IJSRSET173888 | Received : 15 Nov 2017 | Accepted : 29 Nov 2017 | November-December-2017 [(3)8: 317-323]
© 2017 IJSRSET | Volume 3 | Issue 8 | Print ISSN: 2395-1990 | Online ISSN : 2394-4099 Themed Section: Engineering and Technology
317
Secure Web Mining System for Online E-Commerce Business
Sites
1
N. Deshai,
2Dr. I. Hemalatha,
3Dr. G. P. Saradhi Varma
1
Assistant Professor, Department Information Technology, S.R.K.R Engineering College, Bhimavaram, Andhra Pradesh, India
2Professor, Department of Information Technology, S.R.K.R Engineering College, Bhimavaram, Andhra Pradesh, India 3Professor, Department of Information Technology, S.R.K.R Engineering College, Bhimavaram, Andhra Pradesh, India
ABSTRACT
Electronic business procedures and information mining instruments have reformed many organizations. Information that organizations gather about clients and their exchanges are the best resources of that business. Information mining is an arrangement of mechanized methods used to remove covered or already obscure snippets of data from substantial databases, utilizing diverse criteria, which makes it conceivable to find examples and connections. This paper talks about the critical part of business in light of information mining learning improvement to recognition the connection of information mining and electronic trade. What's more, express a few applications and difficulties for this situation.
Keywords : Data Mining, E-Commerce, Web Mining, Business Intelligence, Web Personalization.
I.
INTRODUCTION
In internet business sites, you can offer, publicize, and present various types of administrations and items in the web. Web based business sites have the benefit of achieving a substantial number of clients paying little heed to separation and time constraints. The upside of web based business over customary organizations is the quicker speed and the lower costs for both internet business site proprietors and clients in finishing client exchanges and requests. As a result of the above focal points of internet business over conventional organizations, a great deal of ventures in various fields, for example, retailing, keeping money, medicinal administrations, transportation, correspondence, and instruction are setting up their business in the web. Be that as it may, making a fruitful online business can be an extremely troublesome and expensive errand if not considering web based business web composition standards, web building systems, and what web based business should improve the situation the online business. Web mining can be extensively characterized as revelation and investigation of valuable data from the World Wide Web. In view of the diverse accentuation and distinctive approaches to acquire data, web mining can be separated into three noteworthy classes. The first
is web content mining. The information is taken from Web page substance i.e. from the points of various destinations the valuable information can be extricated.
Web information mining is a branch of information mining. It is progress effective innovation through which data is sifted less demanding. Thus, web information mining turned into a freely open source that gives promising outcomes. With the utilization of web based business through web, organizations locate another and better approach to work together. Subsequent to building up the site thought organizations get benefits, they ought not sit loose. Organizations need to execute Web mining frameworks to comprehend their clients' profiles and to distinguish their own quality and shortcoming of their E-advertising endeavors on the web through constant upgrades. Web is a gold mine, however just for those organizations who understand the significance of Web mining and receive a Web mining procedure now. Web mining innovation has numerous essential parts that ought to be said. It can consequently discover, separate data from the assortment web assets. It additionally creates, enhances and improves the quality and the proficiency of web crawlers, decides pages or records, makes arrangements. It can likewise produce extensive scale continuous information. Web information mining finds valuable data from the Web hyperlink and page content. It has effectively changed the substance of numerous business capacities in a cutting edge focused endeavor. It is clearly simpler to settle on right business choices or comprehend the data that originated from clients with the assistance of web information mining. It encourages online business to see how to enhance its administrations for unique gatherings of clients and customers, and what errands to figure it out. The web based business webpage can build the presentation of its item pages thus normal request size can be expanded. Organizations can spare level of its financial plan every month inferable from learning that was gotten from web mining examination. Web information mining assembles certain learning about customers and educates internet business in each perspective. At that point, it separates profitable and understandable data from colossal web assets to train web based business.
It additionally accumulates the data in a mechanized way and constructs models used to anticipate client acquiring choices. Web mining is valuable to the organization in the fields of understanding client conduct, enhancing client administrations and relationship, propelling target showcasing efforts, measuring the achievement of promoting endeavors, and soon. The example disclosure procedures
incorporate calculations to discover intriguing and valuable examples from web information. Some of them are affiliation rules, grouping, successive examples, and arrangement and so on. Example investigation procedures are utilized to feature general examples in information and to sift through uninteresting examples. The factual information ought to be examined on the sorts of guests that go to the site. Likewise, it is critical to examine the means guests make to achieve the site. Some of the time, these are comparative advances, comparative catchphrases or comparative labels. Further, affiliation rules are inferred with a specific end goal to recognize the relationships between's the site pages. At that point it ought to be examined how the objective of the customer's visit was fulfilled. With the huge measure of clients, it is surely known in the web information mining. There are a few strategies for web information mining in web based business. The way investigation strategy is utilized to enhance the page and site structure. Disclosure of affiliation rules clarifies how the activities are connected. This technique lights up unneeded data from website pages. Disclosure of grouping models strategy customizes benefits through the conduct of the clients. Disclosure of grouping guideline technique discloses how to characterize clients. The disclosure of bunch investigation demonstrates how the clients are like give better administrations in online business.
II.
LITERATURE REVIEW
Data mining on social security and social welfare data (2014)
security/welfare services and data, and the different methods for SSDM framework.
Efficient Algorithms for Mining High Utility Item sets from Transactional Databases (2013).
Mining high utility item sets from a transactional database refers to the discovery of item sets with high utility like profits. Although a number of useful algorithms have been proposed in recent years, they incur the problem of producing a large number of candidate item sets for high utility item sets. Such a huge number of candidate item sets degrades the mining performance in terms of it require more execution time and large space requirement. The situation may become worse when the database contains lots of long transactions or long high utility item sets. In this we propose two algorithms, namely utility pattern growth (UP-Growth) and UP-Growth+, for mining high utility item sets with a set of effective strategies for trimming candidate item sets. The information of high utility item sets is maintained in a tree-based data structure name utility pattern tree(UP-Tree) such that candidate item sets can be generated efficiently with only two scans of database. The performance of Growth and UP-Growth+is compared with the state-of-the-art algorithms on many types of both real and synthetic data sets. Experimental results show that the proposed algorithms, especially UP-Growth+, not only reduce the number of candidates effectively but also outperform other algorithms substantially in terms of runtime, especially when databases contain lots of long transactions.
Data Mining with Big Data
Big Data concerns with huge amount of data, complex, growing data sets with multiple, autonomous sources. With the rapid development of networking, data storage, and the data collection capacity, Big Data is now fastly expanding in all science and engineering domains, including physical, biological and biomedical sciences. This article presents a HACE theorem that characterizes the features of the Big Data revolution, and proposes a Big Data processing model, from the data mining perspective. This data driven model involves demand driven aggregation of information sources, mining and analysis, user interest modeling, and security and privacy considerations. We analyze the challenging
issues in the data driven model and also in the Big Data revolution.
Predicting School Failure Using Data Mining (2013).
This system proposes to apply data mining techniques to tell in advance school failure. We have used real data about 670 middle-school students from Zacatecas, México. Several operations have been carried out in an attempt to improve accuracy in the prediction of final student performance and, specifically, of which students might fail. In the first experiment the best 15 attributes has been checked. Then two different techniques have be seen applied in order to resolve the problem of classifying unbalanced data by rebalancing data and using cost sensitive classification. The outcomes of each one of these approaches using the 10 classification algorithms and 10 fold-cross validations are shown and compared in order to select the best approach to our problem.
Data Mining in Electronic Commerce
Modern business is moving hurriedly toward e-commerce. If the transition is done properly, it enables better management, new services, lower transaction costs and better customer relations. Success depends on skilled information technologists, among who are statisticians. In this focuses on some of the contributions that statisticians are making to help change the business world, especially through the development and application of data mining in systematic way. This is a very big area, and the subjects we cover are chosen to avoid overlap with other system in this special issue, as well as to respect the limitations of our expertise. Inevitably, electronic commerce has raised and is raising fresh research problems in a very wide range of statistical areas, and we try to emphasize those challenges.
III. SYSTEM ARCHITECTURE
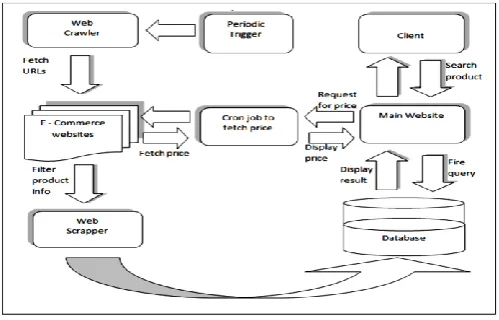
coordinates with the items, rejecting process begins. Crawler intermittently gets data from online business sites to check for refreshes .If refreshes are accessible crawlers conveys those updates and rolls out essential improvements in the database. Web rejecting basically comprises of two assignments: first is to stack the coveted website page and second is to parse HTML data of the page to find proposed data.
Figure 1: System Architecture
In this framework Rejecting is finished utilizing python as it gives rich arrangement of libraries to address these assignments. "demands" is utilized to stack the urls and "Beautifulsoup" library is utilized to parse the site page. In the wake of rejecting the items data from various internet business sites the information is put away in MongoDB database. Utilizing pymongo network information is rejected and put away in database. The frond end comprises of Fundamental site. The customer looks for the required item in seek bar and inquiry is terminated in nearby database i.e. MongoDB. The site is outlined utilizing Django web structure which is composed in python. Correspondence is done between python web system and MongoDB utilizing Mongoengine which is a python protest – archive mapper working with MongoDB. Required outcomes are recovered and shown on Fundamental site. The customer would then be able to think about costs of items that are accessible on web based business sites. A soon as customer chooses on best arrangement as indicated by him ,he will be diverted to the first online business site .Another component gave is, Customers can contrast items that have a place with same classification in order to separate details and pick in like manner.
IV.
IMPLEMENTATION
Techniques In Data Mining In E-Commerce
Web Content Mining
It alludes to mining the E-substance of Website pages. Web content mining is a programmed procedure that concentrates designs from information/web substance/reports, for example, the HTML records, pictures, or Messages, and it goes past just catchphrase extraction or some straightforward measurements of words and expressions in archives. Web content mining could take favorable circumstances of the semi-organized nature of Website page content. It can be utilized to identify co-events of terms in writings.
Web Structure Mining
Web structure mining, a Contributing piece of web mining concentrated on utilizing the investigation of the connection structure of the web, and its motivations is to recognize more ideal archives. It principle concentrated on that a hyperlink from report A to archive B infers that the creator of record A thinks record B contains beneficial data.. when we take the structure of hypertext, Web structure mining abuses the extra data that is (frequently verifiably) contained in the structure of hypertext.
Web Usage Mining
workgroup, and hierarchical framework. Dissecting client get to designs encourages in focusing on promotions to particular gatherings of clients for offering ads on the Internet.
Web Data Collection
The principle undertaking is to get information from Web record , a few considerations ought to be there that occasionally data assets isn't restricted to online Web reports, yet in addition incorporates email, electronic archives, news gathering, or the webpage through the Internet log information and even the arrangement of exchange information in the database.
Preprocessing of Web Data
The genuine information that will be gathered for the most part have the highlights that fragmented, repetition and vagueness. Mining the learning all the more adequately, pre-handling the information gathered is basic. Preprocessing gives precise, succinct information for information mining. Preprocessing of Information, incorporates information cleaning, client distinguishing proof, client sessions distinguishing proof, get to way supplement and exchange recognizable proof.
Discovery of Pattern from Web Data
Example revelation gives us compelling, novel, possibly, helpful and at last justifiable data and learning utilizing mining calculation. The primary strategies are arrangement investigation, affiliation lead revelation, consecutive example disclosure, bunching examination, and reliance displaying.
ANALYSIS OF PATTERN OF WEB DATA
Example investigation is for the most part worried about choosing design we are occupied with from the example set found by show design revelation calculation. The primary point is to discover a profitable model, in particular, the principles and modes we are occupied with and giving graphical UI utilizing representation methods to clients.
In this segment, we review articles that are certain to information mining usage in web based business. The remarkable utilizations of information mining strategies
are exhibited first. Later in this segment, design and information gathering issues are talked about.
CUSTOMER PROFILING
It might be watched that clients drive the incomes of any association. Getting new clients, charming and holding existing clients, and foreseeing purchaser conduct will enhance the accessibility of items and administrations and consequently the benefits. Along these lines the true objective of any information mining exercise in online business is to enhance forms that add to conveying an incentive to the end client. Consider an on-line store like http:www.dell.com where the client can design a PC of his/her decision, put in a request for the same, track its development, and in addition pay for the item and administrations. With the innovation behind such a site, Dell has the chance to influence the retail to encounter outstanding. And no more essential level, the data accessible in web log documents can distinguish what forthcoming clients are Organizations like Dell give their clients access to insights about the greater part of the frameworks and designs they have obtained so they can join the data into their ability arranging and foundation reconciliation. Back-end innovation frameworks for the site client profiles and prescient displaying of situations of client cooperation’s. For instance, switches, switches, stack balancers, reinforcement gadgets and so on. Administer mining based frameworks could look for from a site. Of the incorporate refined information mining instruments that deal with learning portrayal of once a client has bought a specific number of servers, they are probably going to require extra used to propose such other options to the clients.
RECOMMENDATION SYSTEMS
web based business to specialist organization to figure the request of item classes better. Information mining has additionally been connected in distinguishing how clients may react to limited time offers made by a charge card online business organization. Strategies including fluffy registering and interim processing are utilized to create if-then-else rules. At exhibit a technique to fabricate client profiles in web based business settings, in light of item chain of command for more compelling personalization. They separate every client profile into three sections: essential profile gained from client statistic information; inclination profile gained from behavioral information, and run profile chiefly alluding to affiliation rules. In light of client profiles, the creators produce two sorts of suggestions, which are intrigue proposal and affiliation proposal. They additionally propose an uncommon information structure called profile tree for compelling looking and coordinating.
CUSTOMER BEHAVIOR E-COMMERCE
For an effective internet business webpage, diminishing client saw idleness is the second most imperative quality after great website route quality. The best approach towards diminishing client saw idleness has been the extraction of way traversal designs from past clients get to history to anticipate future client traversal conduct and to prefetch the required assets. In any case, this approach is suited for just non-online business locales where there is no buy conduct. Vallamkondu Grunewald depicts a way to deal with anticipate client conduct in online business destinations. The center of their approach includes removing information from coordinated information of procurement and way traversal examples of past clients (possible from web server logs) to foresee the buy and traversal conduct of future clients. Sites are regularly used to set up an organization's picture, to advance and offer products and to give client bolster. The achievement of a site influences and reflects straightforwardly the accomplishment of the organization in the electronic market. SpiJiopoulou and Pohle propose a technique to enhance the accomplishment of sites, in view of the abuse of route design disclosure.
Specifically, the creators exhibit a hypothesis, in which achievement is displayed on the premise of the route conduct of the site's clients. They at that point misuse web utilization digger (WUM), a route design disclosure
excavator, to examine how the accomplishment of a website is reflected in the clients' conduct. With WUM the creators measure the achievement of a site's segments and get solid signs of how the site ought to be moved forward. With regards to web mining, grouping could be utilized to bunch comparative snap streams to decide learning practices on account of e-Iearning or general website get to practices in internet business. The greater part of the calculations displayed in the writing to manage bunching' web sessions regard sessions as sets of went by pages inside a day and age and don't consider the arrangement of the snap stream appearance. This has a huge result when contrasting similitude’s between web sessions. Wang and Zaiane propose a calculation in light of grouping arrangement to gauge likenesses between web sessions where sessions are sequentially requested successions of page gets to.
V.
RESULTS
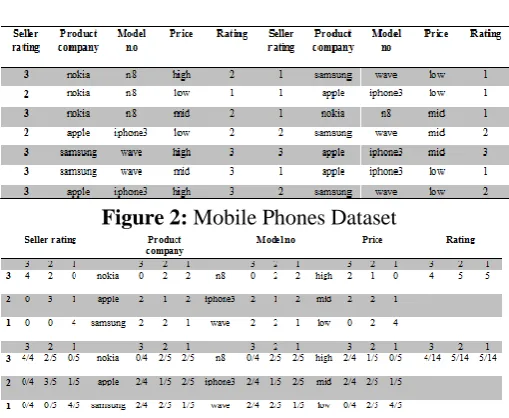
Figure 2: Mobile Phones Dataset
Figure 3: Frequencies and probabilities for the mobile
phones data
CLUSTERING
will be put away in the organization's client profile database, and will be utilized for future information mining reason. A case of bunching could be: half of customers who connected find platinum card in/discover card/customer Service/new card, were in the 25-30 age gathering, with yearly wage between $40,000 – 50,000. Bunching of customer data can be utilized on the advancement and execution of future promoting procedures, on the web as well as disconnected, for example, mechanized mailing effort.
VI. CONCLUSION
This paper demonstrates how we can defeat the customary method for study for client criticism and utilize examination to total and abridge the input from the client which is accessible online as item surveys. By utilizing the investigation framework, the cost and time expected to examine how an item is getting along in the market can be diminish definitely. This gives the chance to respond speedier to the client dissensions and requirements. Utilizing investigation one can undoubtedly screen their item online progressively by gathering information from Amazon, E-cove and Flipkart. The trial aftereffect of investigation utilizing preparing set demonstrates that, the Choice classifier has performed superior to Guileless Bayes classifier with better accuracy, review and F-Measure. For cell phones dataset, the classifier has accomplished an exactness level of 99% by Choice Tree classifier and 67% by Credulous Bayes classifier.
VII.
REFERENCES
[1]. M. S. Chen, J. Han and P. S. Yu, "Data mining: An overview from database perspective," IEEE Trans. on Knowledge and Da Engineering, vol. 8, no 6, pp.866-883, December 1996.
[2]. V. S. Tseng, B. E. Shie, C. W. Wu and P. S. Yu, "Efficient algorithm for mining high utility itemsets from transactional databases," IEE Trans. On Knowledge and Data Engineering, vol. 25, no. 8, pp.177 1786, August 2013.
[3]. D. L. Banks and Y. H. Said, "Data mining in electronic commerce Statistical Science, vol. 21, no. 2, pp.234-246, May 2006.
[4]. L.-J. Kao, Y.-P. Huang and F.E. Sandnes, "Associating unobserved frequent itemsets with infrequent items to identify abnormal transactions," Applied Intelligence, November 2014.
[5]. M. S. Chen, J. Han and P. S. Yu, "Data mining: An overview from database perspective," IEEE Trans. on Knowledge and Da Engineering , vol. 8, no 6, pp.866-883, December 1996.
[6]. V. S. Tseng, B. E. Shie, C. W. Wu and P. S. Yu, "Efficient algorithm for mining high utility itemsets from transactional databases," IEE Trans. On Knowledge and Data Engineering, vol. 25, no. 8, pp.177 1786, August 2013.
[7]. D. L. Banks and Y. H. Said, "Data mining in electronic commerce Statistical Science, vol. 21, no. 2, pp.234-246, May 2006.