IJSRSET184148 | Received:20Sep2016 | Accepted : 15Oct 2016 |September-October-2016[(2)5: 555-561]
© 2016 IJSRSET | Volume 2 | Issue 5| Print ISSN: 2395-1990 | Online ISSN : 2394-4099 Themed Section: Engineering and Technology
555
Enhanced Classification Approach for Dynamic Software
Quality Prediction
1
G.Rajendra,
2Dr.M.Babu Reddy
1Research Scholar,Department of Computer Science, Rayalaseema University, Andhra Pradesh, India 2Asst.Professor,Department of Computer Science, Krishna University, Andhra Pradesh, India
ABSTRACT
Consider the quick improvement of theitem headway application get ready in show days. Programming headway application holds a couple of absconds in introducing/executing programming things. They are cost and intense development programming progression in testing the aftereffect of the item. Usually a level of the data burrowing frameworks were made for recognize programming deformation desire from various data set applications from obvious data. One pass count is one of the frameworks for getting to organizations and diverse idiosyncrasies of the planning units logically programming application headway including the tricks of programming application like thing expense and testing thing. Programming quality and testing profitability are the essential contrivances in programming blemish figure. So in this paper we propose to make insightful portrayal count to decrease cost of the item testing change and cost estimation for programming application process. This method propose to make programming quality and testing efficiency in by building perceptive modules from code attributes present in released thing sets. In this framework, utilize data association fundamental burrowing events for finding support and sureness for each data thing present dynamically programming application headway with property portrayal. This approach is help to engineers recognize programming absconds and bolster wander organization in assigning testing methods with resources feasibly. Keywords:Software defect production, association rule mining, classification, Defect testing, cost and database.
I.
INTRODUCTION
Software engineering is the procedure of develop, design and upkeep of the applying product with modified functions of the earliest database integration. These functions termed as software growth and technology from various modified and outdated application events from other equality applications. Program growth is one of the on-line, documenting and testing involved in real time database integration. Program growth may include various functions in recent research growth processes, reuse, re-engineering servicing, prototyping and other activities in software growth application.
Figure 1 : Software development process
issue with devotee the contrivances in sensible in qualities and inadequacies. Figure 1 indicates system for development programming application including all the functional, programming and diagram utilization with testing practicalities. Consider the above talk we watch that item testing is one of the key component for investigating the tricks of workstation program that makes startling outcomes. The accomplishment of the item change depends on upon the cost and date-book, and also depends on upon quality, quality may depend on after programming defect estimate. Programming flaw is a slip, deformity, misunderstanding, and fault in machine program that conveys sudden outcomes with relative programming change application process. Programming defect conjecture is the philosophy of model that causes with convincing modules in programming headway process organization operations. [2] [6] To reducing programming surrenders continuously application
process organization with their specialist achievements of thing release quality is a guideline built up event in programming conjecture. Programming defect is condition in programming released thing does not depend on after programming essentials and end customer wants. [6] For suitable control of the item deformation figure continuously application change, data mining strategies were familiar with deliver gainful and stunning data organization operations in release programming thing handle. Data mining is the technique of analyzing data from substitute perspective data analyzation and a while later packing the data with supportive information. Assorted data burrowing systems were introduced for understanding programming blemish handle dynamically programming application progression with relative data organization operations. [3] According to the connection guideline mining in data mining strategy events in programming application change qualities they consolidate all the data measures that achieves relations in semantic data portrayal of recorded data using alliance burrowing for concentrating the characteristics of the explored
data development. [2] In connection mining unmistakable standards are formed to predict programming flaw desires with accomplice relations in various techniques for dealing with fundamental set times in semantic data portrayal of data examination. It reveals illustration and examples that are portrayed in bona fide database process. Alliance standard mining isn't simply restrict the organizations with dependence analyzation in the setting application headway besides reveal co-happening cases of the properties in data bases. [4] It takes after connection gathering for running crosswise over satisfied illustration course of action and diverse contrivances of the obliged data base diagram process. One pass count is one of the familiar figurings for depicting these events centered around gathering and helpful request for higher portrayal exactness with dynamic data event affiliations. One pass figuring depicts organization of recorded data from various data exchanges; computation takes after gainful process on appraisal and flaw desire for finding programming distortion frames in legitimate data when we apply mapping evaluation and other contrivance practices in critical data development. This strategy takes after connection rule burrowing for finding out minimum sponsorship and slightest conviction in each data thing present in chronicled data with consecutive trademark check in data analyzation of the conveyed data development. [6] [8] Using this method we reduce the item thing expense and arranging events of evident data in illustrative events to other advancing events with business development time.
programming taking care of units in data consistence with support and trust of the steady data sets for extending programming thing accreditation.
Figure 2 : Defect Prevention Strategy for Software Development Process
The fundamental thought of the affiliation decide mining that starts from recovering information things from authentic information, for instance clients purchase three items p1, p2, and p3 and sorted out with likelihood of all the item data in finding proficient information extraction forms utilizing backing and certainty with other organization comes about. In our system the accompanying technique will happens and figuring the examples of traits in information bases. Affiliation run mining investigates high certainty relationship among various factors it might conquer a few requirements presented by different strategies. The achievement of the product forecast evaluation with affiliation administer mining in different fields persuades in us to apply programming imperfection informational collection.
Remaining part of this paper proposes as follows: Section II explains all the literature review of the previous used techniques with feasibility access on advanced techniques. Section III explains Back ground work propagation of software product assurance with different values. Section IV explains Research approach of predictive classification
procedures. Section V explains experimental evaluation of each sub ordinate software product development.
II.
RELATED WORKTo improve the item quality, advantage programming engineers with data mining figurings to various programming applications with application programming customer interface schedules by a mind boggling library or framework with insufficient documentation. Programming deformation desire is a gadget and a short time later it makes among testing activities and programming progression process applications. [6] Defect markers used to make as resources of the item estimations and other eccentricity practices in business event development. Martin Shepperd presents K-infers and neural data mining techniques on differing data sets and after that delegate those terms in commonsense module portrayal with researching data into particular gatherings with defect resistance. In their examination they have presented relative outcomes performed on same data sets. [4] Partha Sarathi Bishnu presents a use of connection principle mining
Alliance desire estimation does not accomplishes portrayal of all the taking care of units.
III. BACKGROUND WORK
Association principle exploration is to discover the affiliation chooses that meet details set review era in least support and least trust with details delivers about near details process. [2] Traditional datasets are included with advancing occasions gradually development application progression. In this system chronicled details could be portioned into two courses with further review changing of all the company occasion development applications. It isolates into two ways evaluation and flaw prediction utilizing the companies of development item valuation with comparative and modern synchronisation with semantic and different gadgets are started chronicled details reflection. In this specific viewpoint reflection of the details handling there is family members reasonable presentation of every and examined delivers about company movement.
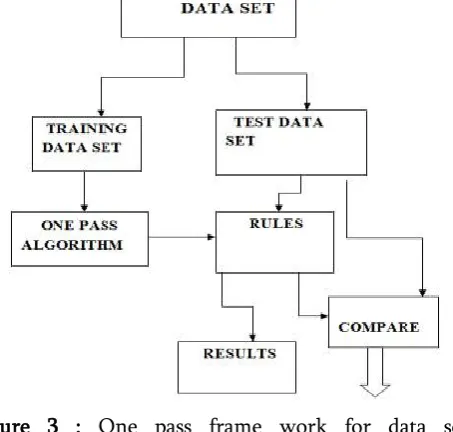
Figure 3 : One pass frame work for data set computation.
Information places are packed into memory process for handling additional requirements of organization concept exploration with conceptual and physical procedures with equal rights discussing between every product set present traditional data. [3] Process of the one successfully pass criteria can be pleased
following repercussions, publish data places and then training some datasets into necessary action in to test data for obtaining solutions from examining data then apply one successfully pass criteria on traditional data places. Compare data places into one successfully pass process immediately handling functions. Association rules are used for following language events with arranged data items in determining minimum support and confidence for obtaining solutions with relevant features of each data item.
IV. RESEARCH APPROACH
According to the utilization information places from historical datasets, then each information product measured association of memorials and processing functions of the extracted information places. [4] These procedures are analyzed into number of product places with including every product set reflection in proceeding on each information product. One pass criteria accomplishes application product price and scheduling of solutions in recommended information events. Consider the reflection of application quality assurance we offer create Predictive Category criteria for increasing the help all of the functions presented in information modulation. We offer create predictive classification criteria to decrease price of the application testing development. This criteria consists 3 phases.
1. Extraction stage 2. Learning Phase
3. Prediction Result Analysis Phase
In Extraction phase the process will include following procedure
Initialize Datasets, Transactions, Training set (TS), Testing set (TS1)
Calculate each transaction r with processing operations on training and testing extraction datasets.
Learning Phase performs following procedures.
Training data from each Data item D=d0,d1,……….dn
Test training data from Extracted data sets D=d0,d1,…...dn.
learner = Build Classifier (d’, scheme. Algorithm)
Calculate Support(S) and Confidence(C) for each attribute in data item including transactions.
V.
Prediction Results
[predictor, bestAttrs ] = Learning (historical Data)
d = select bestAttrs from new Data
Classify data with when transaction occurs Support as P(d0Ud1) for each attribute in data item.
Classify data with when transaction occurs Confidence as P(d0/d1) for each attribute in data item.
Result = Predict (d, predictor).
Algorithm 1 : Predictive Classification algorithm for software defect predictions.
Computation 1 takes after capable technique for processing minimum and most noteworthy data utility centered around association standard mining operations which joins clear illumination regarding data dismemberment and data perception which consolidates changing of data things with quantitative and subjective data things for extending limit religious in data portrayal in introduce system.
Data Source and Extraction: Data we use SEL (Software Engineering Laboratory) data sets which is sub arranged of online data sets like NASA and other amassing and recuperation of programming planning data things. [1][3] The SEL is data fabricates that give wanders in light of programming essentials with characterized characters changes and oversights being created of all the item applications. With the true objective of programming blemish desire which fuses the method of concentrated data from particular tables of SEL data labs. The distortion is greatly direct in concentrating data sets from various contrivance shapes.
Analyzation Approach: For this procedure we use endorsement framework on crossing point data events with results in all the displayed data which handle powerful work multiplication. We use connection rule mining framework to recuperate getting ready data sets from data points of view present in the business work expansion event organization. For deformation connection philosophy of concentrated data sets standard learning is straight progress while defect gauge the subsequent of a precept must be relinquish cure effort.
VI.
EXPERIMENTAL RESULTS
In this section we present trial results for problem transactional information functions when performing the functions of the organization which includes information systems unit as item releasing price and item conformative price and scheduling the item with consequence event management functions.
training and as test information places are used to problem software attempt forecast.
Feedback : Information removal with concept position RR, data places with features, problems. Output: Expected attempt for solving problem features.
Initialize the Simulation---> 0, Effect<--- Φ For each data product e€ attribute
Do
Deffect<---- e;
Apply each concept on data product r € guidelines Defect <--- Consequence(r);
Each data product feature determine the assistance and assurance
Effect<---Effect U Defect;
Simulation <--- Sim U D(attrib)/attri. Defect<----Effect(attrib).
End if End for.
Release problem factor.
Figure 4: Effort prediction procedure
Perform function with each information product then determine the efficiency of precision and quality of software product in commercial event management system application improvement. Our suggested work follows the following process activities in question assessment.
Defect Organization Prediction: When exploration problem association guidelines lowest assistance 10,20, and 30 four lowest assurance principles.
Defectf {DataV alueg} DefectfNullg@(32:5%; 79:9%).
Defectf {Comput:g ^ DefectfIni:g}
DefectfEx:Interfaceg@(34:3%; 75:1%).
The first problem concept that problem the DataValue happened in the problem process. The second concept describes example interface the methodical information reflection in determining assistance and confidence.
Constrain
Accuracy
Error
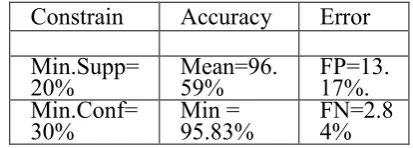
Min.Supp=
20%
Mean=96.
59%
FP=13.
17%.
Min.Conf=
30%
Min =
95.83%
FN=2.8
4%
Table 1: Defect Association Prediction Accuracy.
The quality of the problem organization relies upon upon the organization guidelines which include perfect process of researched with effect of min.supp and min.conf on each organization concept developed with commercial information gathering or amassing on each information product provided in feature reflection.
Defect Attempt Prediction: We use same options for getting and exploration problem solitude which contains problem guidelines for obtaining services.
[1] The submission effort development of all the taken five information sets give lowest support and assurance effort with equivalent formalism with sufficient information systems units.
Table 2 : Defect Isolation Effort PredictionAccuracy.
discussing of information between each information product present in asked for method structure. As caved the above table 2 accomplishes effective evaluation results like apriori organization concept exploration gives higher efficiency in evaluation working process with equivalent rights discussing with other PART, C4.5, and other Naïve Bayes methodologies.
Figure 5: Distribution co-ordination process in each rule specification with minimum confidence application format.
The operation of performing informative reflection of each data item which include procedure applications in real-time processing units.
Figure 5: Distribution functional process results using minimum support application format.
The reason organization concept exploration based forecast works so much better than other methods is that it examines high assurance organizations among several factors and finds exciting guidelines, i.e., guidelines that are useful, powerful, and significant. [1] Determined trial result show effective data set reflection in helping the quality of software in handling usage event management operations.
VII. CONCLUSION
Development quality and maintenance is primary achieving term in present discovery techniques. Expected utilized technological innovation is one pass computation for finding association tenets with least support and least trust. In this paper we offer create prescient agreement computation to reducing cost of the item examining progression and cost evaluation for programming program. Because of this device model program position we build programming statement with all the qualities in shown information set reflection in association standard discovery. It further backings the dedication that a sufficient number of concepts is a precondition for the high
prediction perfection we got in the relationship of problems privacy effort expectation.
VIII.
REFERENCES
[1]. “Software Defect Association Mining And Defect Correction Effort Prediction”, By Qinbao Song, Martin Shepperd, And Michelle Cartwright, Ieee Transactions On Software Engineering, Vol. 32, No. 2, February 2006. [2]. “ Software Defect Prediction from Historical
Data”, K.B.S Sastry, Dr.B.V.Subba Rao, and Dr K.V.Sambasiva Rao, Volume 3, Issue 8, August 2013 ISSN: 2277 128X.
[3]. Software Defect Prediction Based on Classication Rule Mining by Dulal Chandra Sahana.
[4]. Data Mining Techniques for Software Defect Prediction by Ms. Puneet Jai Kaur, Ms. Pallavi [5]. A Probabilistic Model for Software Defect Prediction by Norman Fenton, Paul Krause and Martin Neil.
[6]. Significance of Different Software Metrics in Defect Prediction by Marian Jureczko.
[7]. Using Classification to Evaluate the Output of Confidence-Based Association Rule Mining by Stefan Mutter, Mark Hall, and Eibe Frank. [8]. Association Rule Mining: A Survey by
Qiankun Zhao and Sourav S. Bhowmick. [9]. Association Rule Based Classication by Senthil
K. Palanisamy.
[10]. Software Defect Prediction Based on Association Rule Classification by Baojun Ma Karel Dejaeger Jan Vanthienen Bart Baesens. [11]. Association–Rule Mining Techniques: A