Exploiting In-network Processing for Big Data Management
Lukas Rupprecht
supervised by Dr. Peter Pietzuch Department of Computing
Imperial College London Expected Graduation Date 2016
[email protected]
ABSTRACT
Data processing systems face the task of efficiently storing and processing data at petabyte scale, with the amount set to increase in the future. To meet such a requirement, highly scalable, shared-nothing systems, e.g. Google’s BigTable [6] or Facebook’s Cassandra [14], are built to partition data and process it in parallel on distributed nodes in a clus-ter. This allows the handling of data at scale but introduces new challenges due to the distribution of data. Running queries involves a high network overhead because data has to be exchanged between cluster nodes and hence, the net-work becomes a critical part of the system. To avoid the network bottleneck, it is essential for distributed data pro-cessing systems (DDPS) to be aware of the network rather than treating it as a black box.
We propose in-network processing as a way of achieving
network-awareness to decrease bandwidth usage by custom routing, redundancy elimination, and on-path data reduc-tion. Thereby, we can increase the query throughput of a DDPS. The challenges of an in-network processing system range from design issues, such as performance and trans-parency, to the integration with query optimisation and de-ployment in data centres. We formulate these challenges as possible research directions and provide a prototype im-plementation. Our preliminary results suggest that we can significantly improve query throughput in a DDPS by per-forming partial data reduction within the network.
Categories and Subject Descriptors
H2.4 [Database Management]: Systems—Distributed Databases
General Terms
Design, Experimentation, Performance
Keywords
NoSQL, Scale-out, Date Centres, Network-Awareness
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
SIGMOD’13 PhD Symposium, June 23, 2013, New York, NY, USA.
Copyright 2013 ACM 978-1-4503-2155-6/13/06 ...$15.00.
1.
INTRODUCTION
Increasing amounts of data generated by both research and industry have led to what is commonly known as Big Data. Data processing systems need to be able to manage data in the range of petabytes which traditional scale-up ap-proaches cannot deliver at reasonable cost. Hence, highly scalable data management systems based on distributed, shared-nothing architectures are developed, such as Google’s BigTable [6] or Facebook’s Cassandra [14] on the storage layer and Apache’s MapReduce framework Hadoop [1] or its data warehousing extension Hive [23] for efficient processing. The idea is to partition the data and store it at multiple, dis-tributed nodes in a cluster. To be scalable, the nodes do not share any state and hence, the cluster can be easily scaled out by adding new nodes. Query processing follows a scat-ter/gather pattern, i.e. queries are split into subqueries by a master node and dispatched to workers that execute on the partitions in parallel. The partial results are then combined by the master. We use the term distributed data processing system (DDPS) for such systems.
While the scale-out approach enables dealing with large data sets, it poses new problems. The higher the degree of distribution, the more network communication is required to run a query, and the network becomes the bottleneck for DDPSs. In BigTable, for example, random read workloads have a significantly lower performance compared to random writes or sequential reads, as they involve the most data to transfer [6]. The authors of [21] show that a 10% share of distributed transactions in a given workload already causes a 50% drop in transaction throughput compared to a workload without distributed transactions. Legler et al. [15] report a performance decrease as they scale out their system due to networking overhead. The presented system is the basis for their distributed main memory database HANA [10], hence, scaling properties of HANA are limited.
Especially for distributed main memory systems, network performance is critical because the disk is removed as the major bottleneck and local processing time is reduced by several orders of magnitude. To fully leverage this perfor-mance gain, a low latency, high bandwidth network is re-quired [20]. The RAMCloud project [19] achieves this by deploying high-end Infiniband networking hardware but this becomes expensive in a large data centre. H-Store [13] tries to provide low transaction latency by minimising the net-work traffic of a transaction, which requires complex parti-tioning schemes [21].
To remove the network bottleneck, we propose to make DDPSs network-aware. A network-aware DDPS does not
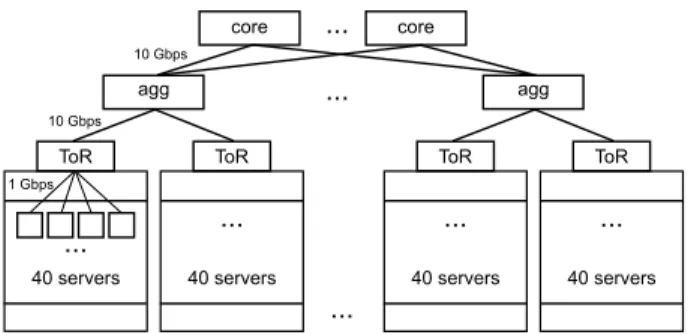
40 servers ToR 40 servers ToR agg 10 Gbps 40 servers ToR 40 servers ToR agg core core ... ... ... 10 Gbps ... 1 Gbps ... ... ...
Figure 1: Typical three-tiered network tree in a data centre
treat the network as a black box but rather exploits its topology and hardware for the benefit of query processing. We focus on DDPSs which are deployed in a data centre, i.e. a closed, static environment that provides more control over the network. In particular, we introduce an in-network processing approach as a means to reduce traffic, save band-width, and thereby increase query processing throughput. Implementing such an approach entails several research chal-lenges: (i) how to make the approach transparent and con-venient to use with an existing DDPS; (ii) how it affects query processing and optimisation; and (iii) how data cen-tre providers can integrate it with their infrastructure.
The paper is structured as follows. In Section 2 we intro-duce typical data centre networks and also present related work. Section 3 analyses research directions for achieving network-awareness in DDPSs. We then introduce the archi-tecture of an in-network query processing system (Section 4) and present preliminary results for a DDPS, enhanced with in-network processing (Section 5). Section 6 discusses future work and Section 7 concludes our proposal.
2.
BACKGROUND
As we focus on DDPSs deployed in data centres, we will first give a short overview of data centre networks.
2.1
Data Centre Networks
A typical data centre consists of tens of thousands com-modity servers organised in racks and interconnected in a tree-like network topology (see Figure 1). Each rack has atop-of-rack (ToR) switch that connects the nodes within the rack and is connected to an aggregation switch. To pro-vide paths between all pairs of racks, another layer of core switches exists. To save hardware costs, data centre net-works are oftenoversubscribed [2], i.e. switches are not able to support the full incoming aggregate bandwidth. Thus, nodes have to reduce the rate at which they send or receive. Consider the example in Figure 1. The maximum incom-ing bandwidth at a ToR switch is 40 Gbps but the available bandwidth to the aggregation switch is only 10 Gbps. Hence, the rack servers can only utilise 1/4 of their bandwidth.
2.2
Problem Statement
We look at the example of a MapReduce job where map-pers acquire and prepare the necessary data from the dis-tributed storage layer and then shuffle it to the different re-ducers that perform the actual computation. The communi-cation cost during this shuffle phase is inO(n2). The trans-fer rates for the exchanges are a major limiting factor for the
runtime of a job because lower rates mean longer execution. For small queries the effect is negligible but when operat-ing on large data amounts, the impact becomes significant. Thus, the oversubscription property of data centre networks is a major obstacle for achieving high performance. Upgrad-ing the network to provide more bandwidth is the simplest solution to increase the performance of DDPSs, however, the cost-benefit ratio quickly becomes infeasible.
2.3
Related Work
To remove the network bottleneck at less cost, different approaches are proposed by the research community. We identify three directions, i.e. approaches that change the net-work architecture, ones that perform data reduction already on partial results, and ones that consider the network topol-ogy and its resources.
Data centre networking. Altering the network archi-tecture to provider better network performance is a common and well-studied approach. Al-Fares et al. [2] interconnect servers in a fat-tree topology which provides full bisection bandwidth at reasonable cost. VL2 [11] focuses on flow iso-lation and flexibility. High link capacity between all pairs of servers is achieved by deploying a Clos network topology, similar to the fat-tree. BCube [12] targets modular data centres and uses a recursively defined, cube-like topology to provide high bandwidth for different communication pat-terns. The main drawback of these approaches is that they increase wiring complexity, making them more difficult to implement. Furthermore, they cannot prevent the bottle-neck at the end-host duringN-to-1 communication.
Partial data reduction. Several systems exist that per-form reduction on partial results to reduce traffic and save bandwidth. Dremel [17] uses execution trees to run queries. Partial results are gathered from the leaves and are aggre-gated on intermediate nodes as they move up to the mas-ter which requires full end-to-end communication. In Cam-doop [7], Costa et al. exploit the CamCube network topol-ogy for MapReduce jobs. During the shuffle phase, data traverses several servers before it arrives at the reducers. These intermediate servers already perform part of the re-ducers’ work. Camdoop relies on a special network topology which makes it hard to deploy in existing data centres. Gi-gascope [9] is a stream database that supports simple filter operations directly on NICs. This reduces traffic before it reaches the actual processing units. Compared to our pro-posed approach, Gigascope’s reduction is limited to simple functions that NICs can support (e.g. packet filtering). The sensor networks community also uses logical trees to per-form partial aggregation. For example, Malhotra et al. [16] introduce dominating set trees which consider the physical network topology and can reduce transmission cost by up to 70% for MAX queries. The tree is an overlay network and no in-network aggregation is performed.
Network considerations. VM placement in data cen-tres is a field that already considers the impact of network-ing. Meng et al. [18] formulate a traffic-aware VM place-ment problem by considering the traffic matrix among VMs in order to minimise traffic. CloudNaaS [4] is a framework that allows users to specify network properties, e.g. middle-box deployment, and its network-aware VM placement algo-rithm enables the support of 10% more applications. This kind of network consideration is similar to network-aware data partitioning and placement but only aims at minimising
traffic, not reducing it. Among data management systems, RamCube [24] leverages a BCube topology to provide fast fault recovery and high fault tolerance while Microsoft’s SQL Azure [5] uses knowledge of networking facilities to provide high availability. Again, both systems do not reduce traffic and increase network performance.
3.
NETWORK-AWARENESS
We present our main ideas on how to remove the network bottleneck in a DDPS by making it network-aware. Recall that network-awareness exploits the network topology and hardware to increase performance. We identify three direc-tions towards this goal.
In-network processing.
In-network processing utilises net-working hardware to perform application specific tasks. This can reduce traffic and thereby increase the performance of a DDPS in different ways.(i) Custom routing/multicast. Write queries, such as an update transaction, require nodes that store the involved data, to be notified and reach consensus. This procedure involves the sending of many duplicate messages. By repli-cating these messages as late as possible on the network path (similar to a multicast), bandwidth utilisation decreases.
(ii) Network redundancy elimination. Network re-dundancy elimination is a successful technique to improve network performance by caching the payload of frequently sent packets [3]. Implementing this approach for a DDPS requires data to be cached at higher granularity, i.e. tuples, key-value pairs, or even whole tables. The result is an in-network cache that can significantly reduce traffic.
(iii) In-network processing. During a read query, data needs to be shipped between the involved nodes. As these queries typically involve data reduction, e.g. joins, selects, or top-k filtering, the amount of transferred data can be reduced by performing this reduction already along the net-work path. Partial results that travel on similar paths can be combined and reduced to require less bandwidth.
To add this functionality to the networking hardware, switches can be either programmed directly or extended with
side cars[22]. Side cars are dedicated devices, that are con-nected to a switch via a direct link and receive all traffic that traverses the switch. Traffic can then be altered in various ways, e.g. redirected, reduced, or replicated. This provides a software-only approach to custom networking and allows to implement arbitrary processing within the network.
Distributed query optimisation.
Network-awareness alsoinfluences distributed query optimisation. The query op-timiser now must consider knowledge of the physical net-work topology and the above described in-netnet-work process-ing functionality. Cost models that include network traffic should account for on-path data reduction and bandwidth utilisation as they influence the decision on what data to ship where. For example, it might be beneficial to move larger data chunks to locations which store less data if these chunks can be reduced on-path more efficiently. To integrate in-network processing with query optimisation is especially challenging for Big Data applications because these usually consist of complex software stacks, e.g. HDFS + Hadoop + Mahout, instead of a single solution. An interesting ques-tion is whether network-awareness needs to be present at all the layers in order to enable effective query optimisation.
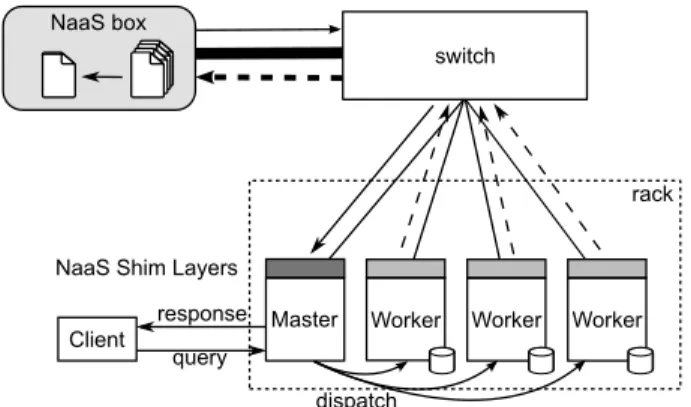
switch NaaS box
dispatch
Master Worker
NaaS Shim Layers
rack
Worker Worker
Client query response
Figure 2: Architecture and data flow for a NaaS-enhanced DDPS
Management complexity.
A basic question fornetwork-aware DDPSs is how data centre providers can enable net-work-awareness for tenants. Tenants should be able to im-plement custom processing functionality within the network but they cannot connect their own, physical in-network pro-cessing devices to switches in the data centre. Hence, a bal-ance needs to be found between a generic in-network pro-cessing system, which supports basic operations but does not allow for any customisation at all, and an environment, which can be programmed freely by users.
Closely related to management aspects is data placement. In a virtualised environment, such as a data centre, ten-ants cannot control on which physical machines their data is stored. However, this is important, especially for a network-aware DDPS, as the information on the distribution of data, the topology, and the existence of in-network processing de-vices is part of the input of a query optimiser. Hence, it is necessary for providers to create appropriate interfaces that make this information available without sacrificing manage-ment flexibility.
4.
IN-NETWORK PROCESSING DESIGN
Our first step towards a network-aware DDPS is to design an architecture for an in-network processing system and im-plement it as a prototype. The prototype is able to per-form partial data reduction and thereby decrease the band-width usage of queries. We call our systemNaaS (Network-as-a-Service) [8]. Figure 2 shows its main architecture. We choose a software-only approach to custom networking because programmable switches have a low-level interface, which makes it difficult to expose to users, and they are ex-pensive. Additionally, the approach allows users to easily implement arbitrary data reduction functions, tailored for various DDPSs. To support the full aggregation bandwidth, the processing device, calledNaaS box, is connected to the switch via a high bandwidth link. This approach is both cost effective and scalable because only one high-end link is needed per switch and no extra wiring costs arise.
Example.To convey the main idea behind our approach, we consider a typical DDPS data flow as depicted in Fig-ure 2. We assume 1 Gbps Ethernet connections for the rack servers and 10 Gbps for the NaaS box. A client submits a query to a master that collects the required data by dis-patching subqueries to worker nodes which in return send their response back to the master. Without NaaS, the
0 20 40 60 80 100 120
filter sort levenshtein
#processed requests (1000s)
aggregation function NaaS
Solr
(a) Request throughput in 120s
0 1 2 3 4 5 16 32 48 64 80 96 0 5 10 15 20 25 30
avg throughput (Gbps) avg requests/second
avg response size (KB) NaaS throughput
Solr throughput NaaS requests/second Solr requests/second
(b) Effect of different workloads
0 0.5 1 1.5 2 2.5 3 3.5 100% 90% 80% 70% 60% 50% avg throughput (Gbps) aggregation overhead NaaS Solr
(c) Effect of aggregation cost Figure 3: Results for the comparison between the NaaS-enhanced and Solr-only set-up
ers can only send responses with 1/3 Gbps as the link to the master has a limited capacity of 1 Gbps. With NaaS, all traffic at the switch is rerouted through the NaaS box and due to the available 10 Gbps, workers can now send at the full 1 Gbps. Since data is reduced on the NaaS box, less data per query arrives at the master and hence, more queries can be supported. Additionally, the NaaS box takes away re-duction computation from the master node. The node can use these spare resources to accept and process more queries which can further improve query throughput.
In order to perform data reduction at rates of 10 Gbps, the NaaS box has several requirements: (i) it needs to have sufficient computational resources to support processing on large data sets. That means that it needs to be hosted by a powerful, multi-core machine; (ii) it has to be highly effi-cient, i.e. processing must be parallelised, no unrelated tasks are allowed to run concurrently, and network communica-tion must not incur a large overhead; and (iii) it needs to be transparent for the supported DDPS, so that no changes to the system are required, and generic, such that various DDPSs can be supported easily.
To meet the third requirement, we add shim layers to the cluster nodes. The shim layers are responsible for re-routing traffic through NaaS boxes and hiding this detour from the application. They are located between the application and the socket layer and intercept all incoming/outgoing traffic. Interception on the socket layer allows us to avoid overhead from application protocols (e.g. Hadoop uses HTTP for com-munication), as no specific server software needs to run and no headers need to be parsed. Additionally, as sockets op-erate on byte streams, communication between shim layers and NaaS boxes can be performed via a lightweight binary protocol. Shim layers provide multiple interfaces which can be implemented to support different applications.
5.
PRELIMINARY RESULTS
To evaluate our NaaS architecture we measure the query throughput in set-ups with and without a NaaS environ-ment. Additionally, we investigate the average query pro-cessing rates a NaaS box can support and analyse the ad-vantage of a NaaS-enhanced set-up in the case when there is no oversubscription in the original network. As a sample DDPS we use the Apache Solr server1 which supports dis-tributed keyword search. A typical Solr query requests the 1http://lucene.apache.org/solr/
topkXML documents matching a set of specified keywords
with a data flow equal to that described in Section 4. Our set-up consists of one Solr frontend (= master), six backends (= worker), all of them having 1 Gbps connections, and one NaaS box with a 10 Gbps connection. The workload is generated by 75 clients which continuously submit queries to the frontend. All queries are equal to prevent throughput variations caused by random queries and the backends store the same data to balance the load between them.
We use three different reduction functions throughout the evaluation. The first one is a random filter that filters 90% of all result documents, the second one sorts all documents by title and then applies the random filter (to keep the work-load comparable) and the third function computes the Lev-enshtein distance between all pairs of titles and then filters. Note that in the set-up without NaaS, the Solr frontend also computes these functions on the result documents to have a comparable workload to the NaaS box.
We first observe the query throughput with and without NaaS. Each query requests 200 documents and we measure the number of processed queries in 120s. Figure 3(a) shows the results. For cheap reduction (filtering and sorting) we can improve the request throughput with NaaS by more than five times due to the higher rates, at which the back-ends are able to send responses. As reduction becomes more expensive (Levenshtein), the number of processed requests decreases as most of the NaaS box’s resources are needed for the computation and hence, fewer requests can be pro-cessed. The Solr throughput stays constant as the request rate is so low that the additional cost for the Levenshtein computation does not exhaust the machine.
To directly compare Solr to NaaS, we connect the fron-tend to the switch via a 10 Gbps connection. Figure 3(b) shows the average throughput and the client’s request rates, for different numbers of queried documents, i.e. different re-sponse sizes, and the random filter reduction. NaaS and Solr perform almost equal by reaching an average throughput of 3.6 Gbps. The request rates decrease with increasing re-sponse sizes as more data is shipped and hence less requests generate a higher throughput. Around 64 KB, the through-put suddenly drops which might be due to fragmentation on the networking layer.
To demonstrate the benefit of NaaS boxes in an oversub-scription-free set-up, we evaluate the throughput for differ-ent costs of the reduction function. We vary the cost of the Levenshtein function by only computing the distance
between a specified percentage of pairs. Results are shown in Figure 3(c). For very expensive aggregation, Solr and NaaS perform equal because both hit the limit of computa-tional resources. For light aggregation they are equal due to the network becoming the bottleneck as too many pack-ets arrive, i.e. too many interrupts need to be handled by one CPU core (receive livelock). For in-between costs we see that NaaS achieves higher throughputs because the frontend has more resources to process requests.
In summary, a NaaS architecture can significantly increase query throughput. Compared to a network without oversub-scription, NaaS still provides a benefit because computation is taken away from master nodes. In a scenario with multi-ple racks, the NaaS solution is inexpensive as only one high speed connection is required per rack.
6.
FUTURE WORK
Our future work follows the directions in Section 3. The first milestone is to provide a NaaS architecture that fully meets the requirements of DDPSs. This includes support for native multicast for transactions, replication, etc., network redundancy elimination, and support for stream processing to enable query processing in the range of tera- or petabytes. Deploying a NaaS architecture in a tree-topology, such as presented in Section 2.1, will also be part of this work.
After that we will investigate the integration of in-network processing and query optimisation. This will include the de-velopment of a network-aware optimisation model and the integration of this model with a DDPS. We will also explore at which layer in the DDPS stack network-aware optimisa-tion should exist.
Throughout our work, we will consider management com-plexity. We intend to find a trade-off between the optimal degree of information and what a data centre provider is willing to expose to tenants.
7.
CONCLUSIONS
We argued that network-awareness is crucial for modern DDPSs because data amounts are increasing and processing has to be parallelised on distributed nodes to cope with these amounts. A network-aware DDPS can make optimal use of the network by performing in-network processing. We pre-sented research directions to achieve network-awareness and demonstrated with a prototype in-network processing archi-tecture that we can significantly improve query throughput and hence, performance. Our experience with our prototype shows that, in order to be completely transparent, a detailed understanding of the supported application is required. We believe that the combination of data management systems and networking is a promising approach to increase the per-formance of DDPSs. Many exciting research questions arise and the result can contribute to the goal of having more scalable solutions to handle the increasing data amounts.
8.
REFERENCES
[1] Apache hadoop.http://hadoop.apache.org/. [2] M. Al-Fares, A. Loukissas, and A. Vahdat. A scalable,
commodity data center network architecture. In
SIGCOMM, 2008.
[3] A. Anand, V. Sekar, and A. Akella. Smartre: an architecture for coordinated network-wide redundancy elimination. InSIGCOMM, 2009.
[4] T. Benson, A. Akella, A. Shaikh, and S. Sahu. Cloudnaas: a cloud networking platform for enterprise applications. InSOCC, 2011.
[5] D. G. Campbell, G. Kakivaya, and N. Ellis. Extreme scale with full sql language support in microsoft sql azure. InSIGMOD, 2010.
[6] F. Chang, J. Dean, S. Ghemawat, et al. Bigtable: A distributed storage system for structured data.TOCS, 26(2), 2008.
[7] P. Costa, A. Donnelly, A. Rowstron, et al. Camdoop: Exploiting in-network aggregation for big data applications. InUSENIX NSDI, 2012.
[8] P. Costa, M. Migliavacca, P. Pietzuch, et al. NaaS: Network-as-a-Service in the cloud. InHotICE, 2012. [9] C. Cranor, T. Johnson, O. Spataschek, et al.
Gigascope: A stream database for network applications. InSIGMOD, 2003.
[10] F. F¨arber, S. Cha, J. Primsch, et al. SAP HANA database: data management for modern business applications.SIGMOD Record, 40(4), 2012. [11] A. Greenberg, J. Hamilton, N. Jain, et al. VL2: a
scalable and flexible data center network. In
SIGCOMM, 2009.
[12] C. Guo, G. Lu, D. Li, et al. Bcube: a high
performance, server-centric network architecture for modular data centers. InSIGCOMM, 2009.
[13] R. Kallman, H. Kimura, J. Natkins, et al. H-store: a high-performance, distributed main memory
transaction processing system.VLDB Endowment, 1(2), 2008.
[14] A. Lakshman and P. Malik. Cassandra - a
decentralized structured storage system.OSR, 44(2), 2010.
[15] T. Legler, W. Lehner, and A. Ross. Data mining with the SAP NetWeaver BI accelerator. InVLDB, 2006. [16] B. Malhotra, M. A. Nascimento, and I. Nikolaidis.
Better tree-better fruits: using dominating set trees for max queries. InDMSN, 2008.
[17] S. Melnik, A. Gubarev, J. Long, et al. Dremel: interactive analysis of web-scale datasets.VLDB Endowment, 3(1), 2010.
[18] X. Meng, V. Pappas, and L. Zhang. Improving the scalability of data center networks with traffic-aware virtual machine placement. InINFOCOM, 2010. [19] D. Ongaro, S. M. Rumble, R. Stutsman, et al. Fast
crash recovery in ramcloud. InSOSP, 2011. [20] J. Ousterhout, P. Agrawal, D. Erickson, et al. The
case for RAMClouds: scalable high-performance storage entirely in DRAM.OSR, 43(4), 2010. [21] A. Pavlo, C. Curino, and S. Zdonik. Skew-aware
automatic database partitioning in shared-nothing, parallel oltp systems. InSIGMOD, 2012.
[22] A. Shieh, S. Kandula, and E. Sirer. Sidecar: building programmable datacenter networks without
programmable switches. InHotNets, 2010. [23] A. Thusoo, J. S. Sarma, N. Jain, et al. Hive: a
warehousing solution over a map-reduce framework.
VLDB Endowment, 2(2), 2009.
[24] Y. Zhang, C. Guo, R. Chu, et al. Ramcube: exploiting network proximity for ram-based key-value store. In