An Open Source Software Development Model
Anonymous ICOST-2006 submission
Paper ID ______
Abstract
Various misconceptions surround the open source phenomenon today. People still think that open source software is developed by a bunch of geeks, hacking away in their chat rooms at obscure hours in the night to develop a remarkably sound product that ‘works’ and which no one understands how came into being. This is the mystery of open source this paper yearns to unravel. Like so many debates in their infancy, the phenomenon of Open Source Software Development (OSSD) has been the subject of significant controversy and discussion amongst the researchers for quite some time now. Some declare it as a radically new phenomenon and process to solve many of the software industry’s problems. Others declare that OSS is not a method itself [1, 2]. So this raises an important question; ‘Is the vastly popular phenomenon of OSSD really, well understood?’ We believe that it’s not possible to answer this question unless we try, not only to capture the open source practices in prose but also to consolidate these in the form of concrete models or frameworks so as to explain the phenomenon more comprehensively and put things into perspective. Further, it’s imperative to do so in the wake of new agile methodologies because we need a comparison of the models to understand how OSSD ‘fits in’ and whether it’s really a new methodology. This paper is an attempt to bridge this gap and presents a graphical model for open source software development. Our approach was to conduct an extensive literature review on the current practices (and proposed models) of OSSD and then try to capture the information in the form of a high level framework, using a process modeling technique, to derive an all encompassing model.
1.
Introduction
Over the years we have seen manufacturing and service industries respond, to the changing customer values and thrive in the global markets by devising customer focused strategies. The same forces can now be seen driving the software development arena towards an emergence of new development methodologies that focus on responding to change and customer feedback throughout the software’s lifespan. Open source software development is one such methodology of modern times with an additional nifty feature. That is, the people for whom the software is developed, the end users, have been empowered to
participate in the development process itself. This phenomenon is not new, it has been adapted to a lesser degree by innovation leaders like Microsoft in the form of end user beta testing. But never before its impact and significance been more pronounced than in open source software development where the end users are producers of the software themselves. They own it. Thus, it might not come as a surprise that open source advocates consider it a new silver bullet capable of solving many practical issues of the software industry [3, 4, 5]. However, its opponents consider this too good to be true and declare it as an ad hoc, chaotic piece of engineering [2, 6]. But to analyze or critique a phenomenon one must understand its dynamics first; and a visual model is probably the best scheme to start with. To date, no globally accepted framework or model exists to define how open source software is developed. Thus, an effort needs to be expended in this regard as to find out how, various open source communities develop their software. This information than must be consolidated in the form of a framework or simplistic model that explains the phenomenon in an easy to understand manner for the masses to comprehend, benefit from, critique and improve. Thanks to the work of researchers as Walt Scacchi, efforts have been done in capturing the practices and processes of some open source communities in recent years. They have tried to identify how communities have learned to use the information highway, communication infrastructure, latest tools and global brains to collaborate and develop remarkably stable software products. But the consolidation part is still missing. Thus, in this paper we have attempted to establish a framework for capturing open source software development processes and, using this information, come up with a model to understand the dynamics at a glance. It must be recognized that open source communities have matured their processes over the years and while this evolution is important in itself, it’s not relevant for the context of this paper. We have tried to focus on the phenomenon in its current form and existing practices. It is also important to mention here that useful studies explaining the practices of open source communities are not abundant. One reason perhaps is that open source communities present a working model of global virtual teams and this aspect has a greater appeal for the people with non Computer Science (CS) background. Thus, we have seen a staggering amount of literature focusing on the economic, social, cultural, organizational and engineering aspects of the phenomenon. But, detailed discourses on the development
process itself have not received the attention they deserved, until perhaps more recently.
2.
Related Work
Open source software has been seen by many as a paradigm shift that can help solve the ‘software crises’ (i.e. systems taking too long to develop, costing too much, and not working very well when eventually delivered). The truly amazing aspect of open source software is that it arises from a process which, at first glance, seems to be completely alien to the fundamental tenets and conventional wisdom of software engineering [2]. For example, there is no real formal design process, there is no risk assessment nor measurable goals, no direct monitory incentives for the developers or organizations, informal coordination and control, much duplication in parallel effort etc. Also, open source software appears to reverse Brooks’ Law and has its own law as coined by Raymond i.e. “given enough eyeballs, every bug is shallow” [4]. There are claims that open source methodology produces exceptionally high quality and reliable software in a very rapid timescale and for free [7].
Researchers have written extensively on the topic and discussions can be found on various facets of the subject. But open source, in its current shape and form, is a relatively recent phenomenon and literature in this domain is gradually maturing with time. Thus, as already highlighted above, in-depth case studies concentrating on the open source development process itself have emerged more recently. In this regard the work of Scacchi is commendable. In [8] he observes that previous studies provide “informal narrative descriptions of the overall software development process” and “do not treat these processes in terms that associate tools or the roles that people play in performing different development tasks”. Further, no visual flow or a formal computational model of these processes is available and the narrative descriptions of these processes can not be easily analyzed, compared, visualized, computationally enacted, or transferred for (re)use in other projects. To bridge this gap Scacchi has made use of ‘rich pictures’ (or Rich Hypermedia Model) in his research, to capture the practices of different open source communities, and Protégé open source tool to create their knowledge base models and ontologies [8, 9, 10]. Textual descriptions or simple illustrative models of how open source software is developed by various communities and their software engineering practices can be found in case studies such as [11, 12, 13, 14]. From a software engineering perspective, Scacchi highlights that open source software development communities do not seem to adhere to the modern software engineering processes and that there are at least five types of development processes employed by such communities. That is; requirements analysis and specification; coordinated version control, system build
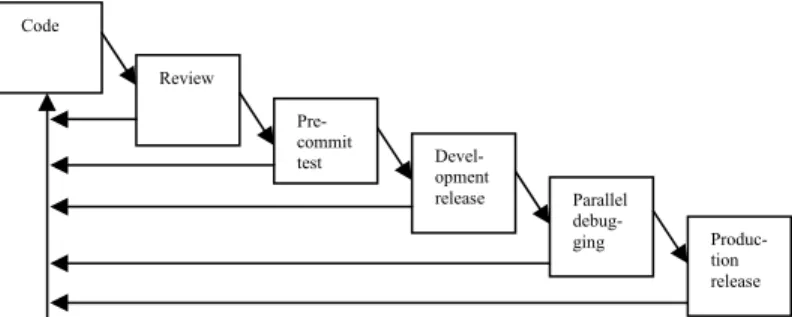
and staged incremental release review; maintenance as evolutionary redevelopment, reinvention and revitalization; project management and career development; software technology transfer and licensing [15]. Sharma and Sugumaran have identified some phases typically observed in open source software development. These include; problem discovery, finding volunteers, solution identification, code development and testing, code change review, code commit and documentation, and release management [16]. Another effort in this regards can be found in Jorgenson work [14], who proposes the following life cycle for the development of individual changes in the FreeBSD open source project;
Figure 1: The life cycle for changes. In general each stage is mandatory. Exceptions include skipping review of a trivial bug fix and, development release and parallel debugging of a bug fix urgently needed for production release.
Potdar and Chang have tried to capture and explain the dynamics of open source software development in the form of a model where, they contrast its dynamics with the motion of a pendulum [17]. They observe that open source software development is similar to its traditional counterparts (closed source models) in many aspects, but there are many areas where it differs. Some of these differences are highlighted along with the need to add and remove certain phases in the waterfall model to make it applicable to open source software development.
One of the challenges in capturing OSSD process is that, its dynamics are rich in substance and are as much about the community and people involved in the process, as they are about the software itself. So, one needs to understand the structure of an open source community to establish a sound comprehension of its approach/methods. Thus, it is not unusual to see case studies covering the community structure before jumping into the actual processes [10, 18]. A number of papers present a generic structure of the open source software development community and the division of responsibilities amongst the members [19, 20]. These classifications identify roles such as the users, developers, contributors, module owners and release manager etc. The vital importance and need of a technological infrastructure to support the activities of such a geographically dispersed team can also be found in literature [11, 18]. Such an infrastructure includes central
Code Review Pre-commit test Devel-opment release Parallel debug-ging Produc-tion release
code and bug/issue repositories, mechanisms for information dispersion and release of product artifacts (web sites, portals) and tools for effective communication (discussion groups, mailing lists, chat facilities etc). A discussion on the dynamics behind the two types of open source communities (i.e. the community founded and sponsored), is provided by West and O’Mahony in [21].
3.
Towards a Framework for Capturing
OSSD Processes
Software development life cycle models present a clear and conclusive picture of how a particular paradigm works and what are the major steps involved in the overall process. These models serve as a vocabulary and provide guidelines or practices for the software industry at large to tailor and adapt for their own development activities. Further these models establish a foundation for healthy discussions and comparisons of the methodologies thus enabling the progression of knowledge for the benefit of research communities and the industry. Therefore, it is not a small event that so far, efforts expended in capturing open source software development practices fall short of presenting a clear and conclusive picture of the model. There may be various reasons for this shortfall. For example some researchers, in the recent past, even declared open source phenomenon as having a limited impact and pointed out the extent to which this apparently new phenomenon draws on the traditional approaches of academic study and interactive development [6, 7]. Further, capturing the development practices of a geographically dispersed team that makes effective use of technology to produce software is perhaps not easy as it sounds and involves capturing the people, process and technology triad in an illustrative, yet easy to understand manner. Open source communities differ in their practices and have varying organizational and cultural philosophies. To exemplify the importance of these facts, various differences can be cited; open source communities differ in their social structure/setup i.e. how people interact and the amount of authority given to various roles/individuals in the community; open source communities differ in their processes such as coding standards and practices, testing approaches, code submission and check in procedures (i.e. who does it and how is he promoted to this level, whether the code is submitted on the mailing list or in the repository). Another characteristic where open source communities vary in their approach is the role of the core and peripheral community [20].
The flipside is that there are ‘shared’ practices followed by more or less all open source communities (the practices that pop up in ones mind when the word open source software development is uttered). For example, distributed development, code reviews, user acceptance testing and feedback by the community; release
management, bug repositories and use of mailing lists for communication etc. These practices of course are necessitated by the structure of the community itself. So it is imperative not only to understand the differences but also to grasp the commonalities which can then be consolidated in the form of a model. Further, an approach is required that can portray the dynamics of the process and its flow along with the involvement of various stakeholders in performing the activities, the transfer of control from one to the other and the use of technology, under one roof. This approach is precisely what Quality Engineers in software process definition groups have been striving to achieve/fulfill since the birth of process improvement frameworks such as ISO and CMMI. SEPG groups make use of a number of mechanisms for capturing the organizational processes ranging from textual narrations of the process, to the use of more formal process modeling techniques such as IDEF, Swimlane diagrams etc [22]. These techniques were devised for the very purpose of visually charting the workflows or processes within an organization. Thus, we believe that this approach can play a vital role in documenting and understanding the practices of open source communities in a consistent manner. Once an understanding is established, deriving a representation for comprehending the ‘open source software development model’ is naturally the next logical step.
We have applied this framework to study and capture the common practices, as found in the literature, followed by some of the successful open source communities (such as Linux, Apache, Mozilla, FreeBSD, NetBeans, Jakarta etc). Owing to the space limitations, it is not possible to include the detailed framework in this paper thus; in the following section we will simply present the outcome and findings of our study i.e. a model to depict open source software development.
4.
An Open Source Software Development
Model
It’s a common belief that open source software development is a hacker style chaotic activity. On the contrary, recent studies suggest that there is some sort of planning activity and thought process that works behind every new release or iteration of the software. The detail and rigor of this initial planning varies from community to community. But in general, it’s a much lighter activity than traditional planning practices and involves the identification of a feature set for the current release, the modules that will be modified or built and identification and assignment of responsibilities to the community members [18]. It includes the selection of a release manager, who coordinates and overlooks the development efforts on the project with the end-goal of releasing a product in line with the project’s vision and roadmap.
Release manager ultimately decides what goes in and what goes out of the final release. The release manager, in co-ordination with the community at large, also establishes a team of trusted lieutenants for overlooking the major modules of the code base [23]. All this information (roles, responsibilities), along with the tentative milestone dates might be captured in the form of a ‘release plan’ which is available to the community for discussion and feedback [10]. Thus, open source team is not as chaotic in its approach as is the common belief.
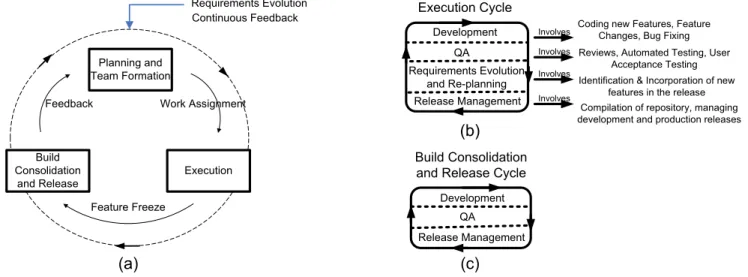
Developing open source software usually occurs as an ongoing, iterative activity, with rapid software release cycles for use and feedback by the community. The development process itself is a highly parallel activity in nature where coding, reviews and/or testing, identification and incorporation of new features in the ongoing release, and release management all occur in parallel. This is made possible by the sheer size of the community. So, while a developer is working on a new feature, some other community member (such as a committer or contributor) may be reviewing a patch submitted by another developer and yet a third may be engaged in testing the latest release of the product or documenting/registering a new bug. Thus after the initial planning and team formation stage typically, open source software development projects enter an execution phase where development, bug fixing and testing occur simultaneously on ongoing basis. The execution phase is primarily driven by the continuous feedback provided by the community at various levels. This process continues till the release manager decides its time to stop incorporating new features in the release (in accordance with the established release schedule) and summon is issued/declared about the code or feature freeze date [24, 25]. The feature freeze simply announces that it is time to stabilize the current code base for an official release to the public. From here onwards, new features are not incorporated in the ongoing release and all attention is focused to get the outstanding features completed; work in progress is gathered and incorporated in the code repository; thorough testing is done to ensure the stability of the code base and finally a production release is made available on the community’s web site and announced at large. This phase is tagged as ‘build consolidation and release’ and the entire process is depicted in the model given in Figure 2. Notice that (part ‘a’ in figure) the requirements evolution (requirements gathering and elicitation) and community feedback cycle is a continuous activity at all stages. It is even executing at the build consolidation phase but new features identified at this phase are not incorporated in the current release and are left for the next one. In OSSD projects requirements elicitation and evolution takes place on the community mailing lists. The execution phase consists of the following broad categories of activities:
Development: The development cycle may be considered as a grouping of processes that are primarily focused on the code. These include the coding of new features identified for the release, completion of previously unfinished features, incorporating changes in the code as they arise and bug fixing.
Quality Assurance: The QA can again be considered a grouping of activities focused on identification of problems in the code and improving its overall quality. These activities mainly include automated testing cycles, reviews and user acceptance (or manual feature) testing performed by the community at large. In addition, the QA team reports, categorizes and prioritizes bugs, manages the set of automated testing scripts and testing software that the builds are run against, and also documents/compiles their results. QA team also establishes criteria for stabilization of modules and project builds.
Release Management: The release management sub-process is mainly concerned with creating separate branches in the CMS (configuration management system/tool) for each module, granting access rights and privileges on it, maintaining the various versions of the code and monitoring all this activity on ongoing basis. The objective is to maintain a ‘relatively’ stable, working copy of the code ready for release at all times. For this purpose the source code repository is compiled on regular basis and at a certain point (or defined frequency), is released to the community as a ‘development release’. Once the feature freeze date is decided and subsequently the build stabilized, it is released to the public as a ‘production release’ along with all the necessary help and documentation.
Requirements evolution and re-planning/monitoring: The requirements evolution and re-planning process includes the identification of new features plus changes to existing ones, for the development cycle of the current release. Since this activity inherently involves additional effort, there is a constant need to monitor the activities. This relies on virtual project management [15] (a job executed by the core team members).
As can be seen by the very nature of these activities most of these are umbrella activities to coding and they are usually conducted in parallel. Thus many features are being worked on in parallel and they are constantly tested, incorporated in the code repository, their configuration is managed, repository is periodically stabilized and released to the community in the form of development releases and evolution of features plus re-planning for the release continues in parallel. This entire cycle goes on till the
Planning and Team Formation Execution Build Consolidation and Release Work Assignment Feature Freeze Feedback Requirements Evolution Continuous Feedback (a) (c) Build Consolidation and Release Cycle
Involves Coding new Features, Feature Changes, Bug Fixing
Involves Reviews, Automated Testing, User
Acceptance Testing
Involves
Identification & Incorporation of new features in the release
Involves
Compilation of repository, managing development and production releases
(b) Execution Cycle Development QA Requirements Evolution and Re-planning Release Management Release Management Development QA
Figure 2: An Open Source Software Development Model depicting the life cycle of a single release. (a) After the initial ‘planning and team formation’ phase, the project enters a highly parallel and iterative ‘Execution’ phase where work on various activities executes in parallel on different features. Once the feature freeze date is decided, the release enters its final stage/phase where code base is stabilized and no new features are allowed. The outer (dashed line) circle depicts that requirements gathering and feedback are continuous ongoing activities (b) The activities in the Execution phase. All activities execute in parallel and iteratively on ongoing basis (c) The activities involved in the build consolidation phase. The only difference here, from part b, is the absence of requirements evolution activity since no new features are allowed at this stage.
feature freeze date and from there onwards, the execution enters the Build consolidation and release phase till the code base is stable and released to the public. The process then starts over again for the next release
5.
Conclusion
We have presented a model for open source software development in this paper which builds on empirical case studies found in the literature so far. The model depicts OSSD dynamics in a simple, easy to understand manner to enable comprehension of the overall development process. Our model suggests that open source software development is not a random, chaotic approach but rather it’s a more disciplined phenomenon. However, the degree of this discipline may vary amongst the communities (with sponsored communities being at the top). Further we stated that open source development is a myriad of software engineering practices and it’s not possible to visualize the concept with out taking into consideration the community or people performing those tasks. A framework for capturing the open source development processes has also been suggested. We are hopeful that this approach will lead to an enhanced comprehension of the topic and will open new avenues for further research and a healthy debate.
6.
References
[1] Alfonso Fuggetta. “Open Source and Free Software: A New Model for the Software Development Process?”.
The European Journal for the Informatics Professional, Oct 2004.
[2] Joseph Feller and Brian Fitzgerald. “Open Source Software: Investigating the Software Engineering,
Psychosocial and Economic Issues”. Information
Systems Journal, Blackwell Publishing, Oxford, 2002. [3] Joseph Feller and Brian Fitzgerald. “A framework
analysis of the open source software development
paradigm”. Proceedings of the 21st International
Conference on Information systems, ACM Press, 2000. [4] Eric S. Raymond. “The Cathedral & the Bazaar”.
O'Reilly Publishers, 1999.
[5] Tim O’ Reilly. “Lessons from Open Source Software
Development”. ACM Communications, 1999.
[6] Alfonso Fuggetta. “Open source software an
evaluation”. The Journal of Systems and Software,
Elsevier Science Inc, 2003.
[7] Brian Fitzgerald and Par J. Agerfalk. “The Mysteries of Open Source Software: Black and White and Red All
Over”. Proceedings of the 38th Annual Hawaii
International Conference on System Sciences (HICSS'05), ACM Press, 2005.
[8] Walt Scacchi. "Issues and Experiences in Modeling Open Source Software Development Processes". 3rd Workshop on Open Source Software Engineering,
[9] Walt Scacchi. “Opportunities and Challenges for Modeling and Simulating Free/Open Source Software Processes”. Institute for Software Research, University of California Irvine, Sep 2004.
[10] Walt Scacchi, Chris Jensen, Maulik Oza, Eugen Nistor and Susan Hu. “A First Look at the NetBeans
Requirements and Release Process”. Institute for
Software Research, University of California - Irvine,
Feb 2004.
[11] Christian Reis and Renata Fortes. “An Overview of the Software Engineering Process and Tools in the
Mozilla Project”. Proceedings of the Workshop on
Open Source Software Development, Newcastle UK, Feb 2002.
[12] Andris Mockus, Roy T Fielding and James D Herbsleb. “Two Case Studies of Open Source Software Development: Apache and Mozilla”. 2002.
[13] Alessandro Narduzzo and Alessandro Rossi, “Modularity in Action: GNU/Linux and Free/Open Source Software Development Model Unleashed”. University of Trento, May 2003.
[14] Niels Jørgensen. “Putting it all in the Trunk, Incremental Software Development in the FreeBSD Open Source Project”. Information Systems Journal, Oct 2001.
[15] Walt Scacchi. “Free and Open Source Development
Practices in the Game Community”. IEEE Software,
Jan/Feb 2004.
[16] Srinarayan Sharma, Vijayan Sugumaran and Balaji Rajagopalan. “A Framework for Creating Hybrid Open
Source Software Communities”. Information Systems
Journal, 2002.
[17] Vidyasagar Potdar, Elizabeth Chang and L. Brankovic. “Pendulum Model for Open Source Software Development”. Proceedings of the 7th World Multi-Conference on Systemics, Cybernetics and Informatics (SCI2003), Orlando, Jul 2003.
[18] Chad Ata, Veronica Gasca, John Georgas, Kelvin Lam and Michele Rousseau. “Open Source Software Development Processes in the Apache Software Foundation”. Dec 2002.
[19] Cristina Gacek and Badi Arief. “The Many Meanings of Open Source”. IEEE Software, Jan/Feb 2004. [20] Kevin Crowston, Hala Annabi, James Howison and
Chengetai Masango. “Effective work practices for FLOSS development: A model and propositions”.
Proceedings of the 38th Hawaii International Conference on System Sciences (HICSS'05), ACM Press, 2005.
[21] Joel West and Siobhán O’Mahony. "Contrasting Community Building in Sponsored and Community
Founded Open Source Projects”. Proceedings of the
38th Annual Hawaii International Conference on System Sciences, Jan 2005.
[22] Alec Sharp and Patrick McDermott. “Workflow Modeling: Tools for Process Improvement and Application Development”. Artech House Publishing, Boston, 2001.
[23] Federico Iannacci. “Coordination Processes in Open Source Software Development: The Linux Case Study”. Department of Information Systems, LSE London, Apr 2005.
[24] Audris Mockus, Roy Fielding and James Herbsleb. “A Case Study of Open Source Software Development:
The Apache Server”. Proceedings of the 22nd
International Conference on Software Engineering (ICSE), 2000.
[25] Federico Iannacci. “The Linux Managing Model”.
First Monday: peer reviewed journal on the internet, 2003 (http://www.firstmonday.org/issues/issue812/Ian- nacci/index.html).