Volume 3, Issue 6, 2016
70 Available online at www.ijiere.com
International Journal of Innovative and Emerging
Research in Engineering
e-ISSN: 2394 - 3343 p-ISSN: 2394 - 5494
An Enhanced Classification approach for Collaborative
Email Abstraction based Spam Filtering
P. Rajendran
a, Dr. A. Tamilarasi
b, R. Mynavathi
caAssistant Professor / MCA, Velalar College of Engineering and Technology, Erode, TamilNadu bProfessor&Head, Department of Computer Applications, Kongu Engineering College, Erode, TamilNadu
cAssistant Professor / IT, Velalar College of Engineering and Technology, Erode, TamilNadu
ABSTRACT:
With the advent of Internet, Emails has become a fast inexpensive way of sharing information. It is used to share both business and personal information. This simple way of using Emails has made various space to spams also. Everyone’s email inbox is full with spam mails now-a-days. The main characteristic of spam is that they are not malicious but are not get blocked by firewalls. However, they are unwanted content received repeatedly by Email users. This paper proposes an enhanced approach towards classifying spam mails by collaborative means. Instead of manipulating on the content of the Email, an abstraction scheme that segregates email layout is considered for classification.
Keywords: Spam, Near duplication, Email abstraction, Bayes Classification, Ham, Spam Filtering, Collaborative Email
I. INTRODUCTION
Unsolicited email messages sent against the interest and knowledge of the recipient is usually referred as Spams. Spam will be basically a no response mail that will link to visit a website for advertisements. Generally they are broadcast messages sent to a large number of peoples. However, it is important to differentiate between unsolicited email, which can be labeled as Spam and solicited email. Solicited email may have the same goals as unsolicited email, but you may receive a solicited email that the sender has deemed to be in your interest, or related to a previous interest. Spam email, however, is usually sent without any knowledge or consideration of the recipients interests, and is sent out only with the desired result in mind. Spams are not only wastage of money, bandwidth also very annoying for the users. Bayesian spam filtering is one of the more common features used today in spam filters to identify spam. Particular words have particular probabilities of occurring in spam email and in legitimate emails. The filter must be trained in advance for these probabilities. After training the word probabilities, they in turn are used to compute the probability that an email with a particular set of words in it belongs to either of the category. Each word in the email contributes to the e-mail spam probability. This contribution is called the posterior probability and is computed using Bayes‘ theorem. Then, the e-mail spam probability is computed over-all words in the email, and if the total percentage exceeds a certain threshold (say 95%), the filter marks the email as a spam. The paper uses this scenario to classify spams. Instead of computing the probability of set of words, the probability of email layout tags are analysed for the classification. Our contribution are as follows:
We propose an abstraction procedure to generate email-abstraction using HTML content.
We design an enhanced classification approach using Naive Bayes classification for Spam Classification. The paper is organised as follows: Section 2 describes the related work. Section 3 devise the abstraction scheme. In Section 4, we discuss on Naive Bayes Spam Classfication. Section 5 shows the experimental results and finally the paper is concluded in Section 6.
II. RELATEDWORK
Volume 3, Issue 6, 2016
71 Hidden Markov Model which are met in papers Paolo B., et al. [11], and José Gordillo, et al. [12]. Kolmogorov complexity esti-mation is met in papers Spracklin L.M., et al. [13]. Application of methods of clustering analyses to the problem of filtering e-mails to legitimate and spam is considered in papers [15]. From 2009 year, beginning from Paulo Cortez’s, et al. article [13] one can meet the statement as a Symbiotic Data Mining which is a hybrid of Collaborative Filtering (CF) and Content- Based Filtering (CBF).
Clustering of spammers considering them in groups is offered in paper Fulu Li, et al. [2]. In works Xu K.S., et al. [23,24] the method of spectral clustering is applied to the set of spam messages collected under project Honey Pot for defining and tracking of social networks of spammers. They represent a social network of spammers as a graph the nods of which correspond to spammers, and a corner between two junctions of graph as social relations between spammers.
Research and development of spam filtering systems are actively carried all over the world. Along with scien-tific institutes there are many organizations and corpora-tions investigating and offering different theoretical, practical and juridical approaches to spam filtering. Dif-ferent organizations as university laboratories (laborato-ries CSAIL MIT in USA [25], Computer Laboratory Faculty University of Cambridge in UK [6] and etc.); research centers (NCSR Democritos in Greece [7], re-search centre of IBM [9] and etc.); commercial companies (Microsoft , Symantec, Kaspersky’s Laboratory and etc.) had been involved to this proc-ess. Many international organizations take great attention to concerned problem. It is created the ASRG (Anti- Spam Research Group) [3] within the organization IETF (Internet Engineering Task Force) [4] in 2003. A lot of international conferences, summits and symposi-ums dedicated to this topic recently (NIST Spam Tech-nology Workshop USA 2004, ASRG Meeting USA 2003, Cambridge Spam Conference USA 2003-2005, Confer-ence on Email and Anti-Spam (CEAS) Mountain View USA 2004-2005, Spam Forum Paris France 2003, Anti- Spam-Symposium Karlsruh Germany 2003, Spam Sum-mit UK 2003, Conference on “Spam problem and its solution” Moscow and etc.) were held [5].
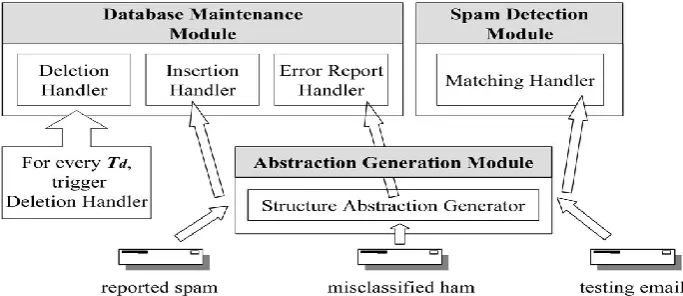
III.EMAIL ABSTRACTION USING HTML TAGS
This section introduces a new email abstraction scheme using HTML content in email. The algorithm of structure abstraction is outlined as follows
Algorithm
Input : email with text/html content-type, tag length threshold
Output : email abstraction of the input email
1.
Transform each tag to <tag.name>;2.
Transform each paragraph of text to <mytext/>3.
Collect all <anchor> tags under AnchorSet4.
Output email abstraction as the concatenation of <tag.name>5.
Preprocess the tag sequence of email abstraction6.
For each tag in email abstraction7.
assign new tag position8.
Place the tag to the new position9.
email abstraction will now be the concatenation of <tag.name> with new position10.
finally append AnchorSet in front of email abstraction11.
return email abstractionThe procedure for email abstraction contains process for tag extraction, tag reordering and finally appending process..
Volume 3, Issue 6, 2016
72 Tag extraction phase extracts each HTML tag, converts all paragraph tags to <mytext> and generates a tentative email abstraction. Tag reordering phase assigns new position to all tags and finally appending phase adds the anchor set tags to generate the complete email abstraction. The main objective of appending phase is to reduce the probability that ham is successfully matched with reported spams when the tag length of an email abstraction is short.
IV.NAIVE BAYE’S CLASSIFICATION FOR SPAM
Bayesian spam filtering is one of the more common features used today in spam filters to identify spam. It requires manual intervention as a user would train the function as to what is spam. The tool uses the concept of Bayes theorem and so using probabilities to weigh a message. By comparing large sets of legitimate e-mail and large sets of spam, bayesian spam filter can then look for combination of words that are statistically likely to occur in spam messages, and for words that are statistically likely to occur in legitimate messages, to determine the probability that an e-Mail is likely to be spam or a legitimate e-mail. After bayesian has scored a sufficient amount of emails, a user will be required to keep an eye on the email logs, to see how well bayesian has learnt to classy emails. Fine tuning may be required if bayesian is scoring incorrectly. When the system is scoring emails correctly, it is recommended to leave bayesian alone. Sometimes over scoring will do more harm than good. When bayesian starts to produce more false positives or/and false false negatives than usual, then it would be required to manually score a subset of emails, and fine tune the Bayesian system again. Sometimes if bayesian is not performing well, it may be required to reset bayesian and start again. Occasionally the emails scored by a user are vague (meaning an email looks legitimate and spammy at the same time) and can confuse the system.
Volume 3, Issue 6, 2016
73
V. EXPERIMENTSANDRESULTS
The spam detection system is evaluated on spam data sets collected from UCI repository. Before the system starts to check for spams, a set of known spams is inserted into the system. Each spam is inserted into the database after the process of matching. We evaluate the effectiveness of the system in terms of classifier accuracy. The efficiency investigation is conducted by inserting email abstraction into the database and deleting outdated spams from the database. Below is the execution time evaluation of the spam detection system.
VI.CONCLUSION
We propose an email abstraction scheme that classifies spam based on naïve Bayesian approach. We explore a more robust email abstraction scheme which considers email layout structure to represent emails. The procedure generates the email abstraction using HTML content in email and this abstraction can more effectively capture the near duplicate phenomenon of spams. This algorithm successfully distinguishes spam and ham e-mails. The efficiency of the process depends on the dataset. The efficiency of the algorithm is more than 82%. In the future work, some advanced results that relate with the characterization of other classification parameters will be studied with also how the false positive/negative results can be minimized.
.
REFERENCES
[1]. W.-F. Hsiao and T.-M. Chang, “An Incremental Clus-ter-Based Approach to Spam Filtering,” Expert Systems with Applications, No. 34, No. 3, 2008, pp. 1599-1608. doi:10.1016/j.eswa.2007.01.018
[2]. S. M. Lee, D. S. Kim and J. S. Park, “Spam Detection Using Feature Selection and Parameters Optimization,” IEEE International Conference on Intelligent and Soft-ware Intensive Systems, Krakow, 15-18 February 2010, pp. 883-888. doi:10.1109/CISIS.2010.116
[3]. M. F. Saeddian and H. Beigy, “Spam Detection Using Dynamic Weighted Voting Based on Clustering,” Pro-ceedings of the 2008 Second International Symposium on Intelligent Information Technology Application, Vol. 2, pp. 122-126. doi:10.1109/IITA.2008.140
Volume 3, Issue 6, 2016
74 [5]. P. Cortez, C. Lopes, P. Sousa, M. Rocha and M. Rio, “Symbiotic Data Mining for Personalized Spam Filter-ing,” IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Milan, 15-18 September 2009, pp. 149-156. doi:10.1109/WI-IAT.2009.30
[6]. W. Lauren, “Spam Wars,” Communications of the ACM —Program Compaction, Vol. 46, No. 8, 2003, p. 136.
[7]. G. Pawel and M. Jacek, “Fighting the Spam Wars: A Re-Mailer Approach with Restrictive Aliasing,” ACM Transactions on Internet Technology (TOIT), Vol. 4, No. 1, 2004, pp. 1-30.
[8]. F. Li, H. Mo-Han and G. Pawel, “The Community Be-havior of Spammers” 2011. http://web.media.mit.edu/~fulu/ClusteringSpammers.pdf.
[9]. K. S. Xu, M. Kliger, Y. Chen, P. J. Woolf and A. O. Hero, “Revealing Social Networks of Spammers through Spec-tral Clustering,” IEEE International Conference on Com-munications, Dresden, 14-18 June 2009, pp. 1-6. doi:10.1109/ICC.2009.5199418
[10]. K. S. Xu, M. Kliger and A. O. Hero, “Tracking Commu-nities of Spammers by Evolutionary Clustering,” 2011. http://www.eecs.umich.edu/~xukevin/xu_spam_icml_2010_sna.pdf.
[11]. P. Boldi, M. Santini and S. Vigna, “PageRank as a Func-tion of the Damping Factor,” Proceedings of the 14th In-ternational Conference on World Wide Web, ACM New York, 10-14 May 2005. doi:10.1145/1060745.1060827
[12]. J. Gordillo and E. Conde, “An HMM for Detecting Spam Mail,” Expert Systems with Applications, Vol. 33, No. 3, 2007, pp. 667-682. doi:10.1016/j.eswa.2006.06.016
[13]. L. M. Spracklin and L. V. Saxton, “Filtering Spam Using Kolmogorov Complexity Estimates,” in Russian, 21st In-ternational Conference on Advanced Information Net-working and Applications Workshops (Ainaw’07), Niag-ara Falls, 21-23 May 2007, pp. 321-328.
[14]. S. V. Korelov, A. K. Kryukov and L. U. Rotkov, “Text Messages’ Digital Analysis on Spam Identification,” in Russian, Proceedings of Scientific Conference on Radio-physics, Nizhni Novgorod State University, Nizhny Nov- gorod Oblast, 2006.