4822
Protecting Sensitive Data In Big Data Using
Privacy Preservation And Data Confidentiality
B.Vinothini, R.Anitha, S.Priyanka, S.Sangavi, N.Saranya
Abstract: Data mining is one of the radically developing fields today. Human services information, client information, share market, sellers and other online networking information are having the Private data about individuals. Private data can entice terrible individuals to abuse. For instance, LIC representatives can use wealthiest individuals and hospitalized individuals data for their showcasing. It irritates and makes the general population apprehensive and attempt conceal themselves from the intermediaries .Remembering the goal to spare individuals , give security this paper proposed PPDM with get to impediment and ensuring delicate information by Generalization, Suppression, Anatomization, Permutation and Perturbation strategies. Here, we look at the security problems found in Data mining from high extensive viewpoint and researches varies forms that can assure secured data. Specifically, we identify varies distinct methods of clients needed in Data mining applications in specific information supplier, data authority, data digger, and leader. For each client, here discuss the security problems and techniques which can be received for ensuring important data. We quickly present the important points of related research points, survey cutting edge methods, and demonstrate few preparatory considerations on upcoming research headings.
Index Term: Data mining, PPDM, Generalization, Suppression, k- anonmity, DataProvider, Datacollector, Dataminer, Decision Maker
—————————— ——————————
I.INTRODUCION
Network security includes certain approaches and methods to counteract and screen unapproved wanted to, abduct, change, or disavowal of a laptop system and system open data. It incorporates the endorsement of process data in a framework, which is monitored by the framework chief. Clients selects are given an ID and secret code or other correct information that allows them to process data and concentrate inside their power. Network security contains an array of personal systems, each open and personal, that are used as a part of ordinary occupations, leading exchanges and interchanges amongst institutions, government offices and folks. Systems can be personal, for example, with an organization and rest which may be available to community. Network security is included Several associations, ventures, and several sorts of organizations.
II.RELATED WORK
A. A OVERVIEW ON PRIVACY PRESERVING DATA MINING Data mining is generally contemplated and also connected into different fields, for example, Internet of Things (IoT) and business advancement. Be that as it may, information mining strategies likewise happen genuine difficulties because of expanded touchy data exposure and security infringement.
Privacy Preserving Data Mining (PPDM), is an imperative division of Data mining and a fascinating theme in security protection, had increased exceptional consideration as of late. Separating helpful data and uncovering designs from a lot of information, PPDM additionally shields private and delicate information from revelation without the consent of information proprietors or suppliers. This paper surveys primary PPDM Framework by considering PPDM structure. We think about the view and drawbacks of various PPDM systems and talk about valid issues .
B. PPDM FRAMEWORK
They characterize a PPDM structure by alluding to direct our PPDM specialized survey. The PPDM structure contains three layers: Data Collection Layer (DCL), Data
Processing Layer (DPL) Data Mining Layer (DML).
C.DATA COLLECTION LAYER
Data collection layer means to shield crude information from revelation without the supplier authorization. Since the crude information is gathered specifically from the information suppliers, the security safeguarding in the DCL can be viewed as the security safeguarding amid information accumulation. By and large, there are two strategies used to conceal the crude information from its unique esteem. The main strategy is to encode all the crude information so thatnobody can get to the plain information with the exception of approved information processors or mineworkers. Though, huge sums of information would prompt to enormous computational cost for both information suppliers and information excavators. It is infeasible to scramble all the crude information, all things considered, applications. The second strategy is to annoy unique information values with a specific end goal to shroud genuine private data. As of now, there are numerous information adjustment strategies proposed for the security protecting information gathering. Most information alteration techniques utilized amid information accumulation in the DCL may be characterized into 2 gatherings: esteem dependent techniques and measurement dependent strategies. Computational cost for ____________________
B.Vinothini is currently working as Assistant Professor of CSE department in Bannari Amman Institute of Technology at sathyamangalam ,[email protected] R.Anitha,S.Priyanka currently working as Assistant Professor of CSE department in Bannari Amman Institute of Technology at sathyamangalam,
S.Sangavi currently pursuing ME-CSE in Bannari Amman Institute of Technology
N.Saranya currently working as Assistant Professor in Park college of Engineering and Technology.
4823 both information suppliers and information excavators. It is
infeasible to scramble all the crude information, all things considered, applications. The second strategy is to annoy unique information values with a specific end goal to shroud genuine private data. As of now, there are numerous information adjustment strategies proposed for the security protecting information gathering. Most information alteration techniques utilized amid information accumulation in the DCL may be characterized into 2 gatherings: esteem dependent techniques and measurement dependent strategies.
D.DATA PRE-PROCESSING LAYER
Data Pre-Process layer are frequently viewed as believed servers to save entire unique or pre-prepared informational indexes. Not the same as the information irritation techniques utilized amid information gathering in the DCL, the security conservation performed in the DPL needs the information of an entire informational collection. The most well-known technique utilized for protecting delicate information in DPL information anonymization (e.g., k-anonymization), which was intended in anticipate revealing the characters of information proprietors in freely accessible records.
E.DATA MINING
Data mining servers at DML can be separated into two sections. First One pre-preparing information before mining so as to empower security protecting highlights. The other is safeguarding security when different gatherings together run an Data mining calculation. The principle information preprocessing strategies, including esteem based information irritation, measurement based information annoyance and anonymization, have been presented. The joint Data mining among various gatherings is frequently concentrated by considering the circulation of informational indexes. The information sets can be evenly dispersed or vertically disseminated (allude to the definitions beneath). For neither a evenly dispersed nor vertically appropriated informational collection, Secure Multiparty Computation (SMC) is right now descibed as a key system for security safeguarding Data mining mutually directed by different parties.
II.
PROPOSED MODEL
The point of privacy preserving Data mining (PPDM) calculations is to remove pertinent Data from a lot of information during ensuring at the similar time delicate data. An essential angle in the outline of such calculations is the distinguishing proof of appropriate assessment criteria and the advancement of similar benchmarks. Late research in the region has committed much push to decide a exchange off between the privilege to protection and the need of information disclosure. It is frequently the case that no safety saving calculation prevails that outflanks all the others on all acceptable criteria. Accordingly, it is urgent to give an exhaustive see on an arrangement of measurements identified with existing protection saving calculations so that we can pick up bits of knowledge on the best way to outline more successful estimation and PPDM calculations. which are the principle objectives a PPDM calculation ought to implement:
• A PPDM calculation ought need to keep the disclosure of delicate data.
• It should be impervious to the different Data mining procedures.
• It ought not trade off the get to and the utilization of non delicate information.
• It ought not have an exponential computational resourceful quality.
• Privacy level offered by a security protecting strategy, which shows how nearly the delicate data has been covered up.
• Hiding disappointment, that is, the part of delicate data that is not covered up by the use of safeguarding strategy.
• Complexity that defines the capacity of a security protecting calculation to execute with great execution as far as every one of the assets suggest.
Fig.1. Representation of PPDM
III.
PROPOSED WORK MODEL
With a specific goal to give a security to private information, there are four distinctive security models are connected on the information traits. They are:
1) Identifier: Attributes that can straightforwardly and particularly realize an individual, for example, name, ID
2) numbers and portable number. Semi identifier: Attributes that can be linked with outer information to re-recognize singular record that a needs to cover.
3) Non-delicate Attribute: Attributes other than ID, QID and Dedicate Attribute.
4) Delicate Attribute: Attributes that an individual needs to cover, for instances, ailment and compensation.
4824 various records. Every record consists of the
four sorts of attributes. Protecting delicate data is the true aim of all IT safety efforts. Two in number contentions for conforming delicate data are to dodge data fraud and to conserve protection.
• The inappropriate divulgence of delicate information can likewise bring about damage and impact to understudies, workforce, and staff members, and possibly hurt the notoriety of an Institute. Consequently, it is further bolstering everybody's good fortune to guarantee that delicate data is secured.
C. Data provider
Data Provider Definition is utilized only to retrieve Data from social information sources in non-constant applications. It deals with the information at every phase by mapping the consistent segment definitions in the Application View to physical table sections in the client database. This may include an immediate mapping of segments or SQL questions to choose or infer sections and records as required. For instance, the noteworthy information used to fabricate the model may originate from the distribution center, and the information being scored may originate from the operational framework. The Data Provider Definition additionally indicates the information source and qualifications used to get information.
D.Data collector
Data Collector is the way toward social events and calculating info on focus matters in a set up methodical art, which then impulse one to answer pertinent inquiries and assess results. The segment of researches is basic to all departments of study including physical and sociologies, humanities and business. It helps us to collect the basic focuses as assembled data. While strategies differ by train, the accentuation on guaranteeing exact and legit gathering continues as before. The aim for all information gathering is to identify quality confirmation that then meant rich data investigation and permits the working of a persuading and fast response to enquiries that have been postured.
E. Data miner
Data mining is a procedure utilized by institutions to transform secured information into useful data. By using programming to search -for instances, in costly clusters of information, institutions can take in more about their customers and develop more successful advertising techniques and additionally increment ideas and abatement costs.
F.Decision maker
Decision Maker can gain the information mining gained about straightforwardly from the Data miner from some data Transmitter. It is likely that the data transmitter changes the mining comes about purposefully or inadvertently which may bring about genuine misfortune to the leader. Subsequently, what the chief concerns is if the mining outcome are believable. Examine the security assurance approaches embraced by every client part, in this
paper we underline a typical kind of approach to be specific and they are hypothetical approach that are linked to numerous issues including security insurance in Data mining. In, Data mining situation, every client needs after high self-interests as far as security conservation or data utility, and the utility of different clients are connected. Henceforth the associations among various clients can be deployed as an amusement. utilizing systems from diversion hypothesis, we can get valuable ramifications on how every client part ought to conduct certain precautions to take care of his security issues. The above gave outline portrays the change of touchy data as per different clients, for example, approved clients(authorized) and unapproved users(unauthorized).Here, the delicate data from certain client is contained in the module named as DataProvider,From there information are further accumulated by another module named as Data collector,then the gathered information is mined by Data miner.Here,Information Transmitter goes about as a middle person between information excavator and choice maker.Finally, Decision producer will give information in light of the client sort, for example, approved and unapproved
G.Representation of ppdm model
The beginning of novel information mining systems has given a driving force to the security dangers which has continued developing a far cry. This is undeniably conceivable, inferable from the likelihood actuality to strappingly combine and investigate enormous information stores available on the web, amidst bobble of earlier baffling beyond anyone's ability to view designs. Protection issues likewise enlarge its convolution in light of new up and coming advancements, which are connecting colossal number of proportionally odd and sporadic individuals, to make an overall economy. This situation is of genuine fear testing thought. The significance of Privacy Preserving Data Mining (PPDM) below to the center is worn out not just from its showiness to hurl out urgent learning, additionally from its imperviousness to assault PPDM is a teach whose craving is to approve conveyance sends of respondent information while saving responds privacy. It acquaints arrangements with issues where the question is the means by which to get hold of information mining comes about without destroying protection. In the recommendation of novel arrangements there are two
4825 extemporizing existing calculations and systems for
PPDM is attempted.
H.k-anonmity
The fact that we can accept the Data holder knows which information in PT additionally show up remotely, and in this manner what constitutes a Quasi identifier, the particular qualities contained in outside information can't be expected. In this way data is secured in this work by fulfilling a extraordinary limitation on discharged information, named the k-Anonymity prerequisite. This is an exceptional instance of knap assurance where k is upheld on the discharged information.
I.GENERALISATION:
Generalization comprises of supplanting with quality qualities with semantically reliable however less exact qualities. For instance, place of birth can be supplanted by the nation of birth which happens in more records so that the distinguishing proof of a particular individual is more troublesome. Speculation keeps up the rightness of the information at the record stage however brings about low specific data that may influence the exactness of machine learning calculations connected on the k-mysterious informational index. Distinctive frameworks utilize different strategies for selecting the qualities and records for speculation and also the speculation strategy. It can be connected at the accompanying levels:
1) Quality (AG): In this sub-sort, speculation is executed at the level of section, and it also sums up every one of the qualities in the segment.
2) Cell (CG): In this sub-sort, speculation is executed on single cell. Accordingly, a summed up table may contain, particular section and values at various speculation levels. For example, (date of birth segment).
J.Suppression
Suppression implies to expel certain specific quality esteem and displace events of the incentive with an extraordinary Value showing that any esteem can be set. Concealment can definitely minimize the nature of the information, if not appropriately utilized. Concealment can be connected at the accompanying levels such as:
1) Tuple (t): In sub-sort, concealment is executed at the level of column, and also evacuates an entire tuple.
2) Quality (A): In sort, concealment is executed at the level of segment, and also darkens every one of the estimations in the given section.
3) Cell (C): In this area, concealment is executed at the level of single cells, thus a k-anonym zed table may wipe out just certain cells of a given tuple. K. Data confidentiality
In many fields, much valuable examples can be separated by applying machine learning systems to enormous information. For instance, mining patients'
medicinal records can help assess different adequacy of different treatment choices and find best treatment to battle different illnesses. Be that as it may, these information can be very delicate and information secrecy must be secured. In numerous situations, information classification could well be an essential for information to be shared to empower enormous information investigation.
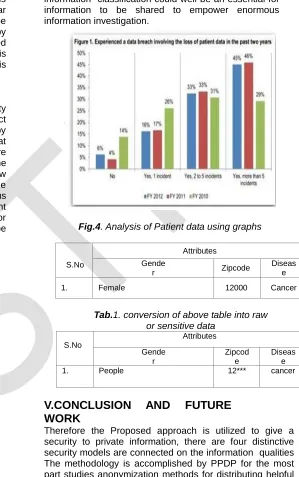
Fig.4. Analysis of Patient data using graphs
S.No
Attributes Gende
r Zipcode
Diseas e
1. Female 12000 Cancer
Tab.1. conversion of above table into raw
or sensitive data
S.No
Attributes Gende
r
Zipcod e
Diseas e
1. People 12*** cancer
V.CONCLUSION
AND
FUTURE
WORK
4826
REFERENCES
[1] Xueyun Li, Zheng Yan (2014), “A Review on Privacy Preserving Data Mining”
[2] J.Han, M.Kamber (2006), “Data Mining: Concepts and Techniques
[3] M.B Malik, M.A Ghazi (2012), “Privacy Preserving Data mining Techniques-Current Scenario and Future Prospects”
[4] S.Matwin, (2013) “Privacy Preserving Data Mining Techniques- Survey and Challenges,” in Discrimination and privacy in the Information Society [5] V.Ciriani, P. Samarati (2007), “Microdata
Protection”, in Secure data management in decentralized Systems
[6] L.Sweeny (2002), “k-anonmity: A Model for Protecting Privacy
[7] Gionis, T.Tassa, (2009), “k-anonimization with Minimal Loss of Information”
[8] S. Sharma, P. Gupta (2012), “Anonymization in Social Network: A Literature Survey and Classification”
[9] Y. Wang, L.Xie (2013), “High Utility k-anonimization for Social Network Publishing”
[10] A.E. Cicek, M.E. Nergiz (2013), “Ensuring
Location Diversity in Privacy-preserving Spatio-temporal data Publishing”