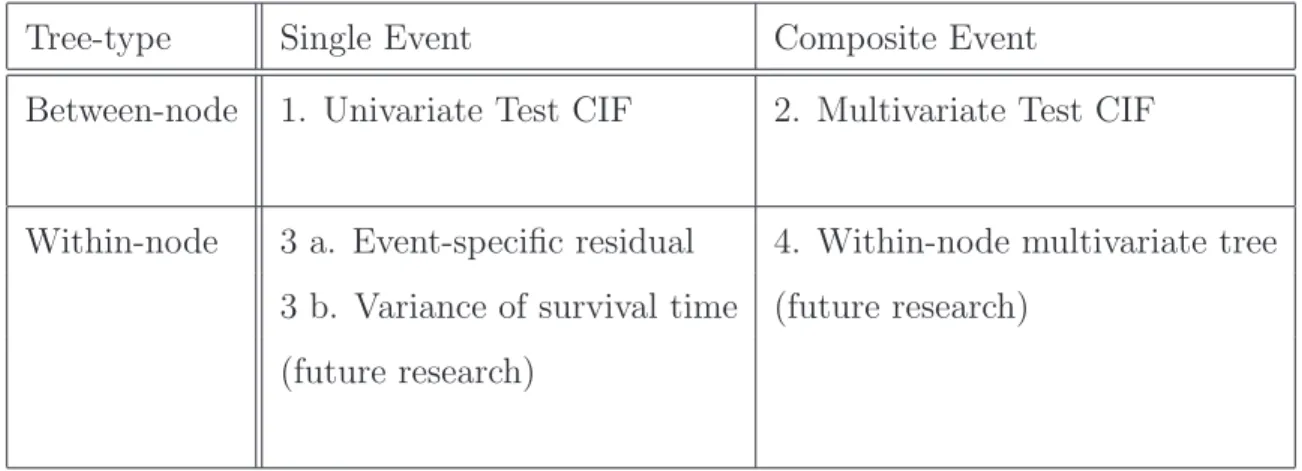
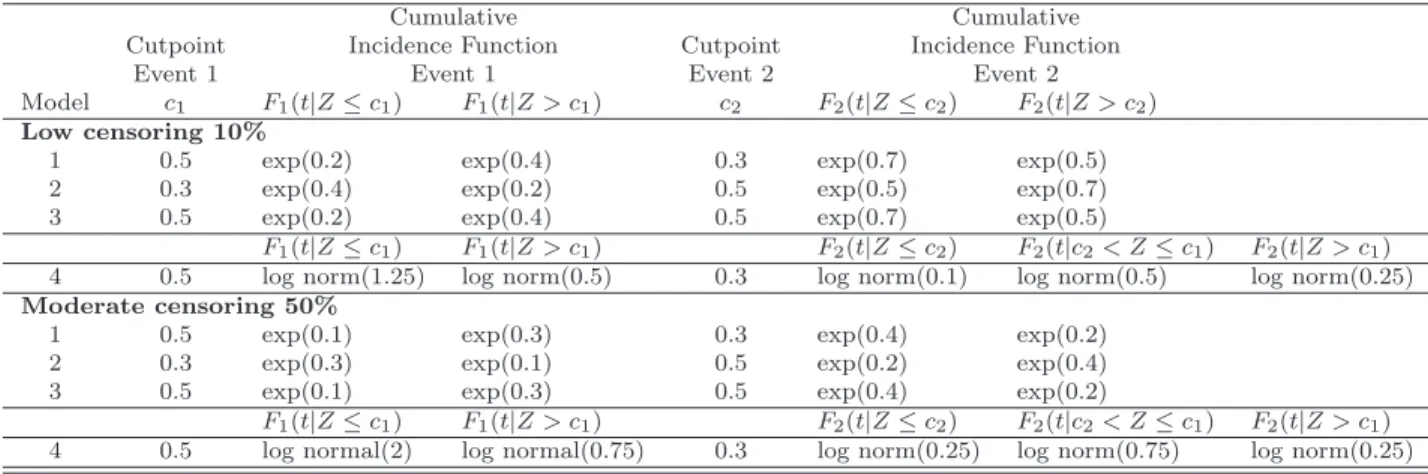
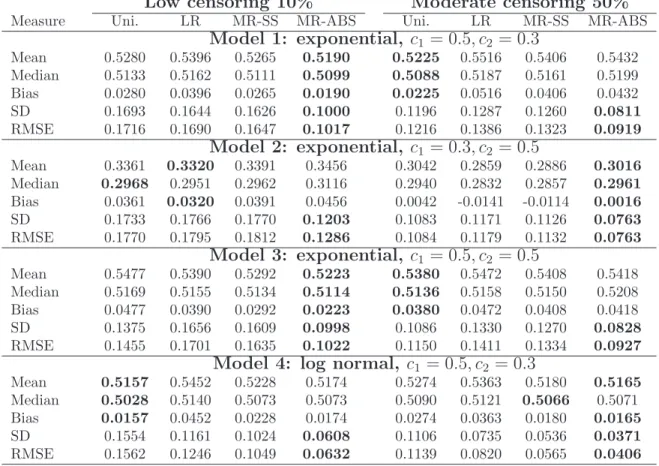
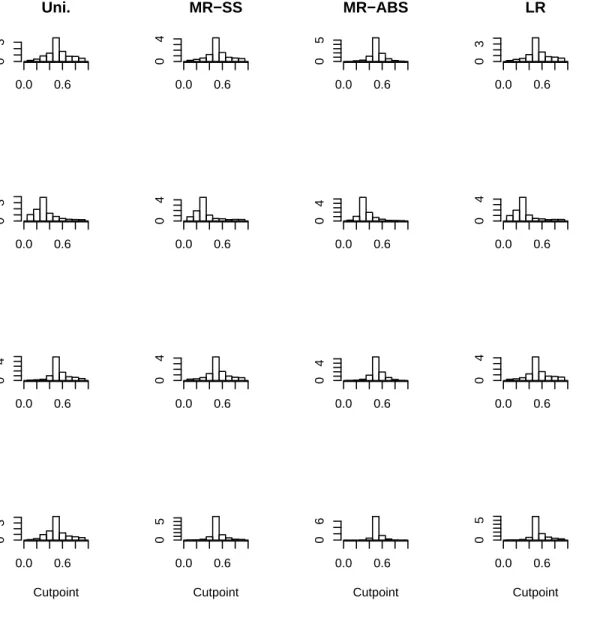
Classification Trees for Survival Data with Competing Risks
Full text
Figure

Related documents
Fur- ther, almost equal amounts of virus lineage migration out of North (19.84%) or South (24.58%) China seed the RABV epidemic in Yunnan, and little more than 1% of all
Although electrochemical cell-based chips showed superior performance for can- cer diagnosis and for the assessment of cell viability, they did not allow us to study the
To monitor and enhance the learning performance of learning groups in a web learning system, teachers need to know the learning status of the group and determine the key
We design feeder transit services in El Cenizo by utilizing the analytical and simulation approaches described in Chapters III and IV to determine the optimal number of service
(adaptive, extrapolative, regressive, and interactive; see Appendix 1 for variable definitions); then estimate using OLS A. Optimal lag specification or single regressor)
Keywords: Fuzzy sets, Fuzzy Logic, Neural Networks, Genetic Algorithms, Data
Aim of the study is to find out the proportion of children with cerebral palsy in the age group of 3‑12 years who have enrolled for some kind of formal education and to study
Table 7 gives the account of final normalized pressure and temperature of compressed air, and change in the polytropic index without and with spheres at various stroke
