Automatic Word Sense D i s c r i m i n a t i o n
H i n r i c h S c h { i t z e *
Xerox Palo Alto Research Center
This paper presents context-group discrimination, a disambiguation algorithm based on cluster- ing. Senses are interpreted as groups (or clusters) of similar contexts of the ambiguous word. Words, contexts, and senses are represented in Word Space, a high-dimensional, real-valued space in which closeness corresponds to semantic similarity. Similarity in Word Space is based on second-order co-occurrence: two tokens (or contexts) of the ambiguous word are assigned to the same sense cluster if the words they co-occur with in turn occur with similar words in a training corpus. The algorithm is automatic and unsupervised in both training and application: senses are induced from a corpus without labeled training instances or other external knowledge sources. The paper demonstrates good performance of context-group discrimination for a sample of natural and artificial ambiguous words.
1. Introduction
Word sense disambiguation is the task of assigning sense labels to occurrences of an a m b i g u o u s word. This p r o b l e m can be d i v i d e d into two subproblems: sense discrimi- nation and sense labeling. Sense discrimination divides the occurrences of a w o r d into a n u m b e r of classes b y d e t e r m i n i n g for a n y two occurrences w h e t h e r they b e l o n g to the same sense or not. Sense labeling assigns a sense to each class, and, in c o m b i n a t i o n with sense discrimination, to each occurrence of the a m b i g u o u s word. This view of disambiguation as a two-stage process m a y not be c o m p l e t e l y general (for example, it m a y not be a p p r o p r i a t e for the iterative process b y w h i c h a lexicographer arrives at the sense divisions of a dictionary entry), b u t it seems applicable to m o s t w o r k on disambiguation in c o m p u t a t i o n a l linguistics.
In this paper, we will address the p r o b l e m of sense discrimination as defined above. That is, w e will not be c o n c e r n e d with the sense-labeling c o m p o n e n t of w o r d sense disambiguation. Word sense discrimination is easier than full disambiguation since w e n e e d only d e t e r m i n e w h i c h occurrences h a v e the same m e a n i n g a n d not w h a t the m e a n i n g actually is. Focusing solely on w o r d sense discrimination also liberates us of a serious constraint c o m m o n to other w o r k on w o r d sense disambiguation. If sense labeling is p a r t of the task, an outside source of k n o w l e d g e is necessary to define the senses. Regardless of w h e t h e r it takes the f o r m of dictionaries (Lesk 1986; G u t h r i e et al. 1991; Dagan, Itai, a n d Schwall 1991; Karov a n d E d e l m a n 1996), thesauri (Yarowsky 1992; Walker and Amsler 1986), bilingual c o r p o r a (Brown et al. 1991; C h u r c h a n d Gale 1991), or hand-labeled training sets (Hearst 1991; Leacock, Towell, a n d Voorhees 1993; N i w a and Nitta 1994; Bruce a n d Wiebe 1994), p r o v i d i n g i n f o r m a t i o n for sense definitions can be a considerable b u r d e n .
W h a t m a k e s o u r a p p r o a c h u n i q u e is that, since we n a r r o w the p r o b l e m to sense discrimination, we can dispense of an outside source of k n o w l e d g e for defining senses.
Computational Linguistics Volume 24, Number 1
We therefore call o u r a p p r o a c h automatic w o r d sense discrimination, since w e d o not require m a n u a l l y constructed sources of knowledge.
In m a n y applications, w o r d sense disambiguation m u s t b o t h discriminate a n d la- bel occurrences; for example, in o r d e r to find the correct translation of an a m b i g u o u s w o r d in m a c h i n e translation or the right p r o n u n c i a t i o n in a text-to-speech system. The application of interest to us is i n f o r m a t i o n access, i.e., m a k i n g sense of a n d find- ing i n f o r m a t i o n in large text databases. For m a n y p r o b l e m s in i n f o r m a t i o n access, it is sufficient to solve the discrimination p r o b l e m only. In one study, w e m e a s u r e d d o c u m e n t - q u e r y similarity b a s e d on w o r d senses rather than w o r d s a n d a c h i e v e d a considerable i m p r o v e m e n t in ranking relevant d o c u m e n t s a h e a d of n o n r e l e v a n t doc- u m e n t s (Schi.itze and P e d e r s e n 1995). Since the m e a s u r e m e n t of similarity is a system- internal process, n o reference to externally d e f i n e d senses n e e d be made. A n o t h e r potentially beneficial application of w o r d sense discrimination in i n f o r m a t i o n access is the design of interfaces that take account of ambiguity. If a user enters a q u e r y that contains an a m b i g u o u s w o r d , a s y s t e m capable of discrimination can give examples of the different senses of the w o r d in the text database. The user can t h e n decide w h i c h sense was i n t e n d e d a n d only d o c u m e n t s w i t h the i n t e n d e d sense w o u l d be retrieved. Again, a reference to external sense definitions is not required for this task.
The algorithm we p r o p o s e in this p a p e r is c o n t e x t - g r o u p d i s c r i m i n a t i o n . 1 Context- g r o u p discrimination g r o u p s the occurrences of an a m b i g u o u s w o r d into clusters, w h e r e clusters consist of contextually similar occurrences. Words, contexts, a n d clus- ters are r e p r e s e n t e d in a high-dimensional, real-valued vector space. C o n t e x t vectors capture the i n f o r m a t i o n p r e s e n t in s e c o n d - o r d e r co-occurrence. Instead of f o r m i n g a context representation f r o m the w o r d s that the a m b i g u o u s w o r d directly occurs w i t h in a particular context (first-order co-occurrence), w e f o r m the context represen- tation from the w o r d s that these w o r d s in t u r n co-occur w i t h in the training corpus. S e c o n d - o r d e r co-occurrence i n f o r m a t i o n is less sparse a n d m o r e robust than first-order information.
In c o n t e x t - g r o u p discrimination, the context of each occurrence of the a m b i g u o u s w o r d in the training c o r p u s is r e p r e s e n t e d as a context vector f o r m e d f r o m second- order co-occurrence information. The context vectors are t h e n clustered into c o h e r e n t g r o u p s such that occurrences j u d g e d similar according to s e c o n d - o r d e r co-occurrence are assigned to the same cluster. Clusters are r e p r e s e n t e d b y their centroids, the av- erage of their elements. An occurrence in a test text is d i s a m b i g u a t e d b y c o m p u t i n g the s e c o n d - o r d e r representation of the relevant context, a n d assigning it to the cluster w h o s e centroid is closest to that representation. Since the choice of representation influ- ences the f o r m a t i o n of clusters, w e will e x p e r i m e n t w i t h several representations in this paper, some involving a dimensionality r e d u c t i o n using singular v a l u e d e c o m p o s i t i o n (SVD).
C o n t e x t - g r o u p discrimination can be generalized to do a discrimination task that goes b e y o n d the n o t i o n of sense that underlies m a n y other contributions to the dis- a m b i g u a t i o n literature. If the a m b i g u o u s w o r d ' s occurrences are clustered into a large n u m b e r n of clusters (e.g., n = 10), t h e n the clusters can capture fine contextual distinc- tions. C o n s i d e r the e x a m p l e of space. For a small n u m b e r of clusters, only the senses " o u t e r space" a n d "limited extent in one, two, or three d i m e n s i o n s " are separated. If the w o r d ' s occurrences are clustered into m o r e clusters, t h e n finer distinctions such as the one b e t w e e n "office space" a n d "exhibition space" are also discovered. N o t e that differences b e t w e e n sense entries in dictionaries are often similarly fine-grained.
Schiitze Automatic Word Sense Discrimination
I WORD I
TRAINING TEXT [VECTORS I WORD SPACE
- - - - T : x x O x ! ~x [] x i /
L. Xx~." '...x.
... ",TEST CONTEXT /
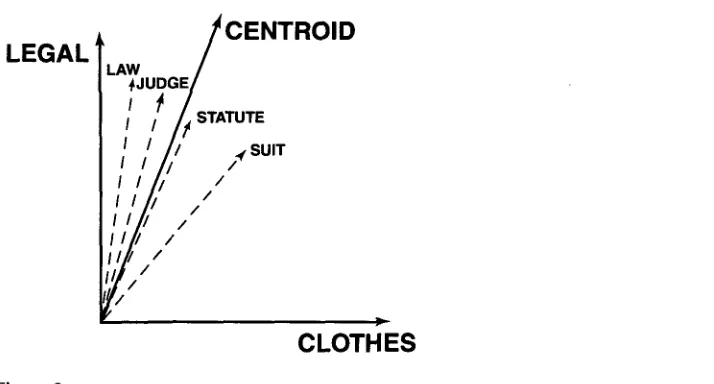
Figure 1
The basic design of context-group discrimination. Contexts of the ambiguous word in the training set are mapped to context vectors in Word Space (upper dashed arrow) by summing the vectors of the words in the context. The context vectors are grouped into clusters (dotted lines) and represented by sense vectors, their centroids (squares). A context of the ambiguous word ("test context") is disambiguated by mapping it to a context vector in Word Space (lower dashed arrow ending in circle). The context is assigned to the sense with the closest sense vector (solid arrow).
Even if the contextual distinctions c a p t u r e d b y generalized context-group discrimina- tion do not line u p perfectly with finer distinctions m a d e in dictionaries, they still help characterize the contextual m e a n i n g in w h i c h the a m b i g u o u s w o r d is used in a partic- ular instance. Such a characterization is useful for the information-access applications described above, a m o n g others.
The basic idea of context-group discrimination is to i n d u c e senses from contextual similarity. There is some e v i d e n c e that contextual similarity also plays a crucial role in h u m a n semantic categorization. Miller and Charles (1991) f o u n d evidence in several e x p e r i m e n t s that h u m a n s d e t e r m i n e the semantic similarity of w o r d s from the similar- ity of the contexts they are used in. We h y p o t h e s i z e that, b y extension, senses are also based on contextual similarity: a sense is a g r o u p of contextually similar occurrences of a word.
The following sections describe the disambiguation algorithm, o u r evaluation, a n d the results of the algorithm for a test set d r a w n from the New York Times N e w s Wire, and discuss the relevance of o u r a p p r o a c h in the context of other w o r k on w o r d sense disambiguation.
2. Context-Group D i s c r i m i n a t i o n
Context-group discrimination g r o u p s a set of contextually similar occurrences of an a m b i g u o u s w o r d into a cluster, w h i c h is then interpreted as a sense. The particular im- p l e m e n t a t i o n of this idea described here m a k e s use of a high-dimensional, real-valued vector space. C o n t e x t - g r o u p discrimination is a corpus-based method: all representa- tions are d e r i v e d from a large text corpus.
[image:3.468.44.328.60.182.2]Computational Linguistics Volume 24, Number 1
possible. The resulting clusters are delimited b y d o t t e d lines in the figure. Each cluster is a s s u m e d to c o r r e s p o n d to a sense of the a m b i g u o u s w o r d (an a s s u m p t i o n to be e v a l u a t e d later). The representative of each g r o u p is its centroid, depicted as a square. After training, a n e w occurrence of the a m b i g u o u s w o r d (labeled "test context" in the figure) is d i s a m b i g u a t e d b y m a p p i n g its context to Word Space (see l o w e r d a s h e d line; the context's p o i n t is depicted as a circle). The context is then assigned to the context g r o u p w h o s e centroid is closest (solid arrow). Finally, the context is categorized as being a use of the sense c o r r e s p o n d i n g to this context group.
There are three types of entities that w e n e e d to represent: words, contexts, a n d senses. T h e y are r e p r e s e n t e d as w o r d vectors, context vectors, a n d sense vectors, re- spectively. Word vectors are d e r i v e d f r o m neighbors in the corpus, context vectors are d e r i v e d from w o r d vectors, a n d sense vectors are d e r i v e d b y w a y of clustering from the distribution of context vectors.
The representational m e d i u m of a vector space was chosen because of its w i d e acceptance in i n f o r m a t i o n retrieval (IR) (see, e.g., Salton a n d McGill [1983]). The vector- space m o d e l is arguably the most c o m m o n f r a m e w o r k in IR. Systems b a s e d o n it h a v e r a n k e d a m o n g the best in m a n y evaluations of IR p e r f o r m a n c e ( H a r m a n 1993). The success of the vector-space m o d e l motivates us to use it for the r e p r e s e n t a t i o n of words. We represent w o r d s in a space in w h i c h each d i m e n s i o n c o r r e s p o n d s to a w o r d , just as d o c u m e n t s a n d queries are c o m m o n l y r e p r e s e n t e d in this space in IR.
A n o t h e r a p p r o a c h to c o m p u t i n g w o r d similarity is the representation of w o r d s in a d o c u m e n t space in w h i c h each d i m e n s i o n c o r r e s p o n d s to a d o c u m e n t (Lesk 1969; Salton 1971; Qiu and Frei 1993). There are f e w e r o c c u r r e n c e - i n - d o c u m e n t than w o r d - co-occurrence events, so these w o r d representations t e n d to be m o r e sparse and, ar- guably, less informative than w o r d - b a s e d representations. Word vectors h a v e also b e e n based on h a n d - e n c o d e d features (Gallant 1991) a n d dictionaries (Sparck-Jones 1986; Wilks et al. 1990). C o r p u s - b a s e d m e t h o d s like the one p r o p o s e d here h a v e the ad- v a n t a g e that no m a n u a l labor is required a n d that a possible m i s m a t c h b e t w e e n a general dictionary a n d a specialized text (e.g., o n chemistry) is avoided. Finally, w o r d similarity can be c o m p u t e d from structural features like h e a d - m o d i f i e r relationships (Grefenstette 1994b; Ruge 1992; Dagan, Marcus, a n d M a r k o v i t c h 1993; Pereira, Tishby, a n d Lee 1993; Dagan, Pereira, a n d Lee 1994). Like d o c u m e n t - b a s e d representations, structure-based representations are sparser than those b a s e d on co-occurrence. It is debatable w h e t h e r structural features are m o r e informative than associational features (Grefenstette 1992, 1996) or not (Schtitze a n d P e d e r s e n 1997). A p p r o a c h e s to w o r d representation closely related to ours w e r e p r o p o s e d b y N i w a a n d Nitta (1994) a n d Burgess and L u n d (1997). Instead of co-occurrence counts, vector entries are m u t u a l i n f o r m a t i o n scores b e t w e e n the w o r d that is to be r e p r e s e n t e d a n d the d i m e n s i o n words, in N i w a a n d Nitta's approach.
The algorithms for vector d e r i v a t i o n a n d sense discrimination are described in w h a t follows.
2.1 Word Vectors
A vector for w o r d w is d e r i v e d f r o m the close neighbors of w in the corpus. Close neighbors are all w o r d s that co-occur w i t h w in a sentence or a larger context. In the simplest case, the vector has an e n t r y for each w o r d that occurs in the corpus. The e n t r y for w o r d v in the vector for w records the n u m b e r of times that w o r d v occurs close to w in the corpus. It is this representational vector space that w e refer to as WOrd Space.
Schiitze Automatic Word Sense Discrimination
Table 1
Co-occurrence counts for four words in a hypothetical corpus. The words
legal
andclothes
are interpreted as dimensions in Figure 2,judge
androbe
as vectors.Vector
D i m e n s i o n
judge
robe
legal
300 133clothes
75 200LEGAL
300
JUDGE
/
133 f
f /
ROBE
I
I
75
200 CLOTHES
Figure 2
The derivation of word vectors,
judge
androbe
are represented as word vectors in atwo-dimensional space with the dimensions 'legal' and 'clothes.' Co-occurrence data are from Table 1.
thetical c o r p u s in Table 1. The w o r d
judge
h a s a v a l u e of 300 on the d i m e n s i o n "legal" b e c a u s ejudge
a n dlegal
co-occur 300 times w i t h each other (see b e l o w for w h i c h w o r d s are selected as d i m e n s i o n s ; a w o r d can be a d i m e n s i o n of W o r d Space a n d r e p r e s e n t e d as a w o r d vector in Word Space at the s a m e time).This vector r e p r e s e n t a t i o n c a p t u r e s the typical topic or subject m a t t e r of a w o r d . For e x a m p l e , w o r d s like
judge
a n dlaw
are closer to the "legal" d i m e n s i o n ; w o r d s likerobe
a n dtailor
are closer to the "clothes" dimension. By l o o k i n g at the a m o u n t of o v e r l a p b e t w e e n t w o vectors, o n e can r o u g h l y d e t e r m i n e h o w closely they are related semantically. This is b e c a u s e related m e a n i n g s are often e x p r e s s e d b y similar sets of w o r d s . Semantically related w o r d s will therefore co-occur w i t h similar n e i g h b o r s a n d their vectors will h a v e considerable overlap.This similarity can be m e a s u r e d b y the cosine b e t w e e n t w o vectors. The cosine is e q u i v a l e n t to the n o r m a l i z e d correlation coefficient:
corr( fi, ~ )
= ~iN=l ViWi [image:5.468.37.222.117.350.2]Computational Linguistics Volume 24, Number 1
(perfect overlap), then the value of the cosine is 1.0. If there is no overlap at all, then the value of the cosine is 0.0. The cosine can therefore be used as a rough measure of semantic relatedness between words.
What words should serve as the dimensions of Word Space? We will experiment with two strategies: a global and a local one. The local strategy focuses on the contexts of the ambiguous words and ignores the rest of the corpus. The global strategy is to select the n most frequent words of the corpus as features and use them regardless of the word that is to be disambiguated. (See Karov and Edelman [1996] for a different approach that selects features according to a combination of global frequency and local salience.)
For local selection, we can also use a frequency cutoff. As an alternative, we will test selection according to a X 2 test. For the frequency-based selection criterion, the neighbors of the ambiguous word in the corpus are counted. A neighbor is any word that occurs at a distance of at most 25 words from the ambiguous word (that is, in a 50- word w i n d o w centered on the ambiguous word). The 1,000 most frequent neighbors are chosen as the dimensions of the space. For the x2-based criterion, a x2-measure of dependence is applied to a contingency table containing the n u m b e r of contexts of the ambiguous word in which the candidate w o r d occurs (N++) and does not occur (N+_), and the n u m b e r of contexts without an occurrence of the ambiguous word in which the candidate word occurs (N_+) and does not occur (N__).
X2 = N(N++N__ - N+_N_+) 2
(N++ + N+_)(N_+ + N__)(N++ + N_+)(N+_ + N _ _ )
The underlying assumption in using the x2-test is that candidate words whose occur- rence depends on whether the ambiguous word occurs will be indicative of one of the senses of the ambiguous word and hence useful for disambiguation. 2
After 1,000 words have been selected in local selection, word vectors are formed by collecting a 1,000-by-I, 000 matrix C, such that element cq records the n u m b e r of times that words i and j co-occur in a w i n d o w of size k. Column n (or, equivalently, row n) of matrix C represents word n. Note that C is symmetric since the words that are represented as word vectors are also those that form the dimensions of the 1,000- dimensional space. We chose a w i n d o w size of k = 50 because no improvement of discrimination performance was found in Schfitze (1997) for k > 50.
For global selection, we choose the 20,000 most frequent words as features and the 2,000 most frequent words as dimensions of Word Space. A global 20, 000-by-2, 000 co-occurrence matrix is derived from the corpus.
Association data were extracted from the training set consisting of 17 months of the New York Times News Service, June 1989 through October 1990. The size of this set is about 435 megabytes and 60.5 million words. Two months (November 1990 and May 1989; 46 megabytes, 5.4 million words) were set aside as a test set.
2.2 Context Vectors
The representation for words derived above conflates senses. For example, both senses of the word suit ('lawsuit' and 'garment') are s u m m e d in its word vector, which will therefore be positioned somewhere between the 'legal' and 'clothes' dimensions in Figure 2. We need to go back to individual contexts in the corpus to acquire information about sense distinctions. Contexts are represented as context vectors in Word Space.
Sch~tze Automatic Word Sense Discrimination
LEGAL
CENTROID
LAW /
~JUDGE
/iJ~ISTATUTE
/ I I ///
/#SUIT/ / /
I/~//
I/1/
CLOTHES
Figure 3
The derivation of context vectors. A context vector is computed as the centroid of the words occurring in the context. The words in this example context are law, judge, statute, and suit.
A context vector is the centroid (or sum) of the vectors of the w o r d s occurring in the context. Figure 3 shows the context vector of an example context of suit containing the words law, judge, statute, and suit. Note that the context vector is closer to the "legal' than to the 'clothes' dimension, thus capturing that the context is a 'legal' use of suit.
(The true s u m of the four vectors is longer than shown. Since all correlation coefficients are normalized, the length of a vector does not play a role in the computations.)
The centroid "averages" the direction of a set of vectors. If m a n y of the words in a context have a strong c o m p o n e n t for one of the topics (like 'legal' in Figure 3), then the average of the vectors, the context vector, will also have a strong c o m p o n e n t for the topic. Conversely, if only one or two words represent a particular topic, then the context vector will be w e a k on this component. The context vector hence represents the strength of different topical or semantic components in a context.
In the computation of the context vector, we will weight a w o r d vector according to its discriminating potential. A rough measure of h o w well w o r d wi discriminates between different topics is the log inverse d o c u m e n t frequency used in information retrieval (Salton a n d Buckley 1990):
ai = l ° g / ~ /
where ni is the n u m b e r of d o c u m e n t s that wi occurs in and N is the total n u m b e r of documents. Poor discriminators of topics are words such as idea or help that are relatively uniformly distributed a n d therefore have a high d o c u m e n t frequency. Good content discriminators like automobile or China have a bursty distribution (they have several occurrences in a short interval if they occur at all [Church a n d Gale 1995]), and therefore a low d o c u m e n t frequency relative to their absolute frequency.
[image:7.468.38.395.55.247.2]Computational Linguistics Volume 24, Number 1
LEGAL
SENSE 1 Cl
..,,,7 ,s ~- SENSE
CLOTHES
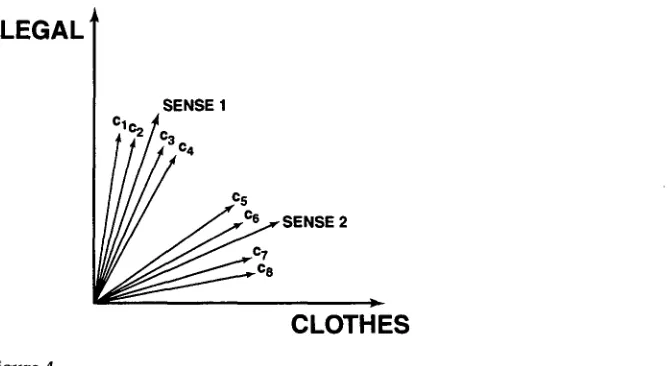
Figure 4
The derivation of sense vectors. Sense vectors are derived by clustering the context vectors of an ambiguous word (here, cl, c2, c3, c4, c5, c6, c7, and
cs),
and computing sense vectors as the centroids of the resulting clusters. The vectors SENSE 1 and SENSE 2 are the sense vectors of clusters {cl, c2, c3, c4} and {cs, c6, c7,cs},
respectively.2.3 Sense Vectors
Sense representations are c o m p u t e d as g r o u p s of similar contexts. All contexts of the a m b i g u o u s w o r d are collected from the corpus. For each context, a context vector is c o m p u t e d . This set of context vectors is t h e n clustered into a p r e d e t e r m i n e d n u m b e r of coherent clusters or context g r o u p s using Buckshot (Cutting et al. 1992), a c o m b i n a t i o n of the EM algorithm a n d agglomerative clustering. The representation of a sense is simply the centroid of its cluster. It m a r k s the p o r t i o n of the m u l t i d i m e n s i o n a l space that is occupied b y the cluster.
We chose the EM algorithm for clustering since it is g u a r a n t e e d to c o n v e r g e o n a locally optimal solution of the clustering problem. In o u r case, the solution is optimal in that the s u m of the s q u a r e d distances b e t w e e n context vectors a n d their centroids will be minimal. In other words, the centroids are optimal representatives for the context vectors in their cluster.
One p r o b l e m w i t h the EM algorithm is that it finds a solution that is only locally optimal. It is therefore i m p o r t a n t to find a g o o d starting p o i n t since a b a d starting point will lead to a local m i n i m u m that is not globally optimal. Some e x p e r i m e n t a l e v i d e n c e given b e l o w shows that cluster quality varies considerably d e p e n d i n g o n the initial parameters. In o r d e r to find a g o o d starting point, w e use g r o u p - a v e r a g e agglomerative clustering (GAAC) o n a sample of context vectors. For each of the 2,000 clustering e x p e r i m e n t s described below, w e first choose a r a n d o m sample of 50. This size is r o u g h l y equal to v ' ~ , the n u m b e r of context vectors to be clustered. Since GAAC is of time c o m p l e x i t y O(n2), this g u a r a n t e e s overall linear time c o m p l e x i t y of the clustering procedure. If the training set has m o r e than 2,000 instances of the a m b i g u o u s w o r d , 2,000 context vectors are selected randomly. The centroids of the resulting clusters are then the p a r a m e t e r s for the first iteration of EM. We c o m p u t e five iterations of the EM algorithm for all e x p e r i m e n t s since in most cases only a few, if any, context vectors w e r e reassigned in the fifth iteration.
[image:8.468.57.391.55.238.2]Schfitze Automatic Word Sense Discrimination
An e x a m p l e is s h o w n in Figure 4. The clustering step has g r o u p e d context vectors cl, c2, c3, a n d c4 in the first g r o u p a n d c5, c6, c7, a n d c8 in the second group. The sense vector of the first g r o u p is the centroid labeled SENSE 1, the sense vector of the second g r o u p the centroid labeled SENSE 2.
The result of clustering d e p e n d s on the representation of context vectors. For this reason, w e also investigate a transformation of the m u l t i d i m e n s i o n a l space via a singular v a l u e d e c o m p o s i t i o n (SVD) (Golub and v a n Loan 1989). SVD is a form of dimensionality reduction that finds the major axes of variation in Word Space. Context vectors can then be r e p r e s e n t e d b y their values on these principal dimensions. The m o t i v a t i o n for a p p l y i n g SVD here is m u c h the same as the use of Latent Semantic Indexing (LSI) in i n f o r m a t i o n retrieval (Deerwester et al. 1990). LSI abstracts a w a y from the surface w o r d - b a s e d representation a n d detects u n d e r l y i n g features. W h e n similarity is c o m p u t e d on these features (via cosine b e t w e e n SVD-reduced context vectors), contextual similarity can be, potentially, better m e a s u r e d than via cosine be- t w e e n u n r e d u c e d context vectors. The a p p e n d i x defines SVD a n d gives an example matrix decomposition.
In this paper, the w o r d vectors will be r e d u c e d to 100 dimensions. The e x p e r i m e n t s r e p o r t e d in Schfitze (1992b, 1997) give evidence that reduction to this dimensionality does not decrease accuracy of sense discrimination. Space r e q u i r e m e n t s for context vectors are r e d u c e d to a b o u t 1 / 1 0 and 1/20 for a 1,000-dimensional a n d a 2,000- dimensional Word Space, respectively. A l t h o u g h most w o r d vectors are sparse, context vectors are dense, since they are the s u m of m a n y w o r d vectors. Time efficiency is increased on the same order of m a g n i t u d e w h e n the correlation of context vectors and sense vectors is c o m p u t e d . The c o m p u t a t i o n of the SVD's in this p a p e r took from a few m i n u t e s p e r w o r d for the local feature set to a b o u t three h o u r s for the global feature set.
2.4 Application of Context-Group Discrimination
C o n t e x t - g r o u p discrimination uses w o r d vectors a n d sense vectors as follows to dis- criminate occurrences of the a m b i g u o u s word. For an occurrence t of the a m b i g u o u s w o r d v:
• Map t into its c o r r e s p o n d i n g context vector ~ in Word Space using the vectors of the w o r d s in t's context (the l o w e r d a s h e d line in Figure 1).
• Retrieve all sense vectors ~j of v (the two points m a r k e d as squares in the figure).
• Assign t to the sense j w h o s e sense vector ~j is closest to ~ (assignment s h o w n as a solid arrow).
This algorithm selects the context g r o u p w h o s e sense vector is closest to the context vector of the occurrence of the w o r d that is to be disambiguated. Context vectors a n d sense vectors capture semantic characteristics of the c o r r e s p o n d i n g context and sense, respectively. Consequently, the sense vector that is closest to the context vector has the best semantic m a t c h with the context. Therefore, context-group discrimination categorizes the occurrence as belonging to that sense.
3. Evaluation
Computational Linguistics Volume 24, Number 1
Table 2
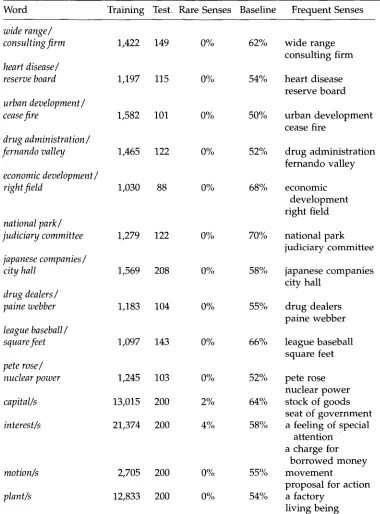
Number of occurrences of test words in training and test set, percent rare senses in test set, baseline performance (all occurrences assigned to most frequent sense), and the two main senses of each of the 20 artificial and natural ambiguous words used in the experiment.
Word Training Test. Rare Senses Baseline Frequent Senses
wide range/
consulting firm
1,422 149 0% 62%heart disease/
reserve board
1,197 115 0% 54%urban development/
cease fire
1,582 101 0% 50%drug administration /
fernando valley
1,465 122 0%wide range consulting firm
heart disease reserve board
urban development cease fire
52% drug administration
fernando valley
economic development /
right field
1,030 88 0% 68%national park/
judiciary committee
1,279 122 0% 70%japanese companies /
city hall
1,569 208 0% 58%drug dealers /
paine webber
1,183 104 0% 55%league baseball/
square feet
1,097 143 0% 66%pete rose/
nuclear power
1,245 103 0% 52%capital/s
13,015 200 2% 64%interest/s
21,374 200 4% 58%motion/s
2,705 200 0% 55%plant/s
12,833 200 0% 54%economic development right field
national park judiciary committee
japanese companies city hall
drug dealers paine webber
league baseball square feet
pete rose nuclear power stock of goods seat of government a feeling of special
attention a charge for
borrowed money movement
proposal for action a factory
[image:10.468.46.426.129.643.2]Schiitze Automatic Word Sense Discrimination
Table 2
Continued.
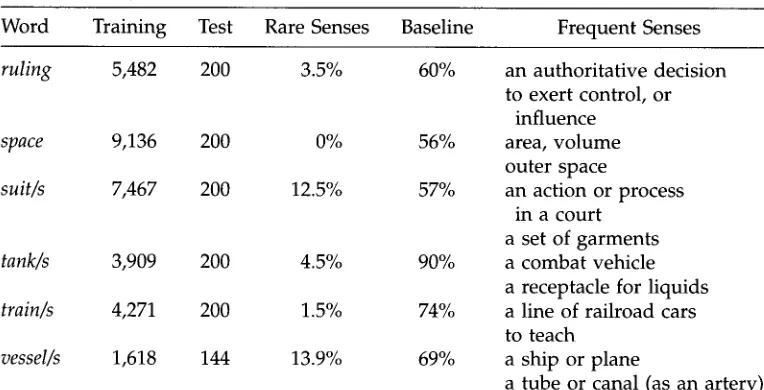
Word Training Test Rare Senses Baseline Frequent Senses
ruling 5,482 200 3.5% 60% an authoritative decision
to exert control, or influence
space 9,136 200 0% 56% area, v o l u m e
outer space
suit/s 7,467 200 12.5% 57% an action or process
in a court a set of g a r m e n t s
tank/s 3,909 200 4.5% 90% a c o m b a t vehicle a receptacle for liquids
train/s 4,271 200 1.5% 74% a line of railroad cars to teach
vessel/s 1,618 144 13.9% 69% a ship or p l a n e
a tube or canal (as an artery)
Artificial a m b i g u o u s w o r d s or p s e u d o w o r d s are a c o n v e n i e n t m e a n s of testing disambiguation algorithms (Schtitze 1992a; Gale, Church, a n d Yarowsky 1992). It is t i m e - c o n s u m i n g to hand-label a large n u m b e r of instances of an a m b i g u o u s w o r d for evaluating the p e r f o r m a n c e of a disambiguation algorithm. P s e u d o w o r d s c i r c u m v e n t this need: Two or m o r e words, e.g., banana and door, are conflated into a n e w type:
banana~door. All occurrences of either w o r d in the c o r p u s are then replaced b y the n e w type. It is easy to evaluate disambiguation p e r f o r m a n c e for p s e u d o w o r d s since one can go back to the original text to decide w h e t h e r a correct decision was made.
To create the p s e u d o w o r d s s h o w n in Table 2, all w o r d pairs w e r e extracted from the corpus, i.e., all pairs of w o r d s that occurred adjacent to each other in the corpus in a particular order. All n u m b e r s were discarded, since n u m b e r s do not seem to involve sense ambiguity. P s e u d o w o r d s were then created b y r a n d o m l y d r a w i n g two pairs from those that h a d a f r e q u e n c y b e t w e e n 500 a n d 1,000 in the corpus. P s e u d o w o r d s were g e n e r a t e d from pairs rather than simple w o r d s because pairs are less likely than w o r d s to be a m b i g u o u s themselves. Pair-based p s e u d o w o r d s are therefore g o o d examples of a m b i g u o u s w o r d s with two clearly distinct senses.
Table 2 indicates h o w often the a m b i g u o u s w o r d occurred in the training and test sets, h o w m a n y instances were instances of rare senses, a n d the baseline p e r f o r m a n c e that is achieved b y assigning all occurrences to the most frequent sense. In the eval- uation given here, only senses that account for at least 15% of the occurrences of the a m b i g u o u s w o r d are taken into account. Rare senses are those that account for fewer than 15% of the occurrences. The w o r d s in Table 2 each h a d t w o frequent senses. The f r e q u e n c y of rare senses ranges from 0% to 13.9%, with an average of 2.1%. Rare senses are not eliminated from the training set.
The training a n d test sets w e r e taken from the New York Times N e w s Service as described above (training set: June 1989-October 1990; test set: N o v e m b e r 1990, M a y 1989). If a w o r d h a d m o r e than 200 occurrences in the test set, then only the first 200 occurrences w e r e i n c l u d e d in the evaluation.
[image:11.468.39.421.85.280.2]Computational Linguistics Volume 24, Number 1
tions b e t w e e n the senses in Table 2 are intuitively clear. For example, the probability of a context in w h i c h suit could at the same time refer to a set of g a r m e n t s a n d an action in court is v e r y low. Consequently, there were f e w e r t h a n five instances w h e r e the a p p r o p r i a t e sense was not obvious from the i m m e d i a t e context. In these cases, the sense that s e e m e d m o r e plausible to the a u t h o r was assigned.
It is i m p o r t a n t to evaluate on a test set that is separate from the training set. C o n t e x t - g r o u p discrimination is b a s e d on the distribution of context vectors in the training set. The distribution in the training set is often a b a d m o d e l for the distribution in the test set. In practice, the i n t e n d e d text of application will be from a time p e r i o d not c o v e r e d in the training set (for example, n e w s w i r e text f r o m after the date of training). Word distributions can change considerably o v e r time. The test set was therefore constructed to be from a time p e r i o d different from the time p e r i o d of the training set. This is also the reason that w e d o not do cross-validation. Cross-validation respecting the constraint that test a n d training sets be from different time p e r i o d s w o u l d h a v e required a test set several times larger than the one that was available.
Clustering and evaluating o n the same set is also problematic because of sampling variation. Consider the following example. We h a v e a set of three context vectors C : {C 1 : (1), c2 = (2), C 3 : (3)} in a o n e - d i m e n s i o n a l space. Contexts 1 a n d 2 are uses
of sense 1, context 3 is a use of sense 2. If C is u s e d as b o t h training a n d e v a l u a t i o n set, then average p e r f o r m a n c e is 83% (with probability 0.5, w e get centroids 1.5 a n d 3 a n d 100% accuracy, w i t h probability 0.5, w e get centroids 1 a n d 2.5 a n d 67% accuracy). If w e split C into a training set T of size 2 and a test set E of size 1, w e get an a v e r a g e p e r f o r m a n c e of 67% (100% for E = {cl}, 50% for E = {c2}, 50% for E = { £ 3 } ) , w h i c h
is l o w e r than 83%. This e x a m p l e shows that conflating training a n d test set can result in artificially high p e r f o r m a n c e .
An a d v a n t a g e of c o n t e x t - g r o u p discrimination is that the g r a n u l a r i t y of sense distinctions is an adjustable p a r a m e t e r of the algorithm. E x p e r i m e n t s r u n directly for the senses in Table 2 will test the algorithm's ability to discriminate coarse sense distinctions. To test p e r f o r m a n c e for fine-grained sense distinctions (e.g., 'office space' vs. 'exhibition space'), w e will r u n two experiments, one that evaluates p e r f o r m a n c e for clustering the context vectors of a w o r d into ten clusters a n d an i n f o r m a t i o n retrieval e x p e r i m e n t in w h i c h the n u m b e r of clusters is also large for sufficiently f r e q u e n t words. The goal of the 10-cluster e x p e r i m e n t s is to i n d u c e m o r e fine-grained sense distinc- tions than in the 2-cluster experiments. H o w e v e r , it is h a r d e r to d e t e r m i n e the g r o u n d truth for fine sense distinctions. W h e n it comes to fine distinctions, a large n u m b e r of occurrences are i n d e t e r m i n a t e or compatible w i t h several of the m o r e finely individ- u a t e d senses (cf. Kilgarriff [1993]).
For this reason, e x p e r i m e n t s with a large n u m b e r of clusters were e v a l u a t e d using two indirect measures. The first m e a s u r e is accuracy for t w o - w a y discriminations, i.e., the d e g r e e to w h i c h each of the ten clusters contained o n l y one of the two "coarse" senses. This evaluation is indirect because a cluster that contains, say, only 'limited extent in one, two, or three d i m e n s i o n s ' uses of space w o u l d be d e e m e d 100% correct, yet it could be r a n d o m l y m i x e d as far as fine sense distinctions are c o n c e r n e d (e.g., 'office space' vs. 'exhibition space'). The a u t h o r inspected the data a n d f o u n d g o o d separation of fine-grained senses in the 10-cluster e x p e r i m e n t s to the extent that the evaluation m e a s u r e indicated g o o d p e r f o r m a n c e on the t w o - w a y discrimination task. H o w e v e r , because of the a b o v e - m e n t i o n e d subjectivity of j u d g e m e n t s for fine sense distinctions, this is h a r d to quantify.
Schiitze Automatic Word Sense Discrimination
i m p r o v e s the p e r f o r m a n c e of an IR system considerably. Since the success of sense- b a s e d retrieval d e p e n d s on the accuracy of context-group discrimination, w e can infer that the algorithm reliably assigns a m b i g u o u s instances to i n d u c e d senses e v e n in the fine-grained case.
4. Experiments
4.1 Word Sense Discrimination
Table 3 shows e x p e r i m e n t a l results for context-group discrimination. There were four conditions that were varied in the e x p e r i m e n t s (as described in Section 2):
• local vs. global feature selection
• feature selection according to f r e q u e n c y v s . X 2
• t e r m representations vs. SVD-reduced representations
• n u m b e r of clusters (2 vs. 10)
For local feature selection, the other three p a r a m e t e r s are varied systematically (the first eight c o l u m n s of Table 3). For global feature selection, selection according to X 2 is not possible, since the X 2 test p r e s u p p o s e s an e v e n t (like the occurrence of an a m b i g u o u s w o r d ) that the occurrence of candidate w o r d s d e p e n d s on. There is no such e v e n t for global feature selection. A larger n u m b e r of d i m e n s i o n s (2,000) is used for the global variant of the algorithm in o r d e r to get coverage of a large range of topics that m i g h t be relevant for disambiguation. We therefore a p p l y SVD in the global feature selection case. Even if w o r d vectors are sparse, context vectors are usually not. Clustering 2,000- dimensional vectors is c o m p u t a t i o n a l l y expensive, so that w e only ran e x p e r i m e n t s with SVD-reduced vectors for the global variant.
Ten e x p e r i m e n t s with different r a n d o m l y chosen initial p a r a m e t e r s w e r e r u n for each of the 200 combinations of the different levels of Word, Representation, a n d Clustering. The m e a n p e r c e n t a g e correctness a n d the s t a n d a r d deviation for each such set of 10 e x p e r i m e n t s is s h o w n in the cells of Table 3. We give m e a n a n d deviation of the percentage of correctly labeled occurrences of all instances in the training set ("total" = "t.'), of the instances of sense 1 ("$1") a n d of the instances of sense 2 ("$2"). The b o t t o m r o w of the table gives averages of the total p e r c e n t a g e correct n u m b e r s over the 20 w o r d s covered. The rightmost c o l u m n gives averages of the m e a n s o v e r the 10 experiments.
We a n a l y z e d the results in Table 3 via analysis of variance (ANOVA, see, for example, Ott [1992]). An ANOVA was p e r f o r m e d for a 20 x 5 x 2 design with 10 replicates. The factors were Word, Representation (local, frequency-based, terms; local, frequency-based, SVD; local, Xa-based, terms; local, x2-based, SVD; global, frequency- based, SVD), a n d Clustering (coarse = 2 clusters, fine = 10 clusters). Percentages were t r a n s f o r m e d using the f u n c t i o n f ( X ) = 2 x sin -1 (v/X) as r e c o m m e n d e d b y Winer (1971). The t r a n s f o r m e d percentages have a distribution that is close to a n o r m a l distribution as required for the application of ANOVA.
We f o u n d that the effects of all three factors and all interactions was significant at the 0.001 level. These effects are discussed in w h a t follows.
Computational Linguistics Volume 24, Number 1
Table 3
Results of disambiguation experiments. Rows give total accuracy for each word ("t.') as well as accuracy for the two senses separately ("$1", "$2"). The average in the bottom row is an average over total ("t.') accuracy numbers only. Columns describe experimental conditions and the mean ("]~") and standard deviation ("a") of 10 replications of each experiment. The rightmost column contains an average over the mean values of the 10 experiments.
Pseudowords are abbreviated to the first words of pairs.
Local Global
wide~consul. $1
$2 55 16 100 0 69 31 92 9 74 25 92 13 69 24 82 10 89 6 94 4 t. 51 4 62 0 60 4 66 3 56 6 64 3 65 8 66 2 87 3 87 3
heart~reserve $1 66 0 78 11 100 0 99 4. 72 0 75 12 100 0 98 2 100 0 100 0 $2 100 0 90 7 100 0 100 0 100 0 94 5 98 0 100 1 100 0 100 0
t. 84 0 : 8 5 2 100 0 99 2 8 7 0 85 3 99 0 99 1 100 0 100 0
urban~cease $1 86 1 87 2 96 0 97 1 9 1 4 90 8 98 0 98 1 100 0 98 2
~rugffern.
.ocon./right
nat./jud.
iap./city $1
71rug/paine $1
!eague/square $1
pete~nuclear $1
:apital $1
interest $1
,wtion $1
~lant $1
ruling $1
;pace $1
~uit S1
~ank $1
~rain $1
vessel $1
X 2 Frequency Frequency
Terms I SVD Terms I SVD SVD
2 10 2 10 2 10 2 10 2 10
[image:14.468.40.423.142.687.2]Schfitze Automatic Word Sense Discrimination
Table 4
The Tukey W test shows significantly different performance for the five representations. Proportions are transformed using f i X ) = 2 x sin -1 (v/X). The rightmost column contains the accuracy A in percent that would correspond to the average value Y in the second column (i.e., f ( A ) = Y). Significant difference for a = 0.01:0.034
Average of Difference C o r r e s p o n d i n g
Level 2 x s i n - l ( V ' X ) from Closest Accuracy
local, )/2, terms 2.11 0.13 76%
local, frequency, terms 2.24 0.13 81%
local, frequency, SVD 2.44 0.06 88%
local, X 2, SVD 2.50 0.06 90%
global, frequency, SVD 2.66 0.16 94%
w o r d s (for example, space and interest) are c o m p o s e d of m a n y different subsenses that are h a r d to identify for b o t h p e o p l e a n d computers.
The only p s e u d o w o r d with p o o r p e r f o r m a n c e is wide range/consultingfirm. This is an illustrative example of a w e a k n e s s of the particular i m p l e m e n t a t i o n of context- g r o u p discrimination chosen here. Since we only rely on topical information, a w o r d c o m p o s e d of a nontopical sense, like wide range, that can occur in almost a n y subject area is d i s a m b i g u a t e d poorly. The 'area, v o l u m e ' sense of space and the 'teaching' sense of train are similarly topically a m o r p h o u s a n d therefore h a r d if only topical informa- tion is considered. The p o o r p e r f o r m a n c e for 'plant' in the 10-cluster e x p e r i m e n t s is p r o b a b l y d u e to the w a y training-set clusters w e r e assigned to senses. The training set was clustered into 20 clusters and each cluster was given a sense label. This proce- d u r e introduces m a n y misclassifications of individual instances in the training set. In contrast, a p e r f o r m a n c e of 92% was achieved in Schiitze (1992b) b y h a n d - c a t e g o r i z i n g the training set, instance b y instance.
N o t e that for some e x p e r i m e n t a l conditions a n d for some words, p e r f o r m a n c e of t w o - g r o u p clustering is b e l o w baseline. In a c o m p l e t e l y u n s u p e r v i s e d setting, we have to m a k e the a s s u m p t i o n that the two i n d u c e d clusters c o r r e s p o n d to two different senses. In the w o r s t case, w e will get, two clusters w i t h identical p r o p o r t i o n s of the two senses a n d an accuracy of 50%, b e l o w the baseline of assigning all occurrences to a sense that occurs in m o r e than 50% of all cases. For example, for vessel the w o r s t case w o u l d be two clusters each with 69% 'ship' instances a n d 31% 'tube' instances. Overall accuracy w o u l d be 0.5 x .69 + 0.5 x .31 = 0.5. It could be a r g u e d that the true baseline for u n s u p e r v i s e d t w o - g r o u p clustering is 50%, not the p r o p o r t i o n of the most frequent sense.
[image:15.468.52.363.131.234.2]Computational Linguistics Volume 24, Number 1
Table 5
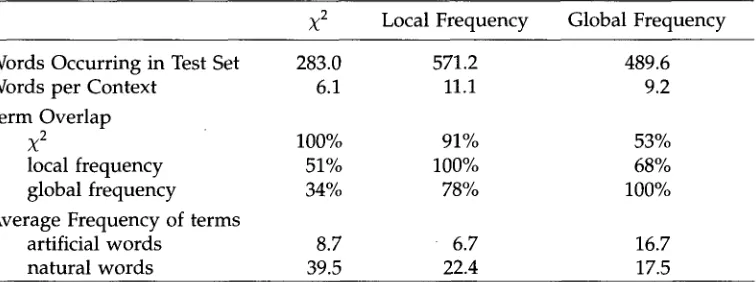
Occurrence of selected term features in the test set. The table shows number of words occurring in the test set (averaged over the 20 ambiguous words); number of words occurring per context (averaged over contexts); proportion of words from one representation occurring in another (averaged first over contexts, then over ambiguous words; e.g., on average 91% of X2-selected terms were also in the set selected by local frequency); average number of contexts that a selected term occurred in (e.g., on average a xa-selected term occurred in 8.7 contexts of the artificial ambiguous words, averaged over the words in a context).
~2
Local F r e q u e n c y Global F r e q u e n c yWords Occurring in Test Set 283.0 571.2 489.6
Words per Context 6.1 11.1 9.2
Term O v e r l a p
X 2 100% 91% 53%
local f r e q u e n c y 51% 100% 68%
global f r e q u e n c y 34% 78% 100%
Average F r e q u e n c y of terms
artificial w o r d s 8.7 6.7 16.7
natural w o r d s 39.5 22.4 17.5
representations, b u t is m o r e accurate for SVD-reduced representations.
W h y do globally selected features p e r f o r m better? Table 5 presents data o n the occurrence of selected terms in the test set that are relevant to this question. N o t e first that locally selected features seem to do better than globally selected ones o n several measures. More locally selected features occur in the test set ( " w o r d s occurring in test set": 571.2 vs. 489.6), m o r e local features occur in the i n d i v i d u a l contexts ( " w o r d s p e r context": 11.1 vs. 9.2), a n d m o r e global features are also local features than vice versa ( o n a per-context basis, 78% of global features are also local features, b u t only 68% of local features are also global features), suggesting that local features capture m o r e i n f o r m a t i o n than global features. The first two m e a s u r e s also s h o w that X2-selected features suffer from sparseness. Both the total n u m b e r of features that occur in the training set a n d the n u m b e r of w o r d s per context are small. This e v i d e n c e explains w h y SVD representations that address sparseness do better than t e r m representations for X 2.
To explain the difference in p e r f o r m a n c e b e t w e e n local a n d global f r e q u e n c y fea- tures, w e h a v e to break d o w n a v e r a g e accuracy according to artificial a n d natural a m b i g u o u s words. Average accuracy for artificial a m b i g u o u s w o r d s is 89.9% (2 clus- ters) a n d 92.2% (10 clusters) for local features a n d 98.6% (2 clusters) a n d 98.0% (10 clusters) for global features. Average accuracy for natural a m b i g u o u s w o r d s is 76.0% (2 clusters) a n d 84.4% (10 clusters) for local features a n d 80.8% (2 clusters) a n d 83.1% (10 clusters) for global features. These data s h o w a clear split. P e r f o r m a n c e of local a n d global features is c o m p a r a b l e for natural a m b i g u o u s words. Global features p e r f o r m clearly better for artificial a m b i g u o u s words.
[image:16.468.51.429.153.294.2]Schi~tze Automatic Word Sense Discrimination
small for X 2 and local f r e q u e n c y in the case of artificial a m b i g u o u s words. Clustering can only w o r k well if contexts h a v e e n o u g h elements in c o m m o n so that similarity can be d e t e r m i n e d robustly. Apparently, there were too few elements in c o m m o n for X 2 a n d local f r e q u e n c y in the case of artificial a m b i g u o u s w o r d (and the patterns w e r e so sparse that e v e n SVD was not an effective remedy).
The p r o b l e m is that artificial a m b i g u o u s w o r d s are m u c h less f r e q u e n t in the training set than natural a m b i g u o u s w o r d s (average frequencies of 1,306.9 vs. 8,231.0), so that reliable feature selection is h a r d e r for artificial a m b i g u o u s words. With a m p l e i n f o r m a t i o n on natural a m b i g u o u s w o r d s available in the training set, features can be selected that will occur d e n s e l y in the test set. The quality of feature selection for artificial a m b i g u o u s w o r d s was less successful d u e to smaller training set sizes.
This analysis reiterates the i m p o r t a n c e of a clear separation of training a n d test sets. P e r f o r m a n c e n u m b e r s will be artificially high if feature selection is d o n e o n b o t h training a n d test sets, a v o i d i n g the p r o b l e m s with feature coverage d e m o n s t r a t e d in Table 5.
Since global feature selection is simpler a n d as effective as local approaches, global feature selection is the p r e f e r r e d i m p l e m e n t a t i o n of context-group discrimination in the general case. Note, however, that different w o r d s m a y h a v e different optimal repre- sentations. For example, local features w o r k best for
vessel.
There are similar individual differences for f r e q u e n c y vs. x2-based selection. F r e q u e n c y - b a s e d selection is best forsuit,
b u t x2-based selection is better forvessel,
at least for SVD-reduced representations.Factor Clustering.
Fine clustering is generally better than coarse clustering. The one case for w h i c h coarse clustering comes close to the p e r f o r m a n c e of fine clustering is global feature selection. But this small difference is almost entirely d u e to the b a d p e r f o r m a n c e of fine clustering forplant,
w h i c h is likely to be d u e to insufficient h a n d - categorization of the training set, as explained above.That fine clustering p e r f o r m s better than coarse clustering is not surprising, since m o r e i n f o r m a t i o n is u s e d in the evaluation of fine clustering: the labeling of clus- ters in the training set. Only coarse clustering is e v a l u a t e d as strictly u n s u p e r v i s e d disambiguation, since w e do not have an evaluation set for fine sense distinctions.
Variance.
In general, the variance of discrimination accuracy is h i g h e r for coarse clus- tering than for fine clustering. This is not surprising, given the fact that w e evaluate b o t h types of clustering o n h o w well they do on a t w o - w a y distinction. There m a y be several quite different w a y s of dividing a set of context vectors into two groups. But if we first cluster into ten g r o u p s a n d assign these g r o u p s to two senses, then the resulting t w o - w a y partitions are m o r e likely to resemble each other (even if the initial 10-group clusterings are not v e r y similar).The e x p e r i m e n t s indicate that context-group discrimination b a s e d on globally se- lected features is the best i m p l e m e n t a t i o n in the general case. The algorithm achieves above-baseline p e r f o r m a n c e (with a small n u m b e r of exceptions for certain p a r a m e t e r settings). The average p e r f o r m a n c e of the SVD-based representations of 83% to 91% is satisfactory, a l t h o u g h inferior b y a b o u t 5% to 10%, to disambiguation with minimal m a n u a l i n t e r v e n t i o n (e.g., Yarowsky [1995]). 3
Computational Linguistics Volume 24, Number 1
4.2 Application to Information Retrieval
Our principal motivation for concentrating on the discrimination subtask is to ap- ply disambiguation to information retrieval. While there is evidence that ambiguity resolution improves the performance of IR systems (Krovetz and Croft 1992), several researchers have failed to achieve consistent experimental improvements for practi- cally realistic rates of disambiguation accuracy.
Voorhees (1993) compared two term-expansion methods for information retrieval queries, one in which each term was expanded with all related terms and one in which it was only expanded with terms related to the sense used in the query. She found that disambiguation did not improve the performance of term expansion. In our study, we will use disambiguation to eliminate document-query matches that are due to sense mismatches (that is, the word in question is used in different types of context in the query and the document). This approach decreases the number of documents that a query matches with whereas term expansion increases it. Another important difference in this study is that longer queries are used. Long queries (as they m a y arise in an IR system after relevance feedback) provide more context than the short queries Voorhees worked with in her experiments.
Sanderson (1994) modified a test collection by creating pseudowords similar to the ones used in this study. He found that even unrealistically high rates of disambiguation accuracy had little or no effect on retrieval performance. An analysis presented in Schfitze and Pedersen (1995) suggests that the main reason for the minor effect of disambiguation is that most of the pseudowords created in the study had a major sense that accounted for almost all occurrences of the pseudoword. Creating this type of pseudoword amounts to adding a small amount of noise to an unambiguous word, which is not expbcted to have a large effect on retrieval performance. To some extent, actual dictionary senses have the same property: one sense often accounts for a large proportion of occurrences. However, this is not necessarily true when rare senses are not taken into account and when high-frequency senses are broken up into smaller groups (the example of 'office space' vs. 'exhibition space'). Large dictionaries tend to break up high-frequency senses into such more narrowly defined subsenses. The successful use of disambiguation in our study may be due to the fact that rare senses, which are less likely to be useful in IR, are not taken into account and that frequent senses are further subdivided.
Good evidence for the potential utility of disambiguation in information retrieval was provided by Krovetz and Croft (1992). They showed that there is a considerable amount of ambiguity even in technical text (which is often assumed to be less ambigu- ous than nonspecialized writing). Many technical terms have nontechnical meanings that are used in addition to more specialized senses even in technical text (e.g.,
window
and
application
in computer magazines,convertible
in automobile magazines [Krovetz1997]). Krovetz and Croft also showed that sense mismatches (i.e., spurious matching words that were used in different senses in query and document) occurred significantly more often in nonrelevant than in relevant documents. This suggests that eliminating spurious matches could improve the separation between nonrelevant and relevant documents and hence the overall quality of retrieval results.
Schi~tze Automatic Word Sense Discrimination
sent word vectors in Word Space). In sense-based retrieval, documents and queries are also represented in a multidimensional space, but its dimensions are senses, not words. Words are disambiguated using context-group discrimination. Documents and queries that contain a word assigned to a particular sense have a nonzero value on the corresponding dimension.
The test corpus in Sch~tze and Pedersen (1995) is the Category B TREC-1 collection (about 170,000 documents from the Wall Street Journal) in conjunction with its queries 51-75 (Harman 1993). Sense-based retrieval improved average precision by 7.4% when compared to word-based retrieval. A combination of word-based and sense-based retrieval increased performance by 14.4%. The greater improvement of the combination is probably due to discrimination errors (i.e., the fact that discrimination is less than 100% correct), which are partially undone by combining sense and word evidence. Improvement was particularly high when small sets of documents were requested, for example, 16.5% (sense-based) and 19.4% (word- and sense-based combined) for a recall level of 10% of relevant documents. This experiment suggests a high utility of sense discrimination for information retrieval.
At first sight, sense-based retrieval may seem related to term expansion. Both sense-based retrieval and term expansion take individual terms as the starting point for modifying the similarity measure that determines which documents are deemed most closely related to the query. However, the two approaches are actually opposites of each other in the following sense. Term expansion increases the number of match- ing documents for a query. For example, if the query contains cosmonaut and expan- sion adds astronaut, then documents containing astronaut become additional nonzero matches. Sense-based retrieval decreases the number of matches. For example, if the word suit occurs in the query and is disambiguated as being used in the 'legal' sense, then documents that contain suit in a different sense will no longer match with the query.
5. D i s c u s s i o n
What distinguishes context-group discrimination from other work on disambiguation is that no outside source of information need be supplied as input to the algorithm. Other disambiguation algorithms employ various sources of information. Kelly and Stone (1975) consider hand-constructed disambiguation rules; Lesk (1986), Krovetz and Croft (1989), Guthrie et al. (1991), and Karov and Edelman (1996) use on-line dic- tionaries; Hirst (1987) constructs knowledge bases; Cottrell (1989) uses syntactic and semantic structure encoded in a connectionist net; Brown et al. (1991) and Church and Gale (1991) exploit bilingual corpora; Dagan, Itai, and Schwall (1991) use a bilingual dictionary; Hearst (1991), Leacock, Towell, and Voorhees (1993), Niwa and Nitta (1994), and Bruce and Wiebe (1994) exploit a hand-labeled training set; and Yarowsky (1992) and Walker and Amsler (1986) perform computations based on a hand-constructed semantic categorization of words (Roget's Thesaurus and Longman's subject codes, re- spectively).
Computational Linguistics Volume 24, Number 1
give a seed word or a set of good features for each sense of the word. They are more likely to satisfy a request by the system to choose the correct sense (e.g., by mouse click), if example contexts corresponding to different senses are presented without the requirement of additional user interaction. In an application like this, it is of great ad- vantage that context-group discrimination does not require any manual intervention to induce senses.
Another body of related work is the literature on word clustering in computational linguistics (Brown et al. 1992; Finch 1993; Pereira, Tishby, and Lee 1993; Grefenstette 1994a) and document clustering in information retrieval (van Rijsbergen 1979; Willett 1988; Sparck-Jones 1991; Cutting et al. 1992). In contrast to this earlier work, we cluster
contexts or, equivalently, word tokens here, not words (or, more precisely, word types)
or documents. The straightforward extension of word-type clustering and document clustering to word-token clustering would be to represent a token by all words it co- occurs with in its context and cluster these representations. Such an approach based on first-order co-occurrence is used, for example, by Hearst and Plaunt (1993) for the representation of tiles or document subunits that are similar to our notion of context. Instead, we use second-order co-occurrence to represent the tokens of ambiguous words: the words that occur with the token are in turn looked up in the training corpus and the words they co-occur with are used to represent the token. Second- order representations are less sparse and more robust than first-order representations. In a cluster-based approach, the subdivision of the universe of elements into clus- ters depends on the representation. If the representation does not capture the infor- mation crucial for distinguishing senses, then context-group discrimination performs poorly. The clearest such example in the above experiments is the pseudoword wide range~consulting firm. The algorithm does not do better than the baseline of always choosing the most frequent sense. The reason is that the representation captures only topic information. So a cluster will contain a group of contexts that are about the same topic. Unfortunately, the pair wide range can come up in text about almost any topic. Since there is no clear topical characterization of one sense of the pseudoword, context-group discrimination performs poorly.
The reliance on topical similarity m a y also be the reason that performance for pseudowords is generally better than performance for natural ambiguous words. All pseudowords except for wide range/consultingJirm are composed of two pairs from dif- ferent topics. For example, heart disease and reserve board pertain to biology and finance, respectively, two clearly distinct topics. On the other hand, the senses of some of the ambiguous words have less clear associations with particular topics. For example, one can be trained to perform a wide variety of activities, so the 'teaching' sense of train
can be invoked in m a n y different topics. Part of the superior performance for pseu- dowords is due to this different topic sensitivity of natural and artificial ambiguous words.