p a i r s .
i t . 1 6 - m o s t . l , i t . 1 6 - n o t i c e . 5 , i t . 1 6 - k e y w o r d . 1 4 , i t . 1 6 - f u n c t i o n . 2 3 , i t . 1 6 - u s e r . 2 0 , i t . 1 6 - n o t i c e . 2 9 , i t . 1 6 - c o p y r i g h t . 2 8 , i t s . 2 6 - m o s t . l , i t s . 2 6 - n o t i c e . 5 , i t s . 2 6 - n o t i c e . 2 9 , i t s . 2 6 - c o p y r i g h t . 2 8
Pleonastic Pronouns.
it. 16
A n a p h o r - - A n t e c e d e n t links.
its.(l.26) to function. (1.23)
function.(l.23) a n d keyword.(l.14) share the highest salience weight of all candidates
that pass the morphological and syntactic filters; they are both subjects and therefore higher in salience than the third candidate, £XEC.(1.10). function.(1.23) is then selected as the antecedent owing to its proximity to the anaphor.
3.3 Multiple Cases of Intrasentential Anaphora
Because of this, M i c r o E M A C S cannot process an i n c o m i n g ESC until it
knows what character follows it.
N o n - c o r e f e r e n t i a l p r o n o u n - - N P pairs.
it.12 - character.15, it.l? - c h a r a c t e r . 1 5
A n a p h o r - - A n t e c e d e n t links.
it.(l.12) to M i c r o E M A C S . ( l . 4 )
it.(l.iT) to ESC.(I.10)
MicroEMACS.(1.4) is preferred over ESC.(1.10) as an antecedent of it.(1.12)-- MicroEMACS.(1.4) receives subject emphasis versus the lower object emphasis of ESC.(1.10). In addition, MicroEMACS.(1.4) is rewarded because it fills the same gram- matical role as the anaphor being resolved.
In the case of it.(1.17), the parallelism reward works in favor of ESC.(1.10), causing it to be chosen, despite the general preference for subjects over objects.
3.4 Intersentential and Intrasentential Anaphora in the Same Sentence
At this point, emacs is w a i t i n g for a command.
It is p r e p a r e d to s e e if the variable keys are TRUE, and executes some lines if they are.
N o n - c o r e f e r e n t i a l p r o n o u n - - N P pairs.
it.1 - key. O, it.1 - line.16, it.1 - they.18, they.18 - it.1
A n a p h o r - - A n t e c e d e n t links.
it.(2.1) to emacs.(1.5)
they.(2.18) to key.(2.0)
3.5 Displaying Discourse Referents
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
discourse referents from earlier sentences that are not members of anaphoric chains extending into the current sentence rapidly become "uncompetitive."
S a l i e n c e w e i g h t
465 310 280 135 90
D i s c o u r s e r e f e r e n t ( s )
e m a c s . ( i . 5 ) s ( i t , l ) . ( 2 . 1 )
s ( k e y , l ) . ( 2 . 9 ) s ( t h e y , l ) . ( 2 . 1 8 )
s ( l i n e , l ) . ( 2 . 1 6 )
s ( c o m m a n d , 2 ) . ( l . l O )
s ( p o i n t , 4 ) . ( l . 3 )
3.6 Detailed Displays of Salience Weights
Y o u h a v e n o t w a i t e d f o r the f i l e to close.
Y o u m a y h a v e a s k e d to p r i n t on t h e v i r t u a l p r i n t e r , b u t it c a n n o t
p r i n t u n t i l t h e o u t p u t f i l e is closed.
N o n - c o r e f e r e n t i a l p r o n o u n - - N P pairs:
y o u . 1 - p r i n t e r . l O , y o u . l - it.13, y o u . l - o u t p u t . 1 9 ,
y o u . l - f i l e . 2 0 , i t . 1 3 - you.l, i t . 1 3 - o u t p u t . 1 9 ,
i t . 1 3 - f i l e . 2 0
S a l i e n c e v a l u e s :
p r i n t e r . ( 2 . 1 0 ) - 270
f i l e . ( 1 . 7 ) - 190
S a l i e n c e f a c t o r values: p r i n t e r . ( 2 . 1 0 )
s e n t e n c e _ r e c - i00
n o n _ a d v e r b i a l _ e m p h - 50
p o b j _ e m p h - 40 h e a d _ e m p h - 80
f i l e . ( l . 7 )
s e n t e n c e _ r e c - 50
n o n _ a d v e r b i a l _ e m p h - 25 s u b j _ e m p h - 40
h e a d _ e m p h - 40
L o c a l s a l i e n c e f a c t o r v a l u e s :
file. (I.7)
p a r a l l e l _ r o l e s _ r e w a r d - 35
A n a p h o r - - A n t e c e d e n t links:
i t . ( 2 . 1 3 ) to p r i n t e r . ( 2 . 1 0 )
This example illustrates the strong preference for intrasentential antecedents, print- er.(2.10) is selected, despite the fact that it is much lower on the hierarchy of grammat- ical roles than the other candidate, file.(1.7), which also benefits from the parallelism reward. Degradation of salience weight for the candidate from the previous sentence is substantial enough to offset these factors.
The P A R T N U M t a g p r i n t s a p a r t n u m b e r on the d o c u m e n t .
N o n - c o r e f e r e n t i a l p r o n o u n - - N P p a i r s :
i t . 6 - s e t t i n g . 4 , i t . 6 - c o v e r . l O
S a l i e n c e v a l u e s :
n u m b e r . ( 1 . 7 ) - 1 7 5
t a g . ( 1 . 3 ) - 1 5 5
s c s y m ( n a m e ) . ( 2 . 1 ) - 1 5 0
d o c u m e n t . ( 1 . 1 0 ) - 1 3 5
P A R T N U M . ( 1 . 2 ) - 7 5
S a l i e n c e f a c t o r v a l u e s :
n u m b e r . ( l . Z )
s e n t e n c e _ r e c - 5 0 n o n _ a d v e r b i a l _ e m p h - 2 5 a c c _ e m p h - 2 5
h e a d _ e m p h - 4 0
t a g . ( l . 3 ) .
s e n t e n c e _ r e c - 5 0 n o n _ a d v e r b i a l _ e m p h - 2 5 s u b j _ e m p h - 4 0
h e a d _ e m p h - 4 0
s c s y m ( n a m e ) . ( 2 . 1 ) s e n t e n c e _ r e c - I 0 0 n o n _ a d v e r b i a l _ e m p h - 5 0 P A K T N U M . ( I . 2 )
s e n t e n c e _ r e c - 5 0 n o n _ a d v e r b i a l _ e m p h - 2 5
L o c a l s a l i e n c e f a c t o r v a l u e s :
d o c u m e n t . ( l . l O ) s e n t e n c e _ r e c - 5 0 n o n _ a d v e r b i a l _ e m p h - 2 5 p o b j _ e m p h - 2 0
h e a d _ e m p h - 4 0
n u m b e r . ( l , 7 )
p a r a l l e l _ r o l e s _ r e w a r d - 3 5
A n a p h o r - - A n t e c e d e n t l i n k s :
s ( i t , l ) . ( 2 . 6 ) t o s ( n u m b e r , l ) . ( l . 7 )
Four c a n d i d a t e s receive a similar salience w e i g h t i n g in this e x a m p l e . Two p o - tential intrasentential c a n d i d a t e s that w o u l d h a v e received a h i g h salience ranking, setting.(2.4) a n d cover.(2.10), are ruled o u t b y the syntactic filter. The r e m a i n i n g in- trasentential candidate, scsym(name).(2.1) 8 r a n k s relatively low, as it is a p o s s e s s i v e d e t e r m i n e r - - i t scores l o w e r t h a n t w o c a n d i d a t e s f r o m the p r e v i o u s sentence. The par- allelism r e w a r d causes number.Off ) to be preferred.
4. Testing o f R A P o n M a n u a l Texts
We t u n e d R A P o n a c o r p u s of five c o m p u t e r m a n u a l s containing a total of a p p r o x i - m a t e l y 82,000 w o r d s . F r o m this c o r p u s w e extracted sentences w i t h 560 occurrences
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
Table 2
Results of training phase
Total Intersentential cases Intrasentential cases
Number of pronoun occurrences 560 89 471
Number of cases that the algorithm 475 (85%) 72 (81%) 403 (86%)
resolves correctly
of third p e r s o n p r o n o u n s (including reflexives a n d reciprocals) and their antece- dents. 9
In the training phase, w e refined o u r tests for pleonastic p r o n o u n s and exper- i m e n t e d extensively with salience weighting. O u r goal was, of course, to optimize RAP's success rate with the training corpus. We p r o c e e d e d heuristically, analyzing cases of failure a n d a t t e m p t i n g to eliminate them in as general a m a n n e r as possible. The parallelism r e w a r d was i n t r o d u c e d at this time, as it s e e m e d to m a k e a sub- stantial contribution to the overall success rate. A salience factor that was originally present, viz.
matrix emphasis,
was revised to b e c o m e thenon-adverbial emphasis
factor. In its original form, this factor contributed to the salience of a n y N Pnot
contained in a s u b o r d i n a t e clause or in an adverbial PP d e m a r c a t e d b y a separator. This was f o u n d to be too general, especially since the relative positions of a given p r o n o u n and its a n t e c e d e n t candidates are not taken into account. The revised factor could be t h o u g h t of as an adverbialpenalty
factor, since it in effect penalizes NPS occurring in adverbial pps. 1°We also e x p e r i m e n t e d with the initial weights for the various factors a n d with the size of the parallelism r e w a r d a n d cataphora penalty, again a t t e m p t i n g to optimize RAP's overall success rate. A value of 35 was chosen for the parallelism reward; this is just large e n o u g h to offset the preference for subjects o v e r accusative objects. A m u c h larger value (175) was f o u n d to be necessary for the cataphora penalty. The final results t h a t we obtained for the training corpus are given in Table 2.
Interestingly, the syntactic-morphological filter reduces the set of possible an- tecedents to a single NP, or identifies the p r o n o u n as pleonastic in 163 of the 475 cases (34%) that the algorithm resolves correctly. 11 It significantly restricts the size of the candidate list in most of the other cases, in which the a n t e c e d e n t is selected on the basis of salience ranking and proximity. This indicates the i m p o r t a n c e of a p o w e r f u l s y n t a c t i c - m o r p h o l o g i c a l filtering c o m p o n e n t in an a n a p h o r a resolution system.
We then p e r f o r m e d a blind test of RAP on a test set of 345 sentences r a n d o m l y selected from a c o r p u s of 48 c o m p u t e r m a n u a l s containing 1.25 million words. 12 The results w h i c h we obtained for the test c o r p u s (without a n y further modifications of RAP) are given in Table 3.13
This blind test p r o v i d e s the basis for a c o m p a r a t i v e evaluation of RAP a n d Dagan's
• 9 These sentences and those used in the blind test were edited slightly to overcome parse inaccuracies. Rather than revise the lexicon, w e m a d e lexical substitutions to i m p r o v e parses. In s o m e cases constructions had to be simplified. However, such changes did not alter the syntactic relations a m o n g the p r o n o u n and its possible antecedents.
For a discussion of ESG's p a r s i n g accuracy, see McCord (1993).
10 See c o m m e n t s at the end of Section 4 about refining RAP's m e a s u r e s of structural salience.
11 Forty-three of the p r o n o u n occurrences in the training c o r p u s ( ~ 8%) were pleonastic; a r a n d o m sample of 245 p r o n o u n occurrences extracted from o u r test corpus included 15 pleonastic p r o n o u n s ( ~ 6%). 12 The test set w a s filtered in order to satisfy the conditions of o u r experiments on the role of statistically
Table 3
Results of blind test
Total Intersentential cases Intrasentential cases
Number of pronoun occurrences 360 70 290
Number of cases that the algorithm 310 (86%) 52 (74%) 258 (89%)
resolves correctly
(1992) system, RAPSTAT, w h i c h e m p l o y s b o t h RAP's salience w e i g h t i n g m e c h a n i s m and statistically m e a s u r e d lexical preferences, as well as for a detailed analysis of the relative contributions of the various elements of RAP's salience weighting m e c h a n i s m to its overall success rate. We will discuss the blind test in greater detail in the following sections.
4.1 Limitations of the Current Algorithm
Several classes of errors that RAP m a k e s are w o r t h y of discussion. The first occurs with m a n y cases of intersentential a n a p h o r a , such as the following:
This green indicator is lit w h e n the c o n t r o l l e r is on.
It shows that the DC power supply voltages are at the correct
levels.
Morphological a n d syntactic filtering exclude all possible intrasentential candidates. Because the level of sentential e m b e d d i n g does not contribute to RAP's salience weight- ing m e c h a n i s m , indicator.(1.3) a n d controller.(1.8) are r a n k e d equally, since b o t h are subjects. RAP then e r r o n e o u s l y chooses controller.(1.8) as the antecedent, since it is closer to the p r o n o u n than the other candidate.
The next class of errors involves antecedents that receive a low salience weighting o w i n g to the fact that the e v o k i n g N P is e m b e d d e d in a matrix N P or is in a n o t h e r structurally n o n p r o m i n e n t position (such as object of an adverbial PP).
The users you enroll may not n e c e s s a r i l y be new to the system and may already have a user p r o f i l e and a system d i s t r i b u t i o n
d i r e c t o r y entry.
&ofc. checks for the e x i s t e n c e of these objects and only
creates t h e m as necessary.
Despite the general preference for intrasentential candidates, user.(1.2) is selected as the antecedent, since the only factor contributing to the salience w e i g h t of object.(2.8) is sentence recency. Selectional restrictions or statistically m e a s u r e d lexical preferences (see Section 5) could clearly help in at least some of these cases.
In a n o t h e r class of cases, RAP fails because s e m a n t i c / p r a g m a t i c i n f o r m a t i o n is required to identify the correct antecedent.
conditions.
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
Table 4
Relative contribution of elements of salience weighting mechanism
Total correct Correctly disagrees with RAP Incorrectly disagrees with RAP
I 310 (86%)
II 308 (86%) 2 4
III 308 (86%) 2 4
IV 302 (84%) 3 11
V 301 (84%) 9
VI 297 (83%) 12 25
VII 294 (82%) 1 17
VIII 231 (64%) 79
IX 212 (59%) 21 119
X 184 (51%) 17 143
Again, the Migration Aid produces an exception report automatically at the end of every migration run.
As you did with the function, use it to verify that the items have been restored to your system successfully.
function.(2.6) is selected as the antecedent, rather than aid.(1.5).
4.2 The Relative Contributions of the Salience Weighting Mechanisms
Using the test corpus of our blind test, we conducted experiments with modified versions of RAP, in which various elements of the salience weighting mechanism were switched off. We present the results in Table 4 and discuss their significance.
Ten variants are presented in Table 4; they are as follows:
I "standard" RAP (as used in the blind test)
II parallelism reward deactivated
III non-adverbial and head emphasis deactivated
IV matrix emphasis used instead of non-adverbial emphasis
V cataphora penalty deactivated
VI subject, existential, accusative, and indirect object/oblique complement
emphasis (i.e., hierarchy of grammatical roles) deactivated
VII equivalence classes deactivated
VIII sentence recency and salience degradation deactivated
IX all "structural" salience weighting deactivated (II +III + V + VI)
X all salience weighting and degradation deactivated
[image:17.468.37.431.82.207.2]particular NP contribute to its salience weight, without any contribution from other anaphorically linked NPs. The performance of the syntactic filter is degraded some- what in this variant as well, since NPs that are anaphorically linked to an NP fulfilling the criteria for disjoint reference will no longer be rejected as antecedent candidates. The results for VII and VIII indicate that attentional state plays a significant role in pronominal anaphora resolution and that even a simple model of attentional state can be quite effective.
Deactivating the syntax-based elements of the salience weighting mechanism in- dividually led to relatively small deteriorations in the overall success rate (II, III, IV, V, and VI). Eliminating the hierarchy of grammatical roles (VI), for example, led to a deterioration of less than 4%. Despite the comparatively small degradation in per- formance that resulted from turning off these elements individually, their combined effect is quite significant, as the results of IX show. This suggests that the syntactic salience factors operate in a complex and highly interdependent manner for anaphora resolution.
X relies solely on syntactic/morphological filtering and proximity to choose an antecedent. Note that the sentence pairs of the blind test set were selected so that, for each pronoun occurrence, at least two antecedent candidates remained after syn- tactic/morphological filtering (see Section 5.1). In the 17 cases in which X correctly disagreed with RAP, the proper antecedent happened to be the most proximate can- didate.
We suspect that RAP's overall success rate can be improved (perhaps by 5% or more) by refining its measures of structural salience. Other measures of embeddedness, or perhaps of "distance" between anaphor and candidate measured in terms of clausal and NP boundaries, may be more effective than the current mechanisms for non- adverbial and head emphasis. 14 Empirical studies of patterns of pronominal anaphora in corpora (ideally in accurately and uniformly parsed corpora) could be helpful in defining the most effective measures of structural salience. One might use such studies to obtain statistical data for determining the reliability of each proposed measure as a predictor of the antecedent-anaphor relation and the orthogonality (independence) of all proposed measures.
5. Salience and Statistically Measured Lexical Preference
Dagan (1992) constructs a procedure, which he refers to as RAPSTAT, for using sta- tistically measured lexical preference patterns to reevaluate RAP's salience rankings of antecedent candidates. RAPSTAT assigns a statistical score to each element of a candidate list that RAP generates; this score is intended to provide a measure (relative to a corpus) of the preference that lexical semantic/pragmatic factors impose upon the candidate as a possible antecedent for a given pronoun, is
14 Such a distance m e a s u r e is reminiscent of H o b b s ' (1978) tree search procedure. See Section 6.1 for a discussion of H o b b s ' algorithm and its limitations.
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
RAPSTAT reevaluates R A P ' s r a n k i n g of the elements of the antecedent candidate list L in a w a y that combines b o t h the statistical scores a n d the salience values of the candidates. The elements of L a p p e a r in d e s c e n d i n g order of salience value. RAPSTAT processes L as follows. Initially, it considers the first t w o elements Cl a n d C2 of L. If (i) the difference in salience scores b e t w e e n C1 a n d C2 does not exceed a parametrically specified value (the salience difference threshold) a n d (ii) the statistical score of C2 is significantly greater than that of C1, then RAPSTAT will substitute the former for the latter as the currently preferred candidate. If conditions (i) a n d (ii) do not hold, RAP- STAT confirms R A P ' s selection of C1 as the preferred antecedent. If these conditions do hold, then RAPSTAT selects C2 as the currently preferred candidate a n d proceeds to c o m p a r e it with the next element of L. It repeats this p r o c e d u r e for each successive pair of candidates in L until either (i) or (ii) fails or the list is completed. In either case, the last currently preferred candidate is selected as the antecedent.
A n example of a case in w h i c h RAPSTAT overules RAP is the following.
The Send Message display is shown, allowing you to enter your message and specify where it will be sent.
The t w o top candidates in the list that RAP generates for it.(1.17) are display.(1.4) with a salience value of 345 a n d message.(1.13), w h i c h has a salience value of 315. In the c o r p u s that w e used for testing RAPSTAT, the verb-object pair
send-display
appears only once, whereassend-message
occurs 289 times. As a result, message receives a considerably higher statistical score than display. The salience difference threshold that w e used for the test is 100, a n d conditions (i) a n d (ii) hold for these two candidates. The difference b e t w e e n the salience value of message a n d the third element of the candidate list is greater than 100. Therefore, RAPSTAT correctly selects message as the antecedent of it.5.1 A Blind Test of RAP and RAPSTAT
D a g a n et al. (in press) report a c o m p a r a t i v e blind test of RAP a n d RAPSTAT. To con- struct a database of grammatical relation counts for RAPSTAT, we applied the Slot G r a m m a r parser to a corpus of 1.25 million w o r d s of text from 48 c o m p u t e r m a n u - als. We automatically extracted all lexical tuples a n d recorded their frequencies in the p a r s e d corpus. We then constructed a test set of p r o n o u n s b y r a n d o m l y selecting from the corpus sentences containing at least one non-pleonastic third p e r s o n p r o n o u n oc- currence. For each such sentence in the set, we i n c l u d e d the sentence that i m m e d i a t e l y precedes it in the text (when the preceding sentence does not contain a pronoun). 16 We filtered the test set so that for each p r o n o u n occurrence in the set, (i) RAP generates a candidate list with at least t w o elements, (ii) the actual antecedent N P a p p e a r s in the candidate list, a n d (iii) there is a total tuple frequency greater than 1 for the candidate
See Dagan 1992 and Dagan et al. (in press) for a discussion of this lexical statistical approach to ranking antecedent candidates and possible alternatives.
list (in most cases, it was considerably larger). ~7 The test set contains 345 sentence pairs with a total of 360 pronoun occurrences. The results of the blind test for RAP and RAPSTAT are as follows. TM
RAP RAPSTAT
Total correct: 310 (86%) 319 (89%)
Total decided: 360 (100%) 182 (51%)
Correctly decided: 310 (86%) 144 (79%)
RAPSTAT
Disagrees with RAP:
Correctly disagrees with RAP: Incorrectly disagrees with RAP:
41 (22% of cases decided) 25 (61%)
16 (39%)
RAP/RAPSTAT Both wrong:
Either RAP or RAPSTAT is correct:
22 (12%) 335 (93%)
When we further analyzed the results of the blind test, we found that RAPSTAT's success depends in large part on its use of salience information. If RAPSTAT's statis- tically based lexical preference scores are used as the only criterion for selecting an antecedent, the statistical selection procedure disagrees with RAP in 151 out of 338 instances. RAP is correct in 120 (79%) of these cases and the statistical decision in 31 (21%) of the cases. When salience is factored into RAPSTAT's decision procedure, the rate of disagreement between RAP and RAPSTAT declines sharply, and RAPSTAT's performance slightly surpasses that of RAP, yielding the results that we obtained in the blind test.
In general, RAPSTAT is a conservative statistical extension of RAP. It permits sta- tistically measured lexical preference to overturn salience-based decisions only in cases in which the difference between the salience values of two candidates is small and the statistical preference for the less salient candidate is comparatively large. ~9 The comparative blind test indicates that incorporating statistical information on lexical preference patterns into a salience-based anaphora resolution procedure can yield a modest improvement in performance relative to a system that relies only on syntactic salience for antecedent selection. Our analysis of these results also shows that statis- tically measured lexical preference patterns alone provide a far less efficient basis for anaphora resolution than an algorithm based on syntactic and attentional measures of salience. 2°
6. Comparison with Other Approaches to Anaphora Resolution
We will briefly compare our algorithm with several other approaches to anaphora resolution that have been suggested.
17 In p r e v i o u s tests of RAP w e f o u n d that it generates a candidate list that includes the correct antecedent of the p r o n o u n in a p p r o x i m a t e l y 98% of the cases to w h i c h it applies.
18 We take RAPSTAT as deciding a case w h e n it considers at least t w o candidates rather than deferring to RAP after the initial candidate because of a large salience difference b e t w e e n this candidate and the next one in the list. In cases in w h i c h RAPSTAT does not make an i n d e p e n d e n t decision, it e n d o r s e s RAP's selection. RAPSTAT's total success rate includes b o t h sorts of cases.
19 John Justeson did the statistical analysis of the comparative blind test of RAP and RAPSTAT. These results are described in Dagan et al. (in press).
Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
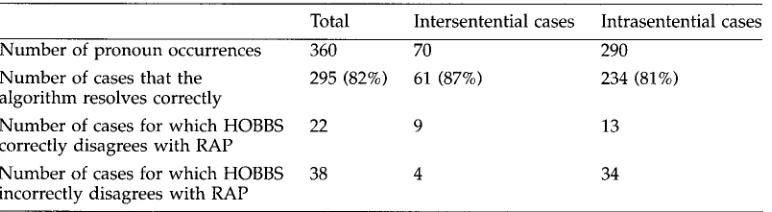
6.1 Hobbs' Algorithm
Hobbs' (1978) algorithm relies on a simple tree search procedure formulated in terms of depth of embedding and left-right order. By contrast, RAP uses a multi-dimensional measure of salience that invokes a variety of syntactic properties specified in terms of the head-argument structures of Slot Grammar, as well as a model of attentional state.
Hobbs' tree search procedure selects the first candidate encountered by a left- right depth first search of the tree outside of a minimal path to the pronoun that satisfies certain configurational constraints. The algorithm chooses as the antecedent of a pronoun P the first NPi in the tree obtained by left-to-right breadth-first traversal of the branches to the left of the path T such that (i) T is the path from the NP dominating P to the first NP or S dominating this NP, (ii) T contains an NP or S node N that contains the NP dominating P, and (iii) N does not contain NPi. If an antecedent satisfying this condition is not found in the sentence containing P, the algorithm selects the first NP obtained by a left-to-right breadth first search of the surface structures of preceding sentences in the text.
We have implemented a version of Hobbs' algorithm for Slot Grammar. The origi- nal formulation of the algorithm encodes syntactic constraints on pronominal anaphora in the definition of the domain to which the search for an antecedent NP applies. In our implementation of the algorithm, we have factored out the search procedure and substituted RAP's syntactic-morphological filter for Hobbs' procedural filter. Let the Mods (modifiers) of a head H be the sisters of H in the Slot Grammar representation of the phrase that H heads. Our specification of Hobbs' algorithm for Slot Grammar is as follows:
.
.
°
4.
.
.
,
8.
.
Find a node N1 such that (i) N1 contains the pronoun P; (ii) N1 is an S or NP; and (iii) it is not the case that there is a node N1, such that N1 contains N1, and N1, satisfies (i) and (ii).
Check the list of Mods of N1 left to right for NPs that are not elements of the list of pairs < P - N P > identified by the syntactic-morphological filter as noncoreferential and that occur to the left of R
Select the leftmost NP in the filtered list of NP Mods of N1.
If this list is nil, then repeat steps 2 and 3 recursively for each Mod in the list of Mods of N1, each Mod in this second list of Mods, etc., until an N P antecedent is found.
If no NP antecedent is found by applying step 4, then identify a node N2 that is the first N P / S containing N1.
If N2 is an NP and is not an element of the list of pairs < P - N P > identified by the filter, propose it as the antecedent.
Otherwise, apply steps 2-4 to N2.
If no antecedent NP is found, continue to apply steps 5 and 6 and then steps 2-4 to progressively higher N P / S nodes.
Table 5
Results of blind test (Hobbs' algorithm)
Total Intersentential cases Intrasentential cases
Number of pronoun occurrences 360 70
Number of cases that the 295 (82%) 61 (87%)
algorithm resolves correctly
Number of cases for which HOBBS 22 9
correctly disagrees with RAP
Number of cases for which HOBBS 38 4
incorrectly disagrees with RAP
290 234 (81%)
13
34
We ran this version of H o b b s ' algorithm on the test set that we used for the blind test of RAP a n d RAPSTAT; the results a p p e a r in Table 5.
It is i m p o r t a n t to note that the test set does not include pleonastic p r o n o u n s or lexical a n a p h o r s (reflexive or reciprocal p r o n o u n s ) , neither of w h i c h are dealt with b y H o b b s ' algorithm. Moreover, o u r Slot G r a m m a r i m p l e m e n t a t i o n of the algorithm gives it the full a d v a n t a g e of RAP's s y n t a c t i c - m o r p h o l o g i c a l filter, w h i c h is m o r e p o w e r f u l than the configurational filter built into the original specification of the algorithm. Therefore, the test results p r o v i d e a direct c o m p a r i s o n of RAP's salience metric and H o b b s ' search procedure.
H o b b s ' algorithm was m o r e successful than RAP in resolving intersentential ana- p h o r a (87% versus 74% correct). 21 Because intersentential a n a p h o r a is relatively rare in o u r corpus of c o m p u t e r m a n u a l texts a n d because RAP's success rate for intrasentential a n a p h o r a is higher than H o b b s ' (89% versus 81%), RAP's overall success rate on the blind test set is 4% higher than that of o u r version of H o b b s ' algorithm. This indicates that RAP's salience metric p r o v i d e s a m o r e reliable basis for a n t e c e d e n t selection than H o b b s ' search p r o c e d u r e for the text d o m a i n on w h i c h we tested b o t h algorithms.
It is clear from the relatively high rate of a g r e e m e n t b e t w e e n RAP a n d H o b b s ' algorithm on the test set (they agree in 83% of the cases) that there is a significant d e g r e e of c o n v e r g e n c e b e t w e e n salience as m e a s u r e d b y RAP a n d the configurational p r o m i n e n c e defined b y H o b b s ' search procedure. This is to be expected in English, in w h i c h grammatical roles are identified b y m e a n s of p h r a s e order. H o w e v e r , in languages in which grammatical roles are case m a r k e d a n d w o r d o r d e r is relatively free, we expect that there will be greater d i v e r g e n c e in the predictions of the t w o algorithms. The salience measures used b y RAP have application to a w i d e r class of languages than H o b b s ' order-based search procedure. This p r o c e d u r e relies o n a c o r r e s p o n d e n c e of grammatical roles a n d linear p r e c e d e n c e relations that holds for a c o m p a r a t i v e l y small class of languages.
6.2 D i s c o u r s e B a s e d M e t h o d s
Most of the w o r k in this area seeks to f o r m u l a t e general principles of discourse struc- ture a n d interpretation a n d to integrate m e t h o d s of a n a p h o r a resolution into a com- putational m o d e l of discourse interpretation (and s o m e t i m e s of generation as well). Sidner (1981, 1983), Grosz, Joshi, a n d Weinstein (1983, 1986), Grosz and Sidner (1986),
[image:22.468.47.433.86.192.2]Shalom Lappin and Herbert J. Leass An Algorithm for Pronominal Anaphora Resolution
Brennan, Friedman, and Pollard (1987), and Webber (1988) present different versions of this approach. Dynamic properties of discourse, especially coherence and focusing, are invoked as the primary basis for identifying antecedence candidates; selecting a candidate as the antecedent of a pronoun in discourse involves additional constraints of a syntactic, semantic, and pragmatic nature.
In developing our algorithm, we have not attempted to consider elements of dis- course structure beyond the simple model of attentional state realized by equivalence classes of discourse referents, salience degradation, and the sentence recency salience factor. The results of our experiments with computer manual texts (see Section 4.2) indicate that, at least for certain text domains, relatively simple models of discourse structure can be quite useful in pronominal anaphora resolution. We suspect that many aspects of discourse models discussed in the literature will remain computationally intractable for quite some time, at least for broad-coverage systems.
A more extensive treatment of discourse structure would no doubt improve the performance of a structurally based algorithm such as RAP. At the very least, for- matting information concerning paragraph and section boundaries, list elements, etc., should be taken into account. A treatment of definite NP resolution would also pre- sumably lead to more accurate resolution of pronominal anaphora, since it would improve the reliability of the salience weighting mechanism.
However, some current discourse-based approaches to anaphora resolution assign too dominant a role to coherence and focus in antecedent selection. As a result, they establish a strong preference for intersentential over intrasentential anaphora resolu- tion. This is the case with the anaphora resolution algorithm described by Brennan, Friedman, and Pollard (1987). This algorithm is based on the centering approach to modeling attentional structure in discourse (Grosz, Joshi, and Weinstein 1983, 1986). 22 Constraints and rules for centering are applied by the algorithm as part of the selection procedure for identifying the antecedents of pronouns in a discourse. The algorithm strongly prefers intersentential antecedents that preserve the center or maximize con- tinuity in center change, to intrasentential antecedents that cause radical center shifts. This strong preference for intersentential antecedents is inappropriate for at least some text domains--in our corpus of computer manual texts, for example, we estimate that less than 20% of referentially used third person pronouns have intersentential antecedents. 23
There is a second difficulty with the Brennan et al. centering algorithm. It uses a hierarchy of grammatical roles quite similar to that of RAP, but this role hierarchy does not directly influence antecedent selection. Whereas th e hierarchy in RAP contributes to a multi-dimensional measure of the relative salience of all antecedent candidates, in Brennan et al. 1987, it is used only to constrain the choice of the backward-looking center,
Cb,
of an utterance. It doesnot
serve as a general preference measure for an- tecedence. The items in the forward center list,Cf,
are ranked according to the hier- archy of grammatical roles. For an utterance U,,Cb(Un)
is required to be the highest ranked element ofCf(U~_I)
that is realized in U,. If an element E in the list of possible22 "A d i s c o u r s e s e g m e n t consists of a s e q u e n c e of u t t e r a n c e s U 1 , . . . , Urn. With each utterance, Un is associated w i t h a list of forward-looking centers, Cf(Uti), consisting of t h o s e d i s c o u r s e entities that are
directly realized or realized by linguistic e x p r e s s i o n s in that utterance. R a n k i n g of a n entity o n this list
c o r r e s p o n d s r o u g h l y to the likelihood that it will be the p r i m a r y focus of s u b s e q u e n t discourse; the first entity on this list is the preferred center, Cp(Un). Un actually centers, or is 'about,' o n l y o n e entity at a time, the backward-looking center, Cb(U~). The b a c k w a r d center is a c o n f i r m a t i o n of a n entity that h a s a l r e a d y b e e n i n t r o d u c e d into the discourse; m o r e specifically, it m u s t be realized in the i m m e d i a t e l y p r e c e d i n g utterance, Un--l" (Brennan, F r i e d m a n , a n d Pollard 1987, p. 155).