Classification and Clustering of User Mails by Using an Improved
k-means Clustering Algorithm
S. VenkateshP
1
P
, M. SreenivasuluP
2
P
P
1
P
Department of CSE, J.N.T.U Anantapur, Tirupathi, Andhra Pradesh, India, Email-U[email protected]
P
2
P
Department of CSE, Sathyabama University, Chennai, Tamilnadu, India,Email-U[email protected]
Abstract
K-approach clustering has been extensively used to advantage perception into organic systems from huge-scale lifestyles science records. To quantify the similarities among biological facts units, Pearson correlation distance and standardized Euclidean distance are used maximum frequently; however, optimization techniques were in large part unexplored. Those two distance measurements are equivalent inside the feel that they yield the same ok-approach clustering end result for same sets of ok preliminary centroids. for that reason, an efficient set of rules used for one is applicable to the alternative. numerous optimization techniques are available for the Euclidean distance and may be used for processing the standardized Euclidean distance; but, they're no longer custom designed for this context. We as an alternative approached the trouble by analyzing the homes of the Pearson correlation distance, and we invented an easy but effective heuristic approach for markedly pruning unnecessary computation while keeping the final solution.
Keywords: Classification, Clustering, Preprocessing, Word frequency.
1. Introduction
Clustering, an unmonitored gaining knowledge of set of rules to group information into similar classes, has been widely used to benefit insights into biological structures from large-scale organic facts, which includes gene expression records monitored with the aid of microarrays [1], [2], [3], [4], his tone modifications [5], [6], [7], [8], [9], [10], and nucleosome positioning . An expansion of clustering algorithms, consisting of hierarchical clustering, ok-approach clustering, self-organizing map (SOM), and most important additives analysis (PCA), had been used. of these, okay-approach clustering is the most extensively used to procedure big-scale information units, in part due to the fact the computational complexity of hierarchical clustering is quadratic or higher in the wide variety of statistics points, whilst k-method clustering algorithms have decrease computational complexity. Accelerating k-way clustering algorithms is still necessary to manner the
developing quantity of organic records because of the recent progress in information series with the aid of subsequent-generation sequencing.
1.1 Existing System
These days many researchers have proposed the clustering algorithms for class of the facts gadgets into the clusters by way of their similarities. All those research had been concentrated a great deal towards offline and small information units. K-manner clustering is applicable for massive records units; nevertheless its overall performance wishes enhancements. Inside the existing structures, length of the init-centroids reasons the overall performance versions.
1.2 Disadvantages of Existing System
Applicable for small length datasets.
Off-line.
Overall performance is less and eating of excessive computational recourses.
Greater delay.
2. Proposed System
2.1 Advantages of Proposed system
Relevant for datasets of better-quantity.
Off-line & online three.
Best overall performance at much less
computational recourses.
Higher speed.
3. System Architecture
Fig.1 Classification and Clustering Architecture
3.1 Implementation
Preprocessing:
Pre-Processing Steps before going for walks clustering algorithms on textual content datasets, we completed some preprocessing steps. Particularly, stop words (prepositions, pronouns, articles, and beside the point record metadata) have been eliminated. Also, the Snowball stemming set of rules for Portuguese phrases has been used.
Calculating word frequency occurring in each document:
Then, we followed a conventional statistical technique for text mining, wherein files are represented in a vector space model. On this model, each report is represented via a vector containing the frequencies of occurrences of words, which can be defined as delimited alphabetic strings, whose number of characters is among four and 25. We also used a dimensionality discount technique known as time period Variance (television) which can growth both the effectiveness and efficiency of clustering algorithms. TV selects a number of attributes (in our case 100 phrases) which have the greatest variances
over the files. That allows you to compute distances among files, measures were used, namely: cosine-primarily based distance and Leven- shtein -based totally distance. The later has been used to calculate distances between file (document) names most effective.
Estimate the number of clusters:
if you want to estimate the range of clusters, a broadly used technique consists of having a fixed of information partitions with distinctive numbers of clusters after which selecting that particular partition that offers the best result according to a specific pleasant criterion (e.g., a relative validity index Such a set of partitions may end result immediately from a hierarchical clustering dendrogram or, alternatively, from more than one runs of a partition set of rules(e.g., K-way)starting from special numbers and initial positions of the cluster prototypes (e.g., see] and references therein). For the instant, let us expect that a hard and fast of information walls with distinct numbers of clusters is to be had, from which we need to choose the excellent one—in line with a few relative validity criterion. notice that, by using deciding on such a information partition, we are acting version choice and, as an intrinsic a part of this manner, we also are estimating the quantity of clusters.
Run silhouette algorithm to find the similarity matrix A broadly used relative validity index is the so-known as silhouette, which has additionally been adopted as a factor of the algorithms employed in our work. Consequently, it's miles beneficial to define it even before we address the clustering algorithms used in our observe. Let us bear in mind an item belonging to cluster. The average dissimilarity of to all different objects of is denoted with the aid of. Now let us take into account cluster. The average dissimilarity of to all gadgets of can be referred to as. After computing for all clusters, the smallest one is chosen, i.e., This value represents the dissimilarity of to its neighbor cluster, and the silhouette for a provide object, is given by:
Find maximum s (I) of a document cluster
As a consequence, the great clustering corresponds to the records partition that has the maximum average silhouette. The common silhouette simply addressed depends at the computation of all distances among all objects. So as to provide you with a more computationally efficient criterion, referred to as simplified silhouette, you could compute handiest the distances some of the objects and the centroids of the clusters. The term of now corresponds to the dissimilarity of object to its corresponding cluster centroid. As a consequence, it is important to compute handiest one distance to get the price, rather than calculating all of the distances between and the opposite items of. Further, instead of computing as the common dissimilarity of to all gadgets of, we are able to now compute the distances between and the centroid of. Observe that the computation of the authentic silhouette, in addition to of its simplified model relies upon most effective on the performed partition and not at the followed clustering algorithm. thus, these silhouettes can be applied to assess walls(thinking of the quantity of clusters) received by means of numerous clustering algorithms, as the ones employed in our have a look at and advert- dressed inside the sequel.
4. Literature Survey
4.1 Study about Data Clustering: 50 Years beyond K-Means
Organizing statistics into practical groupings is one of the maximum essential modes of knowledge and getting to know. For instance, a commonplace scheme of scientific classification places organisms into a machine of ranked tax: area, nation, phylum, class, and many others.. Cluster analysis is the formal study of strategies and algorithms for grouping, or clustering, items consistent with measured or perceived intrinsic characteristics or similarity. Cluster analysis does no longer use class labels that tag gadgets with previous identifiers, i.e., elegance labels. The absence of class facts distinguishes facts clustering (unsupervised gaining knowledge of) from category or discriminate analysis (supervised getting to know). The purpose of clustering is to locate shape in facts and is therefore exploratory in nature. Clustering has an extended and rich history in a spread of clinical fields. one of the maximum famous and simple clustering algorithms, k-approach, became firs posted in 1955. no matter the fact that okay-manner was proposed over 50 years in the past and hundreds of clustering algorithms were posted
considering then, ok-way is still broadly used. This speaks to the difficulty of designing a general purpose clustering set of rules and the unwell-posed hassle of clustering. We provide a quick evaluate of clustering, summarize widely recognized clustering techniques, talk the most important demanding situations and key issues in designing clustering algorithms, and factor out a number of the emerging and beneficial studies instructions, which includes semi-supervised clustering, ensemble clustering, simultaneous feature choice all through data clustering and massive scale facts clustering.
4.2 Study about Cluster Analysis for Gene Expression Data: A Survey
the high-quality and reliability of clustering consequences. Finally, we finish this paper and recommend the promising developments on this subject.
5. Simulated Result
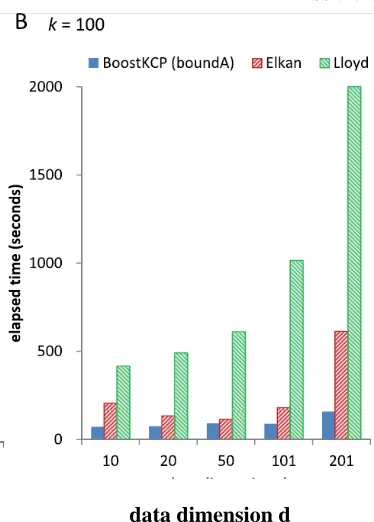
we've up to now tested situations whilst the number of clusters k tiers from to seventy eight in reality due to the fact these numbers of corporations are of interest in real organic packages. We here look into whether BoostKCP (bound A) outperforms Elkin’s and Lloyd’s algorithms for larger values of k, inclusive of k ¼ one hundred and 500. Certainly, Fig. 6 illustrates that BoostKCP (bound A) become the winner when the three algorithms were used to cluster the nucleosome positioning information of measurement d ¼ 10, 20, 50, a hundred and one, and 201 into okay ¼ a hundred and 500 groups.
data dimention d
data dimension d
Fig 2. Performance improvement by BoostKCP (bound A) using nucleosome positioning data of dimension d ¼ 10,
20, 50, 101, and 201 to group the data into k ¼ 100 and 500 clusters.
6. Conclusion
Excessive dimensional statistics, which includes epigenome information, nucleosome positioning, and gene expression patterns, are pretty commonplace in biological research. k-manner clustering the usage of the Pearson correlation and standardized Euclidean distances has proven beneficial for acquiring novel perception from such massive-scale biological information sets; however, it is possibly to be a computationally intense challenge, thus traumatic a technique for accelerating computational overall performance for high-dimensional biological records. we've addressed the trouble of casting off unnecessary calculations associated with the okay-way clustering set of rules. on this paper, we brought BoostKCP, a easy however effective heuristic technique that has proved useful for reducing the computational time.
References
expression patterns,” in Proc. Natl. Acad. Sci. USA, 1998, vol. 95, no. 25, pp. 14863–14868.
[2] P. Tamayo, D. Slonim, J. Mesirov, Q. Zhu, S. Kitareewan, E. Dmitrovsky, E. S. Lander, and T. R. Golub, “Interpreting patterns of gene expression with self-organizing maps: Methods and application to hematopoietic differentiation,” in Proc. Natl. Acad. Sci. USA, vol. 96, no. 6, 1999, pp. 2907–2912, 1999.
[3] D. Jiang, C. Tang, and A. Zhang, “Cluster analysis for gene expression data: A survey,” IEEE Trans. Knowl. and Data Eng., vol. 16, no. 11, pp. 1370–1386, Nov. 2004. [4] P. D’haeseleer, “How does gene expression clustering work?” Nat. Biotechnol., vol. 23, pp. 1499–501, 2005. [5] T. S. Mikkelsen, M. Ku, D. B. Jaffe, B. Issac, E. Lieberman, G. Giannoukos, P. Alvarez, W. Brockman, T.-K. Kim, R. P. Koche, W. Lee, E. Mendenhall, A. O’Donovan, A. Presser, C. Russ, X. Xie, A. Meissner, M. Wernig, R. Jaenisch, C. Nusbaum, E. S. Lander, and B. E. Bernstein, “Genome-wide maps of chromatin state in pluripotent and lineage-committed cells,” Nature, vol. 448, pp. 553–60, 2007.
[6] N. D. Heintzman, G. C. Hon, R. D. Hawkins, P. Kheradpour, A. Stark, L. F. Harp, Z. Yet, L. K. Lee, R. K. Stuart, and C. W. Ching, “Histone modifications at human enhancers reflect global celltype-specific gene expression,” Nature, vol. 459, no. 7243, pp. 108– 112, 2009.
[7] P. V. Kharchenko, A. A. Alekseyenko, Y. B. Schwartz, A. Minoda, N. C. Riddle, J. Ernst, P. J. Sabo, E. Larschan, A. A. Gorchakov, and T. Gu, “Comprehensive analysis of the chromatin landscape in Drosophila melanogaster,” Nature, vol. 471, no. 7339, pp. 480– 485, 2010.
[8] S. Roy, J. Ernst, P. V. Kharchenko, P. Kheradpour, N. Negre, M. L. Eaton, J. M. Landolin, C. A. Bristow, L. Ma, and M. F. Lin, “Identification of functional elements and regulatory circuits by Drosophila modENCODE,” Science, vol. 330, no. 6012, pp. 1787– 1797, 2010.
[9] L. Handoko, H. Xu, G. Li, C. Y. Ngan, E. Chew, M. Schnapp, C. W. H. Lee, C. Ye, J. L. H. Ping, F. Mulawadi, E. Wong, J. Sheng, Y. Zhang, T. Poh, C. S. Chan, G. Kunarso, A. Shahab, G. Bourque, V. Cacheux-Rataboul, W.-K. Sung, Y. Ruan, and C.-L. Wei, “CTCFmediated functional chromatin interactome in pluripotent cells,” Nat. Genetics, vol. 43, pp. 630–8, 2011.
[10] T. Liu, A. Rechtsteiner, T. A. Egelhofer, A. Vielle, I. Latorre, M. S. Cheung, S. Ercan, K. Ikegami, M. Jensen, and P. KolasinskaZwierz, “Broad chromosomal domains of his tone modification patterns in C. elegans,” Genome Res., vol. 21, no. 2, pp. 227–236, 2011.
S.Venkatesh received the B.Tech Degree in Computer Science and Engineering from vaageswari college of engineering, University of JNTUHYDERABAD in 2010.He is currently working towards the Master’s Degree in Computer Science and Engineering, in Shree Institute of Technology & Sciences University of JNTUA. He interest lies in the areas of Web Development Platforms, SQL, and Cloud Computing Technology.