Independence Assumptions Considered Harmful
A l e x a n d e r F r a n z
S o n y C o m p u t e r S c i e n c e L a b o r a t o r y &: D 2 1 L a b o r a t o r y S o n y C o r p o r a t i o n
6-7-35 K i t a s h i n a g a w a S h i n a g a w a - k u , T o k y o 141, J a p a n
a m I © c s l , s o n y . c o . j p
A b s t r a c t
Many current approaches to statistical lan- guage modeling rely on independence a.~- sumptions 1)etween the different explana- tory variables. This results in models which are computationally simple, but which only model the main effects of the explanatory variables oil the response vari- able. This paper presents an argmnent in favor of a statistical approach that also models the interactions between the ex- planatory variables. The argument rests on empirical evidence from two series of ex- periments concerning automatic ambiguity resolution.
1 I n t r o d u c t i o n
In this paper, we present an empirical argument in favor of a certain approach to statistical natural lan- guage modeling: we advocate statistical natural lan- guage models that account for the interactions be- tween the explanatory statistical variables, rather than relying on independence a~ssumptions. Such models are able to perform prediction on the basis of estimated probability distributions that are properly conditioned on the combinations of the individual values of the explanatory variables.
After describing one type of statistical model that is particularly well-suited to modeling natural lan- guage data, called a loglinear model, we present ein- pirical evidence fi'om a series of experiments on dif- ferent ambiguity resolution tasks that show that the performance of the loglinear models outranks the performance of other models described in the lit- erature that a~ssume independence between the ex- planatory variables.
2 S t a t i s t i c a l L a n g u a g e M o d e l i n g By "statistical language model", we refer to a mathe- matical object that "imitates the properties" of some respects of naturM language, and in turn makes pre- dictions that are useful from a scientific or engineer-
ing point of view. Much recent work in this flame- work hm~ used written and spoken natural language data to estimate parameters for statisticM models that were characterized by serious limitations: mod- els were either limited to a single explanatory vari- able or. if more than one explanatory variable wa~s considered, the variables were assumed to be inde- pendent. In this section, we describe a method for statistical language modeling that transcends these limitations.
2.1 C a t e g o r i c a l D a t a A n a l y s i s
Categorical data analysis is the area of statistics that addresses categorical statistical variable: variables whose values are one of a set of categories. An exam- pie of such a linguistic variable is PART-OF-SPEECH, whose possible values might include nou.n, verb, de- terminer, preposition, etc.
We distinguish between a set of explanatory vari- ames. and one response variable. A statistical model can be used to perforin prediction in the following manner: Given the values of the explanatory vari- ables, what is the probability distribution for the response variable, i.e.. what are the probabilities for the different possible values of the response variable?
2.2 T h e C o n t i n g e n c y Table
Tile ba,sic tool used in categorical data analysis is the contingency table (sometimes called the "cross- classified table of counts"). A contingency table is a matrix with one dimension for each variable, includ- ing the response variable. Each cell ill the contin- gency table records the frequency of data with the appropriate characteristics.
2.3 T h e L o g l i n e a r M o d e l
A loglinear model is a statistical model of the effect of a set of categorical variables and their combina- tions on the cell counts in a contingency table. It can be used to address the problem of sparse data. since it can act a.s a "snmothing device, used to obtain cell estimates for every cell in a sparse array, even if the observed count is zero" (Bishop, Fienberg, and Holland. 1975).
Marginal totals (sums for all values of some vari- ables) of the observed counts are used to estimate the parameters of the loglinear model; the model in turn delivers estimated expected cell counts, which are smoother than the original cell counts.
The mathematical form of a loglinear model is a,s follows. Let mi5~ be the expected cell count for cell ( i . j . k . . . . ) in the contingency table. The general form of a loglinear model is ms follows:
logm/j~... = u.-{-ltlti).-~lt2(j)-~-U3(k)-~lZl2(ij)-~-.. . ( 1 )
In this formula, u denotes the mean of the logarithms
of all the expected counts, u + u l ( 1 ) denotes the mean
of the logarithms of the expected counts with value
i of the first variable, u + u2(j) denotes the mean of the logarithms of the expected counts with value j of the second variable, u + ux~_(ii) denotes the mean of the logarithms of the expected counts with value i of the first veriable and value j of the second variable, and so on.
Thus. the term uzii) denotes the deviation of the mean of the expected cell counts with value i of the first variable from the grand mean u. Similarly, the term
Ul2(ij)
denotes the deviation of the mean of the expected cell counts with value i of the first variable and value j of the second variable from the grand mean u. In other words, ttl2(ij) represents the com- bined effect of the values i and j for the first and second variables on the logarithms of the expected cell counts.In this way, a loglinear model provides a way to estimate expected cell counts that depend not only on the main effects of the variables, but also on the interactions between variables. This is achieved by adding "interaction terms" such a.s U l 2 ( i j ) t o the nmdel. For further details, see (Fienberg, 1980).
2.4 T h e I t e r a t i v e E s t i m a t i o n P r o c e d u r e
For some loglinear models, it is possible to obtain closed forms for the expected cell counts. For more complicated models, the iterative proportional fitting algorithm for hierarchical loglinear models (Denting and Stephan, 1940) can be used. Briefly, this proce- dure works ms follows.
Let the values for the expected cell counts that are estimated by the model be represented by the sym- bol 7hljk .... The interaction terms in the loglinear
nmdels represent constraints on the estimated ex- pected marginal totals. Each of these marginal con- straints translates into an adjustment scaling factor for the cell entries. The iterative procedure has the following steps:
1. Start with initial estimates for the estimated ex- pected cell counts. For example, set all 7hijal = 1.0.
2. Adjust each cell entry by multiplying it by the scaling factors. This moves the cell entries to- wards satisfaction of the marginal constraints specified by the nmdel.
3. Iterate through the adjustment steps until the maximum difference e between the marginal totals observed in the sample and the esti- mated marginal totals reaches a certain mini- mum threshold, e.g. e = 0.1.
After each cycle, the estimates satisfy the con- straints specified in the model, and the estimated expected marginal totals come closer to matching the observed totals. Thus. the process converges. This results in Maximum Likelihood estimates for both multinomial and independent Poisson sampling schemes (Agresti, 1990).
2.5 M o d e l i n g I n t e r a c t i o n s
For natural language classification and prediction tasks, the aim is to estimate a conditional proba- bility distribution P ( H [ E ) over the possible values of the hypothesis H, where the evidence E consists of a number of linguistic features el, e2 . . . Much of the previous work in this area assumes independence between the linguistic features:
P(/-/le~.ej . . . . ) ~ P ( H l e l ) x P ( H l e j ) x ... (2)
For example, a model to predict Part-of-Speech of a word on the basis of its morphological affix and its capitalization might a.ssume independence between the two explanatory variables a,s follows:
P(POSIAFFIX, CAPITALIZATION) ,,~ (3)
P(POSIAFFIX ) x P(POSICAPITALIZATION )
This results ill a considerable computational sim- plification of the model but, as we shall see below. leads to a considerable loss of information and con- comitant decrease in prediction accuracy. With a loglinear model, on the other hand. such indepen- dence assumptions are not necessary. The loglinear model provides a posterior distribution that is prop- erly conditioned on the evidence, and maximizing the conditional probability P ( H I E ) leads to mini- mum error rate classification (Duda and Hart. 1973).
s
3 P r e d i c t i n g P a r t - o f - S p e e c h
We will now t u r n to the empirical evidence s u p p o r t - ing the a r g u m e n t against i n d e p e n d e n c e a s s u m p t i o n s . ~ In this section, we will c o m p a r e two m o d e l s for pre- e ~ d i c t i n g the P a r t - o f - S p e e c h of an unknown word: A ~ simple m o d e l t h a t t r e a t s the various e x p l a n a t o r y variables ms i n d e p e n d e n t , and a model using log- linear s m o o t h i n g of a c o n t i n g e n c y table t h a t takes into a c c o u n t the i n t e r a c t i o n s between the e x p l a n a - t o r y variables.
3 . 1 C o n s t r u c t i n g t h e M o d e l
T h e m o d e l wa~s c o n s t r u c t e d in the following way. F i r s t , features t h a t could be used to guess the P U S of a word were d e t e r m i n e d b y examining the t r a i n i n g p o r t i o n of a text corpus. T h e initial set of features consisted of the following:
• INCLUDES-NUMBER. Does the word include a nunlber?
• CAPITALIZED. Is the word in s e n t e n c e - i n i t i a l po- sition and capitalized, in any other p o s i t i o n a n d capitalized, or in lower ca~e?
• INCLUDES-PERIOD. Does the word include a pe- riod?
• INCLUDES-COMMA. Does the word include a c o l n l n a ?
• FINAL-PERIOD. Is the last c h a r a c t e r of the word a p e r i o d ?
• INCLUDES-HYPHEN. Does the word include a h y p h e n ?
• ALL-UPPER-CASE. Is the word in all u p p e r case? • SHORT. Is the length of the word three charac-
ters or less?
• INFLECTION. Does the word c a r r y one of the English inflectional suffixes?
• PREFIX. Does the word c a r r y one of a list of frequently occurring prefixes?
• SUFFIX. Does the word c a r r y one of a list of frequently occurring suffixes?
Next, e x p l o r a t o r y d a t a analysis was perfornled in o r d e r to d e t e r m i n e relevant features and their values, a n d to a p p r o x i m a t e which features interact. E a c h word of the training d a t a was then t u r n e d i n t o a feature vector, and the feature vectors were cross- classified in a contingency table. T h e c o n t i n g e n c y table was s m o o t h e d using a loglinear models.
3 . 2 D a t a
T r a i n i n g and evaluation d a t a was o b t a i n e d from the P e n n T r e e b a n k Brown corpus (Marcus, Santorini, a n d Marcinkiewicz, 1993). The c h a r a c t e r i s t i c s of "'rare" w o r d s t h a t might show up ms unknown words differ fi'om the c h a r a c t e r i s t i c s of words in general. so a two-step procedure wa~ employed a first t i m e
Overall Accuracy
i .
4 L~hnem¢ F ~ t g f ~ _ _ , . . . , o _9 L~llnQ&¢ ~ O a t u ¢ ~
8
.
F=0.4 Set Accuracy
. . . . 4 maeo,tnaom Flalu,~ [ i 4 LOgL'/~III 9 l.~Jl~ar v u l u , u ~omtur~ j i
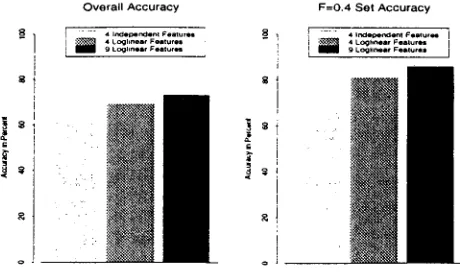
F i g u r e 1: P e r f o r m a n c e of Different M o d e l s
to o b t a i n a set of "'rare" words ms t r a i n i n g d a t a , a n d a g a i n a second time to o b t a i n a s e p a r a t e set of "'rare*" words ms evMuation data. T h e r e were 17,000 words in the t r a i n i n g d a t a , and 21,000 words in the evalua- tion d a t a . A m b i g u i t y resolution a c c u r a c y was evalu- a t e d for the "'overall accuracy" ( P e r c e n t a g e t h a t the m o s t likely P U S tag is correct), a n d "'cutoff factor a c c u r a c y " ( a c c u r a c y of the a n s w e r set consisting of all P U S t a g s whose p r o b a b i l i t y lies within a factor F of the m o s t likely P U S (de Marcken, 1990)).
3 . 3 A c c u r a c y R e s u l t s
(Weischedel et al., 1993) describe a m o d e l for un- known words t h a t uses four features, b u t t r e a t s the f e a t u r e s ms i n d e p e n d e n t . We r e i m p l e m e n t e d this model by using four features: POS, INFLECTION, CAPITALIZED, and HYPHENATED, In Figures i 2, the results for this model are labeled 4 I n d e p e n - d e n t F e a t u r e s . For comparison, we c r e a t e d a log- l i n e a r m o d e l with the same four features: the results for this m o d e l are labeled 4 L o g l i n e a r F e a t u r e s .
T h e h i g h e s t accuracy was o b t a i n e d by the log- linear m o d e l t h a t includes all two-way interac- tions a n d consists of two c o n t i n g e n c y tM)les with the following features: P O S , ALL-UPPER-CASE. HYPHENATED, INCLUDES-NUMBER, CAPITALIZED, INFLECTION, SHORT. PREFIX, and SUFFIX. The re- sults for this m o d e l are lM)eled 9 L o g l i n e a r F e a - t u r e s . T h e p a r a m e t e r s for all three u n k n o w n word m o d e l s were e s t i m a t e d from the training d a t a . and the m o d e l s were evaluated on the e v a l u a t i o n d a t a .
[image:3.612.310.540.39.175.2]o
o
o o
• .-- . . . ~ .. . . o- . . . o .. . . o .. . . .
• - - L°glmea'wlt F ~ t ~ e = ]
1 2 3 4 5 6 7
N ~ o l Features
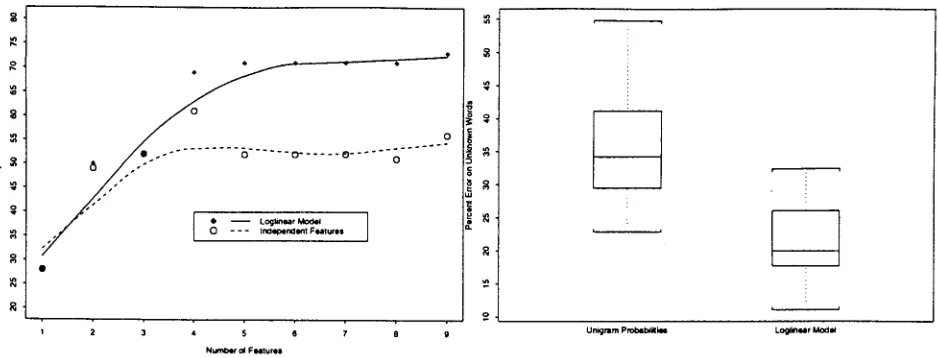
F i g u r e 2: Effect of N u m b e r of F e a t u r e s on A c c u r a c y $
o
Uregmm P r o ~ e x e ~ k o g ~ r Mce.~
F i g u r e 3: E r r o r R a t e on U n k n o w n W o r d s
features f u r t h e r improves this score.
3 . 4 E f f e c t o f N u m b e r o f F e a t u r e s o n A c c u r a c y
T h e p e r f o r m a n c e of the loglinear m o d e l can be im- proved by a d d i n g more features, b u t this is n o t pos- sible w i t h the simpler nmdel t h a t assumes i n d e p e n - dence between the features. F i g u r e 2 shows the p e r f o r m a n c e of the two t y p e s of nmdels with fen- ture sets t h a t ranged from a single f e a t u r e to nine features.
As the d i a g r a m shows, the accuracies for b o t h m e t h o d s rise with the first few features, b u t then the two m e t h o d s show a clear divergence. T h e ac- c u r a c y of the simpler m e t h o d levels off a r o u n d a t a r o u n d 50-55%, while the loglinear m o d e l reaches an a c c u r a c y of 70-75%. This shows t h a t the loglin- ear m o d e l is able to tolerate r e d u n d a n t features and use i n f o r m a t i o n from more features t h a n the s i m p l e r m e t h o d , a n d therefore achieves b e t t e r results a t am- b i g u i t y resolution.
3.5 A d d i n g C o n t e x t t o t h e M o d e l
Next, we a d d e d of a s t o c h a s t i c P O S t a g g e r ( C h a r - niak et al., 1993) to provide a model of c o n t e x t . A s t o c h a s t i c P O S tagger assigns P O S labels to words in a sentence by using two p a r a m e t e r s :
• L e x i c a l P r o b a b i l i t i e s : P ( w l t ) - - the p r o b a - b i l i t y of observing word w given t h a t the t a g t occurred.
• C o n t e x t u a l P r o b a b i l i t i e s : P ( t i [ t i - 1 , t~_2) - - the p r o b a b i l i t y of o b s e r v i n g t a g ti given t h a t the two previous tags ti-1, t,i--2 occurred.
T h e t a g g e r maximizes the p r o b a b i l i t y of the t a g se- quence T = t.l,t, 2 . . . . ,t.,, given the word sequence
W = w z , w 2 , . . . , w , , , which is a p p r o x i m a t e d a.s fol- lows:
I"L
P(TIW) ~ I I P(wdt~)P(tdt~_~, ti_=)
(4)
i = 1
T h e a c c u r a c y of the c o m b i n a t i o n of the loglinear m o d e l for local features and the s t o c h a s t i c P O S tag- ger for c o n t e x t u a l features was e v a l u a t e d e m p i r i c a l l y by c o m p a r i n g three m e t h o d s of h a n d l i n g unknown words:
• U n i g r a m : Using the prior p r o b a b i l i t y distri- b u t i o n P ( t ) of the P O S tags for rare words. • P r o b a b U i s t i c U W M : Using the p r o b a b i l i s t i c
m o d e l t h a t assumes i n d e p e n d e n c e between the features.
• C l a s s i f i e r U W M : Using the loglinear model for u n k n o w n words.
S e p a r a t e sets of training and e v a l u a t i o n d a t a for the t a g g e r were o b t a i n e d from from the P e n n T r e e b a n k Wall S t r e e t corpus. E v a l u a t i o n of the c o m b i n e d sys- t.em was p e r f o r m e d on different configurations of the P O S t a g g e r on 30-40 different s a m p l e s c o n t a i n i n g 4,000 words each.
Since the t a g g e r displays c o n s i d e r a b l e variance in its a c c u r a c y in assigning P O S to u n k n o w n words in c o n t e x t , we use b o x p l o t s to d i s p l a y the results. Fig- ure 3 c o m p a r e s the tagging error r a t e on unknown words for the u n i g r a m m e t h o d (left) a n d the log- linear m e t h o d with nine features (labeled s t a t i s t i - c a l c l a s s i f i e r ) at right. This shows t h a t the Ioglin- ear m o d e l significantly improves the P a r t - o f - S p e e c h tagging a c c u r a c y of a stochastic t a g g e r on unknown words. T h e m e d i a n error rate is lowered consider- ably, and s a m p l e s with error rates over 32% are elim- i n a t e d entirely.
[image:4.612.66.535.46.225.2]o =
==
• P m O ~ ¢ UWM • Logli~e= UWM
o u , * = *
• • • = a
• o °° 08°
0 S tO 15 2Q 25 30 35 40 4S 50 SS 60
Peeclntage ol Unknown WO~=
Figure 4: Effect of Proportion of Unknown Words on Overall Tagging Error Rate
3.6 E f f e c t o f P r o p o r t i o n o f U n k n o w n W o r d s
Since most of the lexical ambiguity resolution power of stochastic PUS tagging comes from the lexical probabilities, unknown words represent a significant source of error. Therefore, we investigated the effect of different types of models for unknown words on the error rate for tagging text with different propor- tions of unknown words.
Samples of text that contained different propor- tions of unknown words were tagged using the three different methods for handling unknown words de- scribed above. The overall tagging error rate in- creases significantly as the proportion of new words increases. Figure 4 shows a graph of overall tagging accuracy versus percentage of unknown words in the text. The graph compares the three different meth- ods of handling unknown words. The diagram shows that the loglinear model leads to better overall tag- ging performance than the simpler methods, with a clear separation of all samples whose proportion of new words is above approximately 10%.
4
Predicting P P
A t t a c h m e n t
In the second series of experiments, we compare the performance of different statistical models on the task of predicting Prepositional Phrase (PP) attach- ment.
4.1 F e a t u r e s for P P A t t a c h m e n t
First, an initial set of linguistic features that could be useful for predicting P P attachment was deter- mined. The initial set included the following fea- tures:
• PREPOSITION. Possible values of this feature in- clude one of the more frequent prepositions in
the training set, or the value
other-prep.
* VERB-LEVEL. Lexical association strength be- tween the verb and the preposition.
• N O U N - L E V E L . Lexical association strength be- tween the noun and the preposition.
• NOUN-TAG. Part-of-Speech of the nominal at- tachment site. This is included to account for correlations between attachment and syntactic category of the nominal attachment site, such as "PPs disfavor attachment to proper nouns."
• NOUN-DEFINITENESS. Does the nominal attach- ment site include a definite determiner? This feature is included to account for a possible cor- relation between P P attachment to the nom- inal site and definiteness, which was derived by (Hirst, 1986) from the principle of presup- position minimization of (Craln and Steedman, 1985).
• PP-OBJECT-TAG. Part-of-speech of the object of the PP. Certain types of P P objects favor at- tachment to the verbal or nominal site. For ex- ample, temporal PPs, such as
"in 1959",
where the prepositional object is tagged CD (cardi- nal), favor attachment to the VP, because tile VP is more likely to have a temporal dimension. The association strengths for VERB-LEVEL and NOUN-LEVEL were measured using the Mutual In- formation between the noun or verb, and the prepo- sition. 1 The probabilities were derived ms Maximum Likelihood estimates from all P P cases in the train- ing data. The Mutual Information values were or- dered by rank. Then, the a~ssociation strengths were categorized into eight levels (A-H), depending on percentile in the ranked Mutual Information values.4.2 E x p e r i m e n t a l D a t a a n d E v a l u a t i o n
Training and evaluation data was prepared from the Penn treebank. All 1.1 million words of parsed text in the Brown Corpus, and 2.6 million words of parsed WSJ articles, were used. All instances of PPs that are attached to VPs and NPs were extracted. This resulted in 82,000 PP cases from the Brown Corpus, and 89,000 PP cases from the WS.] articles. Verbs and nouns were lemmatized to their root forms if the root forms were attested in the corpus. If the root form did not occur in the corpus, then the inflected form was used.
All the P P cases from the Brown Curl)us, and 50,000 of the WSJ cases, were reserved ms training data. The remaining 39,00 WSJ P P cases formed the evaluation pool. In each experiment, performance
[image:5.612.73.309.44.226.2]o 1
|
u
R ~ m A ~ j l l o n H f r , 3 ~ & Roolh kog~eaw ~ a k ~ r
1
!
o
o
ol
°t
Ii
o!
l l
o
Figure 5: Results for Two Attachment Sites Figure 6: Three Attachment Sites: Right Associa- tion and Lexical Association
was evaluated oil a series of 25 random samples of 100 PP cases fi'om the evaluation pool. in order to provide a characterization of the error variance.
4.3 E x p e r i m e n t a l R e s u l t s : T w o A t t a c h m e n t s Sites
Previous work oll automatic PP attachment disam- biguation has only considered the pattern of a verb phrase containing an object, and a final PP. This lends to two possible attachment sites, the verb and the object of the verb. The pattern is usually further simplified by considering only the heads of the possi- ble attachment sites, corresponding to the sequence "Verb Noun1 Preposition Noun2".
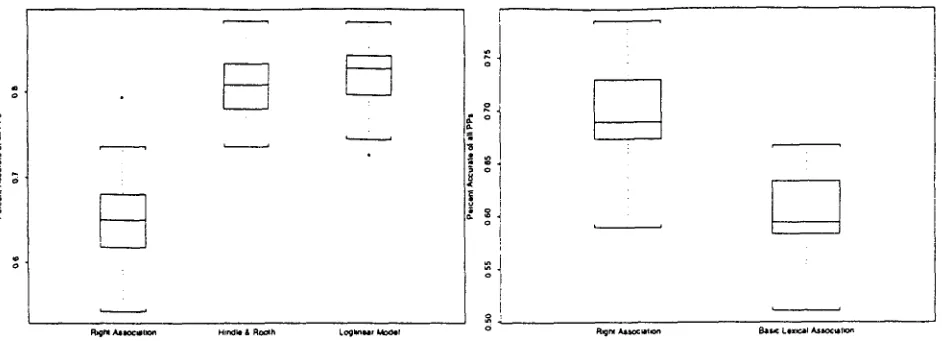
The first set of experiments concerns this pattern. There are 53,000 such cases in the training data. and 16,000 such cases in the evaluation pool. A number of methods were evaluated on this pattern accord- ing to the 25-sample scheme described above. The results are shown in Figure 5.
4.3.1 B a s e l i n e : R i g h t A s s o c i a t i o n
Prepositional phrases exhibit a tendency to attach to the most recent possible attachment site; this is referred to ms the principle of "'Right Association". For the "V NP PP'" pattern, this means preferring attachment to the noun phra~se. On the evaluation samples, a median of 65% of the PP cases were at- tached to the noun.
4.3.2 R e s u l t s o f Lexical A s s o c i a t i o n
(Hindle and R ooth. 1993) described a method for obtaining estimates of lexical a.ssociation strengths between nouns or verbs and prepositions, and then using lexical association strength to predict. P P at- tachment. In our reimplementation of this lnethod. the probabilities were estimated fi'om all the P P cases in the training set. Since our training data
are bracketed, it was possible to estimate tile lexi- cal associations with much less noise than Hindle & R ooth, who were working with unparsed text. The median accuracy for our reimplementation of Hindle & Rooth's method was 81%. This is labeled "Hindle & Rooth'" in Figure 5.
4.3.3 R e s u l t s o f t h e L o g l i n e a r M o d e l The loglinear model for this task used the features
PREPOSITION. VERB-LEVEL, NOUN-LEVEL, and
NOUN-DEFINITENESS, and it included all second-
order interaction terms. This model achieved a me- dian accuracy of 82%.
Hindle & Rooth's lexical association strategy only uses one feature (lexical aasociation) to predict P P attachment, but. ms the boxplot shows, the results from the loglinear model for the "V NP PP" pattern do not show any significant improvement.
4.4 E x p e r i m e n t a l R e s u l t s : T h r e e A t t a c h m e n t Sites
As suggested by (Gibson and Pearlmutter. 1994), P P attachment for the "'Verb NP PP" pattern is relatively easy to predict because the two possible attachment sites differ in syntactic category, and therefore have very different kinds of lexical pref- erences. For example, most PPs with
of
attach to nouns, and most PPs with f,o andby
attach to verbs. In actual texts, there are often more than two possi- ble attachment sites for a PP. Thus, a second, more realistic series of experiments was perforlned that investigated different PP attachment strategies for the pattern "'Verb Noun1 Noun2 Preposition Noun3"' that includes more than two possible attachment sites that are not syntactically heterogeneous. There were 28,000 such cases in the training data. and 8000 ca,~es in the evaluation pool. [image:6.612.63.534.46.219.2]"5 o
RIgN AUCCUII~ Split HinOle & Rooln Lo~l~ur M0~el
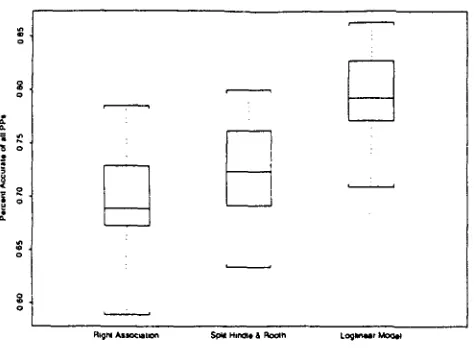
Figure 7: Summary of Results for Three Attachment Sites
4.4.1 Baseline: R i g h t A s s o c i a t i o n
As in the first set of experiments, a number of methods were evaluated an the three attachment site pattern with 25 samples of 100 random P P cases. The results are shown in Figures 6-7. The baseline is again provided by attachment according to the principle of "Right Attachment'; to the nmst recent possible site, i.e. attaclunent to Noun2. A median of 69% of the P P cases were attached to Noun2.
4 . 4 . 2 R e s u l t s o f Lexical A s s o c i a t i o n
Next, the lexical association method was evalu- ated on this pattern. First. the method described by Hindle & Rooth was reimplemented by using the lexical association strengths estimated from all P P cases. The results for this strategy are labeled "Basic Lexical Association" in Figure 6. This method only achieved a median accuracy of 59%, which is worse than always choosing the rightmost attachment site. These results suggest that Hindle & R.ooth's scoring function worked well in the "'Verb Noun1 Preposi- tion Noun2"' case not only because it was an accurate estimator of lexical associations between individual verbs/nouns and prepositions which determine P P attachment, but also because it accurately predicted the general verb-noun skew of prepositions.
4.4.3 R e s u l t s o f E n h a n c e d L e x i c a l A s s o c i a t i o n
It seems natural that this pattern calls for a com- bination of a structural feature with lexical associa- tion strength. To implement this, we modified Hin- dle & Rooth's method to estimate attachments to the verb, first noun. and second noun separately. This resulted in estimates that combine the struc- tural feature directly with the lexical association strength. The modified method performed better
than the original lexical association scoring function, but it still only obtained a median accuracy of 72%. This is labeled "Split Hindle & Rooth" in Figure 7.
4 . 4 . 4 R e s u l t s o f L o g l i n e a r M o d e l
To create a model that combines various structural and lexical features without indepen- dence assumptions, we implemented a loglinear model that includes the variables VERB-LEVEL FIRST-NOUN-LEVEL. and SECOND-NOUN-LEVEL. 2 The loglinear model also includes the variables PREPOSITION and PP-OBJECT-TAG. It, was smoothed with a loglinear model that includes all second-order interactions.
This method obtained a median accuracy of 79%; this is labeled "Loglinear Model" in Figure 7. As the boxplot shows, it performs significantly better than the methods that only use estimates of lexical a,~so- clarion. Compared with the "'Split Hindle Sz Rooth'" method, the samples are a little less spread out, and there is no overlap at all between the central 50% of the samples from the two methods.
4.5 D i s c u s s i o n
The simpler "V NP PP" pattern with two syntacti- cally different attachment sites yielded a null result: The loglinear method did not perform significantly better than the lexical association method. This could mean that the results of the lexical associa- tion method can not be improved by adding other features, but it is also possible that the features that could result in improved accuracy were not identi- fied.
The lexical association strategy does not perform well on the more difficult pattern with three possible attachment sites. The loglinear model, on the other hand, predicts attachment with significantly higher accuracy, achieving a clear separation of the central 50% of the evaluation samples.
5 C o n c l u s i o n s
We have contrasted two types of statistical language models: A model that derives a probability distribu- tion over the response variable that is properly con- ditioned on the combination of the explanatory vari- able, and a simpler model that treats the explana- tory variables as independent, and therefore models the response variable simply a~s the addition of the individual main effects of the explanatory variables.
[image:7.612.74.311.35.210.2]The experimental results show that, with the same feature set, inodeling feature interactions yields bet- ter performance: such nmdels achieves higher accu- racy, and its accura~,y can be raised with additional features. It is interesting to note that modeling vari- able interactions yields a higher perforlnanee gain than including additional explanatory variables.
While these results do not
prove
that modeling feature interactions is necessary, we believe that they provide a strong indication. This suggests a mlmber of avenues for filrther research.First, we could a t t e m p t to improve the specific models that were presented by incorporating addi- tional features, and perhal)S by taking into account higher-order features. This might help to address the performance gap between our models and hu- man subjects that ha,s been documented in the lit- erature, z A more ambitious idea would be to use a statistical model to rank overall parse quality for en- tire sentences. This would be an improvement over schemes that a,ssnlne independence between a num- ber of individual scoring fimctions, such ms (Alshawi and Carter, 1994). If such a model were to include only a few general variables to account for such fea- tures a.~ lexical a.ssociation and recency preference for syntactic attachment, it might even be worth- while to investigate it a.s an approximation to the human parsing mechanism.
R e f e r e n c e s
Agresti, Alan. 1990.
Categorical Data Analysis.
.John Wiley & Sons, New York.
Alshawi, Hiyan and David Carter. 1994. Training and scaling preference functions for disambigua- tion.
Computational Linguistics,
20(4):635-648. Bishop. Y. M., S. E. Fienberg, and P. W. Holland.1975.
Discrete Multivariate Analysis: Th, eory and
Practice.
M I T Press, Cambridge, MA.Charniak, Eugene, Curtis Hendrickson, Neil ,Jacob- son, and Mike Perkowitz. 1993. Equations for part-of-speech tagging. In
AAAI-93,
pages 784~ 789.Church, Kenneth W. and Patrick Hanks. 1990. Word a,~soeiation norms, mutual information, and lexicography.
Computational Linguistics,
16(1):22-29.
Crain, Stephen and Mark 3. Steedman. 1985. On not being led up the garden path: The use of
3For cXaml)l(', If random s(;ntcnc(;s with "V('rb NP PP" (:~(:s from th(: Penn tr(',(;l)ank aa'(: tak(:n ms the gohl standard, then (Hindlc and Rooth, 1993) and (Ratna- l)arkhi, Ryn~r, aal(t Roukos. 1994) rcl)ort that human, (:xi)(;rts using only hca(t words obtain 85%-88% a('cu- ra~:y. If the huma~l CXl)erts arc allow(:d to consult the whoh," scntcn(:(:, their accuracy judged against random Trc(}l)ank s(',ntclm(:s rises to al)l)roximatcly 93%.
context by the psychological syntax processor. In David R. Dowty, Lauri Karttunen, and An- rnold M. Zwicky, editors,
Natural Language Pars-
ing,
pages 320-358, Cambridge, UK. CambridgeUniversity Press.
de Marcken, Carl G. 1990. Parsing the LOB corpus.
In Proceedings of A CL-90,
pages 243-251. Deming, W. E. and F. F. Stephan. 1940. On a lea.stsquares adjustment of a sampled frequency ta- ble when the expected marginal totals are known.
Ann. Math. Statis,
(11):427--444.Duda, Richard O. and Peter E. Hart. 1973.
Pattern
Classification and Scene Analysis.
John Wiley & Sons, New York.Fienberg, Stephen E. 1980.
Th.e Analysis of Cross-
Classified Categorical Data.
The M I T Press, Cambridge, MA, second edition edition.Franz, Alexander. 1996.
Automatic Ambiguity Res-
olution in Natural Language Processing.
volume 1171 ofLecture Notes in Artificial Intelligence.
Springer Verlag, Berlin.
Gibson, Ted and Neal Pearhnutter. 1994. A corpus- ba,sed analysis of psycholinguistic constraints on P P attachment. In Charles Clifton Jr., Lyn Frazier, and Keith Rayner, editors,
Perspectives
on Sentence Processing.
Lawrence Erlbaum Asso- ciates.Hindle, Donald and Mats Rooth. 1993. Structural ambiguity and lexical relations.
Computational
Linguistics,
19( 1 ): 103-120.Hirst, Graeme. 1986.
Semantic Interpretation and
the Resolution of Ambiguity.
Cambridge Univer- sity Press, Cambridge.Marcus, Mitchell P., Beatrice Santorini, and Mary Ann Marcinkiewicz. 1993. Building a large annotated corpus of English: The Penn Treebank.
Computational Linguistics,
19(2):313-330. Ratnaparkhi, Adwait, Jeff B ynar, and SalimRoukos. 1994. A m a x i m u m entropy model for Prepositional Phra,se attachment. In
ARPA
Workshop
on Human Language Technology.
Plainsboro, N.], March 8-11.
Weischedel, Ralph, Marie Meteer, Richard Schwartz, Lance Ramshaw, and Jeff Palmucci. 1993. Cop- ing with ambiguity and unknown words through probabilistic models.
Computational Linguistics,
19(2):359-382.