PROSODIC FEATURE BASED TEXT
DEPENDENT SPEAKER RECOGNITION
USING MACHINE LEARNING
ALGORITHMS
Sunil Agrawal*
Department of ECE, U.I.E.T., Panjab University, Chandigarh, 160014.
Shruti A.K.
Department of CSE, N.I.T.T.T.R, Panjab University, Chandigarh, 160014.
C. Rama Krishna
Department of CSE, N.I.T.T.T.R, Panjab University, Chandigarh, 160014. Abstract :
Most of us are aware of the fact that voices of different individuals do not sound alike. The ability of recognizing a person solely from his voice is known as speaker recognition. Speaker recognition can not only assist in building better access control systems and security apparatus, it can be a useful tool in many other areas such as forensic speech analysis. The choice of features plays an important role in the performance of ML algorithm. Here we propose prosodic features based text dependent speaker recognition where the prosodic features can be extracted through linear predictive coding. Formants are efficient parameters to characterize a speaker’s voice. Formants are combined with their corresponding amplitudes, fundamental frequency, duration of speech utterance and energy of the windowed section. This feature vector is input to machine learning (ML) algorithms for recognition. We investigate the performance of four ML algorithms namely MLP, RBFN, C4.5 decision tree, and BayesNet. Out of these ML algorithms, C4.5 decision tree performance is consistent. MLP performs better for gender recognition and experimental results show that RBFN gives better performance for increased population size.
Keywords: Speaker Recognition; Linear Predictive Coding; Prosodic Features; Machine Learning Algorithms. 1. Introduction
Applications of speaker recognition are becoming ubiquitous, especially after the increased terrorist activities around the world. Speech patterns can prove extremely useful in criminal investigation and litigation. Historically, a suspect’s voice has always provided cues about truthfulness, mental and emotional states, and level of intoxication. Accent and dialect has also given information about individual’s homeland [1]. Moreover speaker recognition can be useful to adapt the machines into their users because a speech interface, in a user's own language, is ideal as it is the most natural, flexible, efficient, and economical form of human communication. In recent years, there has been a booming interest in the use of biometric characteristics as a means of recognizing and identifying a person. Human voice is one of the most important biometric identifiers of a person. While speech recognition is concerned with extraction of linguistic message underlying a spoken utterance, speaker recognition is concerned with extraction of the identity of the person speaking the utterance. There are two types of speaker recognition systems:
If the text must be the same for enrollment and recognition then it is called text-dependent recognition. In a text dependent speaker recognition system, individual presents a fixed password or “prompted phrase” that is programmed into the system and can improve performance especially with cooperative users. Prompts can be common for all speakers or unique. Text independent technologies do not compare what was said at enrollment and recognition. Text independent system has no advance knowledge of the presenter’s phrasing and is much more flexible in situations where speaker is not cooperative. There are two main applications of speaker recognition: if the speaker claims to be of a certain identity and voice is used to verify this claim, this is called verification or authentication. On the other hand, identification is the task of determining an unknown speaker’s identity. Each speaker recognition system has two phases: enrollment and verification or identification. During enrollment, the speaker’s voice is recorded and a number of features are extracted to form a data set or template. In the second phase a speech sample or utterance is compared against a previously created template. For identification systems, the utterance is compared against multiple templates in order to determine best match while verification systems compare an utterance against a single template specific to a particular speaker under verification. Because of the process involved, verification is faster than identification. We propose ML algorithms for speaker recognition in which we use the values of extracted features for training of selected ML algorithms and trained model will be used for recognition of specific speaker.
2. Literature Survey
Speaker recognition is basically a pattern classification task preceded by feature extraction stage. Given a sequence of feature vectors representing a given test utterance, it is the job of the classifier to find out which speaker has produced this utterance. Several classifiers have been applied to the task of speaker recognition, many of which originate in speech recognition. Early methods of speaker recognition consisted of classifiers like Vector Quantization (VQ) [2], Dynamic Time Warping (DTW) [3], Hidden Markov Models (HMM) [4], and Gaussian Mixture Models (GMM) [5]. Though VQ classifier had success for speaker recognition, it suffered from the drawback that the search for the closest centroid within the codebook for large speaker population can be cumbersome. One way to alleviate this problem is to use tree structured VQ. However, the tradeoff in using tree structured VQ is that the search time will be reduced at the expense of optimal cluster assignment. The technique of DTW performed better for text dependent speaker recognition but since the method of template construction is inherently text dependent, is a drawback of DTW.
In [4] D.M. Weber et al. showed that the performance of HMM for speaker recognition was considerably better than VQ. However, if the nature of the speech is not the same as the given sample or the next phoneme in the word depends on more than just the previous state, then the recognition rate drops dramatically. Further training stage is time consuming. Recognition accuracies attained by GMM were quite promising, but for noisy environment, the performance of GMM degrades considerably. Further GMM require several minutes of training, which is not practical for real world applications. Other classifiers are neural networks such as multi layer perceptron, radial basis function network, decision trees such as C4, ID3 and CART. Neural networks learn complex mappings between input and output and are capable of solving much more complicated recognition tasks. They can handle low quality, noisy data. Another advantage of neural network is that they require smaller number of parameters than independent speaker models. Further we need not to train individual model to represent an individual speaker. Rather neural networks are trained to model decision functions which best discriminates the speakers with in a known set [5]. However, optimal neural architecture to solve a particular problem must be selected by trial, which is a drawback. Decision trees have an advantage over neural networks that they have self organizing architectures that do not have to be specified a priori as with neural networks. BayesNet are less sensitive to small data set size and are therefore more suited for environments that change rapidly.
recognition based on tracking Formant frequency trajectories. They used neural network and CART as classifier and neural network out performed CART with significantly less misclassification rate. R.V Pawar et al. in 2005 [9] proposed a text dependent speaker identification using neural networks. Linear prediction coefficients were extracted to form feature vector and results showed that system worked fine for identifying a speaker from number of different speakers. D. Gharavian et al. in 2007 [10] evaluated the effect of prosodic parameters such as pitch, formants on gender dependent speech recognition. Authors have shown that speech parameters as fundamental frequency, formants and their slopes are gender- dependent and appending these parameters to the feature vector can lead to improved recognition results.
T. Lalith Kumar et al. in 2009 [11] proposed a speaker dependent speech recognition system using MLP and RNN. Linear prediction coefficients were used as feature vector. Accuracy levels obtained during testing reveals that MLP’s recognition accuracies are better than RNN. We found that different features have been used to characterize the speaker’s voice which includes features like mel frequency cepstral coefficients, linear predictive coefficients, linear predictive cepstral coefficients, linear spectral frequency, formants and pitch [7]. This paper proposes a unique feature vector. Formant frequencies are the resonance frequencies of the vocal tract and are speaker dependent. Further, fundamental frequency is an important property of speech and it defines the periodicity of the speech signal. Its value is low for adult male speakers and high for female speakers and children. When speech utterances are carefully selected such that all the frames in an utterance are voiced, the fundamental frequency works reasonably well for speaker recognition [16]. They are efficient parameters to characterize a speaker’s voice, but none of the paper was found till date, using these prosodic features as a whole, for text dependent speaker recognition. Here we propose combination of first three formants with their corresponding amplitudes, fundamental frequency, duration of speech utterance and energy of the windowed section [12]. Linear predictive coding will be used for extraction of these features. Further we propose the use of ML classifier to overcome the drawbacks of traditional classifiers. We investigate and compare the performance of four machine learning algorithms namely MLP, RBFN, C4.5, and BayesNet in this work since these ML algorithms outperform all other ML algorithms in most of the applications. An improvement in recognition accuracy is expected by using these features along with ML algorithms.
3. Our Proposal
A speaker recognizer system comprises of two distinct blocks, a feature extractor and a recognizer. The Feature extractor block uses a LPC analysis technique, with the help of which we can translate the incoming speech into a feature space. After that, feature vector is input to the ML algorithm for recognition. The process to be followed is shown in Figure 1.
Figure 1: Speaker Recognizer
Speech samples from five adult speakers (two male and three female) were collected using microphone and standard PC sound card in-built in Dell Studio15. Speakers were asked to speak numerical digits three, seven, eight in normal speed, under normal conditions. Same microphone is used for all recordings. Speech signals were sampled at 22,050 Hz with 16 bits of precision. Speaker specific features: first three formants and their corresponding amplitudes and energy of windowed section were extracted from the speech samples by performing 18 pole LPC analysis on a single 10 ms speech segment taken right of cursor at highest amplitude in the waveform, so that number of features can be kept at minimum. Hamming window is used in order to prevent abrupt changes at the end points of segment.
Speech Signal
Acquisition
Feature Extractor
(LPC)
Recognizer
(ML Algorithm)
Fundamental frequency was computed using auto correlation method. For calculating duration, from each recorded speech sample silence period was removed and duration of speech utterance was determined. This was accomplished using COLEA [13]: A Matlab software tool for speech analysis. Thus for the purpose of recognition, the description of speech segment is based on following parameters/features:
Fundamental Frequency, F0 in Hz
F-pattern (F1, F2, F3) in Hz and their corresponding Amplitudes in Hz Energy in dB
Duration in milliseconds
Hence the total numbers of features are nine.
Dataset consists of fifteen utterances of numerical digits three, seven, and eight (five utterances for each digit) per person. For proper training of ML algorithms training instances were replicated. 60% of the instances were used for training and rest for testing the performance of ML algorithms. Main task to be considered is the performance analysis of four ML algorithms: MLP, RBFN, C4.5 decision tree, and BayesNet using prosodic features for determining the following:
1. Speaker recognition capability 2. Gender recognition capability
3. Impact of increase in number of speakers on the performance of ML algorithms
For ML algorithms we use Weka which is an open source simulator [14]. Weka is a java implementation of different ML algorithms being widely used by researchers. Performance analysis of ML algorithms will be done on the basis of the performance metrics: precision, recall, and miss classification rate which are explained below:
1. Precision: Defined as percentage of those instances that truly have class X, among all those classified as class X.
2. Recall: Defined as percentage of members of class X correctly classified as belonging to class X. 3. Misclassification Rate: It is the number of incorrectly identified instances divided by total number of
instances.
3.1.Linear Prediction of Speech
As speech interaction with computers increases for activities like telephonic financial transactions, information retrieval and control of entry into reserved areas, the requirement for recognizing persons on the basis of vocal characteristics increases. Moreover, speaker recognition is a biometric modality that uses an individual’s voice for recognition purposes. It relies on features influenced by both physical structure of an individual vocal tract and behavioral characteristics of an individual. Linear Predictive Coding which models human vocal tract has been successfully used and gives good speech feature estimations.
LPC provides extremely accurate estimates of speech parameters, and is relatively efficient for computation. It analyzes the speech signal by estimating the formants, removing their effects from the speech signal, and estimating the intensity and frequency of the remaining buzz. The basic problem of the LPC system is to determine the formants from the speech signal. The solution is a difference equation, which expresses each sample of the signal as a linear combination of previous samples. Such an equation is called a linear predictor [15]. The coefficients of the difference equation (the prediction coefficients) characterize the formants, so the LPC system needs to estimate these coefficients. The estimate is done by minimizing the mean-square error between the predicted signal and the actual signal. Linear prediction analysis of speech signal predicts a given speech sample at time n as a linear weighted sum of previous p samples,
̂
Where ̂ is the predicted sample at time n and is the speech sample at time n, and , k = 1, 2, ,….p are the predictor coefficients.
The prediction error is defined as
̂ (2)
The mean square of the prediction error over an analysis frame of N samples is given by
∑ (3)
Minimizing E with respect to the set of predictor coefficients results in a set of p normal equations. The predictor coefficients are obtained by solving this set of p normal equations.
3.2. Machine Learning Algorithms
3.2.1.
MLP
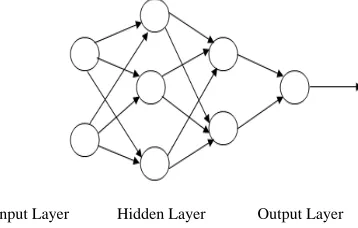
A Multilayer Perceptron is a multi-layer feed forward artificial neural network model that maps sets of input data onto a set of appropriate output. Each node in one layer connects with a certain weight wij to every node in the following layer. Learning occurs in the perceptron by changing connection weights after each piece of data is processed, based on the amount of error in the output compared to the expected result. This is an example of supervised learning, and is carried out through back propagation, a generalization of the least mean squares algorithm. Figure 2 show the architecture of MLP.
Input Layer Hidden Layer Output Layer
Figure 2: Multi Layer Perceptron Architecture
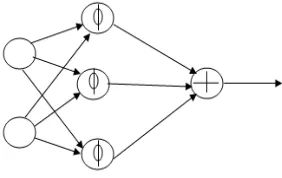
3.2.2 RBFN
Input Layer Hidden Layer Output Layer
Figure 3: RBF Neural Network Architecture
3.2.3 C4.5
C4.5 builds decision trees from set of labeled training data using the concept of information entropy. It uses the fact that each attribute of data can be used to make a decision by splitting the data into smaller subsets. The splitting procedure stops if all instances belong to the same class. Its criterion is the normalized information gain (difference in entropy) that results from choosing an attribute for splitting the data. The attribute with the highest normalized information gain is chosen to make the decision. Then a leaf node is created in the decision tree telling to choose that class. C4.5 can handle both continuous and discrete attributes, training data with missing attribute values.
3.24 Bayes Net
A Bayesian network, belief network or directed acyclic graphical model is a probabilistic graphical model that represents a set of random variables and their conditional independencies via a directed acyclic graph (DAG). Formally, Bayesian networks are directed acyclic graphs whose nodes represent random variables in the Bayesian sense: they may be observable quantities, latent variables, unknown parameters or hypotheses. Edges represent conditional dependencies; nodes which are not connected represent variables which are conditionally independent of each other. Each node is associated with a probability function that takes as input a particular set of values for the node's parent variables and gives the probability of the variable represented by the node. Efficient algorithms exist that perform inference and learning in Bayesian networks. Bayesian networks are less sensitive to small data set size and are therefore more suited for environments that change rapidly.
3.3.Experimental Results
In order to analyze the impact of increase in number of speakers (population size) on the performance of ML algorithms, speech samples from another five adult speakers (two females and three males) were collected and dataset was created using the specified method. ML algorithms were trained and tested on speech samples from ten speakers. PC used in feature extraction, training and testing has single Intel Core 2 Duo processor at 2.10 GHz with 3 GB of RAM and Windows 7 ultimate (32 bit) operating system.
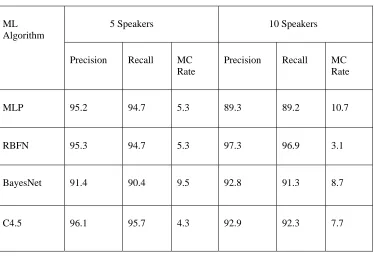
Table 1: Performance comparison of ML Algorithms for Speaker Recognition
*MC Rate: Misclassification Rate
Table 2 contains the details of the performance of machine learning algorithms for gender recognition capability. All results are in percentage.
Table 2: Gender Recognition Capability of ML Algorithms.
*MC Rate: Misclassification Rate
Observations of four ML algorithms for the testing performed on 40% of the dataset are shown in Table 1 and 2. The testing was done to determine the speaker recognition, gender recognition capability and impact of increase in number of speakers on the performance of ML algorithms. The experimental results clearly show that as far as
ML Algorithm
5 Speakers
10 Speakers
Precision Recall MC Rate
Precision Recall MC Rate
MLP 95.2 94.7 5.3 89.3 89.2 10.7
RBFN 95.3 94.7 5.3 97.3 96.9 3.1
BayesNet 91.4 90.4 9.5 92.8 91.3 8.7
C4.5 96.1 95.7 4.3 92.9 92.3 7.7
ML Algorithms
Male
Female
Precision Recall MC Rate Precision Recall MC Rate
MLP 97.2 97.2 2.8 98.4 98.4 1.6
RBFN 86.1 86.1 13.9 92.2 92.2 7.8
BayesNet 85.7 66.6 33.4 83.3 93.8 6.2
speaker recognition for a population size of five speakers is concerned, C4.5 gives lowest misclassification rate of 4.3%. However, for increased speaker population C4.5 performance degrades. RBFN gives better performance for increased speaker population with lowest misclassification rate of 3.1% and highest recognition accuracy of 96.9% as compared to other three ML algorithms. MLP outperforms other ML algorithms for gender recognition, with an MC rate of 2.8% for male, 1.6% for female recognition, and an overall misclassification rate of 2.2%. BayesNet performed least in comparison to the other three ML algorithms. This gender recognition capability was tested for a population of five speakers.
4.Conclusion and Future Scope
As far as speaker recognition is concerned, RBFN outperforms other ML algorithms, with an improvement in classification accuracy (or MC rate) as the number of speakers, the classifier has to recognize, increases. The classification accuracy of other ML algorithms degrades as the population size increases. MLP performs best for gender recognition with an overall misclassification rate of 2.2%. Thus for an application requiring both gender and speaker recognition MLP and RBFN can be used in combination.
Moreover, in order to further decrease the misclassification rate, emphasis can be laid on including more number of features, using hybrid feature set. Hybrid feature set can be a combination of prosodic features like formants, pitch with mel frequency cepstral coefficients or a combination of linear predictive coefficients with mel frequency cepstral coefficients. Performance improvement in Ml algorithms is expected by using more elaborate and large databases.
References
[1] Dennis C. Tanner, Matthew E. Tanner, “Forensic aspects of speech patterns: voice prints, speaker profiling, lie and intoxication detection”,
Learn How publishing, 2004.
[2] Kevin R. Farrell et al., “Speaker recognition using neural networks and conventional classifiers”, IEEE Transactions on Speech and Audio
Processing, vol. 2, Jan 1994, pp. 194-204.
[3] K. Yu et al., “Speaker recognition using hidden Markov models, dynamic time warping, and vector quantization”, in Proc. Image Signal
Process, vol. 142, Oct 1995, pp. 313-318.
[4] D.M. Weber et al., “A comparison between hidden Markov models and vector quantization for speech independent speaker recognition”,
IEEE Comsig, 1993, pp. 139-144.
[5] Douglas A. Reynolds et al., “Robust text-independent speaker identification using Gaussian mixture speaker models”, IEEE Transactions
on Speech and Audio Processing, vol.3, Jan 1995, pp. 72-83.
[6] Chularat Tanprasert et al., “Text-dependent speaker identification using neural network on distinctive Thai tone marks”, Technical Journal,
vol.1, Jan-Feb 2000, pp. 249-253.
[7] Hassen Seddik et al., “Text independent speaker recognition based on attack state formants and neural network classification”, IEEE
International Conference on Industrial Technology, 2004, pp. 1649-1653.
[8] Mohammad M. Tanabian et al., “Automatic speaker recognition with formant trajectory using CART and neural networks”, IEEE, May
2005, pp. 1225-1228.
[9] R.V Pawar et al., “Speaker identification using neural networks”, World Academy of Science, Engineering and Technology, 2005, pp.
31-35.
[10] D. Gharavian et al., “Statistical evaluation of the effect of gender on prosodic parameters and their influence on gender dependent speech
recognition”, IEEE ICICS, 2007.
[11] T. Lalith et al., “Speech recognition using neural networks”, IEEE International Conference on Signal Processing Systems, 2009, pp.
248-252.
[12] L. Cremer, “The acoustics of speech”, in Proceedings of Third International Congress on Acoustics, Stuttgart, 1959, pp. 3-16.
[13] COLEA: A Matlab Software Tool for Speech Analysis “http://www.utdallas.edu/~loizou/speech/colea.htm”
[14] Weka, “http://www.utdallas.edu/~loizou/speech/colea.htm”.
[15] S. Sengupta, “Lecture 11: Computational aspects of LPC parameters”, Lecture Series on Digital Voice & Picture Communication, IIT
Khragpur, India.