An Optimized Feature Selection Technique For
Email Classification
Olaleye Oludare, Olabiyisi Stephen, Olaniyan Ayodele, Fagbola Temitayo
Abstract: In machine learning, feature selection is a problem of global combinatorial optimization resulting in poor predictions and high computational overhead due to irrelevant and redundant features in the dataset. The Support Vector Machine (SVM) is a classifier suitable to deal with feature problems but cannot efficiently handle large e-mail dataset. In this research work, the feature selection in SVM was optimized using Particle Swarm Optimization (PSO). The results obtained from this study showed that the optimized SVM technique gave a classification accuracy of 80.44% in 2.06 seconds while SVM gave an accuracy of 68.34% in 6.33 seconds for email dataset of 1000. Using the 3000 e-mail dataset, the classification accuracy and computational time of the optimized SVM technique and SVM were 90.56%, 0.56 second and 46.71%, 60.16 seconds respectively. Similarly, 93.19%, 0.19 second and 18.02%, 91.47 seconds were obtained for optimized SVM technique and SVM respectively using 6000 e-mail dataset. In conclusion, the results obtained demonstrate that the optimized SVM technique had better classification accuracy with less computational time than SVM. The optimized SVM technique exhibited better performance with large e-mail dataset thereby eliminating the drawbacks of SVM.
Index Terms: Classification, Dataset, E-mail, Feature-Selection, Machine Learning, Particle Swarm Optimization, Support Vector Machine.
————————————————————
1
I
NTRODUCTIONElectronic mail (e-mail) is the most popular means of communication over the internet because it is free, fast and easy to send. Despite its popularity and usefulness, it is faced with continuous increase in the amount of unwanted bulk
emails, commonly referred to as ―spam‖, received [4]. Spam
are mostly mails or messages on advertisement, promotions, contest, publicity of one form or the other sent out to gain the attention of internet users. It could also be regarded as unsolicited email which can take the form of chain mails, mass emailing, threatening, or abusive email etc. More than 97% of all the e-mails sent over the net are unwanted [26]. With volumes such as this, a tremendous burden is placed on the ISP to process and store that amount of data. Volumes like this will undoubtedly contribute to many of the access, speed, and reliability problems noticeable with lots of ISPs. Indeed, many large ISPs have suffered major system outages as a result of massive junk email campaigns [7]. Moreover, virus attachments, spyware agents and phishing which are added in spam have become the most serious security threats to individuals and businesses recently. In addition, recipients become increasingly annoyed because they waste most of their precious working time to delete spam mails.
Therefore, there is need to distinguish between spam and legitimate mail message. As a result of this growing problem, a number of spam detection models have been proposed. Existing detection models search for particular keyword patterns in e-mails by using machine learning algorithms [1], [15], [18], [24]. There are large amounts of emails and they contain a lot of keyword patterns which denote spam mails. They may burden spam detection system, so the model should reduce the resources for processing to catch up with the huge amounts of e-mails. To reduce the amount of resources consumed with guaranteeing high detection rates; parameters optimization (for example, threshold function value, the number of hidden layers in Artificial Neural Networks (ANN) and parameters of kernel function in Support Vector Machine, SVM and so on) and feature selection (which figures out what features of mail are more important and need to be selected to detect spam mails) methods can be adopted. However, a feature selection approach was considered. The main idea of feature selection is to remove redundant or irrelevant features from the data set as they can lead to a reduction in classification accuracy or clustering quality and to an unnecessary increase of computational cost [3], [14]. The advantage of FS is that no information about the importance of single features is lost. Support vector machines (SVM) was considered to detect spam. SVMs are a new generation learning system based on recent advances in statistical learning theory [5]. SVMs calculate a separating hyperplane that maximizes the margin between data classes to produce good generalization abilities. SVMs have proved to be an efficient learning machine from numerous successful applications [10], [27], [28]. However, despite its high performance, SVMs have some limitations. Support Vector Machine has shown power in binary classification. It has good theoretical foundation and well mastered learning algorithm. It shows good results in static data classification but the disadvantage is that it is time and memory consuming, that is, computationally expensive, thus runs slow when size of data is enormous [20]. Also, SVMs are much more effective than other conventional nonparametric classifiers such as the neural networks, nearest neighbor and k-NN classifier in terms of classification accuracy, computational time and stability to parameter setting [8], [13], [16], [17], it is weak in its attempt to classify highly dimensional dataset with large number of features [2]. As a result, an optimizer is required to reduce the __________________________
Olaleye Oludare, Department of Computer Science, Allover Central Polytechnic, Ota, Nigeria.
Olabiyisi Stephen, Department of Computer Science and Enineering, Ladoke Akintola University of Technology, Ogbomoso, Nigeria
Olaniyan Ayodele, Department of Computer Eng, Gateway Polytechnic Sapaade,
number of features before the resultant feature subsets are introduced to SVM for better classification within reasonable time. This study tends to improve the classification efficiency (in terms of accuracy rate and time) of SVM by optimizing its feature selection process using Particle Swarm Optimization (PSO) for the classification of email into spam or non-spam.
2
LITERATURE REVIEW2.1 Classification
A number of classification systems have been developed, often specializing in particular problem domains or dataset types [6]. Their performance is evaluated according to their ability to classify novel patterns, based on the ones they are trained with. The most popular measure that reflects this is accuracy (usually expressed as a rate), which is defined as the number of correct classifications over the total number of patterns classified. When developing classification systems there is an underlying tendency towards simpler models, as the overly complex ones may compromise the accuracy of the classification [6] while at the same time exhibit higher computational cost. Therefore, the dominant approach for many years was to use (often basic) statistics and develop what are now known as the Statistical Methods of classification. Yet, relatively recently, another approach has been developed, namely, that using Artificial Intelligence (AI) methods. These two types of approaches are the two main categories of pattern recognition [19]. Statistical Methods include Linear and Quadratic Discriminant Functions (LDFs and QDFs respectively), Bayesian classifiers, Parzen Classifier, Logistic Classifier, etc. [11], [19]. The characteristic which appears in the majority of them is their use of probabilities for the estimation of the most suitable class of the unknown patterns using the assumed probability density functions based on the known patterns. The main difference between statistical and AI methods is that the former make assumptions of the data (such as the distribution they form), while the latter make less strict assumptions [22]. However, since a lot of classifiers, which take elements of both approaches, have been developed, the boundaries between Statistical and AI classification methods are not clear-cut. Another important issue is that of noise, which influences the data values by making the structure of the classes appear to be more irregular. Though its presence is often a hindrance to statistical classifiers, AI based classifiers often deal with it effectively and sometimes it even helps them make better generalization (for example, in the case of Neural Networks), as argued by [6]. Lastly, a significant issue for classification systems is that of computational complexity. Even though in some cases it may be possible to attain an error-free classification by using a vast amount of resources (particularly time and storage), this is often not practical [6]. Many AI methods are developed so that they are ―lighter‖ and therefore perform the classification process in a fast and efficient way, something which is not usually shared by the statistical methods. They are like that because they often rely on heuristic measures or methods for the classification process.
2.2 Artificial Intelligence Methods for Classification
The Artificial Intelligence methods used in classification vary in their function and their structure. The most popular ones are:
1. Support Vector Machines (SVMs)
2. Decision Trees
3. Artificial Neural Networks (ANNs), such as
(i) Multi-Layer Neural Networks or Multi-Layer
Perceptrons (MLPs)
(ii)Radial Basis Function networks (RBFs)
(iii)Self-Organising Maps (SOMs)
(iv)Probabilistic Neural Networks (PNNs)
4. K Nearest Neighbour (kNN) and its variations
5. Other distance-based classifiers
6. Fuzzy Logic classifiers
7. Stochastic methods according to [6]
belongs to the AI category, even though they have many Statistical elements in their function
8. Hybrid classification systems
Apart from these classifiers, there are also approaches which aim at combining different classifiers, either of the same kind,
or, quite often, of different philosophy such as mixture of
expert models, pooled classifiers, or classifier ensembles [21], [23]. These methods employ an information fusion technique (for example, majority vote) to combine the outputs of the different classifiers they comprise of (ensemble members). In some cases, the combination of the members of the ensemble takes place in a lower level, particularly that of the training phase [9]. The classifier ensembles can have statistical methods (such as Linear and Quadratic Discriminant Functions, Bayesian classifiers, Parzen Classifier, Logistic Classifier, etc.) as their members, yet they usually include one or more AI methods. In the remainder of the section a review of the AI techniques will be given.
2.3 Feature Selection
Feature selection is of considerable importance in pattern classification, data analysis, information retrieval, machine learning and data mining application. Researchers are realizing that in order to achieve a successful classification, feature selection is an indispensable component. Feature selection is a process commonly used in machine learning, wherein subsets of features available from the data are selected for application of a learning algorithm. It reduces the number of features, removes irrelevant, redundant or noisy features, and brings about noticeable effects for application, speeding up classification algorithm. The best subset contains the least number of dimensions that most contribute to accuracy, the remaining dimensions discarded and leading to
better model comprehensibility. Feature selection methods
seeking optimal subsets are usually directed toward one of two goals:
1. Minimize the number of features selected while
satisfying some minimal level of classification capability or
2. Maximize classification ability for a subset of
prescribed cardinality. The feature selection process can be made more efficient by optimizing its subset selection techniques through the use of some well-known optimizers.
3 M
ETHODOLOGY3.1 Support Vector Machine
the two classes of the dataset in the best possible way (that is, having a relatively high margin). They form decision rules based on that hyper plane and perform classification accordingly. In order to accomplish this, they make use of a usually much higher dimensionality than that of the original feature space. This is because with the right nonlinear mapping to a high enough dimensions, patterns from two different classes can always be separated by a hyper-plane. Yet, the boundaries they form in this space can be non-linear as well, depending on the kernel parameter of the SVM [25]. By finding a separating hyper-plane with the highest possible margin (that is, distance from actual patterns of the dataset), SVMs provide the generalization they require for the classification task (the higher the margin, the better the generalization).
3.2 Particle Swarm Optimization
Inspired by the flocking and schooling patterns of birds and fish, Particle Swarm Optimization (PSO) was invented by Russell Eberhart and James Kennedy. It is a population-based stochastic approach for solving continuous and discrete optimization problems [12]. In particle swarm optimization,
simple software agents, called particles, move in the search
space of an optimization problem. The position of a particle represents a candidate solution to the optimization problem at hand. Each particle searches for better positions in the search space by changing its velocity according to rules originally inspired by behavioral models of bird flocking. All of particles have fitness values which are evaluated by the fitness function to be optimized, and have velocities which direct the flying of the particles. The particles fly through the problem space by following the current optimum particles. PSO is initialized with a group of random particles (solutions) and then searches for optima by updating generations. In every iteration, each particle is updated by following two "best" values. The first one is the best solution (fitness) it has achieved so far. (The fitness value is also stored.) This value is called pbest. Another "best" value that is tracked by the particle swarm optimizer is the best value, obtained so far by any particle in the population. This best value is a global best and called gbest. When a particle takes part of the population as its topological neighbors, the best value is a local best and is called lbest. After finding the two best values, the particle updates its velocity and positions equation (1) and (2).
(1)
(2)
where v[] is the particle velocity, present[] is the current particle (solution). pbest[] and gbest[] are defined as stated before. rand () is a random number between (0,1). c1, c2 are learning factors, usually c1 = c2 = 2.
The pseudo code of the procedure is as follows
For each particle
Initialize particle
END
Do
For each particle
Calculate fitness value
If the fitness value is better than the best fitness value (pBest) in history
set current value as the new pBest
End
Choose the particle with the best fitness value of all the particles as the gBest
For each particle
Calculate particle velocity according equation (1)
Update particle position according equation (2)
End
While maximum iterations or minimum error criteria is not attained
The flow diagram illustrating the particle swarm optimization algorithm is presented in Fig. 1.
3.3 The Optimized SVM Technique
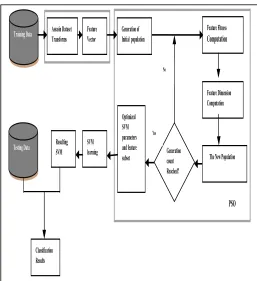
This study adopted a feature vector dictionary approach for binary classification of e-mail messages using look-up table of spam features to determine the spamicity of e-mail messages. The features extracted (keywords) from the e-mail datasets were introduced to a PSO technique for optimal feature subset selection after a predefined number of generations were obtained and the resulting feature subset was passed to SVM
for classification as illustrated by Fig. 2. Simulation was conducted using MATLAB 7.7.0 and performance of the optimized SVM technique was compared with SVM in terms of classification accuracy and computational time (testing time) using 1000, 3000, and 6000 e-mail datasets respectively to determine the behavior of both techniques with increasing size of datasets. Each training set produced contained 75% of each dataset while the remaining 25% were used for testing.
4
E
XPERIMENTALR
ESULTS ANDDISCUSSION
To measure the performance of the optimized SVM technique and to compare its performance with that of the SVM, the
spam assassin datasets from www.spamassassins.com was
used.
4.1 Description of Classifiers Implementation
The experimental results obtained for SVM and optimized SVM technique are presented and discussed below;
4.1.1 Experimental Results using 1000 Email Messages
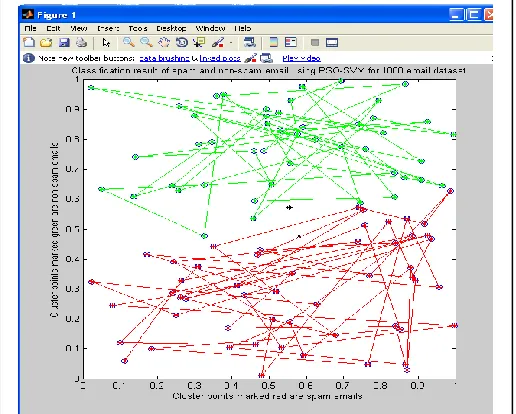
In the first experiment, 1000 email messages were generated randomly. 750 emails were used to train the classifier and 250 to test it. Fig. 3 depicts the SVM classification of the 1000 email messages into spam and non-spam by finding a separating hyper-plane with the highest possible margin (that is, distance from actual patterns of the dataset).
The accuracy (in %) and time used by SVM for the classification of the 1000 e-mail datasets is shown in Figure 4. The classification accuracy using SVM is 68.34% while the time used is 6.33 seconds.
Fig. 5 depicts the optimized SVM technique's classification of the 1000 email messages into spam and non-spam by finding a separating hyper-plane with the highest possible margin. The accuracy (in %) and time used by optimized SVM technique for the classification of the 1000 e-mail datasets is shown in Fig. 6. The classification accuracy using optimized SVM technique is 80.44% while the time used is 2.06 seconds.
Training Data
Generation count Reached? Generation of
Initial population
Optimized SVM parameters and feature subset
Feature Fitness
Computation
Feature Dimension Computation
The New Population Testing Data SVM learning
Feature Vector Assasin Dataset Transforms
Resulting SVM
Classification Results
No
Yes
PSO
Fig. 2. Architecture of the Optimized SVM Technique for
Email Classification.
Fig. 3. Classification of 1000 Email dataset into Spam and Non-spam using SVM
4.1.2 Experimental Results using 3000 Email Messages
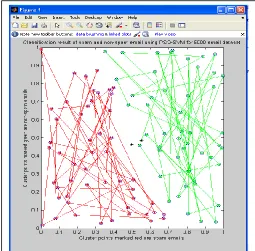
In the second experiment, 3000 e-mail datasets were used. The training set contained 2250 emails while the test set contained 750 emails. Fig. 7 depicts the SVM classification of the 3000 email datasets into spam and non-spam. The accuracy (in %) and time used by SVM for the classification of the 3000 e-mail datasets is shown in Fig. 8. The classification accuracy using SVM is 46.71% while the time used is 60.16 seconds. Fig. 9 depicts the optimized SVM classification of the 3000 email datasets into spam and non-spam. The accuracy (in %) and time used by optimized SVM technique for the classification of the 3000 e-mail datasets is shown in Fig. 10. The classification accuracy using optimized SVM technique is 90.56% while the time used is 0.56 seconds.
Fig. 5. Classification of 1000 Email dataset into Spam and Non-spam using Optimized SVM
Fig. 6. Classification Result for 1000 Email Dataset using Optimized SVM
Fig. 7. Classification of 3000 Email dataset into Spam and Non-spam using SVM
Fig. 8. Classification Result for 3000 Email Dataset using SVM
4.1.3 Experimental Results using 6000 Email Messages
In the third experiment, 6000 email datasets were used for the classification. The training set produced contained 4500 email messages while the test set contained 1500 email messages. Fig. 11 depicts the SVM classification of the 6000 email messages into spam and non-spam by finding a separating hyper-plane with the highest possible margin. The accuracy (in %) and time used by SVM for the classification of the 6000 email datasets is shown in Fig. 12. The classification accuracy using SVM is 18.02% while the time used is 91.47 seconds.
Fig. 13 depicts the optimized SVM classification of the 6000 email messages into spam and non-spam. The accuracy (in %) and time used by optimized SVM technique for the classification of the 6000 email datasets is shown in Fig. 14. The classification accuracy using optimized SVM technique is 93.19% while the time used is 0.19 seconds.
Fig. 10. Classification Result for 3000 Email Dataset using Optimized SVM
Fig. 11. Classification of 6000 Email dataset into Spam and Non-spam using SVM
Fig. 12. Classification Result for 6000 Email Dataset using SVM
4.2 Comparative Evaluation of SVM and Optimized SVM Techniques
After due evaluation of SVM and the optimized SVM technique, the result obtained is summarized and presented in Table 1.
TABLE 1
EXPERIMENT RESULTS OF SVM AND PSO-SVM
Based on the result obtained from this study and summarized in Table 1, it can be observed that when dataset size is 1000, optimized SVM technique yields a classification accuracy of 80.44% in 2.06 seconds while SVM yields an accuracy of 68.34% in 6.33 seconds. This result shows that the optimized SVM technique produced 12.1% higher accuracy in 4.27 seconds lesser computational time than SVM. Also, when the dataset size is 3000, the result obtained for optimized SVM technique and SVM are 90.56% in 0.56 seconds and 46.71% in 60.16 seconds respectively. This result shows that the optimized SVM technique gave 43.85% higher classification accuracy in 59.6 seconds lesser computational time than SVM with an increase of 2000 emails. Lastly, the classification accuracy and computational time for optimized SVM technique and SVM are 93.19% in 0.19 seconds and 18.01% in 91.47 seconds respectively. This shows that the optimized SVM technique produced 75.18% higher classification accuracy 91.28 seconds lesser computational time than SVM with an increase of 3000 emails. Therefore, experimental results
obtained demonstrate that for every increase in dataset size, there is always a reduction in the classification accuracy of SVM with a remarkable increase in computational time while optimized SVM technique shows otherwise, thus confirming the argument that SVM becomes weak and time consuming with large dataset size and also PSO’s ability to find an optimal set of feature weights that improve classification rate.
4.3 Implication of the Results Obtained
SVM has been observed to consume a lot of computational resources and result in inaccurate classification in the face of a large e-mail dataset. The result above indicates that optimized SVM technique has a remarkable improvement on classification accuracy and computational time over SVM in the face of a large e-mail dataset showing that the optimized SVM technique has eliminated the drawbacks of SVM.
C
ONCLUSIONThis study presents a particle swarm optimization-based feature selection technique, capable of searching for the optimal parameter values for SVM to obtain a subset of beneficial features. PSO is applied to optimize the feature subset selection and classification parameters for SVM classifier. It eliminates the redundant and irrelevant features in
the dataset, and thus reduces the feature vector
dimensionality drastically. This helps SVM to select optimal feature subset from the resulting feature subset. This optimal subset of features is then adopted in both training and testing to obtain the optimal outcomes in classification. Comparison of the obtained results with SVM classifier demonstrates that the optimized SVM technique has better classification accuracy than SVM. The optimized SVM technique has shown a significant improvement over SVM in terms of classification accuracy as well as the computational time in the face of a large dataset.
R
EFERENCES[1] Abu-Nimeh S., D. Nappa, X.Wang, and S. Nair. Bayesian
Additive Regression Trees-Based Spam Detection for Enhanced Email Privacy. In Proc. of the 3rd Int. Conf. on Availability, Reliability and Security (ARES 2008), Barcelona, Spain, pp 1044–1051, IEEE, March 2008.
[2] Andrew Webb (2010), Statistical Pattern Recognition.
London: Oxford University Press.
[3] Blum A. L., and Langley P.,. Selection of relevant features
and examples in machine learning. Artificial Intelligence, 97:245–271, 1997.
[4] Cranor, Lorrie F. & LaMacchia, Brian A. (1998): ―Spam‖,
Communications of the ACM, 41(8): 1998, pp. 74-83
[5] Cristianini, N., & Shawe-Taylor, J. (2000). A introduction
to support vector machines and other kernel-based learning methods. Cambridge, UK: Cambridge University Press.
[6] Duda, R. O., Hart, P. E., and Stork, D. G., 2001. Pattern
Classification (2nd ed.). John Wiley and Sons, University of Michigan.
Dataset
SVM PSO-SVM
Classificatio
n Accuracy
(%)
Computationa
l Time (secs)
Classification
Accuracy (%)
Computational
Time (secs)
1000 68.34 6.33 80.44 2.06
3000 46.71 60.16 90.56 0.56
6000 18.02 91.47 93.19 0.19 Fig. 14. Classification Result for 6000 Email Dataset
[7] Edward, D. (2003): ―Intelligent Filters that Blocks SPAM‖, Email and Pornographic Images
[8] El-Naqa, Yongyi, Y., Wernick M. N., Galatsanos, N. P., &
Nishikawa R. M. (2002): A Support Vector Machine Approach for Detection of Microcalcifications, Medical Imaging, 21(12), pp. 1552-1563
[9] Fard, M. M., 2006. Ensemble Learning with Local Experts.
IEEE Computer Society ezine “Looking.Forward” student magazine 14th edition. Available online at: 110 http://www.computer.org/portal/cms_docs_ieeecs/ieeecs/c ommunities/students/lookin g/2006fall/05.pdf (last accessed: August 2008)
[10]Hsu, C.-W., & Lin, C.-J. (2002). A comparison of methods
for multiclass support vector machines. IEEE Transactions on Neural Networks, 13(2), 415–425.
[11]Jain, A. K., Duin, R. P. W., Mao, J., 2000. Statistical
pattern recognition: a review. IEEE Transactions on
Pattern Analysis and Machine Intelligence, vol. 22 (1), pp. 4-38.
[12]Kennedy, J. and R.C. Eberhart. 1995. Particle Swarm
Optimization. Proceedings IEEE International Conference on Neural Networks, IV, p. 1942-1948.
[13]Kim, K. I., Jung, K., & Kim, J. H. (2003). Texture-based
approach for text detection in images using support vector machines and continuously adaptive mean shift algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(12), pp. 1631–1639.
[14]Koller .D, and Sahami M.,. Toward optimal feature
selection. pages 284–292. Morgan Kaufmann, 1996.
[15]Lee S, D. Kim, J. Kim, and J. Park. Spam Detection Using
Feature Selection and Parameters Optimization. In Proc. of the 4th International Conference on Complex, Intelligent and Software Intensive Systems (CISIS’10), Krakow, Poland, pp. 883–888, IEEE, February 2010.
[16]Liyang, W. Y., Yongyi, R. M., Nishikawa, M. N., &
Wernick, A. E. (2005a). Relevance vector machine for automatic detection of clustered microcalcifications. IEEE Transactions on Medical Imaging, 24(10), pp. 1278–1285.
[17]Liyang, W., Yongyi, Y., Nishikawa, R. M., & Yulei, J.
(2005b). A study on several machine-learning methods for
classification of malignant and benign clustered
microcalcifications. IEEE Transactions on Medical
Imaging, 24(3), pp. 371–380.
[18]Liang J., S. Yang, and A. Winstanley. Invariant Optimal
Feature Selection (2008). A Distance Discriminant and Feature Ranking based Solution. Pattern Recognition, 41(1): pp. 1429–1439.
[19]McKenzie, D. and Low, L. H., 1992. The construction of
computerized classification systems using machine
learning algorithms: an overview. Computers in Human
Behavior, vol. 8, pp. 155- 67. Ruta, D. and Gabrys, B.,
2005. Classifier selection for majority voting. Information
Fusion, 6, pp. 63–81.
[20]Priyanka, C., Rajesh, W., & Sanyam, S. (2010), ―Spam
Filtering using Support Vector Machine‖, Special
Issue of IJCCT 1(2, 3, 4), 166-171.
[21]Ruta, D. and Gabrys, B., 2005. Classifier selection for
majority voting. Information Fusion, 6, pp. 63–81.
[22]Shanin, M. A., Tollner, E. W. and McClendon, R. W.,
2001. Artificial intelligence classifiers for sorting apples
based on watercore. Journal of Agricultural Engineering
Resources, vol. 79 (3), pp. 265-274.
[23]Shipp, C. A. and Kuncheva, L. I., 2002. Relationships
between combination methods and measures of diversity
in combining classifiers. Information Fusion, 3, pp. 135–
148
[24]Thota H, R. N. Miriyala, S. P. Akula, K. M. Rao, C. S.
Vellanki, A. A. Rao, and S. Gedela. Performance Comparative in Classification Algorithms Using Real Datasets (2009). Journal of Computer Science and Systems Biology, 2(1): pp. 97–100.
[25]Vapnik, V., 2000b. Support Vector Machines and Other
Kernel-based Learning Methods. John Shawe-Taylor & Nello Cristianini, Cambridge University Press.
[26]Waters, Darren. ― Spam Overwhelms Email Messages‖
BBC News, 2009. Retrieved 2012-12-10
[27]Widodo, A., & Yang, B.-S. (2007). Support vector machine
in machine condition monitoring and fault diagnosis. Mechanical Systems and Signal Processing, 21, 2560– 2574.
[28]Widodo, A., Yang, B.-S., & Han, T. (2007). Combination of