DEVELOPING A NEURAL
NETWORK-BASED METHOD FOR FASTER FACE
RECOGNITION BY TRAINING &
SIMULATION
IFAT-AL-BAQEE
Lecturer, Stamford University Bangladesh, Dhaka, Bangladesh A.S.M. MOHSIN
Lecturer, Stamford University Bangladesh, Dhaka, Bangladesh KURRATUL AIN
Lecturer, Stamford University Bangladesh, Dhaka, Bangladesh MOHAMMAD ASHRAF HOSSAIN SADI
Lecturer, Stamford University Bangladesh, Dhaka, Bangladesh MD. RAKIBUL HASAN
Assistant Engineer, R & D Lab, CEF Atomic Energy Research & Establishment, Dhaka, Bangladesh
Abstract:
Neural networks have been extensively studied for applications related to face recognition by training data sets extracted from facial images. In this paper, a feed-forward neural network-based upright frontal face detection method is developed. Local statistics of face images such as mean, standard deviation and kurtosis are used as datasets to be trained by feed forward neural networks. Each of the images is subdivided into several small blocks which are used to determine the datasets with two combinations of mean, standard deviation or kurtosis to train the feed-forward network. The extensive simulations are conducted using different images of same subjects from a standard face database to study and compare the face detection performance of the neural networks. It is found that neural network that uses the datasets of kurtosis gives the best performance among the two processes. Finally, the main focus is to improve the detection speed rather than performance.
Keywords: Face Recognition, Kurtosis, Neural network, Standard deviation.
1. Introduction
Face recognition system is a computer application for automatically identifying or verifying a person from a digital image or a video frame from a video source. One of the ways to do this is by comparing selected facial features from the image and a facial database. A general statement of the face recognition problem (in computer vision) can be formulated as follows: Given still or video images of a scene, identify or verify one or more persons in the scene using a stored database of faces.
Artificial neural network are a proven technology for pattern recognition. Neural nets derive their strong pattern recognition abilities from their insensitivities to small changes in input data. This property allows nets to be trained on datasets with minor errors and subsequently used to evaluate real data, which might contain slight variations from the training data. In the case of face recognition, a neural net can be trained on photos of a known individual and then used to determine.
There are many popular face databases such as LFW face database, FERET database, YALE face database, Indian Face Database and so on are used in facial recognition technology now-a-days. In this paper, we obtain our photo images from the “Indian Face Database”, these color images is converted to usable datasets using local statistics of images (mean, Standard Deviation and Kurtosis). We used 30 sample images (6 different persons in 5 varying orientations and illumination condition) to obtain datasets and trained to a target value using a single network. After successful training, 6 different random images (different pose and illumination condition) of those following persons are picked from the face database to simulate with the same network and compare the result without expected target. We find that our proposed system can recognize up to maximum 80% of test images correctly within the target value in about 2.8 to 3.6 seconds while using the datasets obtain from kurtosis. Of course our proposed methodology has not brought any significant impact considering the performance of the face recognition results but rather we focused on the detection time as in some face detection cases time becomes an important factor, so a simple methodology is developed to convey our objective in this work. Certainly we hope to improve our performance in our following work by pre-processing the images with the goal of eliminating the variations in the processed output i.e. using feature extraction to help correct for subject orientation by only sending images of certain features, such as the eyes, to the network. Hopefully then the efficiency of our work will increase rapidly without altering i.e. increasing the time duration.
2. Literature Review
Over the years, several related approaches have investigated face recognition. The different face recognition techniques can be classified into four categories: Eigen faces, feature- based, hidden Markova based model, and neural network based algorithms. In 1991, Turk and Penland [2] further developed the Eigen faces approach by discovering that it enabled both face detection (through the residual error) and face recognition. A good work on face recognition using Eigen faces can be found in [3] where two well known techniques (PCA and LDA) are presented. An example of feature-based recognition can be found in [4]. An interesting approach using hidden Markov models is found in [5]. Literature surveys detailing recent work on face detection and face recognition can be found in [6] and [7], respectively.
Much work has been done using neural networks for face recognition. Addadnia, Faez, and Ahmad [8] and Talukder and Casasent [9] present neural net approaches which deal with both face detection and face recognition, [8] presents an interesting approach for initializing the neural network.
Perhaps the most ground breaking work on Neural Network- based face detection was done by Rowly and Baluja [10]. The sub-imaging (size reduction for computation efficiency) concept used in this paper, and then the system applies a set of neural network-based filters to these sub-images and use an arbitrator to combine the outputs. The filter examines each location in the image at several scales, looking for locations that might contain a face in a group photo. The arbitrator then merges detections from individual filters and eliminates overlapping detection [10].
In fact, our idea of dividing the main images into several sub-images of smaller pixels is adopted from the idea of Rowly for computational efficiency; we keep the sub-image block’s size bigger than to reduce the training time. But in our work we try to match a particular image with some set of images of same subject, provided there are face orientations and different illumination conditions between the images, not to detect the face into a group of faces in a single image.
The issue of illumination variation has been studied significantly. Du and Ward suggest the wavelet-based illumination normalization [4]. Our other complementary preprocessing technique for future work- edge detection is discussed in [11].
3. Neural Network for Face Recognition
neutral happy sad surprised
Fig. 1: Sample subject showing four face expressions
Neural networks process information in a similar way the human brain does. The network is composed of a large number of highly interconnected processing elements, called neurons, working in parallel to solve a specific problem. An artificial neuron is a device with many inputs and one output. Each neuron has a weighting associated with it.
Neural networks learn by example. Therefore, they must be trained with known inputs. Once trained, a neural network can be thought of as an expert in the category of information it has been given to analyze. The network can used to provide insight given new situations of interests. The basic form of artificial neural networks consist of three groups, or layers, of units: a layer of ’input’ units is connected to an intermediate layer of ’hidden’ units, which is connected to a layer of ’output’ units. The activity of the input units represents the raw information that is inputted into the network. The activity of each hidden unit is determined by the activities of the input units and the weights on the connections between the input and the hidden units. The behavior of the output units depends on the activity of the hidden units.
If there is a group of authorized people, in which a recognition system must accept. All the other people are unauthorized or ‘aliens’ and should be rejected. We can train a system to recognize the small group of people that is why application of a Multilayer Perceptions (MLP) Neural Network (NN) was studied for this task. Configuration of our MLP was chosen by experiments. It contains three layers. Input for NN is a grayscale image. Number of input units is equal to the number of pixels in the image. Number of hidden units was 30. Number of output units is equal to the number of persons to be recognized. Every output unit is associated with one person.
NN is trained to respond to a target such as “+1” on output unit, corresponding to recognized 1st person and “+2” on other output for 2nd person. We called this perfect output. After training highest output of NN indicates recognized person for test image.
4. Methodology
In this section we represent the algorithm of our work. In our method, the blocks from face images are used for training a neural network. Instead of taking an entire block of pixels, the combinations of “Mean value”, “Standard Deviation” and “Kurtosis” of the block of sub-images are used for training. The mean value of an image block of size is given by
X
M∑
∑
(1)Where, and XMis the mean of the each image block.
There are usually two definitions for standard deviation. In our work, for an image block of dimension standard deviation is given by
1
∑
1∑
1 i 2 1/2(2)
Where and
= ∑ ∑ (3) The kurtosis of a distribution is defined as
The facial datasets of statistical values for batch training by a feed-forward Neural Network are obtained by using two different combinations of the upper parameters. First combination will be of “mean” and “Standard deviation” and second will be of “kurtosis”. Thereby two sets of dataset are prepared to train and simulate using our designed Neural Network.
Now the face images obtain from a database is been divided into blocks having dimension of 32×32 arrays. After converting the face image into class doubled values, each loaded ‘n’ images will be divided into 32×32 array dimensional sub-images by means of mathematical terms, and suitable logical loop. Here in the particular face database, each image has a dimension of 640×480×3. If each image is divided into smaller images of 32×32 arrays then approximately into 20×15=300 blocks are counted (the color portions have been ignored). Now for the our first program, “mean” of the “standard deviation” of each 32×32 dimensional sub-images is calculated by (1) & (2). In our second program, for 32×32 dimensional blocks the kurtosis for each block is calculated by (4). The result is 1×32 dimensional matrices (for each column there is single kurtosis value) and again determining the kurtosis after transposing these matrices, there will be a single kurtosis value for every blocks. For 300 blocks of images there are 300 statistical values are counted, for ‘n’ number of images a matrix of 300×n size is achieved. Now the matrix or datasets will be trained to the desired ‘target’ by mean of a feed-forward neural network. Feed-forward networks consist of Nl layers using the dot product weight function, net sum net input function, and the specified transfer functions. The first layer has weights coming from the input. Each subsequent layer has a weight coming from the previous layer. All layers have biases. The last layer is the network output. Each layer's weights and biases should be initialized. Adaption is done with trains, which updates weights with the specified learning function. Training is done with the specified training function. Performance is measured according to the specified performance function. Then we simulate the weighted training set with target. In this work specified transfer functions are used such as linear transfer function and log-sigmoid function.
Linear transfer function (purelin): It is a linear transfer function which calculates the neuron's output by simply returning the value passed to it.
(5)
Log-Sigmoid transfer function (logsig): The sigmoid transfer function shown below takes the input, which can have any value between plus and minus infinity and squashes the output into the range 0 to 1. This transfer function is commonly used in back propagation networks, in part because it is differentiable. It is given by
log (6)
Target is a matrix provided to construct the training network with the weighted input matrix. Generally we will differentiate one person’s image with others using suitable targets. The given inputs are trained with a target, targets are given such a way that for each person’s image there will be a particular target, after training the input data with particular target successfully test image as input is given and see whether the simulation resulting the desired target or approximate target, if not, means failing to detect the particular image. Example of a target: for ‘6’ facial images of 6 different persons, the targets may be of
T= [1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5 6 6 6 6 6]
This “target” matrix is of 30×1 dimensions. Each number in the matrix is representing each facial image of a particular subject with different facial orientation and illumination. Suppose five training target “1” means five images with facial orientations and illuminations of a single subject i.e. person. Now after simulating our feed-forward network with the weighted input to this target matrix, the training will be done.
5. Results and Analysis
5.1.Description of Face Database
There are eleven different images for each of 40 distinct subjects. For some subjects, additional photographs have been included. All the images were taken against a bright homogeneous background having the faces in an upright, frontal position.
The files are in JPEG format. The size of each image is 640x480 pixels, with 256 grey levels per pixel. There are 3 color combinations in each pixel (red, blue & green) with resolution of 96 DPI (Dot per inch). The images are organized in two main directories - males and females.
In each of these main directories, there are sub-directories with name and serial numbers, each corresponding to a single individual. In each of these sub-directories, there are eleven different images of that subject, which have names of the form abc.jpg, where abc is the image number for that subject. The following orientations of the face have been included : looking front, looking left, looking right, looking up, looking up towards left, looking up towards right, looking down & also with the emotions: neutral, smile, laughter, sad/disgust. The photographs have been taken with prior permissions of the individual. We have chosen five images of different orientations of six different males from this database to train out Network. [Fig 2]
Fig. 3: Sample faces from the database to test the coding
Test facial images which are to detect by our coding consisting of different orientations and illuminations of the same particuler person’s/subjects [Fig 3].
5.2.Results and Performance Analysis
Thirty images of 6 different persons are taken with 5 different orientations and illuminations to train by our constructed feed-forward Neural Network (Fig 2). Then our code is tested with 6 images (of course different orientations and illuminations from the trained images) of the same 6 persons (Fig 3). Datasets for training by our FF Network are obtained using the following two combinations of statistical datasets-
1. Data train using average of standard deviation of each block of sub-images 2. Data train using kurtosis of each block of sub-images
The detection results are shown in Table 1 and Table 2 and also the detection performance are shown graphically in Fig. 4 and Fig. 5.
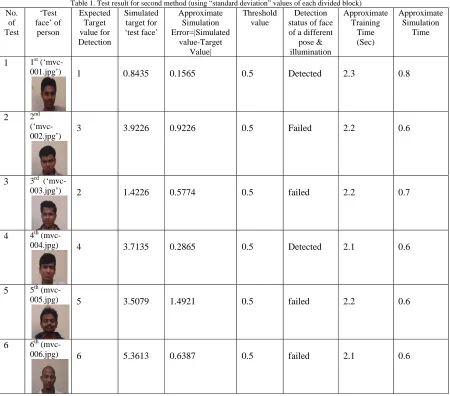
Table 1. Test result for second method (using “standard deviation” values of each divided block)
No. of Test
‘Test face’ of
person
Expected Target value for Detection
Simulated target for ‘test face’
Approximate Simulation Error=|Simulated
value-Target Value|
Threshold value
Detection status of face of a different
pose & illumination
Approximate Training
Time (Sec)
Approximate Simulation
Time
1 1st
(‘mvc-001.jpg’) 1
0.8435 0.1565 0.5 Detected 2.3 0.8
2 2nd (‘mvc-002.jpg’) 3
3.9226 0.9226 0.5 Failed 2.2 0.6
3 3rd (‘mvc-003.jpg’) 2
1.4226 0.5774 0.5 failed 2.2 0.7
4 4th
(mvc-004.jpg) 4 3.7135 0.2865 0.5 Detected 2.1 0.6
5 5th
(mvc-005.jpg) 5 3.5079 1.4921 0.5 failed 2.2 0.6
6 6th
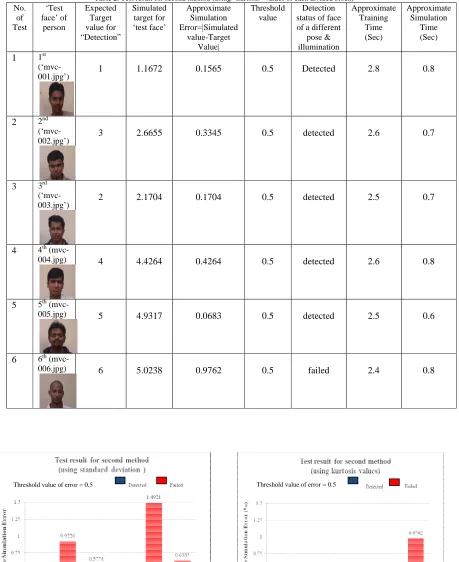
Table 2. Test result for second method (using “kurtosis” values of each divided block)
Fig. 4: Detection result shown graphically for process “1” Fig. 5: Detection result shown graphically for process “2”
No. of Test
‘Test face’ of
person
Expected Target value for “Detection”
Simulated target for ‘test face’
Approximate Simulation Error=|Simulated
value-Target Value|
Threshold value
Detection status of face of a different
pose & illumination
Approximate Training
Time (Sec)
Approximate Simulation
Time (Sec)
1 1st
(‘mvc-001.jpg’) 1 1.1672 0.1565 0.5 Detected 2.8 0.8
2 2nd
(‘mvc-002.jpg’) 3 2.6655 0.3345 0.5 detected 2.6 0.7
3 3rd
(‘mvc-003.jpg’) 2 2.1704 0.1704 0.5 detected 2.5 0.7
4 4th
(mvc-004.jpg) 4 4.4264 0.4264 0.5 detected 2.6 0.8
5 5th
(mvc-005.jpg) 5 4.9317 0.0683 0.5 detected 2.5 0.6
6 6th
(mvc-006.jpg) 6 5.0238 0.9762 0.5 failed 2.4 0.8
Results are subjected to change within each simulation process.
Total Simulation times including training time varies between 2.8 to 3.6 seconds, whereas total detection time is between 0.6 to 0.8 seconds in a Intel Pentium 3 CPU E2450@966 MHz processor and 256 MB System Random Access Memory.
Our sole purpose will be training all the facial images of a databases with the constructed network and save, after that any facial image of different illuminations and orientation of any subject included in the database will be simulated using the same Neural Network in a quick time to achieve a successful detection. The training graphs for each of the 6 test images for the two cases have been showed in Fig. 6 to Fig. 17. Training Graphs: While Data(s) extracted from the “Average” of the “Standard Deviation” of each Sub-image Matrices:
Fig. 6: Simulation with Test Image “1” Fig. 7: Simulation with Test Image “2”
Fig. 8: Simulation with Test Image “3” Fig. 9: Simulation with Test Image “4”
Fig. 10: Simulation with Test Image “5” Fig. 11: Simulation with Test Image “6”
0 20 40 60 80 100 120 140 160 180 10-7 10-6 10-5 10-4 10-3 10-2 10-1 100 101 191 Epochs T rai n ing-B lu
e G
oal
-B
lac
k
Performance is 9.46152e-007, Goal is 1e-006
0 50 100 150 200 250
10-6 10-4 10-2 100 102 284 Epochs T rai n ing-B lue G oa l-B la c k
Performance is 9.9362e-007, Goal is 1e-006
0 50 100 150 200 250 300 350 400 10-7 10-6 10-5 10-4 10-3 10-2 10-1 100 101 449 Epochs T rai n ing-B lu
e G
oal
-B
lac
k
Performance is 9.96989e-007, Goal is 1e-006
0 20 40 60 80 100 120 140 160 180 200
10-6 10-5 10-4 10-3 10-2 10-1 100 101 203 Epochs T rai ni ng -B lu e G o a l-B la c k
Performance is 9.58128e-006, Goal is 1e-005
0 50 100 150 200 250
10-6 10-5 10-4 10-3 10-2 10-1 100 101 275 Epochs T rai n ing-B lu
e G
oal
-B
lac
k
Performance is 9.89046e-006, Goal is 1e-005
0 20 40 60 80 100 120 140 160 10-6 10-5 10-4 10-3 10-2 10-1 100 101 171 Epochs T rai n ing-B lu
e G
oal
-B
lac
k
Training Graphs: While Data(s) extracted from the “Kurtosis” of each Sub-image Matrices
Fig. 12: Simulation with Test Image “1” Fig. 13: Simulation with Test Image “2”
Fig. 14: Simulation with Test Image “3” Fig. 15: Simulation with Test Image “4”
Fig. 16: Simulation with Test Image “5” Fig. 17: Simulation with Test Image “6”
Moreover the process is tested with 120 more sample images taken from the face database mentioned. In these 120 sample images, 6 images of 20 different persons has been included, each representing a particular orientation/emotion and these are used to trained by the network for a given target.
The performance of the face recognition methods was not satisfactory except for the second one (weighted inputs are ‘kurtosis’ values). For the first method, the detection rate has been reduced to 30% (6 out of 20 images are detected correctly). But for the second method, detection rate was 80%. Now in the case of false detection issue i.e. running the process with other 21 sample images of 7 distinct objects (persons), there is an acceptable number of false detections have been noticed. For the 1stmethod, the percentage of false detection was about 57.14% (12 false detections out of 21), in case of 2nd method, the percentage was 23.81% (5 false detections).
0 10 20 30 40 50 60 70 80 90 10-6 10-5 10-4 10-3 10-2 10-1 100 101 91 Epochs T rai n ing-B lu
e G
oal
-B
lac
k
Performance is 8.01838e-006, Goal is 1e-005
0 50 100 150 200
10-6 10-5 10-4 10-3 10-2 10-1 100 101 102 249 Epochs T rai ni ng -B lue G oal -B lac k
Performance is 9.57329e-006, Goal is 1e-005
0 10 20 30 40 50 60 70
10-6 10-5 10-4 10-3 10-2 10-1 100 101 75 Epochs T rai n ing-B lu
e G
oal
-B
lac
k
Performance is 9.30676e-006, Goal is 1e-005
0 10 20 30 40 50 60 70 80
10-6 10-4 10-2 100 102 80 Epochs T rai ni n g -B lu
e G
o a l-B la c k
Performance is 9.57937e-007, Goal is 1e-006
0 10 20 30 40 50 60 70
10-6 10-4 10-2 100 102 72 Epochs T rai n ing-B lu
e G
oal
-B
lac
k
Performance is 9.79534e-007, Goal is 1e-006
0 10 20 30 40 50 60 70 80 90 100
10-6 10-4 10-2 100 102 104 Epochs T rai n ing-B lue G oa l-B la c k
6. Conclusion and Future Work
However, there is still enough of scope to work in the future. The main limitation of the current system is that it only detects upright faces looking at the camera. Separate versions of the system may be trained for each face orientation and the results can be combined using arbitration methods similar to those presented here. Preliminary work in this area indicates that detecting profiles views of faces is more difficult than detecting frontal views, because they have fewer stable features and because the input window will contain more background pixels.There is an option to use the distinct features [11] of an image such as eye, mouth, ear, nose or only face (excluding background) to detect the faces more efficiently. Other differentiable factors such as DCT, MSD can be used to improve face matching between different orientations.
Even within the domain of detecting frontal views of faces, there are ways to improve. When animage sequence is available, temporal coherence can focus attention on particular portions of the images. As a face moves about, its location in one frame is a strong predictor of its location in next frame. Other methods of improving system performance include application of more sophisticated image preprocessing and normalization [4] techniques, is our current work to improve the facial recognition efficiency up to 98% using our algorithm.
References
[1] Zhao, W.; Chellappa, R. (2000): “Illumination-Insensitive Face Recognition Using Symmetric Shape-from-Shading,” In Proc.
Conference on Computer Vision and Pattern Recognition, pp. 286-293.
[2] Turk, M.; Pentland, A. (1991). Eigenfaces for Recognition, Vision and Modeling Group, Media Laboratory, Massachusetts Institute of
Technology.
[3] Wang, J.; Zhang, C.; Shum, H. (2004): Face Image Resolution versus Face Recognition Performance Based on Two Global Methods,
Proceedings of Asia Conference on Computer Vision (ACCV04).
[4] Du, S.; Ward, R. (2005): Wavelet-Based Illumination Normalization for Face Recognition, Image Processing, 2005, ICIP 2005, IEEE
International Conference.
[5] Salah, A.; Bicego, M.; Akarum, L.; Grosso, E.; Tistarelli, M. (2007): Hidden Markov Model-based Face Recognition Using Selective
Attention, Human Vision and Electronic Imaging XII, Proceedings of the SPIE, 6492.
[6] Hjelmas, E.; Low, B. (2001): Face detection: A survey, Computer Vision and Image Understanding, 83(3), pp. 236-274.
[7] Zhao, W.; Chellappa, R.; Rosenfeld, A.; Phillips, P.J. (2002): Face Recognition: A literature survey, Technical Report-CART-TR-948.
University of Maryland.
[8] Karimfaez, J.; Faez, K.; Ahmadi, M. (2005): N-Feature Neural Network Human Face Recognition.
[9] Talukder, A.; Casasent, D. (2001): Adaptive activation function neural net for face recognition, Neural Networks, 2001, Proceedings,
IJCNN'01, International Joint Conference.
[10] Rowley, H. A.; Baluja, S.; Kanade, T. (1998): Neural network-based face detection, IEEE Transactions on Pattern Analysis and
Machine Intelligence, 20(1), pp. 23–38.
[11] Rao, K.; Ben-Arie, J. (1993): Generic face recognition, feature extraction and edge detection using optimal DSNR expansion
matching, Circuits and Systems, ISCAS'93, 1993 IEEE International Symposium on, pp. 547-550.
[12] Marko, K.; Dosdall, J.; Murphy, J. (1990): Automotive control system diagnosis using neural nets for rapid pattern classification of