ContentslistsavailableatScienceDirect
Neurocomputing
journalhomepage: www.elsevier.com/locate/neucom
Object-adaptive
LSTM
network
for
real-time
visual
tracking
with
adversarial
data
augmentation
Yihan
Du
a,b,
Yan
Yan
a,∗,
Si
Chen
c,
Yang
Hua
d aSchoolofInformatics,XiamenUniversity,Fujian361005,ChinabInstituteforInterdisciplinaryInformationSciences,TsinghuaUniversity,Beijing100084,China cSchoolofComputerandInformationEngineering,XiamenUniversityofTechnology,Fujian361024,China dSchoolofElectronics,ElectricalEngineeringandComputerScience,Queen’sUniversityBelfast,UK
a
r
t
i
c
l
e
i
n
f
o
Articlehistory: Received 16 July 2019 Revised 5 December 2019 Accepted 6 December 2019 Available online xxxCommunicated by Dr. Jianbing Shen Keywords:
Visual tracking LSTM network
Generative adversarial network Data augmentation
a
b
s
t
r
a
c
t
Inrecent years,deeplearningbasedvisualtrackingmethodshaveobtainedgreatsuccessowingtothe powerfulfeaturerepresentationabilityofConvolutionalNeuralNetworks(CNNs).Amongthesemethods, classification-basedtrackingmethodsexhibitexcellentperformancewhiletheirspeedsareheavilylimited bytheexpensivecomputationformassiveproposalfeatureextraction.Incontrast,matching-based track-ingmethods(suchasSiamesenetworks)possessremarkablespeedsuperiority.However,theabsenceof onlineupdating rendersthesemethodsunadaptable tosignificantobjectappearancevariations.Inthis paper,weproposeanovelreal-timevisualtrackingmethod,whichadoptsanobject-adaptiveLSTM net-worktoeffectivelycapturethevideosequentialdependenciesandadaptivelylearntheobjectappearance variations.Forhighcomputationalefficiency,wealsopresentafastproposalselectionstrategy,which uti-lizesthematching-basedtrackingmethodtopre-estimatedenseproposalsandselectshigh-qualityones tofeedtotheLSTMnetworkforclassification.Thisstrategyefficientlyfiltersoutsomeirrelevant propos-alsandavoidstheredundantcomputationforfeatureextraction,whichenablesourmethodtooperate fasterthanconventional classification-based trackingmethods. Inaddition, tohandlethe problemsof sampleinadequacyandclassimbalanceduringonlinetracking,weadoptadataaugmentationtechnique basedontheGenerativeAdversarialNetwork(GAN)tofacilitatethetrainingoftheLSTMnetwork. Ex-tensiveexperimentsonfourvisualtrackingbenchmarksdemonstratethestate-of-the-artperformanceof ourmethodintermsofbothtrackingaccuracyandspeed,whichexhibits greatpotentialsofrecurrent structuresforvisualtracking.
© 2019 Elsevier B.V. All rights reserved.
1. Introduction
Visual trackingaims to trackan arbitraryobject throughouta video sequence, where the target is solely identified by the an-notation in the first frame. As a fundamental problem in com-puter vision, visual tracking has extensive applications such as video surveillance, human-computer interaction and automation. Despiterapidprogress inthe pastfew decades,visual trackingis stillverychallengingsincethetrackersarepronetoshowinferior performance undercomplex scenesincluding occlusion, deforma-tion,backgroundclutter,etc.
Inrecent years,deeplearninghasbroughtasignificant break-throughintrackingaccuracyowingtothepowerfulfeature repre-sentationabilityofConvolutionalNeuralNetworks(CNNs)[1].The
∗ Corresponding author.
E-mailaddress: [email protected](Y. Yan).
deeptrackingmethods[2–5]canberoughlydividedintotwo cat-egories, i.e., classification-based tracking methods and matching-based tracking methods. Classification-based tracking methods [2,3,6]trainan onlineclassifier to distinguishthe objectfrom the background.However,mostofthesemethodscontaincomplex fea-tureextractionstagesformassiveproposalsandsophisticated on-line updating techniques to adapt the network to the arbitrary temporally changing object. As a result, although thesemethods have achievedpromising accuracy, the heavy computational bur-den renders these methods difficult to satisfy the real-time re-quirement of the tracking task. In addition, some high-accuracy trackers[2,3,6]pre-traintheirnetworksbasedonthevideosfrom the visual tracking benchmarks, which may raise the risk of over-fitting.
Matching-based tracking methods [4,5,7] usually firstly learn general matching models offline on the large dataset (such as ILSVRC15 [8]). Then, thesemethods directly matchthe candidate proposals withthe target template using the pre-trainedmodels
https://doi.org/10.1016/j.neucom.2019.12.022 0925-2312/© 2019 Elsevier B.V. All rights reserved.
Fig.1. Comparison between our method (OA-LSTM-ADA) and the state-of-the-art matching-based tracking methods, i.e., CFNet [9], RFL [10]and SiamFC [5], on the Bolt and DragonBaby [11]sequences. Our tracker that utilizes background information with online adaptability performs more robustly than the other trackers when encountering object deformation and background clutter.
during online tracking. The succinct online tracking algorithms makethesemethods possessremarkablespeed superiority. How-ever, due to the inherent lack of online adaptability and the ignoranceofbackgroundinformation,thesematching-based track-ingmethods cannot well handletheobjectappearance variations andsimilar objectsin the background.Thus, thesemethods usu-allysufferfromdrift whenthe objectappearance changesorthe similarobjectappearsinsome complexscenes.Recent matching-basedtracking methods[9,10] areproposed toonline updatethe matchingtemplate ofthe object,but they still donot utilize the background information sufficiently. Fig. 1 shows a comparison between our method and some state-of-the-art matching-based tracking methods, i.e., CFNet [9], RFL [10] and SiamFC [5]. The compared matching-based tracking methods cannot effectively trackthetarget whenencountering thesignificant object appear-ance variations or complex background, while our method can accuratelylocatethetargetpositioninthesechallengingsituations. Most of existing deep learning based tracking methods take advantage of the powerfulness of CNN in feature representation, whilethesemethods cannot fullyutilizethetemporal dependen-ciesamongsuccessiveframesin avideosequence.Different from thetraditionalCNN-basedtrackingmethods,weconsidertheLong Short-TermMemory(LSTM) [12]network, avariantof the Recur-rentNeuralNetwork(RNN) [13],which canmemorize useful his-torical information and capturelong-range sequential dependen-cies.Based on the LSTM network, we are able to utilize the se-quentialdependencies andlearn thetarget appearance variations viamaintaininganinternalobjectrepresentationmodel.
Inthispaper,weproposeanovelobject-adaptiveLSTMnetwork forvisual tracking,whichcan fullyutilizethe time dependencies amongsuccessiveframesofavideosequenceandeffectivelyadapt tothe temporally changing objectvia memorizing the target ap-pearancevariations. Sincethe proposed LSTM networkis learned online1 asa per-object classifier,ourtracker can effectivelytrack anarbitraryobjectwithsuperioradaptabilitytosequence-specific circumstances.Furthermore,duetoitsintrinsicrecurrentstructure, ournetworkcandynamicallyupdatetheinternalstate,which char-acterizestheobjectrepresentationduringtheforwardpasses. For highcomputational efficiency,we alsopresenta fastproposal se-lectionstrategy.Inparticular,wemakeuseofthematching-based
1In this paper, “online” refers to that only the information accumulated up to the present frame is used for inference during tracking.
tracking method to pre-estimate the dense proposals and select high-qualityonestofeedtotheLSTMnetworkforclassification.In thisstrategy,wedirectlyobtaintheproposalfeaturesfromthebig featuremap ofthesearch regionso thatonlyone feature extrac-tionoperationisperformed.Inthisway,theproposedstrategycan effectively filter out the irrelevant proposals and only retain the high-quality ones. As a result, the computational burden of pro-posalfeatureextractionislargelyalleviated.
Inordertohandlethesampleinadequacyandclassimbalance problemsduringthe onlinelearningprocess, we alsoadopt Gen-erative Adversarial Network (GAN) [14] to generate diverse pos-itive samples, which augments the available training data and thus facilitates the training of the LSTM network. In this paper, GANis trained inthe firstframe and updated inthe subsequent frames during tracking. We refer to our method as an Object-AdaptiveLSTM networkwithAdversarial DataAugmentation (OA-LSTM-ADA) for visual tracking. Fig. 2 illustrates the pipeline of ourtrackingmethod.Experimental resultsontheOTB (both OTB-2013andOTB-2015)[11],TC-128[15],UAV-123[16]andVOT-2017 [17]benchmarksdemonstratethatourmethodachievesthe state-of-the-art performancewhile operatingatreal-timespeed, which exhibits great potentials of recurrent structures for visual object tracking.
Wesummarizeourmaincontributionsasfollows:
• We propose a novel object-adaptive LSTM network for visual tracking,whichfullyexploits thesequentialdependenciesand effectivelyadaptstotheobjectappearancevariations.Duetoits intrinsicrecurrentstructure, the internal state ofthe network canbedynamicallyupdated duringtheforwardpasses. There-fore,theproposedmethodisabletorobustlytrackanarbitrary objectundercomplexscenarios.
• We propose a fast proposal selection strategy, which utilizes thematching-basedtrackingmethodtopre-estimatethedense samplesandselectshigh-qualityonestofeedtotheLSTM net-work.The proposedstrategy directlyobtainsthe proposal fea-turesfromthefeaturemapofsearchregion.Inthismanner,the expensivecomputationalcostforproposalfeatureextractionin conventionalclassification-based tracking frameworksis effec-tivelyreduced,bywhichourmethodcanoperateinreal-time.
• Weproposeadataaugmentationstrategytoaddressthe prob-lemsof sampleinadequacyandclass imbalanceduringonline learningof theLSTMnetwork. Weusean onlinelearnedGAN to generate diverse positive samples with sequence-specific
Search Region
Template
Features of Selected Proposals
Feature Maps
Tracking Result
Discriminator
Generator
Los
s
Conv
Layers
Response Map
Random Variable
Real Data
Generated Data
Adversarial Data Augmentation
Discriminator Loss
Generator
Loss
Binary
Classification
LSTM
Conv
Layers
Fig.2. Pipeline of the proposed method for visual object tracking. During online tracking, we maintain a set of high-confident tracking results including the given original object. The real data fed to the discriminator are drawn according to this tracking result set. The “Loss” at the far right of the “Adversarial Data Augmentation” part collectively refers to the discriminator loss and generator loss of GAN. The black solid arrows represent the links between blocks. The black dashed arrow between “Generated Data” and “LSTM” means that the generated data of GAN augment the training samples of LSTM. The red solid arrows stand for the backpropagation direction of losses during the training of GAN.
information,whichenrichestheavailabletrainingdataandthus facilitatesthetrainingoftheLSTMnetwork.
This paper is an extension of our previous work [18]. In this paper, we accelerate the proposed method by directly obtaining the proposalfeatures from thefeature map of thesearch region. No extracomputational costforproposalfeature extractionis re-quired.Thus, our methodcan operatein real-time.Moreover, we additionally investigate the problems of sample inadequacy and class imbalance duringthe online trainingof the LSTM network. Specifically, we propose to use a GAN to augment the available trainingdata,whichsignificantlyimprovestheperformanceofthe originalmethod.Theexperimentsarealsoextendedviapresenting resultsofthefurtherinternalcomparison,state-of-the-art compar-isonandattribute-basedcomparison.
The restofthis paperisorganizedasfollows: Section 2gives anoverviewoftherelatedwork.Section3discussestheproposed trackingmethod,which containsthecomponentsofthefast pro-posalselectionstrategy,theobject-adaptiveLSTMnetworkandthe dataaugmentationtechnique.Section4describestheproposed on-linetrackingalgorithm.Section5presentstheexperimentalresults on fourpublictrackingbenchmarks. Conclusionsandfuturework aredrawninSection6.
2. Relatedwork
Inthissection,webrieflyreviewthedeeplearningbased track-ingmethodsanddiscusstherelatedworksonRNNsandgenerative adversariallearning.
Visual tracking. Visual tracking has been actively studied over the past few decades andit remains one of the mostimportant andchallenging problemsin computer vision.A large numberof visual trackingmethods, including sparse representation [19–24], multipleinstance learning[25–27]andcorrelationfilters [28–31], have been proposed. For example, a strong classifier and struc-turallocalsparsedescriptorsareintroducedfortrackingobjectsin [19]. In [21], a tracking method which jointlylearns a nonlinear classierandavisualdictionaryinthesparsecodingmanner,is pro-posed.In[22],theauthorsusesparsecodingtensors torepresent
targettemplates andcandidates,andbuild theappearance model viaincrementally learning.Atrackingframework whichcombines blurstateestimationandmulti-taskreversesparselearning,is pro-posedin [23].A generalized featurepooling method [24] is pre-sentedforrobustvisualtracking.Anoveltwo-stageclassifierwith thecirculantstructure[32]isdevelopedtoaddressscenes includ-ing occlusion.In[33],the authorsemploy a partspacewithtwo onlinelearnedprobabilitiestorepresentthetargetstructure.A hy-perparameteroptimizationmethod[34]isproposed forrobust ob-jecttracking.
In recent years, deep learning based tracking methods [2,3,5,35] have shown their outstanding performance by taking advantage of the powerful ability of CNNs in feature represen-tation. These methods can be roughly divided into classification-based tracking methods and matching-based tracking methods. Classification-basedtrackingmethods[2,3]treatvisualtrackingas abinaryclassificationproblem,whichaims todistinguishthe ob-jectfromthebackground.Forexample,MDNet[2]adoptsa multi-domainlearning strategyto utilizelarge-scale annotated tracking dataandlearn an online per-object classifier.SANet [3]proposes a structure-aware network to handle similar distractors. MRCNN [35]introducesaparticlefilterbasedtrackingframeworkbytaking advantageofanonlineupdatedmanifoldregularizeddeepmodel. Althoughthesemethodsachievehightrackingaccuracy,the expen-sivecostspentonthemassiveproposalfeatureextractionand so-phisticatedonlinefine-tuningheavily limitstheir speeds. Besides, thesemethodsperformthepre-trainingstagesontracking bench-markdatasets,whichmayraisetheriskofover-fitting.
Matching-based tracking methods [4,5,7] are developed to matchthecandidateproposalswiththetarget templateusingthe generalpre-trainednetworks. These methods usually donot per-formanyonlineupdatingproceduressothattheypossess remark-able speed superiority. Siamese network isone ofthe most rep-resentativemethods. For example,GOTURN [4] uses the Siamese network to directly regress the object location from the pre-vious frame. SiamFC [5] proposes a fully-convolutional Siamese network to learn a general similarity function. Despite the effi-ciency ofthese methods,the inherent lack ofonline adaptability Please citethisarticleas:Y.Du,Y. YanandS.Chenetal.,Object-adaptiveLSTM networkforreal-timevisual trackingwithadversarial
makes them prone to drift when the object appearance signifi-cantlychangesorsimilarobjectsappear.
Recently, severalSiamesenetworkbasedtrackers[36–41]have been proposed to address the above problems, which can im-prove the tracking accuracy while preserving real-time speeds. For example, DSiam [36] proposes a dynamic Siamese network with transformation learning and EAST [37] learns a decision-makingstrategy ina reinforcementlearningframework for adap-tivetracking.SiamFC-tri[38] incorporatesanoveltripletloss into the Siamese network to extract expressive deep features. Siame-seRPN [39] proposes an offline trained Siamese Region Proposal Network(RPN).DaSiameseRPN [42] improvesSiameseRPN by in-troducingadistractor-awaremodule.C-RPN[43]proposesSiamese cascadedRPNstosolvetheproblemofclassimbalanceby perform-inghardnegativesampling.HASiam [40]introduces theattention mechanismintotheSiamesenetworktoenhanceitsmatching dis-crimination. Quad [41] proposes a quadruplet network to detect thepotentialconnectionsoftraininginstancesforbetter represen-tation. In contrast to the above Siamese based methods, we use theSiamese network to selecthigh-quality proposalsfor compu-tationalefficiencyandlearnareal-timeobject-adaptiveLSTM net-worktoclassifytheseselectedproposals.Asaresult,theproposed trackereffectivelycaptures theobject appearance variationswith onlineadaptability.
Recently, some works[44–46]adoptspecialized attention net-worksforsaliencyprediction.Differentfromtheseworks,we em-ploythe fast proposal selection strategy for salientobject detec-tion,whichefficientlyselectshigh-qualityproposalsandfiltersout theirrelevantonesaccordingtothematching-basedresponsemap.
Recurrent neural networks. Recurrent Neural Networks (RNNs) have drawn extensive attention due to their excellent capability ofmemorizingusefulhistoricalinformationandmodeling sequen-tial data. Gan et al. [47] and Kahou et al. [48] use attention-based RNNs for visual tracking, but these methods only demon-strate their effectiveness on simple datasets (such as MNIST) in-steadof naturalvideos. Re3 [49]proposesa recurrent regression modelto offline learn the changes in the target appearance and motion.SANet [3]incorporates RNNsintoCNNsto modelthe ob-jectstructureandimprovethetracking robustness.Notethat RFL [10]andMemTrack[50]alsocombineSiamesenetworksandLSTM networksto trackobjects. Theyadoptpre-trainedLSTM networks astargetinformationmemorizerstoupdatethetemplate-matching procedureinSiamesenetworks.However,differentfromtheabove methods,in this paperwe useSiamese network as a coarse ob-ject pre-estimator to filter out irrelevant proposals and train an LSTM network online as a fine object-specific classifer to distin-guishtheobjectfromthebackground.OurLSTMclassifiercannot onlysequence-specificallyutilizebothforegroundandbackground information,butalso effectively equipthe proposed tracker with adaptabilitytotheobjectappearancevariationswhileoperatingin real-time.
Generative adversarial learning. Recently, generative adversarial learning has been widely applied to visual tracking. The state-of-the-arttracker, VITAL[6],proposesto useGANto identify the masksthatmaintainrobustfeaturesoftheobjectoveralong tem-poral span. AlthoughVITAL achieves hightracking accuracy, it is veryslowduetomassivefeatureextractionsandsophisticated on-linefine-tuning procedures. SINT++ [51] generates diverse posi-tivesamples via adeep generativemodel andlearnsa hard pos-itive transformation network with reinforcement learning to oc-cludetheobject withbackgroundimage patchforhigher robust-ness.However, its slowbasictracker(i.e., SINT [7]) heavily limits itstrackingspeed,whichisfarfromthereal-timerequirement. In thispaper,wedirectlyemployGANasanimagedataaugmenterto generatediversepositivesamplesintheimagespace,while main-taininga real-timetrackingspeed.The generatedrealistic-looking
sampleimagesenrichtheavailabletrainingdataandthusfacilitate thetrainingoftheLSTMnetwork.
3. Theproposedmethod
3.1. Overview
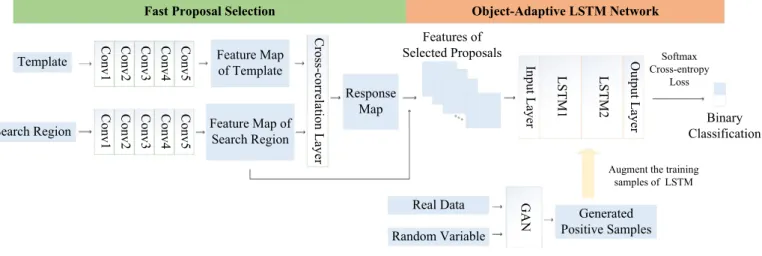
AsshowninFig.3,theproposedmethodconsistsoftwostages,
i.e.,fastproposalselection viaapre-trainedSiamesenetworkand objectclassificationviaanonlineobject-adaptiveLSTMnetwork.
Inthefirststage,we utilizetheSiamesenetworktomatchthe target templatewiththesearch regioncenteredatthe previously estimated target position. As a result, we can obtain a response map, which denotes thesimilarities betweenthe target template andtheproposalsinthesearchregion.Basedontheresponsemap, we selectthehigh-qualityproposalsandcrop their featuresfrom thebigfeaturemapofthesearchregiontofeedtothesubsequent LSTM network for classification. This proposal selection strategy notonlyefficientlyfiltersouttheirrelevantproposals,butalso sig-nificantlyreducesthecomputational costforproposalfeature ex-traction. Therefore, our method can operate in real-time, which is faster than conventional classification-based tracking methods [2,3].
Inthesecondstage,welearnanobject-adaptiveLSTMnetwork onlineto classify theinput proposalfeatures basedon sequence-specific information. Taking advantage of the superior ability of LSTMtomemorizeusefulhistoricalinformation,wefeedtheLSTM networkwiththeselectedproposals,togetherwiththepreviously estimatedtargetstate.Bydoingthis, theLSTMnetworkisableto identifytheoptimaltargetstateaccordingtotheinternalnetwork statewhicheffectivelymemorizestheobjectappearancevariations overalongtemporalspan.Owingtotheintrinsicrecurrent struc-tureoftheLSTMnetwork,theinternalnetworkstatecanbe simul-taneously updated when a forward pass is performed. Note that theSiamesenetworkusedinourmethodispre-trainedonalarge dataset(i.e.,ILSVRC15[8])andtheproposedobject-adaptiveLSTM network is learned online. Therefore, our method is able to ro-bustlytrackanarbitraryobjectwithoutsufferingfromtheproblem ofover-fittingtothetrackingdatasets.
In order to address the problems of sample inadequacy and class imbalance duringthe online learning process of LSTM net-work,wemakeuseofGANtogeneratediversepositivesamplesto approximatetherealtargetimages.Thegenerateddiversepositive samples are incorporated into the training dataset of LSTM net-work. Such a strategy effectively augments the available training dataandthusimprovesthetrackingperformanceofourmethod.
3.2. Fastproposalselection
In the conventional classification-based tracking framework (suchas[2,3]),trackersusuallygeneratemassivecandidate propos-alsviadensesamplingandthenevaluatetheseproposalsthrough convolutional feature extractors and binary classifiers. However, thedenselysampledproposalsincludemanyirrelevantandtrivial proposals,whichare farawayfromthe objectcenter.Asa result, the unnecessary highcomputational cost isspent on thestep of massive proposalfeature extraction,which heavily constrainsthe trackingspeed.
Recently, a number of matching-based tracking methods [4,5,7]aredevelopedtodirectlycomparethetargettemplatewith thesearchregion(andthesemethodsusuallydonotinvolveonline updating procedures). These methods possess remarkable speed superiority, butthey lackof onlineadaptability tosignificant ob-jectappearance variations. Motivatedbythisobservation,we uti-lizearepresentativematching-basedtrackingmethod,SiamFC [5], to pre-estimate the dense proposals and obtain their confidence
Features of
Selected Proposals
Fast Proposal Selection
Object-Adaptive LSTM Network
Binary
Classification
Template
Search Region
Response
Map
Conv1
Conv2
Conv3
Conv4
Conv5
Conv1
Conv
2
Conv
3
Conv4
Conv5
Cross-correlat
ion Layer
Feature Map
of Template
Feature Map of
Search Region
Input Layer
LSTM
1
LSTM2
Output Layer
GA
N
Random Variable
Real Data
Generated
Positive Samples
Adversarial Data Augmentation
Softmax Cross-entropy
Loss
Augment the training samples of LSTM
Fig.3. Overview of the proposed method.
scores.Then,weselecttheproposalsofhighconfidencescoresand crop their featuresfromthebigfeature mapofthe searchregion tofeedtothesubsequentLSTMnetworkforfurtherclassification.
Specifically,SiamFC[5]trainsafully-convolutionalSiamese net-workofflinetocomparethetargettemplatewiththesearchregion. Bytakingadvantageofabilinearlayerwhichcalculatesthe cross-correlationofinputsfromtwostreams,itisabletoachievedense sliding-window evaluationin a single forwardpass. The Siamese networkcanbeformulatedasthefollowingsimilarityfunction, F
(
z,x)
=ϕ
(
z)
∗ϕ
(
x)
+kI, (1) wherez isatemplate imageandxisa searchregion.ϕ
refersto a convolutional embeddingfunction andFrepresents asimilarity metric. ‘∗’ is the cross-correlation operation. kI denotes a signal that takes thevalue k∈Rin every position.F(z, x), denotingthe outputoftheSiamesenetwork,isascoremap,whichcontainsthe similaritiesbetween thetarget template andeach candidate pro-posalinthesearchregion.As mentioned above, we aim to filter out the irrelevant and trivial proposals far away from the object center, which can ef-fectively reduce the redundant computation for proposal feature extraction. Although the matching-based tracking method (such as SiamFC [5]) is sensitive to the changes in object appearance andcontexts, itcanbe effectivelyusedasa coarsepre-estimator. Such a pre-estimator can identify irrelevant and trivialproposals bycomparingthemwiththeinitialobjectappearance.Hence, tak-ing advantage of the high computational efficiency of the fully-convolutionalSiamese network,weselecttheproposalsthathave highconfidence scores tomake further evaluationvia the subse-quentLSTMnetwork.
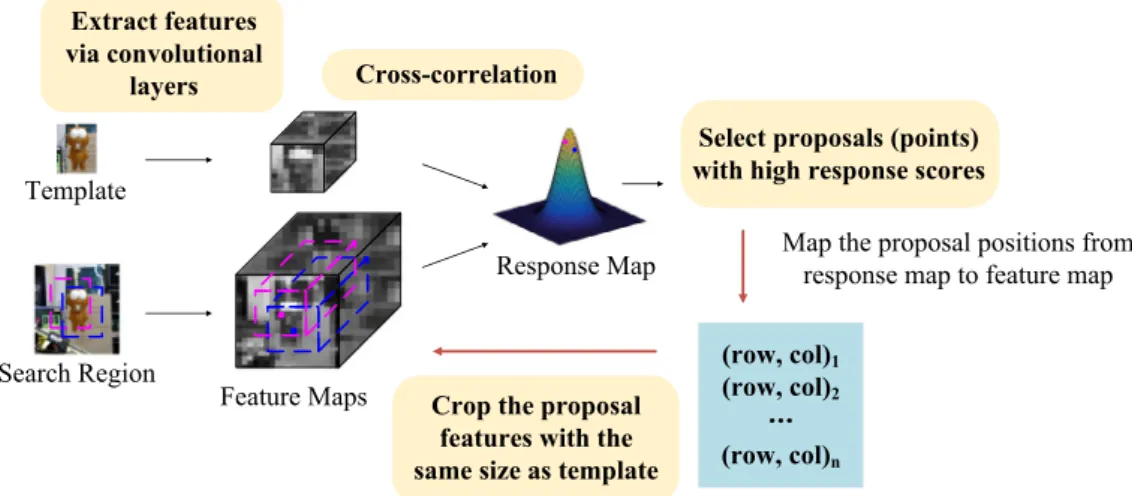
Itisworth pointingoutthat, differentfromourpreviouswork [18],we directlycrop thefeatures ofthe selectedproposals from thefeaturemapofthesearchregionatthelastconvolutionallayer. AsdepictedinFig.4,ascorevalueinthefinalresponsemap cor-respondstoasub-windowinthesearchregion.Thus,wecancrop thefeatureofaproposalbylocatingitscorresponding positionin the search region,where thesize offeatures is thesame asthat ofthetemplatefeatures.Then,wefeedhigh-qualityproposals(i.e., the selectedproposalswithhighconfidence scores)totheonline trainedLSTMnetworktoperformfineestimation.
Thisfastproposalselectionstrategyavoidsamassofredundant computationforthe trivialproposals andenablesthe feature ex-tractionforalltheproposalstobe performedinasingle convolu-tionalforwardpass.Suchamannerefficientlyacceleratesthe
con-ventional classification-based tracking framework. Note that this proposal selection strategy is adopted to optimize the computa-tional efficiencyof proposal feature extraction,while the follow-ingLSTMnetworkisproposedtofinelydetecttheobjectfromthe selectedproposalswiththehighadaptabilitytoconstantly chang-ing target appearance and contexts. Bothcomponents are tightly coupled topromote the tracking performance in both speed and accuracy,especiallyinchallengingscenes.
3.3.Object-adaptiveLSTMnetwork
3.3.1. LSTMnetworkforclassification
Different fromthe existing classification-based tracking meth-ods[2,3],whichsimplytrainthefully-connectedlayersasa classi-fier,inthispaperweapplyanonlineLSTMnetworktovisual track-ingforclassification.AsanalternativeRNN,theLSTMnetwork in-heritsthepowerfulcapabilityofRNNsinmodelingsequentialdata by memorizing the previous input information. In particular, the introductionof the forget mechanism enables theLSTM network tonotonlycapturelong-rangetemporaldependencies,butalso ig-noredistractinginformation.Hence, theproposedLSTM classifica-tion network, which is designed to suit the visual tracking task, canadapt tothe temporallychanging objectappearance and dis-criminatethe trackedtarget fromthe distractors (suchassimilar objectsinbackground).
As discussed in Section 3.2, we can obtain high-quality pro-posalsthroughtheproposedfastproposalselectionstrategy.Then, theseselected proposals are further estimatedby the LSTM net-work using the learned temporal dependencies and memorized historical information. Note that, different from common LSTM networks[10,49,50]thattakeasequenceasaninputandcombine thehiddenstatesofseveraltimestepsasanoutput,ourLSTM net-worktakesa batch ofproposalfeaturesinthe currentframeand thepreviously estimatedLSTMstate asinputs, andthenestimate a classification result for each proposal features in each frame. The classification resultis solely derived from the calculation of thecurrenttimestep.Afterfinishingtheestimationforthecurrent frame,we choose theLSTM state corresponding tothe estimated target state asanewreliable objectrepresentation model,which storestemporaltargetinformationandisusedinnextestimation.
3.3.2. Forwardpass
As depicted in Fig. 5, the internal architecture of our LSTM blocksis astandard model,whilethe input layerandthe output Please citethisarticleas:Y.Du,Y. YanandS.Chenetal.,Object-adaptiveLSTM networkforreal-timevisual trackingwithadversarial
Extract features
via convolutional
layers
Cross-correlation
Template
Search Region
Feature Maps
Response Map
Crop the proposal
features with the
same size as template
Select proposals (points)
with high response scores
Map the proposal positions from
response map to feature map
(row, col)
1(row, col)
2Ă
Ă
(row, col)
nFig.4. An illustration of the proposed fast proposal selection strategy. In this example, the purple and blue points in the response map denote the similarities for the corresponding proposals in the search region. We crop their features (corresponding to the purple and blue rectangular solids, respectively) from the feature map of the search region. ft it ot zt ht ct tanh Input Layer Output Layer
Feature Maps of the Selected Proposals
Classification Result batch_size×17×17×32 batch_size×2×1 WInput, bInput WOutput, bOutput rt xt batch_size×2048×1 t-1
ˆh
t-1ˆc
batch_size×9248×1 Reshaped t-1 t-1ˆ
t-1ˆ
ˆ
State = (c , h )
...
...
batch_size×2048×1 batch_size copies of and corresponding to the previously estimated target batch_size×2048×1 batch_size×2048×1 ... ... batch_size×2048×1 t-1 ˆc t-1ˆh New Estimated Target
New LSTM State t ˆx t t
ˆ
tˆ
ˆ
State = (c , h )
t-1 ˆx...
tanh...
Fig.5. The architecture of the proposed LSTM network. ˆ ct−1and hˆ t−1are the cell and hidden states of the previously estimated target, which together compose the previously estimated LSTM state Stateˆ t−1. xtis the reshaped feature vector of a 17 ×17 ×32 proposal feature map. ztis the transfromed feature vector of xtby the input layer. ctand
htare the generated cell and hidden states corresponding to xt.rtis the classification result. ft,itand otdenote the parameters of forget gates, input gates and output gates
in the LSTM blocks, respectively. WInput,bInput,WOutputand bOutputrespectively represent weight matrices and bias vectors of the input and output layer. In practice, the new
estimated LSTM state Stateˆ t=(cˆ t,hˆ t) corresponding to the new estimated target ˆ xtis fed to the next time step, which allows the information of object representation to
propagate through time.
layeraremodifiedtoclassifythefeaturemapsofselected propos-als.Toobtain suitable inputsforourLSTM blocks(vectors inRn ,
wheren is the number of LSTM units), each feature map of se-lectedproposalsisdirectlyreshaped toavectorxt ∈Rm .The
sub-sequentinput layeris implementedusing afully-connected layer witha weightmatrixWInput∈Rm ×n andabias vectorbInput∈Rn ,
whichtransformsxt ∈Rm tozt ∈Rn .TheinputsofLSTMblocksin
the tth frame consist of three components, i.e., the transformed proposalfeaturevectorzt ,theestimatedcellcˆt−1andhiddenstates
ˆ
ht−1 in the
(
t−1)
th frame.Bothhˆt−1 andcˆt−1 store theprevioustargetinformation.Forbrevity,we denotetheinternal LSTMstate inthetthframebyatupleStatet =
(
ct ,ht)
.Hence,theLSTMblocks takethefeaturevectorztandthepreviouslyestimatedLSTMstateˆ
Statet−1 asinputs.Note that inthefirst frame,giventhe annota-tion, we can obtain the initial LSTM state State1 by passing the
initialtarget feature x1 through theLSTM network. Thus,we can
start the online tracking process from the second frame using
State1.
The parameters ofinput gates it andoutput gates ot in LSTM
blockscontrolthewritingandreadingfornewtargetinformation. The parameters offorget gate ft control to ignore theuseless in-formationsuchasthebackgroundordistractors.TheLSTMblocks calculatecorresponding cell ct andhidden statesht for each fea-ture vector zt , according to the previously estimated LSTM state
ˆ
Statet−1. Notethat our goal isto classify each proposal features, sowe useafully-connected layerwithaweight matrixWOut put ∈
Rn×2 andabiasvector b
Out put ∈R2 andafollowingsoftmax
oper-ationtoimplementtheoutputlayer.
By comparing the historical target information stored in ˆ
Statet−1 with each proposal feature vector xt , our LSTM net-work can generate a corresponding new LSTM state Statet (i.e.,
Statet=
(
ct,ht)
, which stores the representation information ofxt )andtheclassificationresultrt ∈R2 (i.e.,rt =
(
p+(
xt)
, p−(
xt))
T ,where p+
(
xt)
and p−(
xt)
are the positive andnegativescores ofxt). The tracking result is determined by choosing the proposal
considered torepresenttheoptimal targetstate andusedforthe next estimation. In online tracking, Stateˆ t maintains an internal object representation model, which can be dynamically updated while receivingnewobjectfeatures. The proposedLSTM network learns to classify the input proposalfeatures xt according to the previously estimated LSTM state Stateˆ t−1. Specifically, the for-ward passofthe proposed LSTMnetwork canbe calculated with Eqs.(2)–(8). InputLayer: zt =WT Input xt +bInput (2) InputGate: it =
σ
(
Uιzt +Vιˆht−1+b ι)
(3) ForgetGate: ft =σ
(
Uνzt +Vνhˆt−1+b ν)
(4) OutputGate: ot =σ
(
Uωzt +Vωhˆt−1+b ω)
(5) Cell: ct =ft cˆt−1+it tanh(
U c zt +Vc hˆt−1+bc)
(6)CellOutput: ht =ot tanh
(
ct)
(7)OutputLayer: rt =Softmax
(
WOut put T ht +bOut put)
(8)where it, ft and ot denote the parameters of input gates, forget
gates and outputgates inthe LSTM blocks,respectively. U,V are the weight matrices and b is the bias vector. The subscript
ι
,ν
,ω
andc respectivelyrefer totheinput gates, forgetgates, output gates and LSTM cells. ‘’ represents the element-wise product. tanh andσ
respectivelydenotethe hyperbolictangent activation functionandsigmoidactivationfunction.Softmax(·)representsthe softmaxactivationfunction.3.3.3. Backwardpass
We aim to sufficiently utilize the sequence-specific informa-tion totrackan arbitraryobjectandavoidtherisk ofover-fitting to the datasets from the visual tracking domain.Thus, we adopt an onlinelearningstrategy totrain theLSTMnetwork forthe vi-sual tracking task.Particularly, duringthe trainingprocess inthe
tth frame, instead of feeding a sequence of training data to the LSTM network asdone in[10,49,50],we use the previously esti-matedLSTMstateStateˆ t−1andthetrainingsamplesSt drawnfrom the current frame to train a per-object classifier. In thismanner, theLSTM networklearnstodistinguishtheobjectfromthe back-groundinaccordancewiththepreviouslymemorizedobject infor-mation.Thetraininglossisdirectlyderivedfromtheclassification results.Thus,itdoesnotneedtopropagatethroughnoisy interme-diatetimesteps,whichcanacceleratetheconvergenceoftheLSTM network.
Specifically, inthe1stframe,we passtheinitial targetfeature
x1 through the LSTM network and obtain the initial LSTM state
State1=
(
c1, h1)
.Then,weuseState1 andtrainingsamplesS1gen-erated around the original target positionto train theLSTM net-work.Inthetth frame,wegeneratethetrainingsamplesSt accord-ingtotheestimatedtargetstate.TheLSTMnetworkisupdated us-ing St andthepreviously estimatedLSTM state Stateˆ t−1 toobtain online adaptabilityto the temporally changingobject appearance andcontexts. We usethecross-entropyloss functionL for train-ing. The backward pass inthe trainingprocess can be calculated withEqs.(9)–(11).
t r de f =
∂
∂
Lrt∂
rt∂
Softmax(
·)
(9)t h =WOut put
r t (10)
t c =
(
ot)
tanh(
ct)
h t +ot tanh
(
ct)
h t (11)
where
t r is definedas thederivative of loss function L with re-specttothesoftmaxactivationfunctionSoftmax(·),i.e.,the deriva-tive ofthe softmaxcross-entropyloss function.
h t and
c t denote the derivatives of loss function L with respect to ht and ct , re-spectively.(ot)referstothederivativeofotwithrespecttoct,i.e.,
(
ot)
=∂o t∂c t.tanh(·)representsthederivativeofthehyperbolic tan-gentactivationfunction.
3.4.DataaugmentationwithGAN
Tolearnarobustclassifierthat caneffectivelydiscriminatethe objectfromthebackgroundinchallengingscenes,theonline train-ingof theLSTM networkrequires adequatelabeled trainingdata. However, sinceonly one objectis provided despitethe compara-tively broadbackground forthe visual tracking task,the number ofpositivesamplesisrelativelysmallandisfarlessthanthe num-berofnegativesamples.The problemsofsampleinadequacyand positive-negativeclassimbalancewillhindertheonlinetrainingof theLSTMnetworkandneedtobetackledproperly.Comparedwith ourprevious work [18],we presenta dataaugmentationstrategy basedonGAN[14]togeneratediversepositivesamplesinthe im-age space. The proposed strategy enriches the available training dataandthuseffectivelyboosts theperformance oftheproposed method.
In this paper, we adopt a recently developed generative ad-versarial model[52] (DCGAN) forthe trainingstability. Since the tracking methodneeds to trackan arbitraryobject, it is difficult topre-traina generalsampleaugmenter.Therefore,duringonline tracking,we trainGANinthefirstframe tolearntheoriginal tar-get appearance and then update it with real sampled images in thesubsequentframestoeffectivelycapturetemporarilychanging targetappearance.
In the generative adversarial learningprocess, a real image x
ofpositive sampledrawn from theframes obeysthe distribution
Pimg(x). The model containsa generator G to learn thisreal data
distribution anda discriminator D to distinguish the real images fromthe generated images. The generator takes a noise variable
Pnoise (z) asthe input and it outputs an image G(z) that approxi-matestherealimagePimg (x).ThediscriminatorDtakesbothPimg (x) andG(z) asinputsandoutputs their classification probability.On onehand,we trainDtomaximizetheclassification probabilityof assigningthecorrectlabelstoboththerealimagesandgenerated images.Ontheotherhand,wetrainGtomaximizetheprobability ofDmakingamistake,i.e.,tominimizetheclassification probabil-ityofG(z) assignedwiththecorrectlabel. Hence,D andGplay a two-playerminimaxgamewiththefollowingfunction:
min
G maxD F
(
D,G)
=Ex ∼P img(x )[logD(
x)
]+Ez∼P noise(z)[log
(
1−D(
G(
z)))
]. (12) Bytheadversarialtraining,DandGboosttheirrespective per-formance from each other until D cannot distinguish the differ-encesbetweentherealimagesandthegeneratedones.Inthisway,Geffectively learnsthereal data distributionPimg . The generated imagescloselyapproximatetherealimages.
Fig.6presentstherealimagesofpositivesamplesandthe gen-eratedpositivesamplesbasedonGAN.Wetakerealimagesof pos-itivesamplesasPimg (x),whicharedrawnaroundtheestimated tar-getpositionfromvideo frames.Thenoise variablePnoise (z) is ran-domlygenerated.After theadversariallearningprocess, weapply thelearned generator Gto samplea numberof positive samples
G(z). Then, we augment the training data of the LSTM network withthese generatedpositive samples. Bythis way,the problem of class imbalance is alleviated. As shown in Section 5.2.2, this
Fig.6. The left two columns in the red rectangle are real images of positive samples. The right eight columns are the generated positive samples with GAN on the four sequences from the OTB dataset (from top to down: Boy,Girl,Tiger1and Coke, respectively).
data augmentation strategy facilitates the online training of the LSTMnetworkandimprovesthetrackingaccuracyoftheproposed method.
3.5.Discussions
It isworth mentioningthat theproposed methodexploits but differsfromthepreviousworks,includingSiamFC[5]andDCGAN [52].
In this paper, we propose a novel and fast proposalselection strategytoacceleratetheLSTMclassificationnetwork.Specifically, we take advantage of the response map of the matching-based tracking method (SiamFC is used in this paper) to select high-quality proposals and directly obtain the proposal features from thefeaturemapofsearchregion.Suchastrategyeffectivelyavoids theheavy computationforproposalfeatureextractioninthe clas-sificationbasedtrackingframework.Incontrast,SiamFC adoptsan offlinepretrainedmodel,whichdirectlyoutputstheproposalwith thehighest response scoreas the trackedresult. Inother words, SiamFC does not perform object-adaptive proposal re-estimation andinherentlylacksonlineadaptability.
TheproposeddataaugmentationtechniqueisbasedonDCGAN. However,DCGAN[52]istrainedonvariousimagedatasetsfor gen-eralimage representations, while our data augmenter is learned onlinewith sequence-specific information, which better suits for thevisualtrackingtask.Inaddition,weincorporateitintoour re-currenttracking model to facilitate the training of the proposed object-adaptiveLSTMnetwork.
4. Onlinetrackingalgorithm
4.1.Onlinetrainingofthenetworkmodel
As discussed inSection 3.2, theSiamese network (i.e.,SiamFC [5]) used in our fast proposal selection is trained offline using pairsofimagestakenfromtheILSVRC15[8]dataset,whichavoids the risk of over-fitting to the datasets in the visual tracking do-main.SincetheSiamesenetworkisusedasacoarsepre-estimator, we directly apply the pre-trained Siamese network to selectthe high-qualityproposals without online updating. In the following, we introduce the online trainingof the LSTM network, which is designedtofurther estimate the selectedproposals by exploiting temporaldependencies.
Given the annotated first frame, we feed the LSTM network with the original target appearance to initialize the LSTM state. Then,wedrawthepositiveandnegativesamplesaroundthe origi-naltargetpositionwiththenormaldistribution.Weusethe train-ing samples from the first frame andthe original LSTM state to traintheLSTMnetworkasstatedinSection3.3.Inthesubsequent frames, we update the LSTM network usingthe trainingsamples drawnaroundtheestimatedtargetpositionandthepreviously es-timated LSTM state. Through online learning, the LSTM network isencouragedtodiscriminatetheobjectfromthebackground ac-cording tothe previously estimatedLSTM state whichstores the historical information of object representation. Besides, due to its intrinsic recurrent structure, the LSTM network can dynami-cally update its recurrent parameters duringthe forwardpasses. Thus,themodelofobjectrepresentationstoredintheLSTM state is constantly updated as new inputs of proposal features are received.
4.2. OnlinetrackingusingOA-LSTM-ADA
OuronlinetrackingalgorithmoftheObject-AdaptiveLSTM net-workwithAdversarialData Augmentation(OA-LSTM-ADA)is pre-sentedinAlgorithm1.Thesimilaritylearningfunction F refersto the Siamese network[5] used inthe fastproposal selection step (seeSection3.2).Fcanberegardedasageneralfunctionthat cal-culatesthesimilaritiesbetweenthetargettemplateandthe candi-datepatches.
θ
isapredefinedthresholdfortheonlineupdateof theLSTMnetwork.Whenthepositivescoreoftheestimatedtarget stateexceedsθ
,thetrackedresultisconsideredtobereliableand itcanbeusedforthesamplingoftrainingdata.In the first frame, we initialize the LSTM network using the original target state x1 and train the network with the training
data S1 drawn from the first frame. The drawn positive data s1 + aretakenastheinput realimagesfortheinitial trainingofGAN. Aftertheinitial training,thegeneratorofGANcoarselylearnsthe appearancerepresentationoftheobject.
Inthesubsequenttthframe,wefirstlypre-evaluatethedensely sampled proposals with the similarity learning function F and select high-quality ones to feed to the following LSTM network. Then, the selectedproposals are estimatedby the LSTM network according to the previously estimated LSTM state Stateˆ t−1. We obtainthepositivescoresandnegativescoresoftheselected pro-posals andtreat theone withthe maximumpositive scoreto be thetrackedresultxˆt .TheoptimalLSTMstateStateˆ t corresponding
Algorithm1 TrackingalgorithmofOA-LSTM-ADA.
Input: Originaltargetstatex1,similaritylearningfunctionF,
pre-definedthreshold
θ
Output: Estimatedtargetstatexˆt
1: InitializetheObject-AdaptiveLSTMnetworkusingx1;
2: Sampletrainingdatas1
+ands1−fromthe1stframe,
S1←
{
s1 +}
∪{
s1−}
;3: TraintheObject-AdaptiveLSTMnetworkusingS1;
4: TrainGANwiththepositivesampless1 +;
5: repeat
6: Apply the similarity learningfunction F to obtain a confi-dencemap M ;
7: SelectNhigh-scoreproposals
{
xt i}
N i =1fromM;8: Evaluate
{
xt i}
iN =1 with the previously estimated LSTM state ˆStatet−1 toobtaintheirpositivescores
{
p+(
xt i)
}
N i =1;9: Findthetrackedresultbyxˆt =argmaxx t ip
+
(
xt i)
; 10: SettheoptimalLSTMstateStateˆ t correspondingtoxˆt ;11: if p+
(
xˆt)
>θ
then12: Sampletrainingdatast
+andst−byusingthehardnegative miningtechnique,St ←
{
s+t}
∪{
st −}
;13: Take
{
s1+,...,s+t
}
astheinputs,andgeneratediverse posi-tivesamplesgt+usingGAN,St←St∪
{
gt+}
;14: UpdatetheLSTMnetworkusingSt ;
15: endif
16: untilendofsequence
toxˆt isaccordinglyupdatedandwillbeusedfortheestimationof
targetstateinthenextframe.
When the positivescore ofthe estimatedtarget state exceeds
θ
, we perform the update procedure. In order to improve the robustness of the LSTM network to deal with the similar ob-jects inthebackground,we applythe hardnegativemining tech-nique [53]to drawtrainingsamplesSt .Notethatwe candirectly use the confidence map M to selecthard negative samples and do not require the extra computational cost for sample evalua-tion. This technique makes the LSTM network more discrimina-tive when thebackgroundcontainssimilar objectsto thetracked target.Taking the positive samples
{
s1+,...,st +
}
as the input real im-ages,weuseGANtogeneratediversepositivesamplesgt+and aug-mentthetrainingdataSt .Therefore,theLSTMnetworkisupdated with theaugmented training dataSt that contain adequate posi-tivesamplesandhardnegativesamples.Thisstrategyprovidesthe LSTM networkwithhighadaptabilitytothetemporarilychanging objectandbackground.
5. Experiments
Toevaluatetheperformance oftheproposedtrackingmethod, we conductextensiveexperimentsonfourpublic tracking bench-marks,i.e.,OTB(including OTB-2013[54]andOTB-2015[11]), TC-128 [15], UAV-123 [16] and VOT-2017 [17]. In Section 5.1, we present the implementation details and parameter settings used inourexperiments.InSection5.2,weevaluateourtrackeronthe OTB dataset by providing internal comparison,quantitative com-parison, attributed-based comparison andqualitative comparison. InSection 5.3,Section 5.4andSection 5.5,we conductthe evalu-ationontheTC-128,UAV-123andVOT-2017datasetsrespectively, showingtheresultsofquantitativecomparisonwithseveral state-of-the-arttrackers.
5.1. Implementationdetailsandparametersettings
Our tracker, OA-LSTM-ADA, is implemented in Python using TensorFlow [55]. It runs at an average speed of 32.5 fps with a 2.7GHzIntelCorei7CPUwith16GBRAMandanNVIDIAGeForce GTXTitanX GPU.In theproposed fastselection strategy, we uti-lize the matching-based trackingmethod, i.e.,SiamFC-3s [5](the version searchingover3scales instead of5scales).The template usedinthe Siamesenetwork istheoriginal objectappearance in the firstframe. We set the size of the Siameseresponse map to 33× 33 without upsampling. Toobtain the features of the se-lected proposals, we crop the feature patches with the size of 17× 17 (the samesize asthe templatefeature patch) fromthe featuremap(withthesizeof49 × 49)ofthesearchregion.Since SiamFC-3sscales theexemplarimagesandsearchimageswithan addedmarginforcontext,we settheparameter ofcontext to0.2 to alleviate the effects ofthe added context in ourclassification model.Weexperimentally select64high-qualityproposals,which iseffectiveandefficientfora trade-off betweenperformance and speed.
IntheproposedLSTMnetwork,weadoptatwo-layerLSTM net-work,eachlayerofwhichhas2048units.WeusetheADAM gradi-entoptimizer[56]withasoftmaxcross-entropylossfunctionand alearningrateof10−5.Inthe proposeddataaugmentation
strat-egy,we utilizea recentstate-of-the-artmodel (DCGAN [52]) and generate64positive samples ineach update. InAlgorithm1, the positive score of the estimated target state p+
(
xˆt)
is normalized andthethresholdparameterθ
foronlineupdateoftheLSTM net-work is set to 0.6, which is efficient experimentally. In addition, weconductalltheexperimentswiththesameparametersettings toguaranteethereliabilityofourexperimentalresults.5.2.EvaluationonOTB
5.2.1. Datasetandevaluationmetrics
The OTB-2013 [54] dataset consists of 50 fully annotated video sequences withelevenchallengingattributes, such asscale variation, illumination variation, occlusion, etc. The OTB-2015 [11]dataset is the extended version of OTB-2013,which contains the entire 100 fully annotated video sequences with substantial variations.
WeadoptthestraightforwardOne-PassEvaluation(OPE)asthe performance evaluation method. For the performance evaluation metrics, we use precision plots and success plots. Following the protocolintheOTB benchmark,we usethethresholdof20pixels andareaundercurve(AUC)topresentandcomparethe represen-tativeprecisionplotsandsuccessplotsoftrackers,respectively.
5.2.2. Internalcomparison
InOA-LSTM-ADA,we adoptanovelobject-adaptiveLSTM net-work to utilize time dependenciesand memorize the object ap-pearance variations. We also employ the fast proposal selection strategytoimprovethecomputationalefficiency.Inaddition,to fa-cilitatetheonlinetrainingoftheLSTMnetwork,wepresentadata augmentationtechnique basedon GAN. Tovalidate the effective-nessofeach componentinOA-LSTM-ADA, weinvestigateits four variants:
• OA-FF: afeed-forward variant,wheretheLSTMnetwork is re-placedbythefully-connectedlayers.
• OA-LSTM-PS: a variant without using fast proposal selection, which performs dense samplingand tracksthe object via the proposedLSTMnetwork.
• OA-LSTM: our previous work [18], which cumbersomely ex-tracts the proposal features by passing the proposal patches throughconvolutionallayersanddoesnotemploythedata aug-mentationtechnique.
Fig.7. Results of internal comparison on the (a) OTB-2013 and (b) OTB-2015 datasets. The speeds are presented in the legend.
• OA-LSTM+:an acceleratedversion ofOA-LSTM[18],which di-rectly crops the proposal features from the feature map of search regionanddoesnotadoptthedataaugmentation tech-nique.
We evaluate four variants on the OTB-2013 and OTB-2015 datasets and compare their tracking performance with the pro-posedOA-LSTM-ADA.
As shown in Fig. 7, all the variants perform worse than OA-LSTM-ADA in terms of tracking accuracy. OA-FF simply classifies the selected proposals with the fully-connected layers and it does not effectively capture time dependencies among sequen-tial frames. As a result, OA-FF cannot adapt to the temporarily changingobject,andthusitispronetodriftinchallengingscenes. OA-LSTM-PSismuchslowerthanothermethodsduetotheheavy computational burden caused by dense sampling. OA-LSTM and OA-LSTM+ show similar tracking accuracy due to the effective-ness of the object-adaptive LSTM network. However, OA-LSTM+ achievesahigherspeedbydirectlyobtainingtheselectedproposal features from the big feature map of the search region, which acceleratesour original fast proposal selection strategy. This im-pliesthattheproposed fastproposalselectionstrategy effectively reduces the redundant computation for feature extraction and leads to a significant speedup. OA-LSTM-ADA achieves the best tracking accuracy and satisfactory speed among the compared
versions.ThisisbecausethatOA-LSTM-ADAemploysGANto aug-ment training data forthe online training of the LSTM network, whicheffectivelyimprovesthetrackingperformance.Althoughthe speed of OA-LSTM-ADA is slightly lower than that ofOA-LSTM+ duetotheadditionaldataaugmentationtechnique,OA-LSTM-ADA achieves significant improvements intracking accuracy by taking advantageofenrichedtrainingsamples.
Moreover, we further experimentally investigate the influence ofthenumberofselectedproposalsmandthepredefined thresh-old
θ
ontheperformanceandspeedofOA-LSTM-ADA.Weselecta rangeofvaluesforthesetwoparameters,i.e.,m∈{32,64,128}andθ
∈{0.5,0.6,0.7}.TheresultsaregiveninFig.7.AsshowninFig.7, theproposedmethodwiththeparametersettingm=64,θ
=0.6 forOA-LSTM-ADAobtainsthebestperformance amongallthe pa-rametersettings.Whiletheproposedmethodwiththisparameter settingshowsslightlyslowerspeed thanthat withtheparameter settings m=32,θ
=0.6 andm=64,θ
=0.7, it achievesbetter trade-off betweentracking accuracyandspeed. Therefore,we setm=64,
θ
=0.6forpracticalefficiencyinthefollowing.5.2.3. Quantitativecomparison
As illustrated in Fig. 8, we compare the precision plots and success plots obtained by our OA-LSTM-ADA and several state-of-the-arttrackers includingMemTrack[50],TRACA[57], SiamFC-tri[38],CFNet2-tri [38],ACFN[58],CNN-SVM[59],DLSSVM [60],
Fig.8. Precision plots and success plots showing the performance of our OA-LSTM-ADA compared with other state-of-the-art trackers on the (a) OTB-2013 and (b) OTB-2015 datasets.
SiamFC [5], CFNet [9], CSR-DCF [61], Staple [30], RFL [10], KCF [29] and CNT [62]. We choose these methods because SiamFC, CFNet,SiamFC-triandCFNet2-triareSiamesenetworkbased track-ingmethods,whicharecloselyrelatedtoourOA-LSTM-ADA(recall that OA-LSTM-ADA utilizes the Siamese network to pre-estimate thedensely sampledproposals). MemTrackandRFLalsocombine the Siamese networks and LSTM networks, but their LSTM net-worksareusedforobjecttemplatemanagement.Sinceourtracker adopts deep features for object representation, we choose some representativemethods basedon deepfeatures, i.e.,TRACA,ACFN, CNN-SVM,DLSSVMandCNT.Wealsochoosesomestate-of-the-art real-timemethodsbasedoncorrelationfilters,i.e.,CSR-DCF,Staple andKCF.
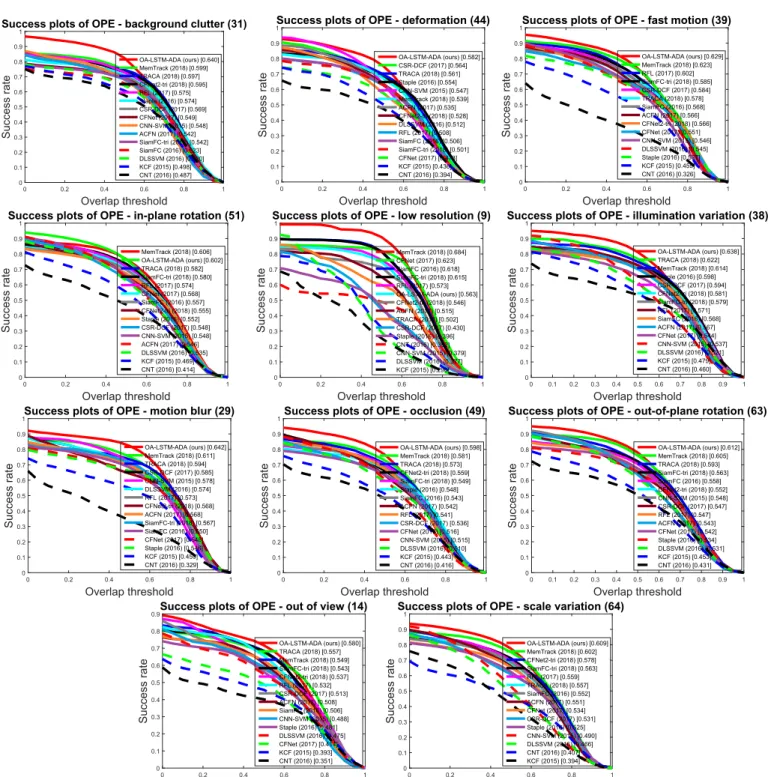
We can observe that our OA-LSTM-ADA performs favorably among the state-of-the-arttrackers on both benchmark versions. Compared with the four Siamese network based trackers, i.e., SiamFC, CFNet, SiamFC-triandCFNet2-tri, OA-LSTM-ADAachieves higher tracking accuracy. This fully validates the effectiveness of the proposednovel object-adaptiveLSTM network.OA-LSTM-ADA performsbetterthanMemTrackandRFLwithrespecttoboth pre-cision plotsandsuccessplots,whichdemonstratesthat ourLSTM network is successful in classifying proposals using its
memo-rizedtargetinformation,comparedwiththematching-based recur-renttrackers.OA-LSTM-ADAalsooutperformsotherdeeplearning basedtrackers,i.e.,TRACA,ACFN,CNN-SVM,DLSSVMandCNT.This isbecausethatOA-LSTM-ADAnotonlyusesdeepfeatures,butalso exploits thesequential dependenciesina video andcaptures the object appearance variationsvia the LSTM network. Other track-ersusinghand-craftedfeatures,i.e.,CSR-DCF,StapleandKCF,adopt thepopularcorrelationfiltertrackingframeworkandachieve state-of-the-art performance. However, these methods achieve worse trackingresults than ourOA-LSTM-ADA, dueto thelack of high-levelsemanticunderstandinginchallengingscenes.Notethat the results of some state-of-the-art methods are directly taken from [63](usingthesamehardwareplatform).
Table1compares theprecision scores, AUCscores andspeeds obtainedbyourOA-LSTM-ADAandotherstate-of-the-arttrackers. For the tracking speed, KCF is the fastest among the compared trackers,butitachievestheworsetrackingaccuracythanother re-centstate-of-the-arttrackers.SiamFC,CFNet,SiamFC-tri,CFNet2-tri andMemTrack achieve high speedsand competitive tracking ac-curacy owing to the efficiencyof the Siamese network. Butthey areworsethanourOA-LSTM-ADAforboth theprecisionandAUC scores. Our OA-LSTM-ADA performs better than high-speed KCF Please citethisarticleas:Y.Du,Y. YanandS.Chenetal.,Object-adaptiveLSTM networkforreal-timevisual trackingwithadversarial
Table1
The precision score, the AUC (Area Under the Curve) score and speed (fps, ∗indi- cates the GPU speed, otherwise the CPU speed) on the OTB-2015 dataset. The best and second best results are displayed in red and blue fonts, respectively.
Tracker Precision AUC Speed
OA-LSTM-ADA 87.2 62.8 32.5 ∗ MemTrack [50] 82.0 62.6 50.0 ∗ TRACA [57] 81.6 60.3 101.3∗ CNN-SVM [59] 81.4 55.4 1.0 ∗ CSR-DCF [61] 80.2 58.7 16.4 ACFN [58] 80.2 57.5 15.0 ∗ Staple [30] 78.4 58.1 50.8 SiamFC-tri [38] 78.1 59.0 86.3 ∗ CFNet2-tri [38] 78.0 59.2 55.3 ∗ RFL [30] 77.8 58.1 15.0 ∗ SiamFC [5] 77.1 58.2 86.0 ∗ DLSSVM [60] 76.3 53.9 4.4 ∗ CFNet [9] 74.8 56.8 75.0 ∗ KCF [29] 69.6 47.7 170.4 CNT [62] 57.2 45.2 1.5
and TRACA (with speeds beyond 100 fps) in tracking accuracy whilestillmaintainingareal-timespeed.Staple,CSR-DCFandCNT areable tooperate atsatisfactory speedson CPU.However, their trackingaccuraciesaremuchlowerthanourOA-LSTM-ADA.Other trackers,i.e.,CNN-SVM,ACFN,RFLandDLSSVM,areslowerandless accurate than our OA-LSTM-ADA. These results demonstrate that OA-LSTM-ADA achieves outstanding trade-off in terms of state-of-the-artaccuracyandreal-time speed amongallthe competing trackers.
5.2.4. Attribute-basedcomparison
Fig. 9 compares the performance obtained by our OA-LSTM-ADAandotherstate-of-the-arttrackersusingsuccessplotsonthe OTB-2015datasetforelevenchallengingattributesincluding back-groundclutter,deformation,fastmotion,in-planerotation,low res-olution,illuminationvariation,motionblur,occlusion,out-of-plane rotation,outofviewandscalevariation.
Our OA-LSTM-ADAperforms favorablyagainst other compared state-of-the-arttrackers in most cases, which indicates that OA-LSTM-ADA possesses high robustness while operating in real-time. Compared with the representative Siamese network based tracker, i.e., SiamFC, our OA-LSTM-ADA achieves significant per-formanceimprovementsunderalltheelevenchallenge attributes. This clearly proves that the proposed object-adaptive LSTM net-work is able to effectively utilize the sequential dependencies among successive frames and learn the object appearance vari-ations with high online adaptability. OA-LSTM-ADA outperforms the recurrent trackers, i.e., MemTrack and RFL, under most at-tributes,whichdemonstratestherobustnessofourLSTMnetwork for classification, compared with the LSTM networks for object templatemanagement usedinMemTrack andRFL.OA-LSTM-ADA obtains much better performance than other compared trackers inthepresenceoffast motion,occlusion andoutofview.This is becausethatOA-LSTM-ADAcanmemorizetheprevious object ap-pearanceandignorethedistractingsimilar objectsviathe object-adaptiveLSTMnetwork.Fortheattributesofin-plainrotationand lowresolution,OA-LSTM-ADAperformsworsethanMemTrack.The reasonmaybethattheobjecttemplateusedforsimilarity comput-inglacks effectiveupdating andthus deviatesfrom thetemporal objectundersuchdisturbancesatthelaterstageoftracking.Even so,OA-LSTM-ADA obtains a higher tracking accuracy than Mem-Trackonthewholedataset.
5.2.5. Qualitativecomparison
Fig.10qualitativelycomparestheperformance obtainedbyour OA-LSTM-ADA,ACFN,Staple,CFNetandSiamFConfivechallenging sequences.
Table2
The precision score, the AUC (Area Under the Curve) score and speed (fps, ∗indi- cates GPU speed, otherwise CPU speed) on the TC-128 dataset. The best and second best results are displayed in red and blue fonts, respectively.
Tracker Precision AUC Speed
OA-LSTM-ADA 72.18 50.16 32.5 ∗ CF2 [64] 70.30 48.40 10.8 HDT [65] 68.56 48.04 9.7 Staple [30] 66.46 49.76 50.8 MEEM [66] 63.92 45.86 11.1 MUSTer [67] 63.57 47.13 4.0 Struck [68] 61.22 44.11 17.8 KCF [29] 54.86 38.39 170.4 DSST [28] 53.99 40.65 12.5 CSK [69] 41.71 30.73 269.0
Forthemostchallengingsequences,mosttrackersfailtolocate the target position orincorrectly estimate the target scale, while our OA-LSTM-ADA accurately tracks the object in terms of both positionandscale.ForthesequenceofCarScale(row1),the com-paredtrackersareable tocorrectlylocatethetargetposition,but they only discriminate a part of the objectinstead of the whole objectwhentheobjectundergoeslargescalevariation.Inspiteof the challenging scale variation, our OA-LSTM-ADA correctly esti-matesboththepositionandscaleoftheobject.Forthesequences ofIronmanandMatrix(rows2and3),themostcomparedtrackers driftawaybecauseofthesignificantilluminationvariationand oc-clusion. Incontrast, ourOA-LSTM-ADAsuccessfully handlesthese challenges and accurately tracks the object despite the complex backgrounds. In the sequences of MotorRolling and Skiing (rows 4and5), the comparedtrackers strugglewhenencountering fast motionandsignificantrotation,whileourOA-LSTM-ADAkeeps ro-busttrackingoftheobjectthroughoutthesequence.
5.3. EvaluationonTC-128
5.3.1. Datasetandevaluationmetrics
The TC-128 [15] dataset contains 128 fully annotated color videosequenceswithmanychallengingfactors.Similartothe eval-uationonOTB(Section5.2.1),we alsousetheperformance evalu-ation method of OPE andmetrics of precision plots and success plotsfortheevaluationonTC-128.
5.3.2. Quantitativecomparison
We quantitatively compare our OA-LSTM-ADA with several state-of-the-arttrackersincludingCF2[64],HDT[65],Staple[30], MEEM[66],MUSTer[67],Struck[68],KCF[29],DSST[28]andCSK [69].Fig. 11shows the comparative resultsin terms of precision plotsandsuccessplotsontheTC-128[15]dataset.
Wecan observethatour OA-LSTM-ADAachievesthebest per-formance in both precision plots and success plots among all the comparedtrackers. OA-LSTM-ADAoutperforms theother two trackerswhichalsousedeepfeatures, i.e.,CF2andHDT,with rel-ative improvements of 1.88% (1.76%) and 3.62% (2.12%), respec-tively. Compared with the trackers based on the hand-crafted features, such as Staple and MEEM, our OA-LSTM-ADA achieves higher tracking accuracy and obtains a real-time speed on the GPU.
Table 2 presents the precision scores, AUC scores andspeeds obtainedby ourOA-LSTM-ADA and other compared state-of-the-arttrackers.
As shown in Table 2, our OA-LSTM-ADA performs favorably against other state-of-the-art trackers in terms of both preci-sion scores andAUC scores whilemaintaining a real-time speed. Compared withfast correlation filterbased trackers such asKCF [29] andStaple[70],whichcanoperateathighspeedsonaCPU,
Fig.9. The success plots on the OTB-2015 dataset for eleven challenging attributes: background clutter, deformation, fast motion, in-plane rotation, low resolution, illumina- tion variation, motion blur, occlusion, out-of-plane rotation, out of view and scale variation.
our OA-LSTM-ADA achievesnoticeably accuracy improvements in both precision scores andAUC scores. Comparedwith the corre-lation filter based trackers using deep features, such asCF2 and HDT, our OA-LSTM-ADA showsthe performance superiority. This indicates thattheproposedobject-adaptiveLSTMnetworkcan ef-fectively adapt to the temporarily changing object and is well suited forthe visual tracking task.In addition,the proposed fast proposal selection strategy provides highefficiency for our deep model, which allows our tracker to be performed at real-time speed.MEEMexploitsamulti-expertrestorationschemetohandle thedriftproblemduringonlinetracking.MUSTeradoptscognitive
psychologyprinciplesto designan adaptiverepresentationfor vi-sualtracking.AlthoughthesetrackerscanbeperformedonaCPU, therestillexistsagapbetweentheirtrackingaccuracyandthatof ourOA-LSTM-ADA.
5.4.EvaluationonUAV-123
5.4.1. Datasetandevaluationmetrics
The UAV-123 [16] dataset consists of 123 fully annotated video sequences captured from a low-altitude aerial perspective for UAV target tracking. Similar to the evaluations on OTB in Please citethisarticleas:Y.Du,Y. YanandS.Chenetal.,Object-adaptiveLSTM networkforreal-timevisual trackingwithadversarial
Fig.10. Qualitative results of our OA-LSTM-ADA, ACFN [58], Staple [30], CFNet [9]and SiamFC [5]on five challenging sequences (from top to down: CarScale,Ironman,Matrix, MotorRolling and Skiing, respectively).
Fig.11. Precision plots and success plots showing the performance of our OA-LSTM-ADA compared with other state-of-the-art trackers on the TC-128 dataset.
Section5.2andTC-128inSection5.3,weusetheOPEperformance evaluationmethodandmetricsofprecisionplotsandsuccessplots toconducttheexperimentsonUAV-123.
5.4.2. Quantitativecomparison
Fig. 12 shows the quantitative comparison of our OA-LSTM-ADA andseveralstate-of-the-arttrackersthat havepublicly avail-ableresultson theUAV-123 dataset,includingSRDCF[70],CFNet [9],SiamFC [5],Staple[30],MEEM[66],SAMF [71],MUSTER[67], DSST [28] and KCF [29]. In terms of both precision and success plots,ourOA-LSTM-ADAoutperformsalltheothertrackerswitha real-timespeed.ComparedwiththeSiamesenetworkbased track-ers, i.e.,SiamFC [5] andCFNet [9], ourOA-LSTM-ADA achievesa higher tracking accuracy owing to the effectiveness of the pro-posedobject-adaptiveLSTMnetworkanddataaugmentation tech-nique. Compared with the hand-crafted feature based trackers, such as SRDCF [70] and Staple [30], our OA-LSTM-ADA, which uses deep features andadopts an efficient object-adaptive LSTM networkwithfastproposalselection,achievesbetterperformance whilemaintainingareal-timespeed.
5.5. EvaluationonVOT-2017
5.5.1. Datasetandevaluationmetrics
TheVOT-2017[17]datasetcontains60fullyannotatedvideo se-quences.Theperformance evaluationmetricistheExpected Aver-age Overlap (EAO) score, which takesboth accuracy and robust-ness into account. The speed is reportedin terms ofEFO, which normalizesspeedmeasurementsobtainedoverdifferenthardware platforms. VOT-2017introduces a newreal-timechallenge, where trackers are requiredto deal with the video frames at real-time speeds. Weevaluate theproposed method ontheVOT-2017 real-timechallenge.
5.5.2. Quantitativecomparison
WecompareourOA-LSTM-ADAwiththetop9trackersonthe VOT-2017 real-time challenge, including CSR-DCF-plus [61], CSR-DCF-f[61],SiamFC [5],ECOhc[72],Staple[30],KFebT[73], ASMS [74], SSKCF and UCT [76]. Fig. 13 presents the Expected Aver-age Overlap (EAO) ranking on the VOT-2017 real-time challenge. Table 3 illustrates specific EAO scores andspeeds (in EFO units)