6433
Very Deep Convolutional Neural Network
Basedsarcasm Sentiment Detection And
Classification Model On Twitter
N.Vijayalakshmi Dr.A.Senthilrajan
Abstract: Present days, posting wry messages via web-based networking media like Twitter, Facebook, WhatsApp, and so forth. Has become another pattern to maintain a strategic distance from direct antagonism. Recognizing these circuitous pessimism i.e., mockery in the web-based social networking content has become a significant errand as they impact each business association. The property of mockery that makes it hard to investigate and distinguish is the hole between its exacting and expected significance. Along these lines, a mechanized framework is required for mockery identification in the information gathered from microblogging sites or interpersonal organizations which would be equipped for distinguishing genuine slant of a given book within the sight of mockery. This paper displays a novel element extraction based order model for the powerful location of mockery on Twitter. A lot of four groups of highlights are extricated: opinion related highlights, accentuation related highlights, syntactic and semantic highlights, and example highlights. At that point, the removed highlights experience characterization by the utilization of Very Deep Convolutional Neural Networks (VDCNN) to group tweets as wry and non-wry. VDCNN works legitimately at the charm level and usages just little convolutions and combining activities. The test approval of the proposed technique happens on the information gathered from Twitter and the outcomes are inspected as far as exactness, review and precision.
Index Terms: Twitter data, Social Networks, Pattern, Punctuation-related features, Syntactic and Semantic features, and Sentiment-related features Very Deep Convolutional Neural Networks (VDCNN)..
————————————————————
1 INTRODUCTION
EELING investigation in twitter has been foremost well-known investigation points in NLP (Natural Language Processing) in the previous time, as appeared in a few ongoing studies [1-2]; The objective of assumption examination to consequently identify the extremity of a twitter message, while mocking or unexpected proclamation changes the extremity of an evidently P or N articulation into it inverse. So it is imperative to separate snide articulation from the expressions that express P or N frames of mind without mockery [3]. Mockery discovery is viewed as a significant part of language which merits unique consideration given its pertinence in fields, for example, assessment examination and feeling mining [4]. The issue of programmed mockery discovery in twitter has been tended to in the previous hardly any years, the mockery identification is typically considered as a grouping issue, past approaches for the most part depended on highlights displaying to the single tweet [5]. Numerous creators grasp a general view on incongruity, as communicating an inverse or distinctive significance based on what is actually said [6]. Under this viewpoint, the nearness of incongruity related non-literal gadgets is getting one of the most fascinating angles to check with regards to online life corpora since it can assume the job of extremity reverser concerning the words utilized in the content thing [7].In any case, an assortment of kinds of non-literal mails can be perceived in (TW) tweets: beginning incongruity to snide posts, and to clever TW that can able to fun loving, planned for entertaining or at reinforcing ties with different clients. Amusing and wry gadgets can express unique relational importance, evoke diverse full of feeling responses, and can act
distinctively as for the extremity inversion marvel [8].
In this way to recognize them can be significant for improving the exhibitions of frameworks in slant investigation. As indicated by the writing, limits in significance between incongruities, mockery etsimilia are fluffy. While a few creators consider incongruity as an umbrella term covering likewise mockery [9-10], others gives bits of knowledge to a partition. Mockery has been perceived in [11] with a particular objective to assault, increasingly hostile, and "personally connected with specific pessimistic full of feeling states" [12], while incongruity has been viewed as progressively like deriding in a sharp and non-hostile way [13]. The utilization of non-literal language has been considered likewise in web-based social networking, however most scientists center around incongruity or mockery independently. Computational models for mockery discovery [14-16] and incongruity identification [17] in online life has been proposed, for the most part focused on Twitter. Just a couple of starter ponders tended to the assignment to explore the contrasts among incongruity and mockery [18-19]. The present work plans to additionally add to this subject.
2
R
ELATED WORSKResearchers have recommended numerous techniques for the TSA. In this scenario, a describe evaluation of few major contributions to the existing related works are presented. Jianqiang, Zhao, GuiXiaolin, and Zhang Xuejun, [20] developed a word embeddings strategy dependent on enormous twitter information with the assistance of solo learning by joining co-event factual trademark and inert relevant semantic connections between words in tweets. The assumption highlights of tweets were shaped by consolidating the word conclusion extremity score and n-gram includes in word inserting. The conclusion order names were anticipated by highlight set which was coordinated into profound convolution neural system (DCNN). The productivity of word inserting strategy was approved by leading trials on five datasets when contrasted and existing methods. The pre-prepared word vectors utilized in DCNN had great execution in the undertaking of TSA. While grouping the nostalgic substance in huge dataset, the computational time turns into
F
————————————————
N.Vijayalakshmi Research Scholar, Department of Computational Logistics, Alagappa University, Karaikudi 630003.,
E-mail: [email protected]
6434 somewhat high. M.Z. Asghar, F. M. Kundi, S. Ahmad, A. Khan,
and F. Khan, [21] proposed a half and half characterization system to defeat the issues of off base order. The exhibition of twitter-based SA frameworks were improved by utilizing four classifiers, for example, a slang classifier, a moticon classifier, the SentiWordNet (SWN) classifier. The information content was gone through the initial two classifiers, for example, emoji and slag, subsequent to applying the preprocessing stage. In the last phase, SWN‐based and d‐s classifiers were fetched to arrange the content precisely. A confinement of the methodology was the absence of programmed scoring of domain‐specific words short of playing out a query activity in SWN, which possibly will build the grouping precision.
H. Ameur, et al., [22] suggested a Contextual Recursive Auto-Encoders for foreseeing the extremity of estimation name at sentence and word (wrd) level. The diminished word vectors by utilizing the Point wise M-I and CoRAE recursively consolidated the every individual word with its neighbor's setting word vectors by word request. The sentence vector portrayal was produced by utilizing these persistent word portrayal. The proficiency of CoRAE was approved by utilizing Sanders TW remarks corpus datasets. The strategy gives terrible showing in characterization precision when the introduction of restrictions setup of auto-encoders calculation was fewer.
F. Bravo-Marquez, et al., [23] executed a technique for assessment dictionary extension for consequently clarified tweets from three kinds of data sources, for example, tweets of emoji explained, hand-commented on and unlabelled tweets. The space explicit issue was handled by moving the strategy into explanation approach for unlabelled tweets. The dissmbiguated grammatical form (POS) was remembered for the extended dictionary for three extremity classes, for example, P, N and unbiased. The direct connection among slant and words were found out by utilizing PMI-semantic direction (PMI-SO) and stochastic inclination plunge SO (SGD-SO). 3 datasets, for example, 6HC, Sanders and SemEval were utilized to approve the regulated vocabulary systems. This methodology utilized the work escalated way to deal with diminish the clamor in marked POS-disambiguated words, however it fresh the information just by physically.
I. Alsmadi, and GanKengHoon, [24] structured an administered term weighting approach (SW) for considering the exceptional attributes of short messages in high-dimensional vector. The SW strategy estimated the quality of a term in report to adapt to the meager condition and brevity of short content. The examinations were done on 2 datasets, for example, Sanders and self-gathered dataset to approve the viability of SW. When contrasted and solo methods, the SW strategy achieved shifted execution and prevalently well. The constraint of this SW technique was its petite messages in informal organizations which incorporates quick nature, nearness of incorrect spellings and much dimensionality of its element space which drives lackluster showing in grouping precision. H. S. Manaman, et al., [25] proposed a half breed strategies for data portrayal known as N-gram learning approach and casings. The N-gram approach comprises of two stages in particular preparing and test step. The preparation step contains four profiles for each organization and utilized 80% of accessible tweets to construct the
organization profiles. The staying 20% information were utilized to approve the effectiveness of N-gmattitude in test stage. The trials were led on Sanders and accomplished higher arrangement precision when contrasted and NN, Bayesian technique. The calculation work sum for N-gram founded characterization strategy was better high.
3 PROPOSED WORK
This paper presents a novel feature extraction based classification model for the effective detection of sarcasm on Twitter. A setof four relatives of structures are take out: sen-related, pun-sen-related, syntactic and semantic, and pattern features. Then, the extracted features undergo classification by the use of Very Deep Convolutional Neural Networks (VDCNN) to categorize TW as sarcastic and non-sarcastic. VDCNN functions directly at the charm range and use minor convolution spooling tasks. The proposed flow diagram is exposed in the fig.1.
Fig.1.The proposed flow diagram.
In this part we depict the assets utilized in our work. There are 5 arrangements of TW slithered from the TW utilizing the Twitter Streaming API and handled over and done with Flume before being put away in the HDFS. Altogether, 1.45 million TW were gathered utilizing catchphrases #sarcasm, #sarcastic, mockery, wry, cheerful, appreciate, miserable, great, awful, love, euphoric, loathe, and so forth. In the wake of preprocessing, around 156,000 tweets were originate as wry. The rest of the tweets roughly 1.294 million were not mocking. Each set enclosed an alternate amount of tweets. Contingent upon the quantity of TW in each set, the creeping time is given in Table 1.
Table.1. Datasets captured for experiment and analysis.
Datasets No. of
TW (approx)
Extraction period (h)
1 5,000 1
2 51,000 9
3 100,000 21
4 250,000 50
5 1,050,000 187
3.1 Preprocessing
The procedure changes over the datasets, which is in a reasonable structure for the PC is alluded as pre-preparing. The snide proclamation must have an objective. What's more, it relies upon the wellspring of the corpus, regardless of whether to recognize these objectives or not. Like in an audit everybody focuses on the item, while in tweets because of unstructured and short printed substance with various exceptional images; endeavors to distinguish the objective isn't worth. While in mockery recognition, preprocessing of information incorporates two stages, for example, Tokenization and Stop words evacuation.
6435 next level to preprocessing. It can be a single word or course
of action of words. To accomplish tokenization maker presented TextBlob pack in NLTK. Apache OpenNLP is used to perform NLP assignments like tokenization, lemmatization, etc.
Stop words removal: These are the unessential words, (for example, "a", "you a") which are sifted through afore handling of regular semantic information. The information from internet based life, surveys, and gatherings contain different unessential words which increment the preparing time; along these lines, removable of such undesirable words or strings streamline handling.
3.2 Feature Extraction
In this proposed system4 set of features are take-out such as S-R, P-R, syntactic and semantic, and pattern-f.
Sentiment-related features
So as to catch the Positive (P) or Negative (P)extremity of words in a line. Three unique marks were utilized to get the estimation communicated in tweets: P, N and a complete worth (that thinks about both P and N qualities). The assessment assets we abused can be part in two classes: those made by basic records out of P and N words, and those where every word is marked with a conclusion quality in a scope of extremity esteems (from P to N). In the principal case, so as to acquire the P and N score for each tweet we aggregate the quantity of words having a place with every classification (P or N articulations). For assets doling out a score value of numerals differing in a scope of force for the extremity valence, the P/N score is the whole of all the P/N qualities in a tweet. In the two cases, the all-out worth is characterized as the contrast between the P and N score. In absolute 24 assumption highlights were acquired from nine unique assets. Punctuation-related features
This marks have been broadly fetched in incongruity recognition. Some lexical imprints help the essayist to call attention to the sense and significance in a book. As per the utilization of some printed variables (for example accentuation marks) may give solid insights for recognizing amusing goal in internet based life contented. In short messages like tweets this sort of viewable prompts can accomplish the genuine expectation behind the exacting substance in the articulation. In IDM, the accentuation imprints and capitalized words are measured as lexical indicators to recognize amusing from non-unexpected expressions.
Semantic features
The fundamental test in Paraphrase Identification and Semantic Text Similarity investigation is to characterize the sets of sentences dependent on their importance similitude, semantic highlights are required. Notwithstanding the NER cover highlights (registered as a component of the content cover includes), the theme displaying highlights were processed. With respect to Arabic NER comment, a few devices can be found to help this errand. For this examination, the Polyglot was utilized to clarify the tweets with their comparing NER labels. The Polyglot just labels the Person, Organization, and Location substances. Lastly the example highlights are removed.
After gaining the feature extraction process, the classification process is taken by using the VDCNN algorithm.
4 VERY DEEP CONVOLUTIONAL NEURAL NETWORK
The general engineering of our system is appeared in Fig. 2. Our classical starts with a look-into table that produces a 2D
tensor of dimension (f0, s) that comprise the installing's of the S characters. S is static to 1024, and f0 can be viewed as the "RGB" measurement of the information content.
Fig.2. overall architecture of our network.
We initially apply one layer of 64 convolutions of size 3, trailed by a pile of worldly "convolutional squares". Propelled by the way of thinking of VGG and ResNets we apply these two plan rules:
(i)for a similar yield transient goals, the layers have a similar number of highlight maps,
(ii)At the point when the worldly goals is divided, the numeral of highlight maps is multiplied over. This lessens the memory impression of the system. The systems contains 3 pooling activities (splitting the worldly goals each time by 2), bringing about 3 degrees of 128,256 and 512 element maps.
The yield of these conv squares is a tensor of size 512 × sd, where sd = s 2 p with p = 3 the quantity of down-examining activities. At this degree of the conv organize, the subsequent tensor can be viewed as a significant level portrayal of the information content. Since we manage cushioned info content of fixed size, sd is consistent. Be that as it may, on account of variable size information, the CE gives a portrayal of the info message that relies upon its underlying length s. Portrayals of a book as a lot of vectors of variable size can be significant specifically for neural machine interpretation, specifically when joined with a consideration model. Transient conv with portion size 3 and X include maps are indicated "3, Temp Conv, X", completely associated layers which are direct projections (grid of sizeI × O) are meant "fc(I,O)" and"3-max pooling, walk 2" signifies fleeting max pooling with bit size 3 and walk 2.
The vast majority of the past utilizations of ConvNets to NLP utilize an engineering which is fairly shallow (up to 6 convolutional layers) and consolidates convolutions of various sizes, for example crossing 3, 5 and 7 tokens. This was persuaded by the way that convolutions remove n-gram includes over tokens and that distinctive n-gram lengths are expected to show short-and long-range relations. In this effort, we suggest to make rather an engineering which utilizes numerous layers of little conv (size 3). Stacking 4 layers of such conv brings about a range of 9 tokens, yet the system can learn independent from anyone else how to best join these distinctive "3-gram highlights" in a profound various leveled way. Our design can be in truth observed as a fleeting adjustment of the VGG arrange. We have additionally explored a similar sort of "ResNet alternate way" associations as, in particular character and 1 × 1 conv.
6436 about highlights are changed into a solitary vector which is the
contribution to a three layer completely associated classifier with ReLU shrouded units and softmax yields. The quantity of yield neurons relies upon the arrangement task, the quantity of concealed divisions is fixed to 2048, and k to 8 in all tests. We don't utilize drop-out with the completely associated layers, however just fleeting cluster standardization after convolutional layers to legalize our system.
4.1 Convolutional Block
Every individual conv square is a grouping of two convolutional layers, every one pursued by a transient Batch Norm layer and a ReLU enactment. The bit dimensions of entire the transient conv is 3, with cushioning to such an extent that the worldly goals is safeguarded (or split on account of the convolutional pooling with walk 2, see underneath). Consistently expanding the profundity of the system by including more conv layers is doable gratitude to the set sum of limits of little convolutional channels in all layers. Various profundities of the general design are gotten by shifting the quantity of convolutional hinders in the middle of the pooling layers (see table 2). Transient bunch standardization applies a similar sort of regularization as clump standardization with the exception of that the actuations in a smaller than normal cluster are together standardized over fleeting (rather than spatial) areas. Along these lines, for a little cluster of size m and highlight maps of worldly size s, the whole and the SD identified with the Batch Norm calculation are occupied above |B| = m • s terms.
We investigate 3 sorts of down-inspecting between squares Ki and Ki+1:
i. The chief conv layer of Ki+1 has walk 2 (ResNet-like). ii. Ki Is trailed by a k-max pooling coat where k is with the end goal that the resolution is split.
iii. Ki Is trailed by max-pooling with part size 3 and walk 2 (VGG-like).
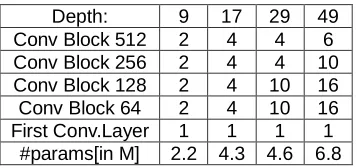
Every one of these sorts of pooling lessen the transient goals by a factor 2. At the last conv layer, the goals is hence sd. In this work, we have investigated four profundities for our systems: 9, 17, 29 and 49, which we characterize just like the quantity of conv layers. The profundity of a system is gotten by adding the quantity of squares with 64,128,256 and 512 channels, with each square containing two conv layers. The system has 2 squares of each kind, bringing about a profundity of 2 × (2 + 2 + 2 + 2) = 16. Including the absolute first conv layer, this wholes to a profundity of 17 conv layers. The profundity would thus be able to be expanded or diminished by including or evacuating convolutional obstructs with a specific sum of channels. The finest designs we watched for profundities 9,17,29 and 49 are portrayed in T. 2. We additionally contribute the quantity of limits of all C layers.
Table.2. No. of conv. layers per depth.
Depth: 9 17 29 49 Conv Block 512 2 4 4 6 Conv Block 256 2 4 4 10 Conv Block 128 2 4 10 16 Conv Block 64 2 4 10 16 First Conv.Layer 1 1 1 1
#params[in M] 2.2 4.3 4.6 6.8
5
RESULT AND DISCUSSIONThis part brief around the investigational outcome and conversation of the novel scheme and also complete about the presentation metric, investigational setup, quantitative study and comparative investigation. The proposed framework was executed utilizing Python code with RAM size of 4 GB, hard disk have 1 TB, and 3.0 GHz Intel i5. The exhibition of the anticipated framework was contrasted and other arrangement techniques and previous examination study dependent on twitter dataset so as to survey the viability of proposed framework. The exhibition of suggested framework was assessed as far as exactness, review, order precision, and f-measure.
5.1 Performance Measure
This is considered as the normal approximation of outcomes and that makes solid data about the adequacy of the suggested outline. Additionally, the show the stimulation measure is the manner toward revealing and dissecting data almost the exhibition. Disarray metric to assess classifier for parallel information is appeared in Table 3 and could be comprehended in the accompanying terms:
Table 3: Confusion Matrix
Predicted P Predicted N Actual P True P (TP) False P (FP) Actual N False N (FN) True N (TN)
TrueP speaks to the real P cases which are ordered accurately as P while false P (FP) speaks to real P mistakenly named N. Thus, true Ns (TN) are real N occasions and furthermore accurately delegated N and false Ns (FN) are real N examples and inaccurately named P. The measured equation of accuracy, f-m, precision, and recall are signified in the Eq. (1), (2), (3), and (4).
Accuracy=(TN+TP)/(TP+TN+FN+FP)×100 (1)
F-measure=2TP/((2TP+FP+FN))×100 (2)
Precision=TP/((FP+TP) )×100 (3)
Recall=TP/((FN+TP) )×100 (4)
5.2 Performance Analysis of Proposed Decision Tree
In this investigational, pretend twitter information is utilized for contrasting the exhibition assessment of existing procedures and the suggested methodology as far as exactness, F-measure, accuracy and review. Two arrangement of examinations under different test conditions are directed in twitter datasets. The investigations fundamentally intend to decide the best directed methodology when contrasted and Auto encoder, LSTM, CNN and VDCNN. The VDCNN is determined for every one of the subject based content characterized tweet of Sanders corpus. This grouping helps the association in concentrating on tweets with most elevated effects. The discourse of VDCNN of Sanders characterized subjects in consequent areas are speaks to beneath.
Performance Analysis in terms ofPr, Rcl and F-M
6437 with previous methods such as RF and MLP in Table 4.
Table 4: Performance of VDCNN for three classes.
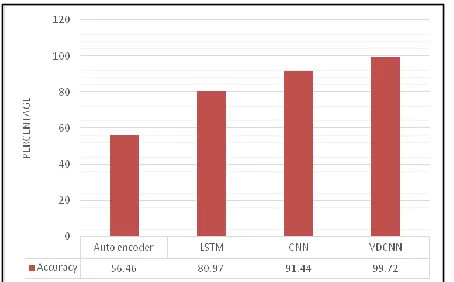
In the above table, shows that the relative examination of the different classifier with the proposed VDCNN for three diverse class. From the examination shows that the proposed VDCNN technique give better outcomes regarding Precision 93% for P assessments, Recall 51% for N suppositions and for common slants Our proposed VDCNN file 96% of execution. The grouping precision of proposed VDCNN are contrasted and existing methods, for example, Auto encoder, LSTM and CNN. Figure 3 speaks to the exactness estimations of proposed technique with existing framework.
Fig.3. Performance of VDCNN in terms of Accuracy.
From the test outcomes, the projected VDCNN accomplished advanced precision (i.e 99.72%) for twitter notion arrangement. The outcomes show that the proposed VDCNN demonstrates its ability to upgrade the segregating intensity of terms for tweet order. The proposed technique can help in dimensionality decrease, estimation examination, spam discovery, and numerous different applications that face various difficulties of tweet. In this way, the proposed plan mitigates the impact of these difficulties on the exhibition of the grouping task. In spite of the fact that our outcomes have been accomplished for information from Twitter, one of the most widely recognized web based life stages, we accept this proposed strategy is likewise appropriate to other web-based social networking.
6 CONCLUSION
TSA is one of the rising examination fields for breaking down and recognizing the assessments and perspectives of clients. The proposed strategy comprises of two phases, for example, Feature extraction and order of TW. The gained TW
information is pre-handled by killing the superfluous emoticon from the TWworth action. The assumption related highlights, accentuation related highlights, syntactic and semantic highlights, and example highlights are improve the proposed framework results. Contrasted with other existing methodologies in TSA, the proposed plan conveyed a powerful presentation by methods for exactness, F-Measure, accuracy and review. The created methodology improved the characterization accuracy and review pace of around 3-15% contrasted with the past techniques. In upcoming effort, to recover the characterization rate, a half breed estimation attitude will be produced for added internet based life information, for example, YouTube and Facebook to recognize the feeling of individuals near specific concerns.
Acknowledgments
NA
REFERENCES
[1] Liu, Bing, and Lei Zhang. "A survey of opinion mining and sentiment analysis." Mining text data. Springer, Boston, MA, 2012. 415-463.
[2] Tsytsarau, Mikalai, and Themis Palpanas. "Survey on mining subjective data on the web." Data Mining and Knowledge Discovery 24.3 (2012): 478-514.
[3] Davidov, Dmitry, Oren Tsur, and Ari Rappoport. "Semi-supervised recognition of sarcastic sentences in twitter and amazon." Proceedings of the fourteenth conference on computational natural language learning. Association for Computational Linguistics, 2010. [4] Pang, Bo, and Lillian Lee. "Opinion mining and sentiment analysis."
Foundations and Trends® in Information Retrieval 2.1–2 (2008): 1-135.
[5] Wang, Zelin, et al. "Twitter sarcasm detection exploiting a context-based model." International Conference on Web Information Systems Engineering. Springer, Cham, 2015.
[6] R. W. Gibbs Jr, J. O’Brien, Psychological aspects of irony understanding, Journal of pragmatics 16 (6) (1991) 523–530. [7] A. Reyes, P. Rosso, On the difficulty of automatically detecting irony: Beyond
a simple case of negation, Knowl. Inf. Syst. 40 (3) (2014) 595–614.
[8] C. Bosco, V. Patti, A. Bolioli, Developing corpora for sentiment analysis: The case of irony and Senti-TUT, IEEE Intelligent Systems 28 (2) (2013) 55–63.
[9] R. L. Brown, The pragmatics of verbal irony, Language use and the uses of language (1980) 111–127.
[10] R. J. Kreuz, R. M. Roberts, The empirical study of figurative language in literature, Poetics 22 (1) (1993) 151–169.
[11] A. Bowes, A. Katz, When sarcasm stings, Discourse Processes: A Multidisciplinary Journal 48 (4) (2011) 215–236.
[12] S. McDonald, Neuropsychological studies of sarcasm, in: H. Colston, R. Gibbs (Eds.), Irony in language and thought: A cognitive science reader, Lawrence Erlbaum, 2007, pp. 217–230.
[13] L. Alba-Juez, S. Attardo, The evaluative palette of verbal irony, in: G. Thompson, L. Alba-Juez (Eds.), Evaluation in Context, John Benjamins Publishing Company, 2014, pp. 93–116.
[14] D. Davidov, O. Tsur, A. Rappoport, Semi-supervised recognition of sarcastic sentences in Twitter and Amazon, in: Proceedings of the Fourteenth Conference on Computational Natural Language Learning, CoNLL ’10, Association for Computational Linguistics, 2010, pp. 107–116.
[15] R. Gonzalez-Ib ´ a´nez, S. Muresan, N. Wacholder, Identifying sarcasm in Twitter: ˜ a closer look, in: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: short papersVolume 2, Association for Computational Linguistics, 2011, pp. 581–586.
[16] D. Maynard, M. A. Greenwood, Who cares about sarcastic tweets? Investigating the impact of sarcasm on sentiment analysis, in: Proceedings of the 9th International Conference on Language Resources and Evaluation, European Language Resources Association, 2014, pp. 4238–4243.
6438 (ELRA), Istanbul, Turkey, 2012, pp. 392–398, aCL Anthology Identifier:
L12-1386.
[18] A. P.-Y. Wang, #irony or #sarcasm — a quantitative and qualitative study based on Twitter, in: Proceedings of the 27th Pacific Asia Conference on Language, Information, and Computation (PACLIC 27), Department of English, National Chengchi University, 2013, pp. 349–356.
[19] F. Barbieri, H. Saggion, F. Ronzano, Modelling sarcasm in Twitter, a novel approach, in: Proceedings of the 5th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Association for Computational Linguistics, Baltimore, Maryland, 2014, pp. 50–58.
[20] Jianqiang, Zhao, GuiXiaolin, and Zhang Xuejun. "Deep convolution neural networks for Twitter sentiment analysis." IEEE Access vol. 6, pp. 23253-23260, 2018.
[21] M.Z. Asghar, F. M. Kundi, S. Ahmad, A. Khan, and F. Khan, ―T‐SAF: Twitter sentiment analysis framework using a hybrid classification scheme‖, Expert Systems, vol. 35, no. 1, e12233, 2018.
[22] H. Ameur, Salma Jamoussi, and Abdelmajid Ben Hamadou. "A New Method for Sentiment Analysis Using Contextual Auto-Encoders." Journal of Computer Science and Technology 33.6 (2018): 1307-1319.
[23] F. Bravo-Marquez, Eibe Frank, and Bernhard Pfahringer. "Building a Twitter opinion lexicon from automatically-annotated tweets." Knowledge-Based Systems 108 (2016): 65-78.
[24] Alsmadi, I. and Hoon, G.K., 2019. Term weighting scheme for short-text classification: Twitter corpuses. Neural Computing and Applications