International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 09, September 2015Available at http://internationaljournalofresearch.org
Update Annotation of document Data alignment
Annotation Information Extraction
Kashapoogu Sharon Rose
1& Dr. Shaik Abdul Muzeer
21M-Tech Dept. of CSE Megha Institute of Engineering & Technology for Women 2Professor & principal Dept. of CSE Megha Institute of Engineering & Technology for Women
Abstract—
An increasing number of documents have ended up web open through structured database interface providing form-based search for the end user. This collection of Multimedia (Text, Images, Audio & Video data) is to be organized in a structured information, extraction of structured relation are often expensive and length process. The structured information does not provide aligned information Natural language policy documents are frequently used as starting point for requirements capture, leading to computer systems that manage process management within organizations. Rather than modeling explicit workflow graphs of business processes, this paper proposes presentation of annotated versions of the natural language policy documents as a user interface indicating both the status of task progress and appropriate potential progress routes. A deontic adaptation of the Event Calculus is presented to monitor the normative state of policy compliance. A non-tree-based document annotation scheme is used to allow a natural language text to be linked with a logic program developed to represent its intentions. The approach is demonstrated by the encoding and presentation through a web application of a section of the United States Food and Drugs Administration regulations. The proposed adaptive technique is relevant attributes to annotate a record, while attempt to fulfill the user questioning needs. Our answer is focused around a new novel system that considers the proof in the document query workload. Questioning value; a model that considers both parts restrictively free and a straight weighted model. Search Data in Unstructured Information and make the search cost less.
Keywords- annotation of document; Data alignment; Annotation; Information Extraction
1. INTRODUCTION
Current information sharing tools, like content
management software (e.g., Microsoft
SharePoint), allow users to share documents and annotate (tag) them in an ad-hoc way. Similarly, Google [1] allows users to define attributes for their objects or choose from predefined templates. This annotation process can facilitate subsequent information discovery. Many annotation systems allow only ―un-typed‖ keyword annotation: for instance, a user may annotate a weather report using a tag such as ―Storm Category 3‖. Enhancing the search results in large archives is a concern shared by Collection of huge and textual
data[9]. The search content improvement can come from two directions of method: Filename based search or Content based search. Both search content directions are active research areas. In this filename based search system are search the data within the filename itself and it produces very low accurate results. And second one is content based search the data within the file contents instead of filename.
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 09, September 2015Available at http://internationaljournalofresearch.org
constraints on the operations of an organization are likely to be described using natural language. For example, contracts, internal process documentation, and the paperwork required to demonstrate compliance to regulatory bodies such as taxation offices and company registries. Ideally, the business processes are converted into software with high fidelity. In practice, end user systems may impose significant limitations to the freedom of staff in an organization in the interest of ensuring compliance to stated requirements. In other words, the workflow encoded is derived from a comparatively ideal-case scenario, and exceptions are dealt with in increasingly ad hoc ways [8]. The document retrieval is referred as the matching of some stated query of user against free-text records set. These records could be any type of mainly unstructured text, such as paragraphs in a manual, real estate records or newspaper articles. The queries of user can be from a few words to multi sentence descriptions of information need.
Document retrieval is sometimes referred to as a branch of Text Retrieval, or Text Retrieval. If a user wants an efficient document retrieval process then annotation, document searching methods and ranking methods play a vital role in whole retrieval process. Here we discuss what these techniques are and how these different techniques are used in this document retrieval system. In the process of ranking every query answer is ranked based on its similarity or relevance to query, it is defined on various information pieces like co-occurrence of some keywords of query as a phrase in record and the query keywords frequencies in the record. Domain-specific features can play a vital role in ranking. E.g., for some publication, number of citations can be used as an indication in ranking
because it is a good indicator of its impact. The Phrase matching effect in ranking gives better results. E.g., for the query q = bbrain, surgeryii, record containing the phrase ―brain surgery‖ is more relevant than the record containing the keywords ―brain‖ and ―surgery‖ alone.
2. RELATED WORK
Annotations are comments, notes, explanations, or external remarks. Annotations are metadata, as they give additional information about data. If the documents are properly annotated it is possible to improve quality of searching. Lack of appropriate annotations makes it hard to retrieve it and rank it properly. Existing annotations [11]makes the analysis and querying of data cumbersome. Therefore this paper surveys, Collaborative Adaptive Data Sharing platform i.e. annotateas-you-create infrastructure. This facilitates fielded data annotation. The key goal of proposed system is to lower the cost of document annotation and provide query workload to direct the process of annotation. Currently available information sharing tools, like content management software annotate document in an ad hoc way.
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 09, September 2015Available at http://internationaljournalofresearch.org
framework manages the crude characteristic dialect message, the Web Tables framework concentrates on HTML- tables, and the profound web surfacing system concentrates on backend databases. Content Runner expends content from a Web scrawl and emits n-ary tuples. It work up to expectations by first linguistically parsing every regular dialect sentence in a creep, then utilizing the results to get a few hopefuls tuple extractions. Recovering social databases from the raw HTML tables comprises of two steps. To start with, Web Tables attempts to channel out all the non-social tables. Second, for all the tables that we accept to be social, Web Tables attempts to recover metadata for each. This methodology is, basically an information joining arrangement that is to make vertical web indexes for particular areas. In this methodology we could make a middle person structure for the area close by and semantic mappings between individual information sources and the arbiter form.[4].
3. PROBLEM DEFINITION
In the existing period many annotation system[5] permits users to share and annotate the document in an adhoc way. Likewise much annotation system allows just ―untyped‖ key word annotation. Annotation that utilization attributes requires users to be more principled in their annotation efforts. They should to know the pattern and field type to utilize additionally they should to know when to utilize such type of fields. Such type of challenges brings about an extremely fundamental annotation that often users simple keywords. Such annotation makes analysis and questioning of database very cumbersome[6]. Additionally one issue in annotation focused around attributes is that many systems have a large number of attributes names for single attributes for instance city and area they may refer
to the same value in differentdatabase. Such kind of constraints makes analysis and searching of database poor.
4. IMPLEMENTATION
4.1 Proposed Information Extraction Algorithm
Information Extraction algorithm is the algorithm we use to extract contents of text file. Following fig shows how information extraction takes place.
Fig.1 Information Extraction Algorithm
Our goal is to suggest annotations for a document.
1) Select a text file
2) Parse the text file. Ignore stopwords from it and count frequency of high querying keywords which will be important for content based search. Maintain frequency count of these keywords appearing in only single document.
3) Upload the file on to the server
4) Then fill all the annotations which are relevant to the document which can be useful for query
based searching. Example:
Select the Text File
Parsing the File
Upload the File
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 09, September 2015Available at http://internationaljournalofresearch.org
year=2012,location=‘Nashik‘ , author =‘Bill Gates‘ etc
4.2 QV, CV Computation and Combining Algorithm:
1) Enter the queries for retrieving the document Example: location=‘Nashik‘ and year=2012
2) Split the queries and pass it to database for retrieving
3) Check all related results and show the related results to user.
4) For much efficient and accurate results,users should try to enter maximum queries they can.
5. ExperimentalResults
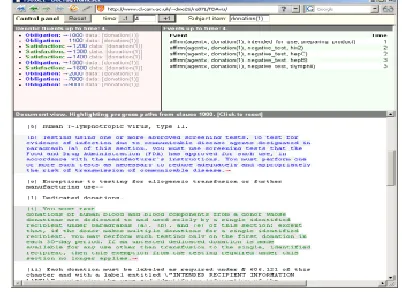
Fig:-2. Annotated screen-capture of document annotations
Fig:-3. Screen-capture of document annotations for a completed workflow
Fig. 4. Screen-capture of progress indication
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 09, September 2015Available at http://internationaljournalofresearch.org
very near completion of the requirements for FDA compliance [15] on this particular blood donation. From the event view, it is clear that six screening tests have been performed (in whatever order suited ‗agentx‘), and all their results are negative. In addition the screening tests have been declared to be FDA complain In Figure 4 shows a clause progress highlight generated from a progress query on the initial clause in the document.
6. CONCLUSION
We presented two ways to combine these two pieces of evidence, content value and querying value. The main advantages of our application are mainly that when users perform query based search, they could get minimum and distinct results where it could be easy for retrieval. By using these techniques, workload of application can reduce by large amount. Also, given the fact the efficiency of searching will be faster because of using the query-based searching technique. This system proposes a new approach for annotating a document, and tries to satisfy querying needs of user efficiently. We studied how the fuzzy search and proximity ranking will improve efficiency of searching. Users will get less and distinct results due to automatic generation of metadata using Open NLP, proximity ranking and instant-fuzzy search. The text mining will be highly boosted due to this system. In future we can enhance this system for any type of documents other than pdf, text, word, etc.
REFERENCES
[1] Eduardo J. Ruiz, Vangelis Hristidis, Panagiotis G.Ipeirotis, ―Facilitating Document Annotation using Contentand Querying Value‖, ieee
transactions on knowledge anddata engineering vol.pp no.99 2013.
[2] Vagelis Hristidis, Panagiotis G. Ipeirotis, Eduardo J. Ruiz―Facilitating Document Annotation Using Content andQuerying Value‖, IEEE Transactions On Knowledge AndData Engineering, volume 6, no 2, IEEE 2014
[3] Akshay Shingote, Nikhil Vispute, Priyanka Dhikale,―Facilitating Document Annotation Using Content & Querying Value‖, IJCTT, vol 9, March 2014
[4] M. J. Camarilla, J. Madhavan, and A. Halevy―Web-scale extraction of structured data,‖SIGMOD Rec., vol. 37, pp. 55–6 1, March 2009.
[5] J. Lu, S. Ji, A. Behm, , C. Li, ― Space- constrained grambased indexing for efficient approximate string search,‖ ICDE, 2009, pp.604– 615.
[6] M. Zhu, S. Shi, J.-R. Wen, and N. Yu, ―Can phrase indexing help to process non-phrase queries?‖ CIKM, 2008, pp. 679–688.
[7] R. Song, M. J. Taylor Y. Yu, , J. R. Wen, H. Hon, ―Viewing term proximity from a different perspective,‖
[8] J. J. Meyer and R. J. Wieringa, Deontic Logic in Computer Science. John Wiley & Sons Ltd, 1993.
International Journal of Research (IJR)
e-ISSN: 2348-6848, p- ISSN: 2348-795X Volume 2, Issue 09, September 2015Available at http://internationaljournalofresearch.org
[10] S. R. Jeffery, M. J. Franklin, and A. Y. Halevy, ―Payasyou-go user feedback for dataspace systems,‖ in ACM SIGMOD, 2008
[11] J. Madhavan and et al., ―Web-scale data integration: You can only afford to pay as you go,‖ in CIDR, 2007
[12] Vagelis Hristidis, Eduardo Ruiz,‖ CADS: A Collaborative Adaptive Data Sharing Platform‖, SCIS, International University, Florida, 2009
[13] R. Schenkel, A. Broschart, S. Won Hwang, G. Weikum, M. Theobald, ―Efficient text proximity search,‖ SPIRE, 2007, pp. 287–299.
[14] H. Yan, S. Shi, F. Zhang, T. Suel, and J.-R. Wen, ―Efficient term proximity search with the term-pair indexes,‖CIKM, 2010, pp. 1229– 1238.
[15] H. Bast, F. Suchanek, A. Chitea, I. Weber, , ―Ester : efficient search on text, entities, and relations,‖ SIGIR, 2007, pp. 671– 678.
Author Profile
Dr.Shaik Abdul Muzeer Professor & Principal
Megha institute of Engineering & Technology for Women