CoNLL 2008: Proceedings of the 12th Conference on Computational Natural Language Learning,pages 41–48
Using LDA to detect semantically incoherent documents
Hemant Misra and Olivier Capp´e
LTCI/CNRS and TELECOM ParisTech
{misra,cappe}@enst.fr
Franc¸ois Yvon
Univ Paris-Sud 11 and LMISI-CNRS
Abstract
Detecting the semantic coherence of a doc-ument is a challenging task and has sev-eral applications such as in text segmenta-tion and categorizasegmenta-tion. This paper is an attempt to distinguish between a ‘semanti-cally coherent’ true document and a ‘ran-domly generated’ false document through topic detection in the framework of latent Dirichlet analysis. Based on the premise that a true document contains only a few topics and a false document is made up of many topics, it is asserted that the entropy of the topic distribution will be lower for a true document than that for a false docu-ment. This hypothesis is tested on several false document sets generated by various methods and is found to be useful for fake content detection applications.
1 Introduction
The “Internet revolution” has dramatically in-creased the monetary value of higher ranking on the web search engines index, fostering the ex-pansion of techniques, collectively known as “Web Spam”, that fraudulently help to do so. Internet is indeed “polluted” with fake Web sites whose only purpose is to deceive the search engines by arti-ficially pushing up the popularity of commercial sites, or sites promoting illegal content 1. These fake sites are often forged using very crude content generation techniques, ranging from web
scrap-ping (blending of chunks of actual contents) to
simple-minded text generation techniques based
c
2008. Licensed under the Creative Commons
Attribution-Noncommercial-Share Alike 3.0 Unported
li-cense (http://creativecommons.org/licenses/by-nc-sa/3.0/). Some rights reserved.
1The annual AirWeb challenge http://airweb.
cse.lehigh.edugives a state-of-the art on current Web Spam detection techniques.
on random sampling of words (“word salads”), or randomly replacing words in actual documents (“word stuffing”) 2. Among these, the latter two are easy to detect using simple statistical models of natural texts, but the former is more challeng-ing, it being made up of actual sentences: recog-nizing these texts as forged requires either to resort to plagiarism detection techniques, or to automati-cally identify their lack of semantic consistency.
Detecting the consistency of texts or of text chunks has many applications in Natural Language Processing. So far, it has been used mainly in the context of automatic text segmentation, where a change in vocabulary is often the mark of topic change (Hearst, 1997), and, to a lesser extent, in discourse studies (see, e.g., (Foltz et al., 1998)). It could also serve to devise automatic metrics for text summarization or machine translation tasks.
This paper is an attempt to address the issue of differentiating between ‘true’ and ‘false’ doc-uments on the basis of their consistency through topic modeling approach. We have used La-tent Dirichlet allocation (LDA) (Blei et al., 2002) model as our main topic modeling tool. One of the aims of LDA and similar methods, including prob-abilistic latent semantic analysis (PLSA) (Hof-mann, 2001), is to produce low dimensionality rep-resentations of texts in a “semantic space” such that most of their inherent statistical characteristics are preserved. A reduction in dimensionality facil-itates storage as well as faster retrieval. Modeling discrete data has many applications in classifica-tion, categorizaclassifica-tion, topic detecclassifica-tion, data mining, information retrieval (IR), summarization and col-laborative filtering (Buntine and Jakulin, 2004).
The aim of this paper is to test LDA for es-tablishing the semantic coherence of a document based on the premise that a real (coherent) docu-ment should discuss only a few number of topics,
2The same techniques are commonly used in mail spams
also.
a property hardly granted for forged documents which are often made up of random assemblage of words or sentences. As a consequence, the co-herence of a document may reflect in the entropy of its posterior topic distribution or in its perplex-ity for the model. The entropy of the estimated topic distribution of a true document is expected to be lower than that of a fake document. Moreover, the length normalized log-likelihood of a true and coherent document may be higher as compared to that of a false and incoherent document.
In this paper, we compare two methods to esti-mate the posterior topic distribution of test docu-ments, and this study is also an attempt to inves-tigate the role of different parameters on the effi-ciency of these methods.
This paper is organized as follows: In Section 2, the basics of the LDA model are set. We then dis-cuss and contrast several approaches to the prob-lem of inferring the topic distribution of a new document in Section 3. In Section 4, we describe the corpus and experimental set-up that are used to produce the results presented in Section 5. We summarize our main findings and draw perspec-tives for future research in Section 6.
2 Latent Dirichlet Allocation
2.1 Basics
LDA is a probabilistic model of text data which provides a generative analog of PLSA (Blei et al., 2002), and is primarily meant to reveal hidden top-ics in text documents. In (Griffiths and Steyvers, 2004), the authors used LDA for identifying “hot topics” by analyzing the temporal dynamics of top-ics over a period of time. More recently LDA has also been used for unsupervised language model (LM) adaptation in the context of automatic speech recognition (ASR) (Hsu and Glass, 2006; Tam and Schultz, 2007; Heidel et al., 2007). Several extensions of the LDA model, such as hierarchi-cal LDA (Blei et al., 2004), HMM-LDA (Grif-fiths et al., 2005), correlated topic models (Blei and Lafferty, 2005) and hidden topic Markov mod-els (Gruber et al., 2007), have been proposed, that introduce more complex dependency patterns in the model.
Like most of the text mining techniques, LDA assumes that documents are made up of words and the ordering of the words within a document is unimportant (“bag-of-words” assumption). Con-trary to the simpler Multinomial Mixture Model
(see, e.g., (Nigam et al., 2000) and Section 2.4), LDA assumes that every document is represented by a topic distribution and that each topic defines an underlying distribution on words.
The generative history of a document (a bag-of-words) collection is the following: Assuming a fixed and known number of topicsnT, for each topict, a distributionβtover the indexing vocab-ulary (w = 1. . . nW) is drawn from a Dirichlet distribution. Then, for each documentd, a distri-butionθdover the topics(t = 1. . . nT) is drawn from a Dirichlet distribution. For a document d, the document length ld being an exogenous vari-able, the next step consists of drawing a topic ti from θd for each positioni = 1...ld. Finally, a word is selected from the chosen topic ti. Given the topic distribution, each word is thus drawn in-dependently from every other word using a
docu-ment specific mixture model. The probability of ithword token is thus:
P(wi|θd, β) = nT
X
t=1
P(ti=t|θd)P(wi|ti, β)(1)
=
nT
X
t=1
θdtβtw (2)
Conditioned on β and θd, the likelihood of doc-ument d is a mere product of terms such as (2), which can be rewritten as:
P(Cd|θd, β) = nW
Y
w=1
"n
T
X
t=1
(θdtβtw)
#Cdw
(3)
whereCdwis the count of wordwind.
2.2 LDA: Training
LDA training consists of estimating the following two parameter vectors from a text collection: the topic distribution in each document d (θdt, t =
1...nT, d = 1...nD) and the word distribution in each topic (βtw, t = 1...nT, w = 1...nW). Both
on the topic assigned to all the other word to-kens. Given a particular Gibbs sample, the pos-teriors forθandβare3: Dirichlet with parameters
(Kt1+λ, . . . , KtnW+λ)and Dirichlet with param-eters(Jd1+α, . . . , JdnT +α), respectively, where
Ktw is the number of times wordwis assigned to topictandJdtis the number of times topictis as-signed to some word token in documentd. Hence,
βtw = PnWKtw+λ
k=1Ktk+nWλ (4)
θdt = PnTJdt+α
k=1Jdk+nTα
(5)
During the Gibbs sampling phase, βt and θd are sampled from the above posteriors while the final estimates for these parameters are obtained by av-eraging the posterior means over the complete set of Gibbs iteration.
2.3 LDA: Testing
Training LDA model on a text collection already provides interesting insights regarding the the-matic structure of the collection. This has been the primary application of LDA in (Blei et al., 2002; Griffiths and Steyvers, 2004). Even better, being a generative model, LDA can be used to make prediction regarding novel documents (assuming they use the same vocabulary as the training cor-pus). In a typical IR setting, where the main fo-cus is on computing the similarity between a doc-umentdand a query d0, a natural similarity mea-sure is given byP(Cd0|θd, β), computed according to (3) (Buntine et al., 2004).
An alternative would be to compute the KL di-vergence between the topic distribution indandd0, which however requires to infer the latter quantity. As the topic distribution of a (new) document gives its representation along the latent semantic dimen-sions, computing this value is helpful for many applications, including text segmentation and text classification. Methods for efficiently and accu-rately estimating topic distribution for text docu-ments are presented and evaluated in Section 3.
2.4 Baseline: Multinomial Mixture Model
The performance of LDA model is compared with that of the simpler multinomial mixture model (Nigam et al., 2000; Rigouste et al., 2007).
3assuming non-informative priors with hyper-parameters α and λ for the Dirichlet distribution over topics and the Dirichlet distribution over words respectively
In this model, every word in a document belongs to the same topic, as if the document specific topic distribution θd in LDA were bound to lie on one vertex of the[0,1]nT simplex. Using the same no-tations as before (except forθt, which now denotes the position independent probability of topic t in the collection), the probability of a document is:
P(Cd|θt, β) = nT
X
t=1
θt nW
Y
w=1
βCdw
tw (6)
This model can be trained through expectation maximization (EM), using the following reestima-tion formulas, where (7) defines the E-step; (8) and (9) define the M-step.
P(t|Cd, θ, β) = θt
QnW
w=1(βtw0 )Cdw
PnT
t=1θtQnwW=1(βtw)Cdw (7)
θt0 ∝ α+
nD
X
d=1
P(t|Cd, θ, β) (8)
β0
tw ∝ λ+ nD
X
d=1
CdwP(t|Cd, θ, β) (9)
As suggested in (Rigouste et al., 2007), we ini-tialize the EM algorithm by drawing initial topic distributions from a prior Dirichlet distribution with hyper-parameter α = 1. β = 0.1 in all the experiments.
During testing, the parameters of the multino-mial models are used to estimate the posterior topic distribution in each document using (7). The like-lihood of a test document is given by (6).
3 Inferring the Topic Distribution of Test Documents
P(Cd|θd), the conditional probability of a
docu-mentdgivenθdis obtained using (3)4. Computing the likelihood of a test document requires to inte-grate this quantity overθ; likewise for the compu-tation of the posterior distribution ofθ. This inte-gral has no close form solution, but can be approx-imated using Monte-Carlo sampling techniques as:
P(Cd) ≈ M1 M
X
m=1
P(Cd|θ(m)) (10)
where θ(m) denotes the mth sample from the Dirichlet prior, and M is the number of Monte
4The dependence on β is dropped for simplicity. β is
Carlo samples. Given the typical length of doc-uments and the large vocabulary size, small scale experiments convinced us that a cruder approxima-tion was in order, as the sum in (10) is dominated by the maximum value. We thus contend ourselves to solve:
θ∗ = argmax
θ,Ptθt=1P(Cd|θ) (11)
and use this value to approximateP(Cd)using (3). The maximization program (11) has no close form solution. However, the objective function is differentiable and log-concave, and can be opti-mized in a number of ways. We considered two different algorithms: an EM-like approach, ini-tially introduced in (Heidel et al., 2007), and an ex-ponentiated gradient approach (Kivinen and War-muth, 1997; Globerson et al., 2007).
The first approach implements an iterative pro-cedure based on the following update rule:
θdt← l1 d
nW
X
w=1
Cdwθdtβtw
PnT
t0=1θdt0βt0w (12)
Although no justification was given in (Hei-del et al., 2007), it can be shown that this update rule converges towards a global opti-mum of the likelihood. Let θ and θ0 be two topic distributions in thenT-dimensional simplex,
L(θ) = logP(Cd|θ), andρt(w, θ) = Ptθ0tθβttw0βt0w. We define an auxiliary function Q(θ, θ0) =
P
wCw(
P
tρt(w, θ) log(θt0)). Q(θ, θ0)is concave
in θ0, and performs the role played by the auxil-iary function in the EM algorithm. Simple cal-culus suffices to prove that (i) the update (12) maximizes in θ0 the function Q(θ, θ0), and (ii)
Q(θ, θ0)−Q(θ, θ) ≥ L(θ0)−L(θ), which stems from the concavity of the log. At an optimum of
Q(θ, θ0)the positivity of the first term implies the positivity of the second. MaximizingQusing the update rule (12) thus increases the likelihood and repeating this update converges towards the opti-mum value. We experimented both with an un-smoothed (12) and with a un-smoothed version of this update rule. The unsmoothed version yielded a slightly better result than the smoothed one.
Exponentiated gradient (Kivinen and Warmuth, 1997; Globerson et al., 2007) yields an alternative update rule:
θdt ←θdtexp η nW
X
w=1
Cdwβtw
PnT
t0=1θdt0βt0w !
(13)
whereηdefines the convergence rate. In this form, the update rule does not preserve the normaliza-tion ofθ, which needs to be performed after every iteration.
A systematic comparison of these rules was car-ried out, yielding the following conclusions:
• the convergence of the EM-like method is very fast. Typically, it requires less than half a dozen iterations to converge. After conver-gence, the topic distribution estimated by this method for a subset of train documents was always very close (as measured by the KL-divergence) to the respective topic distribu-tion of the same documents observed at the end of the LDA training. Taking nT = 50, the average KL divergence for a set of 4,500 documents was found to be less than0.5.
• exponentiated gradient has a more erratic be-haviour, and requires a careful tuning ofηon a per document basis. For large values ofη, the update rule (13) sometimes fails to con-verge; smaller values ofηallowed to consis-tently reach convergence, but required more iterations (typically 20-30). On a positive side, on an average, the topic distributions estimated by this method are better than the ones obtained with the EM-like algorithm.
Based on these findings, we decided to use the EM-like algorithm in all our subsequent experi-ments.
4 Experimental protocol
4.1 Training and test corpora
The Reuters Corpus Volume 1 (RCV1) (Lewis et al., 2004) is a collection of over 800,000 news items in English from August 1996 to August 1997. Out of the entire RCV1 dataset, we se-lected 27,672 documents (news items) for training (TrainReuters) and 23,326 documents for testing (TestReuters). The first4000documents from the
TestReuters dataset were used as true documents
(TrueReuters) in the experiments reported in this paper. The vocabulary size in the train set, after removing the function words, is93,214.
by assembling randomly chosen words (sometimes called as “word salads”). In addition, we also consider the case of documents generated with a stochastic language model (LM). Our “fake” test documents are thus composed of:
• (SentenceSalad) obtained by randomly pick-ing sentences from TestReuters.
• (WordSalad) created by generating random sentences from a conventional unigram LM trained on TrainReuters.
• (Markovian) created by generating random sentences from a conventional 3-gram LM trained on TrainReuters.
Each of these forged document set contains 4,000 documents.
To assess the performance on out-of-domain data, we replicated the same tests using 2,000 Medline abstracts (Ohta et al., 2002). 1,500 doc-uments were used either to generate fake docu-ments by picking sentences randomly or to train an LM and then using the LM to generate fake docu-ments. The remaining 500 abstracts were set aside as “true” documents (TrueMedline).
4.2 Performance Measurements : EER
The entropy of the topic distribution is computed as H = −PTj=1θˆdjlog ˆθdj. The other measure of interest is the average ‘log-likelihood per word’ (LLPW)5.
While evaluating the performance of our sys-tem, two types of errors are encountered: false ac-ceptance (FA) when a false document is accepted as a true document and false rejection (FR) when a true document is rejected as a false document. The rate of FA and FR is dependent on the threshold used for taking the decision, and usually the per-formance of a system is shown by its receiver op-erating characteristic (ROC) curve which is a plot between FA and FR rates for different values of threshold. Instead of reporting the performance of a system based on two error rates (FA and FR), the general practice is to report the performance in terms of equal-error-rate (EER). The EER is the error rate at the threshold where FA rate = FR rate. In our system, a threshold on entropy (or LLPW) is used for taking the decision, and all the
5
This measure is directly related to the text per-plexity in the model, according to perplexity =
2−average log-likelihood per word
documents having their entropy (or LLPW) below (or above) the threshold are accepted as true doc-uments. The EER is obtained on the test set by changing the threshold on the test set itself, and the best results thus obtained are reported.
5 Detecting semantic inconsistency
5.1 Detecting fake documents with LDA and Multinomial mixtures
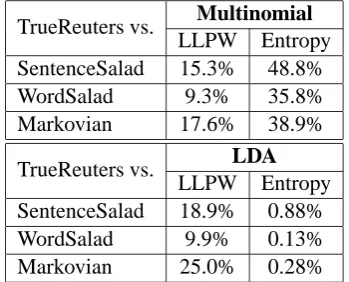
In the first set of experiments, the LLPW and en-tropy of the topic distribution (the two measures) of the Multinomial mixture and LDA models were compared to check the ability of these two mea-sures and models in discriminating between true and false documents. These results are summa-rized in Table 1.
TrueReuters vs. Multinomial LLPW Entropy SentenceSalad 15.3% 48.8% WordSalad 9.3% 35.8% Markovian 17.6% 38.9%
[image:5.595.320.495.307.448.2]TrueReuters vs. LDA LLPW Entropy SentenceSalad 18.9% 0.88% WordSalad 9.9% 0.13% Markovian 25.0% 0.28%
Table 1: Performance of the Multinomial Mixture
and LDA
For the multinomial mixture model, the LLPW measure is able to discriminate between true and false documents to a certain extent. As expected (not shown here), the LLPW of the true documents is usually higher than that of the false documents. In contrast, the entropy of the posterior topic dis-tribution does not help much in discriminating be-tween true and false documents. In fact it remains close to zero (meaning that only one topic is “ac-tive”) both for true and false documents.
The behaviour of the LDA scores is entirely dif-ferent. The perplexity scores (LLPW) of true and fake texts are comparable, and do not make useful predictors. In contrast, the entropy of the topic dis-tribution allows to sort true documents from fake ones with a very high accuracy for all kinds of fake texts considered in this paper. Both results stem from the ability of LDA to assign a different topic to each word occurrence.
variations The texts generated with a Markov model, no matter the order, have the highest en-tropy, reflecting the absence of long range corre-lation in the generation model. Though the texts generated by mixing sentences are more confus-ing with the true documents, the performance is still less than 1% EER. Texts mixing a high num-ber of topics (e.g., Sentence Salads) are almost as likely as natural texts that address only a few top-ics. However, the former has much higher entropy of the topic distribution due to a large number of topics being active in such texts (see also Figure 1).
0 1 2 3 4 5 6
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08
Entropy
Normalized frequency of occurence
[image:6.595.309.505.141.239.2]True: TrueReuters False: SentenceSalad False: WordSalad False: Markovian
Figure 1: Histogram of entropy of θfor different true and false document sets.
It is noteworthy that both the predictors (LLPW and Entropy) give complementary clues regarding a text category. A linear combination of these two scores (the weight to the LLPW score is 0.1) al-lows to substantially improve over these baseline results, yielding a relative improvement (in EER) of +20.0% for the sentence salads, +20.8% for the word salads, and +27.3% for the Markov Models.
5.2 Effect of the number of topics
In this part, we investigate the performance of LDA in detecting false documents when the num-ber of topics is changed. Increasing the numnum-ber of topics means higher memory requirements both during training and testing. Though the results are shown only for SentenceSalad, similar trend is ob-served for WordSalad and Markovian.
The numbers in Table 2 show that the perfor-mance obtained with the LLPW score consistently improve with an increase in the number of top-ics, though the % improvement obtained when the
number of topics exceeds 200 is marginal. In con-trast, the best performance in case of entropy is achieved at 50 topics and slowly degrades when a more complex model is used.
Number of Topics LLPW Entropy
10 27.9 1.88
50 18.9 0.88
100 16.0 0.93
200 14.8 0.90
300 13.8 1.05
[image:6.595.75.264.271.417.2]400 13.6 1.10
Table 2: EER from LLPW and Entropy distribution
for TrueReuters against SentenceSalad.
5.3 Detecting “noisy” documents
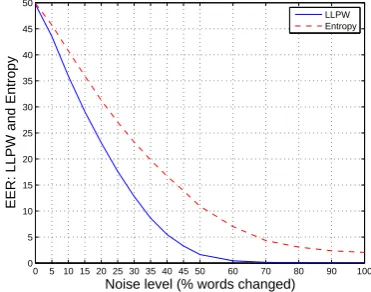
In this section, we study fake documents produced by randomly changing words in true documents (the TrueReuters dataset). In each document, a fixed percentage of content words is randomly re-placed by any other word from the training vocab-ulary6. This percentage was varied from 5 to 100 and EER for these corrupted document sets is com-puted at each % corruption level (Figure 2). As
0 5 10 15 20 25 30 35 40 45 50 60 70 80 90 100 0
5 10 15 20 25 30 35 40 45 50
Noise level (% words changed)
EER: LLPW and Entropy
LLPW Entropy
Figure 2: EER at various noise levels
expected, the EER is very high at low noise levels, and as the noise level is increased, EER gets lower. When only a few words are changed in a true doc-ument, it retrains the properties of a true document (high LLPW and low entropy). However, as more number of words are changed in a true document,
6When the replacement words are chosen from a small set
[image:6.595.311.497.444.590.2]it starts showing the characteristics of a false docu-ment (low LLPW and high entropy). These results suggest that our semantic consistency tests are too crude a measure to detect a small number of in-consistencies, such as the ones found in the state-of-the-art OCR or ASR systems’ outputs. On the other hand, it confirms the numerous studies that have shown that topic detection (and topic adapta-tion) or text categorization tasks can be performed with the same accuracy for moderately noisy texts and clean texts, a finding which warrants the topic-based LM adaptation strategies deployed in (Hei-del et al., 2007; Tam and Schultz, 2007).
The difference in the behavior of our two pre-dictors is striking. The EER obtained using LLPW drops more quickly than the one obtained with en-tropy of the topic distribution. It suggests that the influence of “corrupting” content words (mostly with lowβtw) is heavy on the LLPW, but the topic information is not lost till a majority of the “uncor-rupted” content words belong to the same topic.
5.4 Effect of the document length
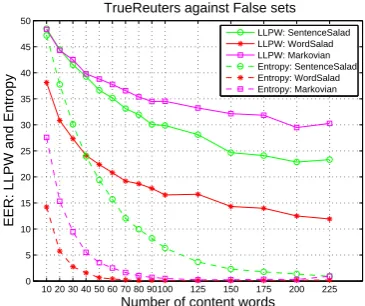
In this section, we study the robustness of our two predictors with respect to the document length by progressively increasing the number of content words in a document (true or fake). As can be seen from Figure 3, the entropy of the posterior topic distribution starts to provide a reasonable discrim-ination (5% EER) when the test documents contain about 80 to 100 content words, and attains results comparable to those reported earlier in this paper when this number doubles. This definitely rules out this method as a predictor of the semantic con-sistency of a sentence: we need to consider at least a paragraph to get acceptable results.
5.5 Testing with out-of-domain data
In this section, we study the robustness of our pre-dictors on out-of-domain data using a small ex-cerpt of abstracts from the Medline database. Both true and fake documents are from this dataset. The results are summarized in Table 3. The
[image:7.595.312.495.77.230.2]per-TrueMedline vs. LLPW Entropy SentenceSalad 31.23% 22.13% WordSalad 30.03% 19.46% Markovian 36.51% 23.63%
Table 3: Performance of LDA on PubMed
ab-stracts
formance on out-of-domain documents is poor,
10 20 30 40 50 60 70 80 90100 125 150 175 200 225 0
5 10 15 20 25 30 35 40 45 50
Number of content words
EER: LLPW and Entropy
TrueReuters against False sets
[image:7.595.85.266.665.723.2]LLPW: SentenceSalad LLPW: WordSalad LLPW: Markovian Entropy: SentenceSalad Entropy: WordSalad Entropy: Markovian
Figure 3: EER with change in number of
con-tent words used for LDA analysis. EER based on: LLPW of TrueReuters and false document sets (solid line) and Entropy of topic distribution of TrueReuters and false document sets (dashed line).
though the entropy of the topic distribution is still the best predictor. The reasons for this failure are obvious: a majority of the words occurring in these documents (true or fake) are, from the perspective of the model, characteristic of one single Reuters topic (health and medicine). They cannot be dis-tinguished either in terms of perplexity or in terms of topic distribution (the entropy is low for all the documents). It is interesting to note that all the out-of-domain Medline data can be separated from the in-domain TrueReuters data with good accu-racy on the basis of the lower LLPW of the former as compared to the higher LLPW of the latter.
6 Conclusion
train-ing LDA model with very large collections. In fu-ture we would like to explore the potential of this method for text segmentation tasks.
Acknowledgment
This research was supported by the European Commission under the contract
FP6-027026-K-Space. The views expressed in this paper are those
of the authors and do not necessarily represent the views of the commission.
References
Blei, David and John Lafferty. 2005. Correlated topic models. In Advances in Neural Information
Process-ing Systems (NIPS’18), Vancouver, Canada.
Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 2002. Latent Dirichlet allocation. In Dietterich, Thomas G., Suzanna Becker, and Zoubin Ghahra-mani, editors, Advances in Neural Information
Pro-cessing Systems (NIPS), volume 14, pages 601–608,
Cambridge, MA. MIT Press.
Blei, David M., Thomas L. Griffiths, Michael I. Jordan, and Joshua B. Tenenbaum. 2004. Hierarchical topic models and the nested Chinese restaurant process. In
Advances in Neural Information Processing Systems (NIPS), volume 16, Vancouver, Canada.
Buntine, Wray and Aleks Jakulin. 2004. Apply-ing discrete PCA in data analysis. In ChickerApply-ing, M. and J. Halpern, editors, Proceedings of the 20th
Conference on Uncertainty in Artificial Intelligence (UAI’04), pages 59–66. AUAI Press 2004.
Buntine, Wray, Jaakko L ¨ofstr¨om, Jukka Perki ¨o, Sami Perttu, Vladimir Poroshin, Tomi Silander, Henry Tirri, Antti Tuominen, and Ville Tuulos. 2004. A scalable topic-based open source search engine. In Proceedings of the IEEE/WIC/ACM International
Conference on Web Intelligence, pages 228–234,
Beijing, China.
Foltz, P.W., W. Kintsch, and T.K. Landauer. 1998. The measurement of textual coherence with Latent Se-mantic Analysis. Discourse Processes, 25(2-3):285– 307.
Globerson, Amir, Terry Y. Koo, Xavier Carreras, and Michael Collins. 2007. Exponentiated gradient al-gorithms for log-linear structured prediction. In
In-ternational Conference on Machine Learning,
Cor-vallis, Oregon.
Griffiths, Thomas L. and Mark Steyvers. 2004. Find-ing scientific topics. ProceedFind-ings of the National
Academy of Sciences, 101 (supl 1):5228–5235.
Griffiths, Thomas L., Mark Steyvers, David M. Blei, and Joshua Tenenbaum. 2005. Integrating topics and syntax. In Proceedings of NIPS, 17, Vancouver, CA.
Gruber, Amit, Michal Rosen-Zvi, and Yair Weiss. 2007. Hidden topic Markov models. In Proceedings
of International Conference on Artificial Intelligence and Statistics, San Juan, Puerto Rico, March.
Hearst, Marti. 1997. TextTiling: Segmenting texts into multi-paragraph subtopic passages. Computational
Linguistics, 23(1):33–64.
Heidel, Aaron, Hung an Chang, and Lin shan Lee. 2007. Language model adaptation using latent Dirichlet allocation and an efficient topic inference algorithm. In Proceedings of European
Confer-ence on Speech Communication and Technology,
Antwerp, Belgium.
Hofmann, Thomas. 2001. Unsupervised learning by probabilistic latent semantic analysis. Machine
Learning Journal, 42(1):177–196.
Hsu, Bo-June (Paul) and Jim Glass. 2006. Style & topic language model adaptation using HMM-LDA. In Proceedings of the Conference on
Empiri-cal Methods in Natural Language Processing,
Syd-ney, Australia.
Kivinen, Jyrki and Manfrud K. Warmuth. 1997. Expo-nentiated gradient versus gradient descent for linear predictors. Information and Computation, 132:1– 63.
Lewis, David D., Yiming Yang, Tony Rose, and Fan Li. 2004. RCV1: A new benchmark collection for text categorization research. Machine Learning
Re-search, 5:361–397.
Minka, Thomas and John Lafferty. 2002. Expectation-propagation for the generative aspect model. In
Pro-ceedings of the conference on Uncertainty in Artifi-cial Intelligence (UAI).
Nigam, K., A. K. McCallum, S. Thrun, and T. M. Mitchell. 2000. Text classification from labeled and unlabeled documents using EM. Machine Learning, 39(2/3):103–134.
Ohta, Tomoko, Yuka Tateisi, Hideki Mima, Jun ichi Tsujii, and Jin-Dong Kim. 2002. The GENIA cor-pus: an annotated research abstract corpus in molec-ular biology domain. In Proceedings of Human
Lan-guage Technology Conference, pages 73–77.
Rigouste, Lo¨ıs, Olivier Capp´e, and Franc¸ois Yvon. 2007. Inference and evaluation of the multino-mial mixture model for text clustering. Informa-tion Processing and Management, 43(5):1260–1280,
September.
Tam, Yik-Cheung and Tanja Schultz. 2007. Correlated latent semantic model for unsupervised LM adapta-tion. In Proceedings of the International Conference
on Acoustics, Speech and Signal Processing,