International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
365
Review Paper on Big Data Challenges and Cloud Computing
Pradeep Yadav
1, Seema Yadav
21
Department of Information Technology and Communication, Jaipur
2Jaipur Engineering College and Research Centre, Jaipur
Abstract—tremendous measure of information which is currently being gathered because of IOT, biomedical fields and online networking is termed as Big Data. As this data is very huge in volume it is very difficult to derive and analyse this data. Huge information is such on promotion due to its various applications in the division of Test information
examination (information mining), web-based social
networking investigation, portable information investigation, and so forth. Cloud computing is a most dominant innovation which performs huge scale and complex processing. It disposes of the necessity to keep up expensive registering equipment, committed space prerequisite and related programming. Monstrous development in the size of
information or huge information produced through
distributed computing has been distinguished. Idea of enormous information is a difficult and time-requesting task that requires an extensive computational space to guarantee fruitful information preparing and investigation. This paper incorporates definition, qualities, and arrangement of big data alongside certain Cloud Computing introduction.
Keywords—Big Data, Cloud Computing, Hadoop, HDFS.
I. INTRODUCTION
Big Data is a word utilized for nitty gritty data of massive measures of information which are either organized, semi organized or unstructured. The information which can't be dealt with by the conventional databases and programming Technologies then we partition such information as large information. The term Big Data is started from the web organizations who used to deal with inexactly organized (numerical structure, figures, and exchange information and so on.) or unstructured information (Email connections, Images remarks on long range interpersonal communication locales). The Big Datais created generally from the data innovation mechanical work, interpersonal interaction locales, messages, magazines and papers, and web journals covering the whole World Wide Web. Previously, decryption of human genome process takes around 10 years, presently not over seven days. Interactive media information have enormous load on web spine traffic and is relied upon to increment 70% by 2013. Just Google has got more than one million servers around the universes. There have been 6 billion portable memberships on the planet and consistently 10 billion instant messages are sent.
Constantly 2020, 50 billion gadgets will be associated with systems and the web.
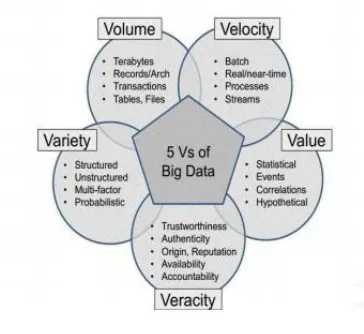
5 V’s that define Big Data:
Volume: Volume refers to the huge measure of
information produced each second. Volume
establishes of heap messages, video cuts, interactive media information, Facebook and twitters messages which are created and shared each second by individuals. Volume of information currently is bigger than terabytes and petabytes.
Velocity The term velocity means the speed with which information is created and handled to satisfy need. On New Year‟s Eve, the speed at which information is created increments asymptotically sticking the entire system. This delineates the disturbing speed at which the new information is created to the speed.
Veracity demonstrates information dependability as for enormous information misuse. Because of numerous types of enormous data, quality and exactness can’t be controlled much, for instance Twitter posts with hash labels, truncations, errors and casual discourse. Enormous information and investigation innovation enables us to work with veracious information. The volumes frequently compensate for the absence of value or exactness Value indicates worth as for enormous information
abuse. Since huge information isn't just extensive yet additionally unique and quickly developing. Some expository strategies are required so as to the endeavor a few significant data.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
[image:2.612.73.255.146.313.2]366
Figure 1: Big dataII. BIG DATA ANALYTICS CHALLENGES
In recent years enormous information has been gathered in a few spaces like medicinal services, open organization, retail, natural chemistry, and other interdisciplinary logical investigates. Online applications experience huge information every now and again, for example, social figuring, web content and archives, and web look ordering. Social figuring incorporates informal organization investigation, online networks, prescribed frameworks, notoriety frameworks, and forecast markets where as web look ordering incorporates ISI, IEEE Xplorer, Scopus, Thomson Reuters and so forth. Considering this favorable circumstances of enormous information it gives another open doors in the learning preparing assignments for the up and coming specialists. Anyway openings dependably pursue a few difficulties. To deal with the difficulties we have to know different computational complexities, data security, and computational strategy, to dissect huge information. For instance, numerous measurable techniques that perform well for little information estimate don't scale to voluminous information. Additionally, numerous computational methods that perform well for little information face noteworthy difficulties in dissecting huge information. Different difficulties that the well being area face was being examined by much scientists. Here the difficulties of huge information investigation are characterized into four general classifications to be specific information stockpiling and examination; learning disclosure and computational complexities; versatility and representation of information; and data security. We examine these issues quickly in the accompanying subsections:
1)Data Storage and Analysis :
Main challenge is storing huge amount of data and examining the huge diverse data. In recent years the size of data has grown exponentially. These information are put away on spending much expense while they disregarded or erased at last on the grounds that there is no enough space to store them. In this way, the main test for huge information investigation is capacity mediums and higher info/yield speed. In such cases, the information availability must be on the top need for the learning disclosure and portrayal. The prime reason is being that, it must be gotten to effectively and expeditiously for further examination. In past decades, expert utilize hard plate drives to store information however, it slower irregular info/yield execution than consecutive information/yield. Another challenge of Big Data examination is credited to decent variety or diversity of information. With the consistently developing of datasets, information mining assignments has essentially expanded. Moreover information decrease, information choice, highlight choice is a basic assignment particularly when managing huge datasets. Further design of machine learning algorithm to analyze such data and scalability of such machines is required.
2)Knowledge Discovery:
Knowledge discovery and representation is a prime target of big data. It incorporates various sub fields for
example authentication, archiving, management,
protection, information retrieval, and representation. There are several tools for knowledge discovery and representation such as soft set, near set, rough set, natural language processing , fuzzy set, formal concept analysis , principal component analysis etc.
3)Scalability of Data:
For the Scalability, it is important to create examining, on-line, and multi-goals examination strategies. Steady strategies have great adaptability property in the part of enormous information examination. As the information estimate is scaling a lot quicker than CPU speeds, there is a natural sensational move in processor innovation being inserted with expanding number of centres.
4)Security:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
367
There is a tremendous security hazard related with huge information. Security of huge information can be improved by utilizing the systems of confirmation, approval, and encryption.III. CLOUD COMPUTING AND BIG DATA
Big Data Analytics can be characterized as the utilization of cutting edge investigative systems on enormous information. Investigation of Big Data includes different information mining strategies to discover the targets. In this segment, we will quickly talk about different strategy of Data mining which is every now and again utilized in Big Data Analysis. AI: .Machine learning is a develop and all around perceived research region of software engineering, for the most part worried about the disclosure of models, designs, and different regularities in information. AI to bring PC to learn complex examples and make clever choices dependent on it.
Bunch Analysis: Clustering is an unsupervised procedure used to arrange substantial datasets in to correlative gatherings. No predefined class name exists for the information focuses or occasions. Bunching bunches information examples into subsets in such a way, that comparable cases are assembled, while diverse cases have a place with diverse gatherings and the gatherings are called as groups. Bunching can be ordered into Partitioning grouping, Hierarchical grouping, Density based bunching, Model based bunching, Grid based grouping.
Connection Analysis: Correlation is a strategy for exploring the connection between two quantitative, nonstop factors. Pearson's connection coefficient (r) is a proportion of the quality of the relationship between the two factors. As such, it deciding the low of connection among factors.
Factual Analysis: A gathering of computerized or semiautomated systems for finding beforehand obscure examples in information, including connections that can be utilized for forecast of client significant amounts. There are two computational hindrances for enormous information examination:
1) The information can be too huge to hold in a PC's memory; and
2) The registering undertaking can take too long to even think about waiting for the outcomes.
These boundaries can be drawn closer either with recently created factual strategies and additionally computational procedures Regression Analysis: Regression examination is a type of prescient demonstrating system which researches the connection between a reliant (target) and free factor (s) (predictor).
Regression investigation is a critical instrument for displaying and examining information. Seven relapse systems i.e Linear Regression, Logistic Regression, Polynomial Regression, Stepwise Regression, Edge Regression, Lasso Regression, ElasticNet Regression are utilized in Big Data examination. Most continuous procedures for Big Data investigation are direct
examination and polynomial examination. The
advancement of Cloud Computing have made
supercomputing progressively available and moderate. The utilization of these virtual PCs is known as distributed computing which has been one of the most vigorous enormous information system. Huge Data and cloud processing advances are created with the significance of building up an adaptable and on interest accessibility of assets what's more, information. Distributed computing fit enormous information, by on demand access to configurable figuring assets through virtualization systems. The advantages of using the Cloud figuring incorporate offering assets when there is an interest furthermore, pay just for the assets which are expected to create the item. All the while, it improves accessibility and cost decrease. Open difficulties and research issues of huge information what's more, distributed computing are talked about in detail by numerous specialists which features the difficulties in information the board, information assortment and speed, information stockpiling, information preparing, and asset the executives. So Cloud processing makes a difference in building up a plan of action for all assortments of utilizations with foundation and devices. Huge information application utilizing distributed computing should bolster information logical and improvement. The cloud condition ought to give devices that permit information researchers and business examiners to intelligently and cooperatively investigate learning securing information for further handling and separating productive outcomes. This can understand expansive applications that may emerge in different areas. Likewise, distributed computing ought to likewise empower scaling of devices from virtual advances into new advances like sparkle, R, and different sorts of enormous information handling procedures. Enormous information shapes a structure for talking about distributed computing alternatives. Contingent upon extraordinary need, client can go to the commercial center and purchase framework administrations from cloud administration
suppliers, for example, Google, Amazon, IBM,
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
368
The undeniable one is the time and cost that are expected to transfer and download enormous information in the cloud condition. Else, it winds up hard to control the conveyance of calculation furthermore, the basic equipment. Yet, the serious issues are security concerns identifying with the facilitating of information on open servers, furthermore, the capacity of information from human investigations. Every one of these issues will take enormous information and distributed computing to an abnormal state of improvement.Tools used for Big Data Analysis
IV. HADOOP
[image:4.612.338.536.203.319.2]The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures. This is a most accessible java based programming system which bolsters the handling of huge measure of information in a dispersed figuring condition. With the assistance of Hadoop, huge sum of informational indexes can be dissected over group of servers also, applications can be kept running on framework with thousands of hubs including terabytes of data.
Figure 2: Internal Transaction
HDFS is the canonical file system for Hadoop, but Hadoop’s file system abstraction supports a number of alternative file systems, including the local file system, FTP, AWS S3, Azure’s file system, and OpenStack’s Swift.
The file system used is determined by the access URI, e.g. file: for the local file system, s3: for data stored on Amazon S3, etc. Most of these have limitations, though, and in production HDFS is almost always the file system used for the cluster.
Figure 3: HDFS
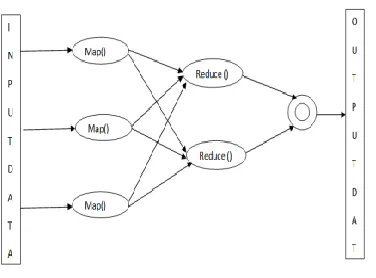
Map Reduce
[image:4.612.380.502.478.608.2]Map Reduce system is fundamentally used to compose applications that break down a lot of information so to speak and blame tolerant. At first the application is isolated into individual pieces which are examined by individual map employments by following the idea of parallelism. The aftereffect of map arranged by a structure and afterward sent to the reduce undertakings. The supervision is taken consideration by the system. The system parts the information into littler lumps that are prepared in parallel on group of machines by projects called mappers.
Figure 4: Mappers
V. IBMINFOSPHERE
[image:4.612.78.266.497.636.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 8, Issue 1, January 2018)
369
InfoSphere Information Server provides you with the ability to flexibly meet your unique information integration requirements — from data integration to data quality and data governance — to deliver trusted information to your mission-critical business initiatives (such as big data and analytics, data warehouse modernization, master data management and point-of-impact analytics).VI. CONCLUSION
In recent years data are generated at a numerous pace. Storing, Analyzing and processing these information is extremely difficult for general man. To this end in this paper, we review the different research issues, difficulties, and devices used to dissect these enormous information. From this review, it is comprehended that each huge information stage has its individual core interest. Some of them are intended for cluster handling though some are great at ongoing diagnostic. Each huge information stage additionally has explicit usefulness. Diverse systems utilized for the investigation incorporate factual examination, AI, information mining, smart investigation, distributed computing, quantum registering, and information stream preparing.
We believe that in future specialists will give more consideration to these systems to take care of issues of huge information successfully and proficiently.
REFERENCES
[1] D. P. Acharjya and Kauser Ahmed P IJACSA Vol. 7, No. 2, 2016 [2] M. K.Kakhani, S. Kakhani and S. R.Biradar, Research issues in big
data analytics, International Journal of Application or Innovation in Engineering & Management, 2(8) (2015), pp.228-232
[3] X. Jin, B. W.Wah, X. Cheng and Y. Wang, Significance and challenges of big data research, Big Data Research, 2(2) (2015), pp.59-64.
[4] A. Gandomi and M. Haider, Beyond the hype: Big data concepts, methods, and analytics, International Journal of Information Management, 35(2) (2015), pp.137-144
[5] A. Abouzeid, K. B. Pawlikowski, D. J. Abadi, A. Rasin, and A. Silberschatz. HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads. PVLDB,2(1):922–933, 2015